
Mureka V7.5 - Modelos avanzados de creación musical por IA de Quintessence
Mureka V7.5 es un modelo de generación musical de IA de última generación de Kunlun World Wide, centrado en la composición de canciones chinas. El modelo reproduce con precisión el timbre y las técnicas de interpretación para generar voces naturales, suaves y emotivas. Basado en la tecnología optimizada de reconocimiento automático del habla (ASR), Mureka V...

Skywork Deep Research Agent v2 - Una versión mejorada de la Inteligencia de Investigación Profunda de Kunlun
Skywork Deep Research Agent v2 es un organismo inteligente de investigación profunda lanzado por Kunlun Wave, centrado en la integración y el análisis de información multimodal.Skywork Deep Research Agent v2 puede procesar texto, gráficos...

Hunyuan-GameCraft - Marco de código abierto de Tencent Hunyuan para generar vídeo interactivo para juegos de nueva generación.
Hunyuan-GameCraft es el marco de generación de vídeo de juegos interactivos de código abierto del equipo Tencent Hunyuan. Marco de una sola imagen y le pide que genere vídeo de juego altamente dinámico , apoyar al usuario a través del teclado y el ratón para controlar el contenido de vídeo en tiempo real .

Skywork UniPic 2.0 - Modelado multimodal eficiente de código abierto por KunlunWanwei
Skywork UniPic 2.0 es un eficiente modelo multimodal de código abierto de Quintessence, centrado en la generación, edición y comprensión de imágenes. El modelo se basa en una arquitectura SD3.5-Medium de 2B parámetros, y se realiza mediante pre-entrenamiento, estrategia de refuerzo progresivo de doble tarea y co-entrenamiento....

RynnRCP - Primer protocolo de contexto robótico de código abierto del Instituto Ali Dharma
RynnRCP es un protocolo de contexto robótico (RCP, Robot Context Protocol) de código abierto del Instituto Ali Dharma que reduce el umbral para el desarrollo de la inteligencia incorporada y abre todo el proceso de desarrollo.

RynnEC - El modelo de comprensión del mundo de código abierto del Instituto Ali Dharma
RynnEC es un modelo de comprensión del mundo presentado por el Instituto Dharma de Alibaba, centrado en tareas de inteligencia incorporada. El modelo se basa en una tecnología de fusión multimodal que combina datos de vídeo y lenguaje natural, y puede analizar objetos de una escena desde múltiples dimensiones, lo que permite funciones como la comprensión de objetos, la percepción espacial y la segmentación de objetivos de vídeo.

Matrix-3D - Marco de generación de mundos 3D de código abierto para todo el mundo Kunlun
Matrix-3D es un framework de código abierto del equipo Skywork AI, centrado en la generación de mundos 3D panorámicos explorables. El marco combina técnicas de generación de vídeo panorámico y reconstrucción 3D para generar mundos 3D explorables omnidireccionales de alta calidad a partir de una sola imagen o...
GLM-4.5V - Modelo de razonamiento visual multimodal de código abierto de Smart Spectrum
GLM-4.5V es el modelo de inferencia visual de código abierto líder mundial presentado por Smart Spectrum, con 106.000 millones de parámetros totales y 12.000 millones de parámetros activados. El modelo se entrena a partir del modelo base de texto de nueva generación GLM-4.5-Air, con potentes capacidades de comprensión y razonamiento visual, capaz de manejar imágenes, vídeo...
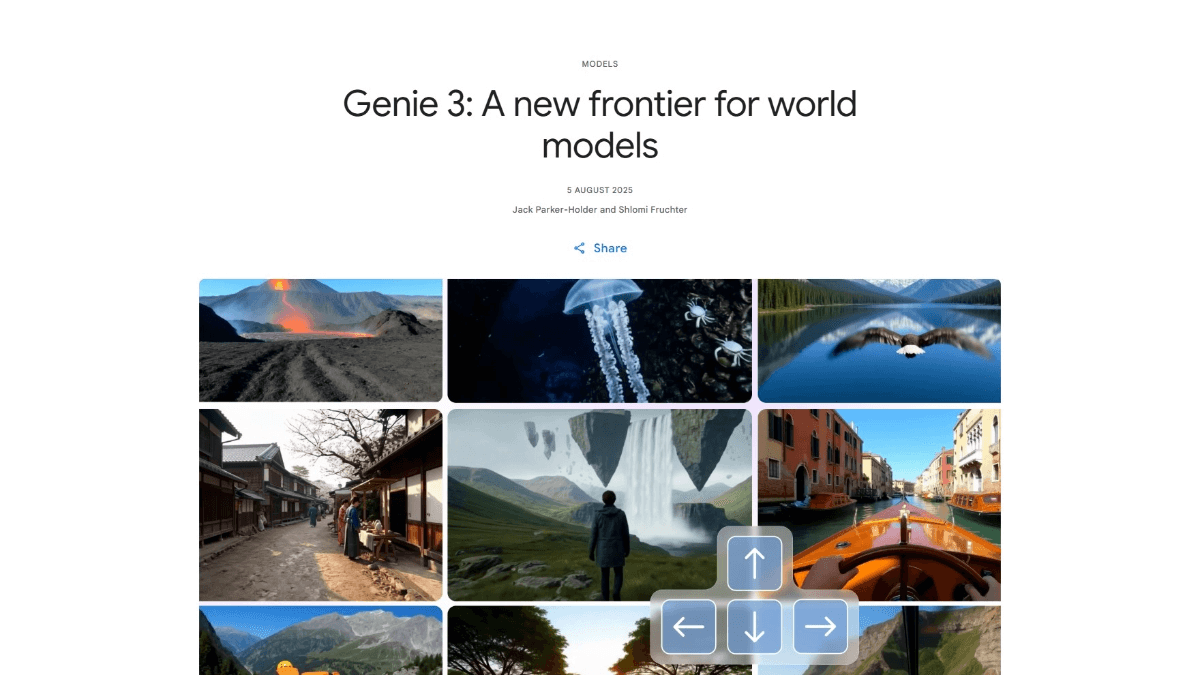
Genie 3 - El modelo universal del mundo de Google
Genie 3 es una nueva generación de modelos de mundo universales de Google DeepMind que permiten generar mundos virtuales muy dinámicos y coherentes en tiempo real.Genie 3 simula fenómenos físicos, ecosistemas naturales y admite la creación de escenarios fantásticos e históricos. Con indicaciones de texto, los usuarios pueden...
Claude Opus 4.1 - El modelo de programación más potente de Anthropic
Claude Opus 4.1 es un modelo de lenguaje a gran escala de última generación de Anthropic, diseñado para el procesamiento eficiente de tareas complejas. El modelo destaca en el ámbito de la programación, generando código de alta calidad, soportando hasta 32k de salida única y adaptándose a una amplia gama de estilos de programación....