
Alibaba AI Research Institute lanza CosyVoice 2: un modelo mejorado de síntesis de voz en streaming


1. Panorama general
La tecnología de síntesis de voz ha avanzado mucho en los últimos años, sobre todo en lo que respecta a la generación de voz natural y fluida en tiempo real. Sin embargo, problemas como la latencia, la precisión de la pronunciación y la coherencia del locutor siguen afectando al sector en aplicaciones reales, sobre todo en aplicaciones de streaming que requieren una gran capacidad de respuesta. Estos problemas técnicos son especialmente graves cuando se trata de entradas lingüísticas complejas, como trabalenguas o palabras polifónicas, que superan la capacidad de procesamiento de los modelos existentes. Para hacer frente a estos retos, los investigadores de Alibaba han presentado CosyVoice 2, un modelo mejorado para los retos técnicos de la síntesis de voz, que pretende resolver eficazmente estos problemas.
2. Debut de CosyVoice 2: de lo básico a lo más avanzado
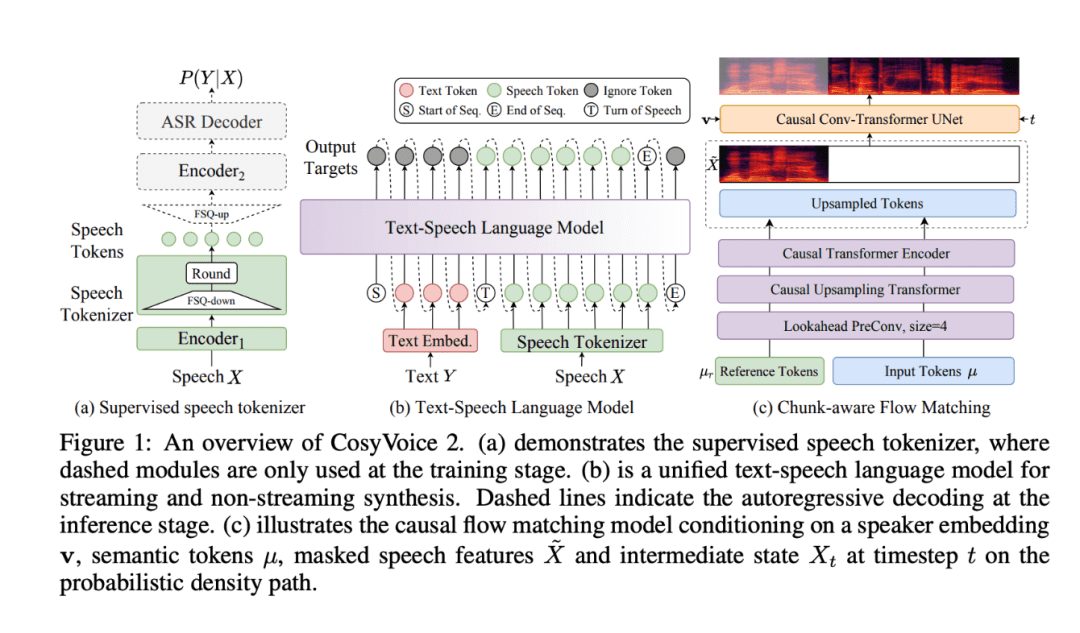 CosyVoice 2 se basa en los cimientos del CosyVoice original y aporta una importante mejora en la tecnología de síntesis de voz. Este modelo mejorado no sólo está optimizado para aplicaciones de streaming, sino que también supone un avance significativo en aplicaciones offline. Se ha mejorado su adaptabilidad, flexibilidad y precisión en una amplia gama de escenarios de aplicación, especialmente en los sistemas de conversión de texto en voz y de voz interactiva.
CosyVoice 2 se basa en los cimientos del CosyVoice original y aporta una importante mejora en la tecnología de síntesis de voz. Este modelo mejorado no sólo está optimizado para aplicaciones de streaming, sino que también supone un avance significativo en aplicaciones offline. Se ha mejorado su adaptabilidad, flexibilidad y precisión en una amplia gama de escenarios de aplicación, especialmente en los sistemas de conversión de texto en voz y de voz interactiva.
Aspectos más destacados de CosyVoice 2:
- Modos unificados de streaming y no streamingCosyVoice 2 se adapta sin problemas a diversos escenarios de aplicación, tanto si se generan en tiempo real como si se procesan fuera de línea, sin comprometer el rendimiento.
- Mayor precisión de pronunciación: En entornos lingüísticos complejos, CosyVoice 2 reduce los errores de 30%-50% pronunciación y mejora notablemente la inteligibilidad del habla, especialmente cuando se trata de palabras polisílabas o trabalenguas.
- mayor congruencia del oradorTanto si se trata de síntesis de disparo cero como de síntesis entre idiomas, CosyVoice 2 garantiza la coherencia de la salida, para que cada síntesis sea natural y fluida.
- Control de mando más precisoLos usuarios pueden controlar con precisión el tono, el estilo y el acento de su voz mediante comandos de lenguaje natural, e incluso adaptar la actuación de la voz a sus necesidades emocionales.
3. La tecnología y los puntos fuertes de la innovación
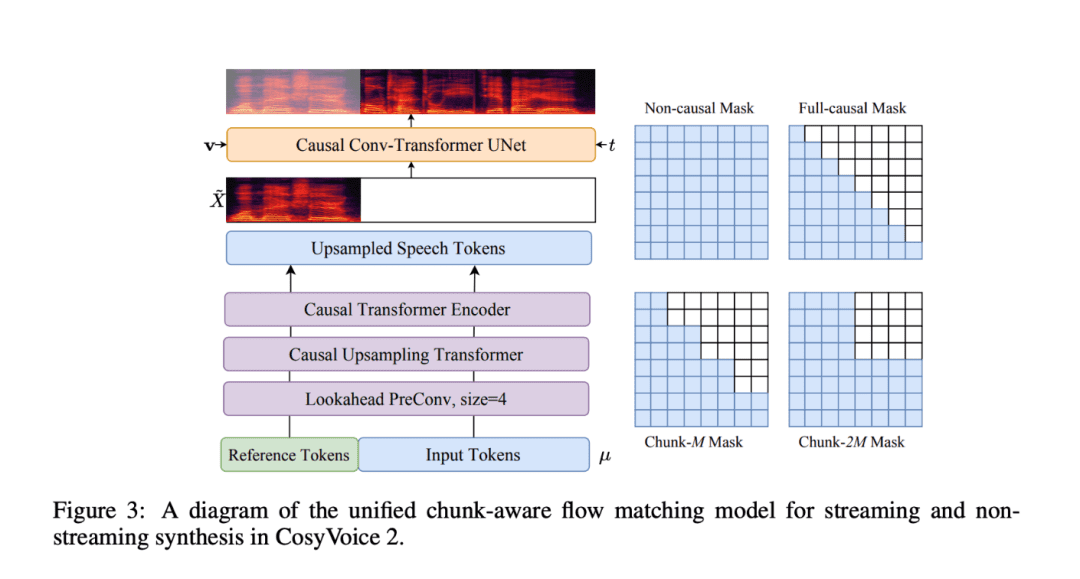
CosyVoice 2 ha sido capaz de resolver una serie de retos en el campo de la síntesis del habla gracias a una serie de innovaciones en su tecnología.
- Técnica de cuantificación escalar finita (FSQ): la FSQ sustituye al método tradicional de cuantificación vectorial, optimiza el uso de vocabularios con etiquetas de voz y mejora la capacidad de representación semántica y la calidad de la síntesis. Esta innovación tecnológica no sólo mejora la capacidad expresiva del modelo, sino que también reduce eficazmente la complejidad del tratamiento de datos.
- Arquitectura simplificada de conversión de texto a voz: CosyVoice 2 se basa en grandes modelos lingüísticos (LLM) preentrenados, lo que elimina la necesidad de codificadores de texto adicionales y simplifica la arquitectura del modelo para mejorar el rendimiento en varios idiomas. Este diseño arquitectónico hace que CosyVoice 2 sea mucho más eficiente y preciso al procesar varios idiomas.
- Correspondencia de flujos causales basada en bloques: esta innovadora tecnología permite alinear las características semánticas y acústicas con una latencia mínima, lo que permite a CosyVoice 2 destacar en la generación de voz en tiempo real, especialmente para aplicaciones de interacción y transmisión de voz en tiempo real.
- Conjunto de datos de comandos ampliado: Con más de 1500 horas de datos de entrenamiento, CosyVoice 2 añade control granular sobre diferentes acentos, emociones y estilos de voz, haciendo que la síntesis de voz sea más flexible y expresiva. Tanto si se trata de un tono de voz cálido como de una emoción tensa, CosyVoice 2 es capaz de captarla y expresarla con precisión.
4. Rendimiento de CosyVoice 2: cómo resuelve problemas reales
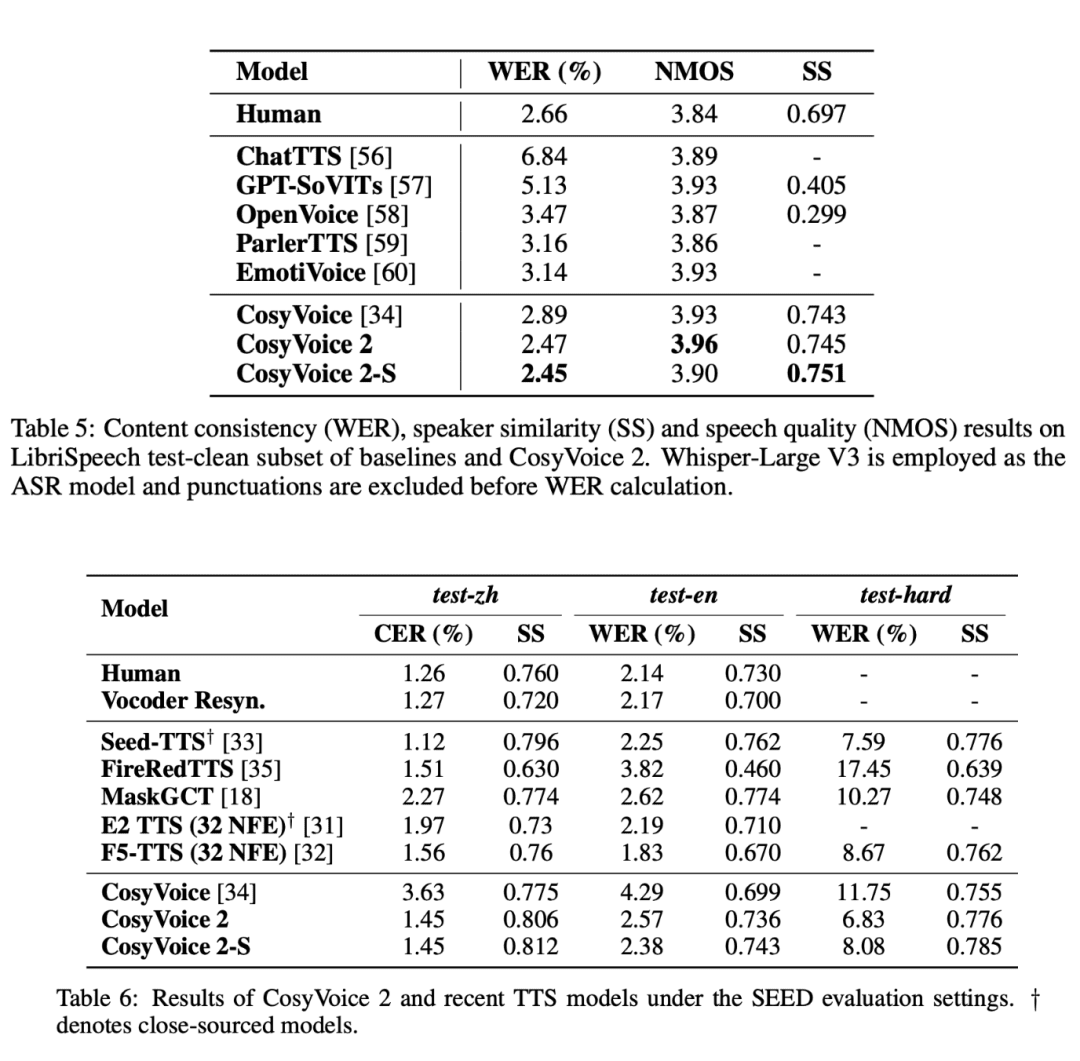
En una serie de rigurosas pruebas de evaluación, CosyVoice 2 demostró ventajas innegables, sobre todo en términos de baja latencia, alta precisión y coherencia vocal.
- Baja latencia y alta eficiencia: CosyVoice 2 tiene tiempos de respuesta de tan sólo 150 milisegundos en la generación de voz, lo que significa que puede ser ideal para aplicaciones de voz en tiempo real como el chat de voz y las interacciones por streaming.
- Mejora de la precisión de la pronunciaciónCosyVoice 2 aporta mejoras significativas a las estructuras lingüísticas complejas (por ejemplo, polisílabos, trabalenguas, etc.), mejorando drásticamente la precisión de la pronunciación y reduciendo los errores en la síntesis del habla cotidiana.
- Rendimiento uniforme de los altavocesCosyVoice 2 es capaz de mantener un alto grado de coherencia en distintas tareas de síntesis, ya se trate de síntesis entre idiomas o de síntesis de disparo cero, y la naturalidad y estabilidad del habla están ampliamente garantizadas.
- multilingüismoCosyVoice 2 también obtuvo buenos resultados en pruebas de idiomas como el japonés y el coreano y, a pesar de los problemas que plantean algunos juegos de caracteres superpuestos, demostró la potencia de la síntesis multilingüe.
- Resistencia en situaciones difícilesCosyVoice 2 demostró una mayor claridad y precisión que los modelos anteriores en algunas situaciones de habla difíciles (por ejemplo, trabalenguas), superando las limitaciones técnicas anteriores.
5. Conclusión
El lanzamiento de CosyVoice 2 supone un importante avance en la tecnología de síntesis de voz. Ofrece una solución más madura y estable al abordar cuestiones clave como la latencia, la precisión y la coherencia del locutor. Tecnologías innovadoras como FSQ y la correspondencia de flujo causal con detección de bloques respaldan firmemente el rendimiento y la facilidad de uso del modelo, mientras que un amplio conjunto de datos de formación y un control preciso de los estilos de voz le permiten hacer frente a una amplia gama de escenarios de aplicaciones de voz complejas.
Aunque CosyVoice 2 aún debe mejorar en términos de compatibilidad multilingüe y procesamiento de escenarios lingüísticos complejos, sienta unas bases sólidas para la futura tecnología de síntesis de voz, especialmente en la aplicación de streaming multimedia y la generación de voz en tiempo real, que tiene amplias perspectivas de desarrollo. Ya sea en el campo de los asistentes de voz inteligentes, la atención al cliente inteligente o la traducción en tiempo real, CosyVoice 2 demuestra su gran potencial y allana el camino para nuevos avances en la tecnología de síntesis de voz.
Referencia:
- https://arxiv.org/abs/2412.10117
- https://huggingface.co/spaces/FunAudioLLM/CosyVoice2-0.5B
- https://www.modelscope.cn/models/iic/CosyVoice2-0.5B
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...