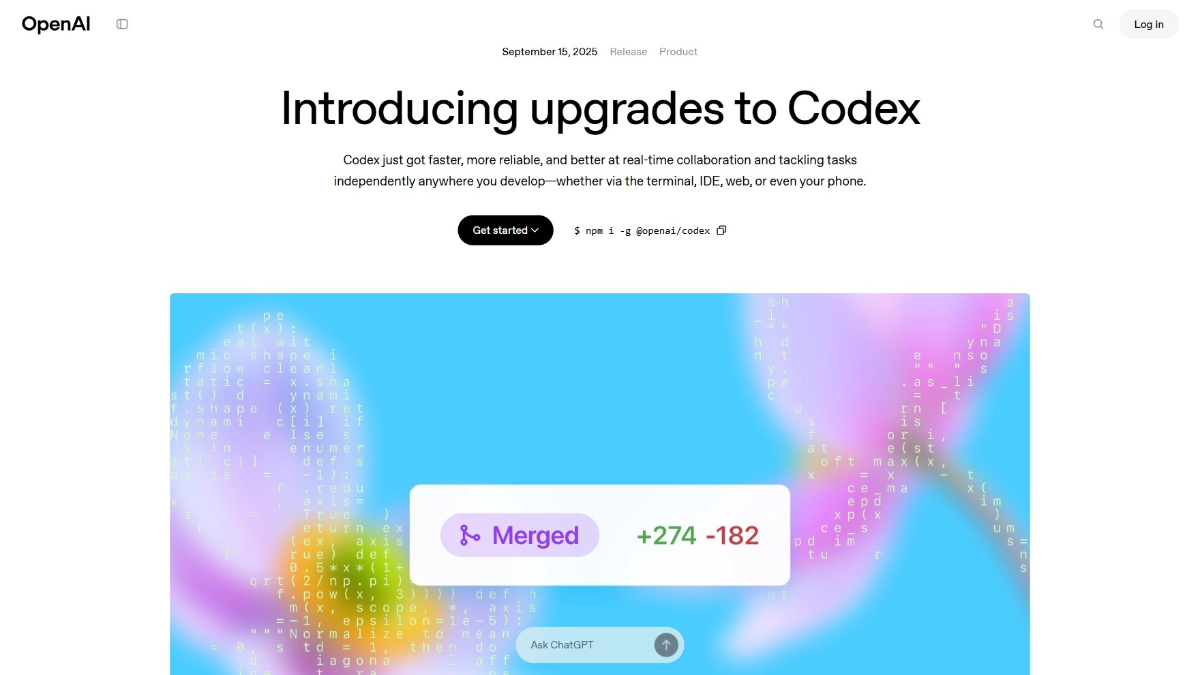
GPT-5-Codex: el modelo de programación más sólido introducido por OpenAI
GPT-5-Codex es un potente modelo de optimización de programación de OpenAI, mejorado por GPT-5 y diseñado para ingenieros de software. El modelo genera código de alta calidad con rapidez, es compatible con múltiples lenguajes de programación y optimiza el código existente para mejorar el rendimiento.

MiniMax Music 1.5 - ¡El último modelo de generación de música por IA de MiniMax!
MiniMax Music 1.5 es una herramienta avanzada de generación de música por IA que permite generar hasta 4 minutos de música a partir de la descripción en lenguaje natural del usuario. El modelo es compatible con una amplia gama de estilos musicales y personalización del estado de ánimo, y genera tonos vocales naturales y completos, transiciones suaves y arreglos ricamente estratificados....
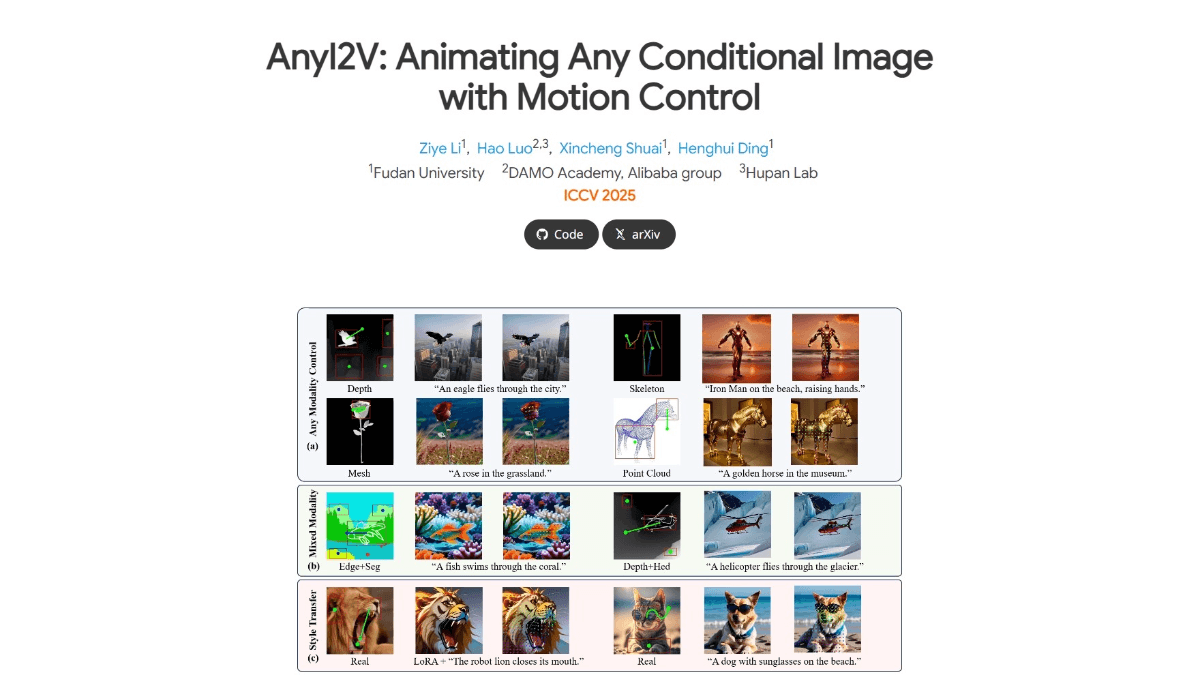
AnyI2V - Fudan y Ali Dharma Institute y otro marco de generación de animación de imágenes inteligente de código abierto
AnyI2V es un marco de generación de animaciones de imágenes lanzado conjuntamente por la Universidad de Fudan, Alibaba Darmo Academy y otras entidades, que permite convertir imágenes condicionales estáticas (por ejemplo, cuadrículas, nubes de puntos, etc.) en vídeos dinámicos sin necesidad de un complejo proceso de formación y una gran cantidad de datos.
SRPO - Modelo de generación de texto a imagen lanzado por Tencent Hybrid
SRPO (Semantic Relative Preference Optimization) es un modelo de generación de texto a imagen introducido por Tencent Mixed Meta, que optimiza el mecanismo de recompensa a través de señales condicionales textuales para lograr el ajuste en línea de las recompensas y reducir la dependencia del ajuste fuera de línea.
Qwen3-Next, el último modelo básico lanzado por Ali Tongyi
Qwen3-Next es un gran modelo de arquitectura híbrida de nueva generación, desarrollado por Ali Tongyi, que combina las tecnologías Gated DeltaNet y Gated Attention, lo que le permite tratar textos largos, realizar inferencias rápidas y ahorrar recursos informáticos.
Wenshin Big Model X1.1 - El modelo de pensamiento profundo de Baidu para comprender mejor
Wenxin Big Model X1.1 es un modelo de pensamiento profundo lanzado por Baidu, basado en un marco híbrido de aprendizaje por refuerzo que se centra en mejorar la comprensión y la generación de lenguaje. El modelo destaca en el manejo de preguntas complejas, el seguimiento de instrucciones y la simulación del comportamiento de las inteligencias, y puede proporcionar con precisión respuestas bien fundamentadas y contenidos de texto de alta calidad.

Imagen híbrida 2.1 - Modelo gráfico de proveedor de código abierto de Tencent
HunyuanImage 2.1 es el modelo gráfico de código abierto de Tencent diseñado para la generación de imágenes de alta calidad. El modelo admite resolución 2K nativa, puede renderizar con precisión escenas y detalles complejos, de modo que la expresión y el movimiento de los personajes pueden reproducirse vívidamente.
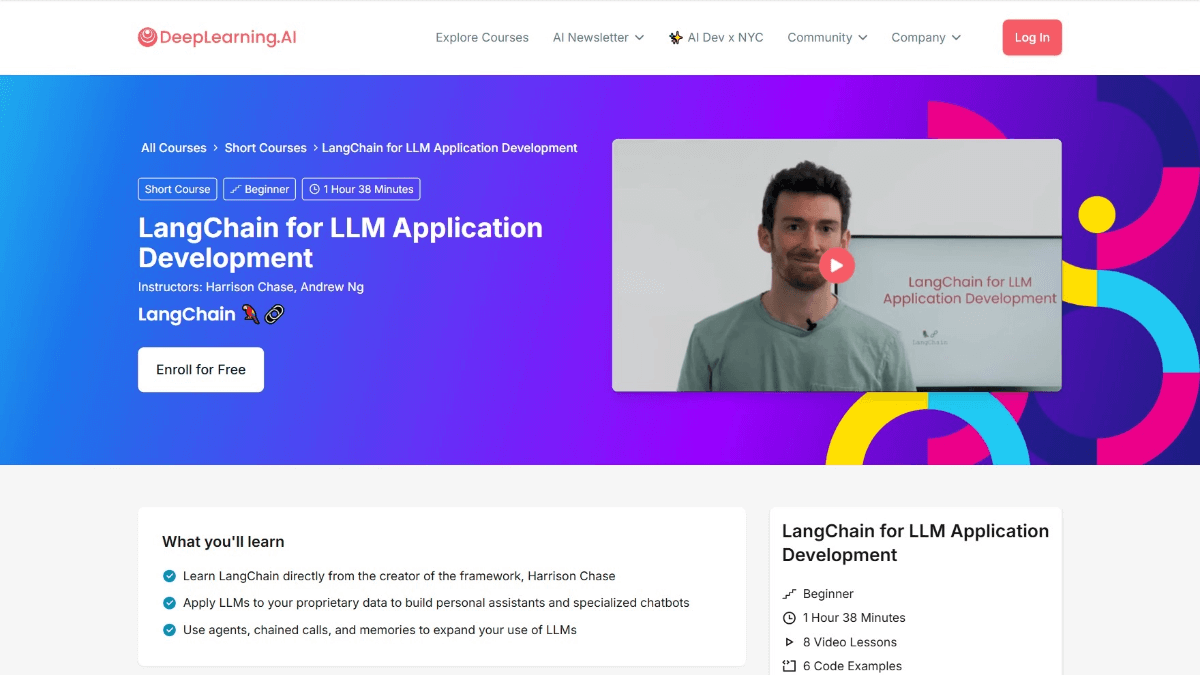
Curso gratuito de LangChain para el desarrollo de aplicaciones LLM por Ernest Ng
LangChain for LLM Application Development es un curso en línea de DeepLearning.AI en el que participan el fundador de LangChain, Harrison Chase, y Andrew Ng.
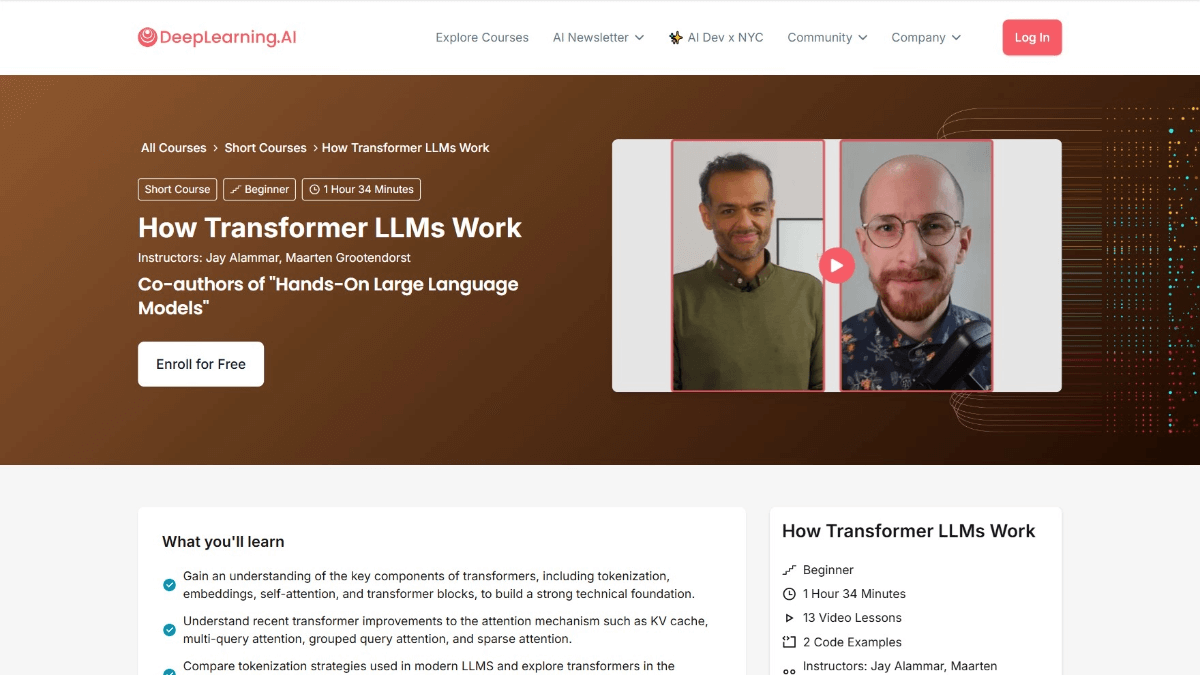
Curso gratuito sobre el funcionamiento de los Transformer LLM, por Enda Wu
Los LLM transformadores funcionan según el principio que DeepLearning.AI y Jay Alammar y Maarten Grootend, autores de Hands-On Large Language Models...

Seedream 4.0: la última generación de modelos de creación de imágenes lanzada por Bytes
Seedream 4.0 es una herramienta avanzada de generación y edición de imágenes lanzada por ByteDance, que se centra en la integración de la generación y la edición, con potentes funciones como la edición precisa de comandos, la alta retención de funciones y la comprensión profunda de intenciones.