Se ha publicado la primera lista de puntos de referencia de la evaluación "AI Search"! El margen de ventaja de 4o es pequeño, y los grandes modelos nacionales rinden brillantemente, con un total de 5 bases, 11 escenarios y 14 modelos.


La publicación de la evaluación comparativa del big model chino "AI Search" (SuperCLUE-AISearch) es una evaluación en profundidad de la capacidad del big model combinado con la búsqueda. La evaluación no sólo se centra en las capacidades básicas del big model, sino que también examina su rendimiento en aplicaciones de escenarios. La evaluación abarca 5 capacidades básicas, como la recuperación de información y la adquisición de información actualizada, así como 11 aplicaciones de escenarios, como las noticias y las aplicaciones de la vida, para probar exhaustivamente el rendimiento del modelo en la combinación de búsqueda en diferentes capacidades básicas y tareas de aplicaciones de escenarios. Para conocer el esquema de evaluación, véase: "AI Search" Benchmark Evaluation Scheme Release. En esta ocasión, hemos evaluado las capacidades de búsqueda de IA de 14 grandes modelos representativos nacionales y extranjeros, y a continuación presentamos el informe de evaluación detallado.
Resumen de la evaluación de la búsqueda por IA
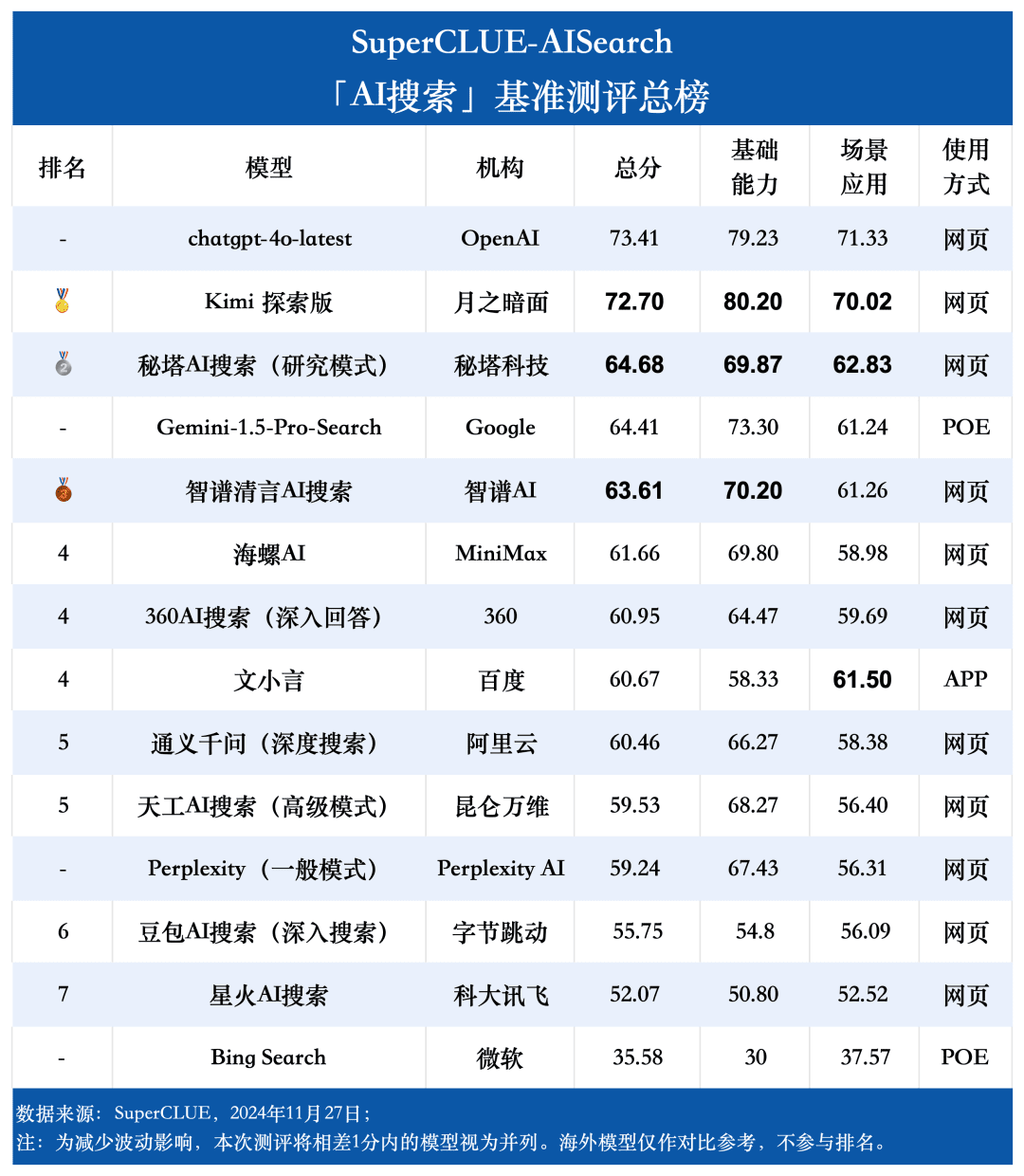
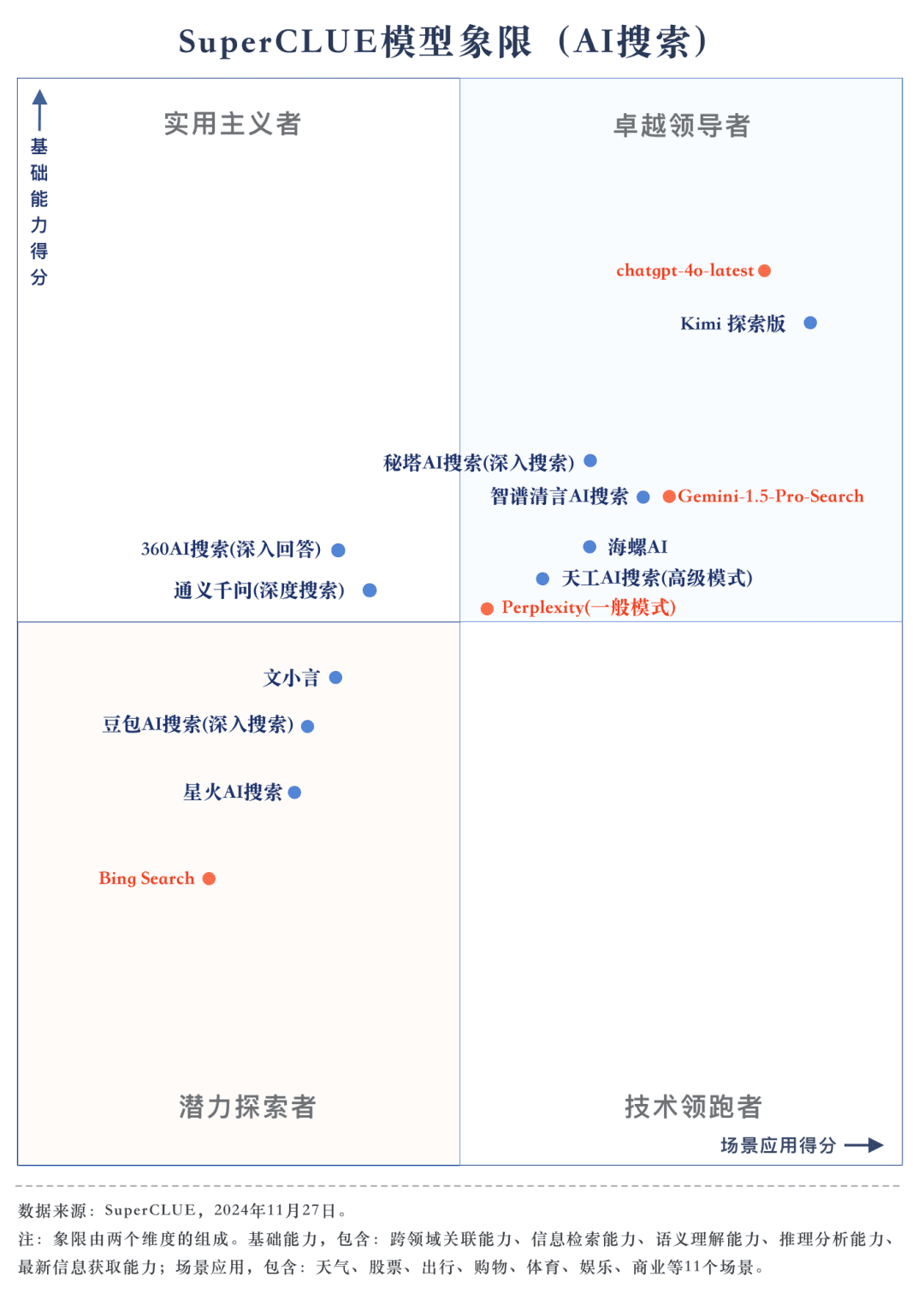
Punto de medición 1chatgpt-4o-latest lidera la lista de búsqueda de IA, seguido de Kimi Explorer, con sólo 0,71 puntos entre ambos En esta evaluación, chatgpt-4o-latest obtuvo 73,41 puntos con un rendimiento excelente, por delante de otros modelos participantes. Por su parte, el gran modelo nacional Kimi El rendimiento de la edición Explorer también es digno de mención, ya que obtiene buenos resultados en los temas de compras y cultura en la aplicación de escenarios, demostrando unas magníficas capacidades de búsqueda de IA, además de mostrar un excelente rendimiento global en múltiples dimensiones.
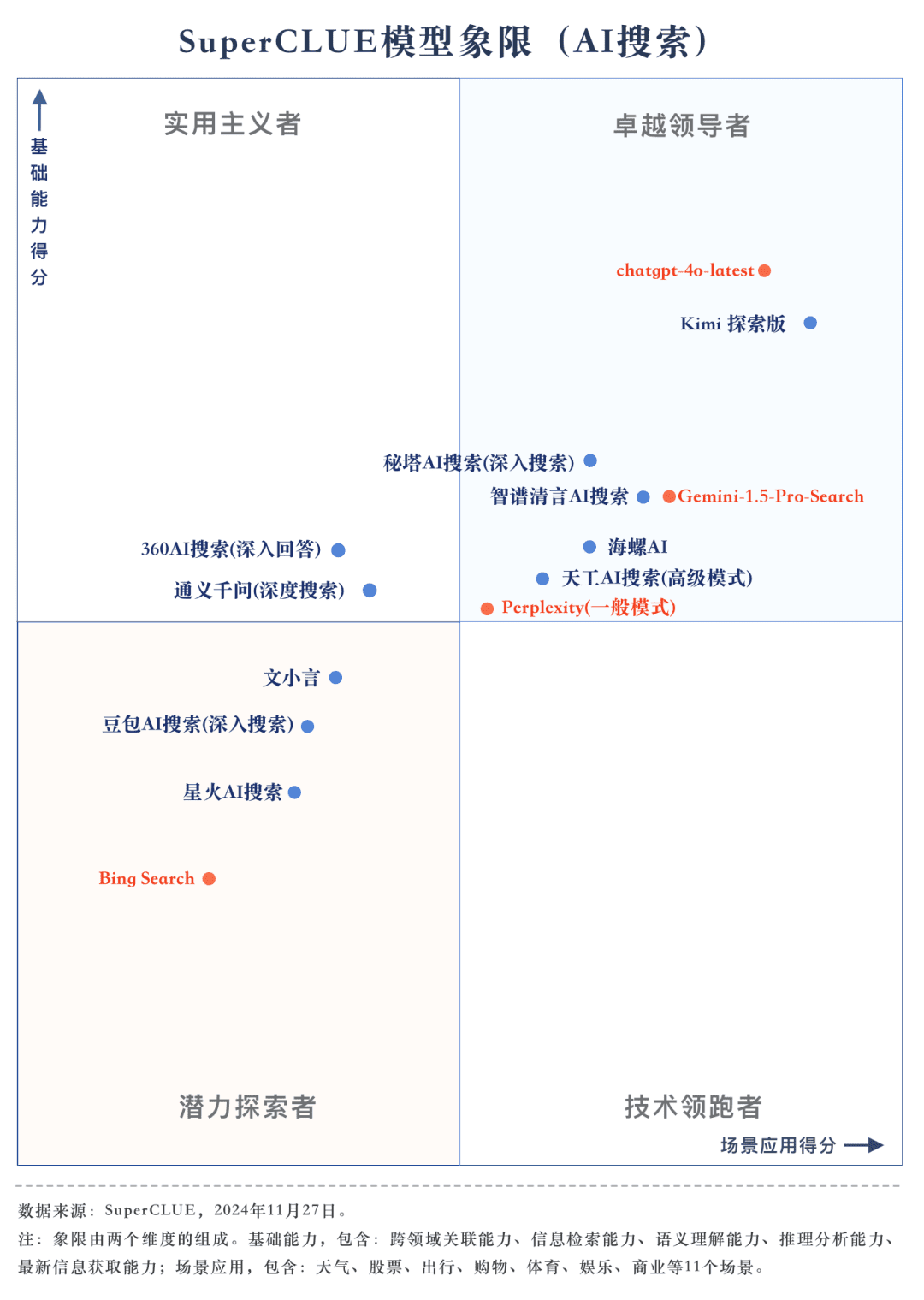
Punto de medición 2A partir de los resultados de la evaluación, los grandes modelos nacionales como Secret Tower AI Search (Research Mode), Wisdom Spectrum Clear Speech AI Search y Conch AI son más impresionantes en términos de rendimiento general, a la par con el gran modelo extranjero Gemini-1.5-Pro-Search. Aparte de eso, el rendimiento de varios grandes modelos nacionales en el medio del rendimiento general como 360AI Search (respuesta en profundidad), Wen XiaoYin, Tongyi QianQi (búsqueda profunda) y otros grandes modelos no son similares, mostrando una pequeña diferencia.
Punto de medición 3Los modelos muestran distintos grados de rendimiento en diferentes escenarios de aplicación. En la evaluación de la búsqueda de IA, también nos centramos en el rendimiento de cada gran modelo en diferentes escenarios de aplicación. Los grandes modelos nacionales obtuvieron resultados relativamente buenos en escenarios como la ciencia y la tecnología, la cultura, los negocios y el entretenimiento, demostrando una excelente capacidad de recuperación e integración de la información al tiempo que captaban la actualidad de la información. Sin embargo, los big models nacionales aún pueden mejorar en escenarios como el bursátil y el deportivo.
Resumen de la lista
Introducción a SuperCLUE-AISearch
SuperCLUE-AISearch es un completo conjunto de evaluación de modelos chinos de búsqueda de IA, cuyo objetivo es proporcionar una referencia para evaluar la capacidad de los modelos de búsqueda de IA en el ámbito chino.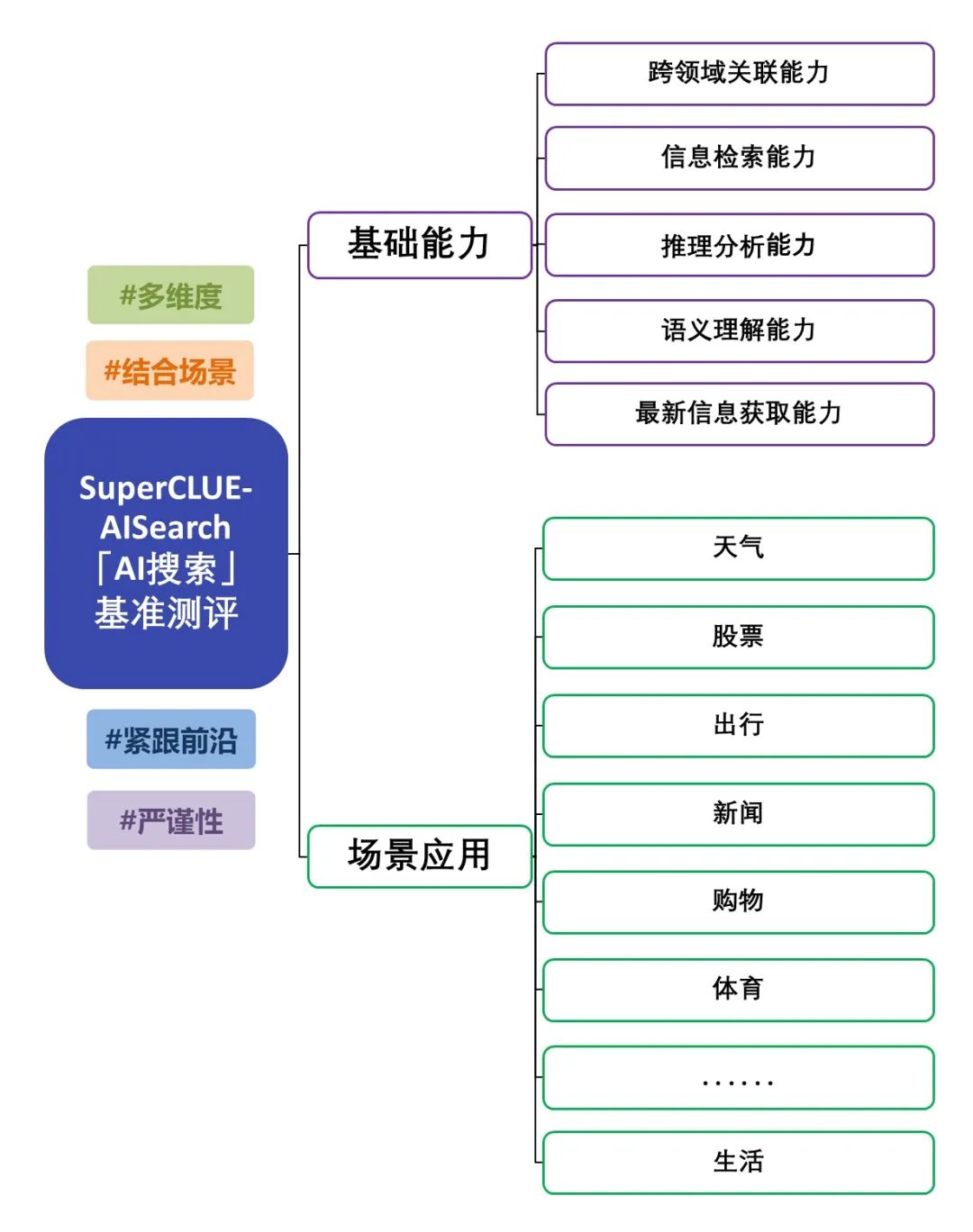
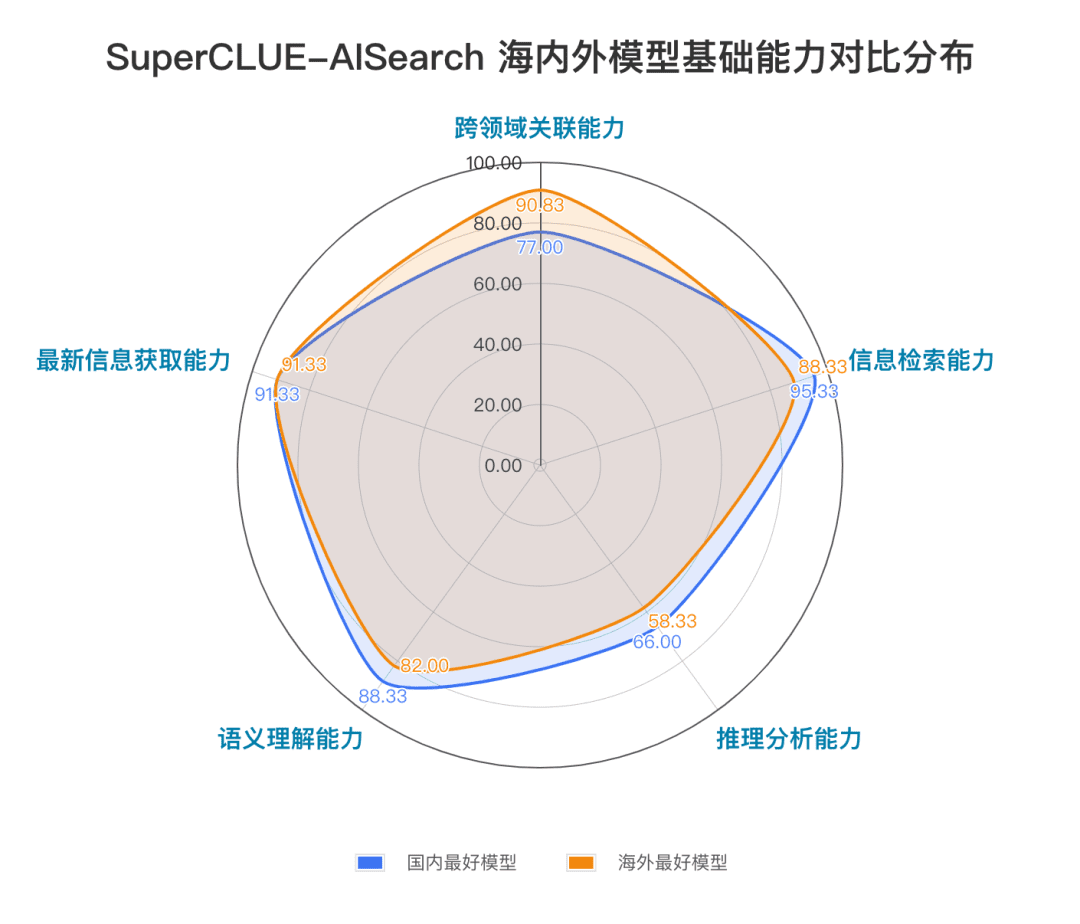
Las capacidades fundacionales incluyen cinco capacidades necesarias en las tareas de búsqueda de IA: relevancia entre dominios, recuperación de información, comprensión semántica, adquisición de información actualizada y razonamiento.
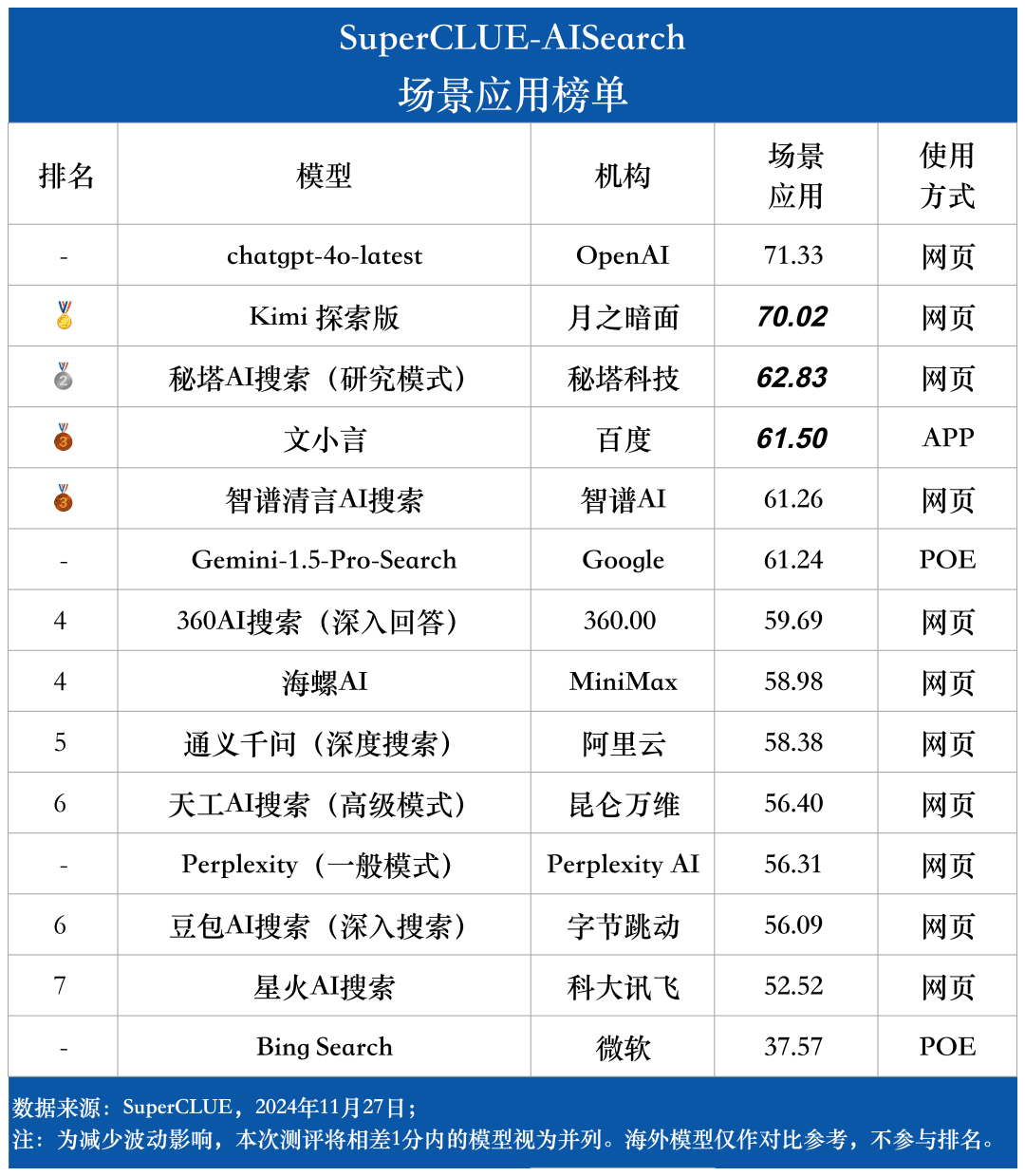
Las aplicaciones de escenarios incluyen 11 escenarios comunes a las tareas de búsqueda de IA: tiempo, bolsa, viajes, noticias, compras, deportes, entretenimiento, educación, viajes, negocios, cultura, tecnología, sanidad y vida.
Metodología
En referencia al enfoque de evaluación detallada de SuperCLUE, se construye un conjunto específico de mediciones, y cada dimensión se evalúa a un nivel detallado y se puede proporcionar información de retorno detallada.
1) Construcción del juego de medidas
Proceso de elaboración de la consigna china: 1. Referencia a la consigna existente ---> 2. Redacción de la consigna china ---> 3. Pruebas ---> 4. Modificación y finalización de la consigna china; elaboración de un conjunto de evaluaciones específicas para cada dimensión.
2) Método de puntuación
El proceso de evaluación comienza con la interacción del modelo con el conjunto de datos, que hay que comprender y responder en función de las preguntas planteadas.
Los criterios de evaluación abarcan las dimensiones de proceso de pensamiento, proceso de resolución de problemas, reflexión y ajuste.
Las normas de puntuación combinan la puntuación cuantitativa automatizada con la revisión por expertos para puntuar de forma eficaz, garantizando al mismo tiempo que la evaluación sea científica y justa.
3) Criterios de puntuación
Para la evaluación de la calidad de respuesta de cada macromodelo en las tareas de evaluación, utilizamos dos criterios de evaluación para evaluar las preguntas subjetivas y objetivas del conjunto de evaluación, respectivamente. A estos criterios se les asignaron diferentes pesos en la evaluación para reflejar plenamente el rendimiento de los macromodelos en la tarea de búsqueda de IA.
El sistema de evaluación SuperCLUE-AISearch está diseñado para puntuar las preguntas subjetivas sobre 5 puntos, que se evalúan a partir de las dimensiones de utilidad de la información, precisión analítica y claridad de expresión, de las cuales la utilidad de la información supone 60%, la precisión analítica supone 20% y la claridad de expresión supone 20%.Los criterios de puntuación de las preguntas objetivas se puntúan sobre 5 puntos, que se evalúan a partir de las dimensiones de precisión de la información y claridad de expresión, de las cuales la precisión de la información supone 80% y la claridad de expresión supone 20%. Las preguntas objetivas se puntúan sobre 5 puntos, evaluados en dos dimensiones: exactitud de la información y claridad de la expresión, de las cuales la exactitud de la información supone 80% y la claridad de la expresión supone 20%. 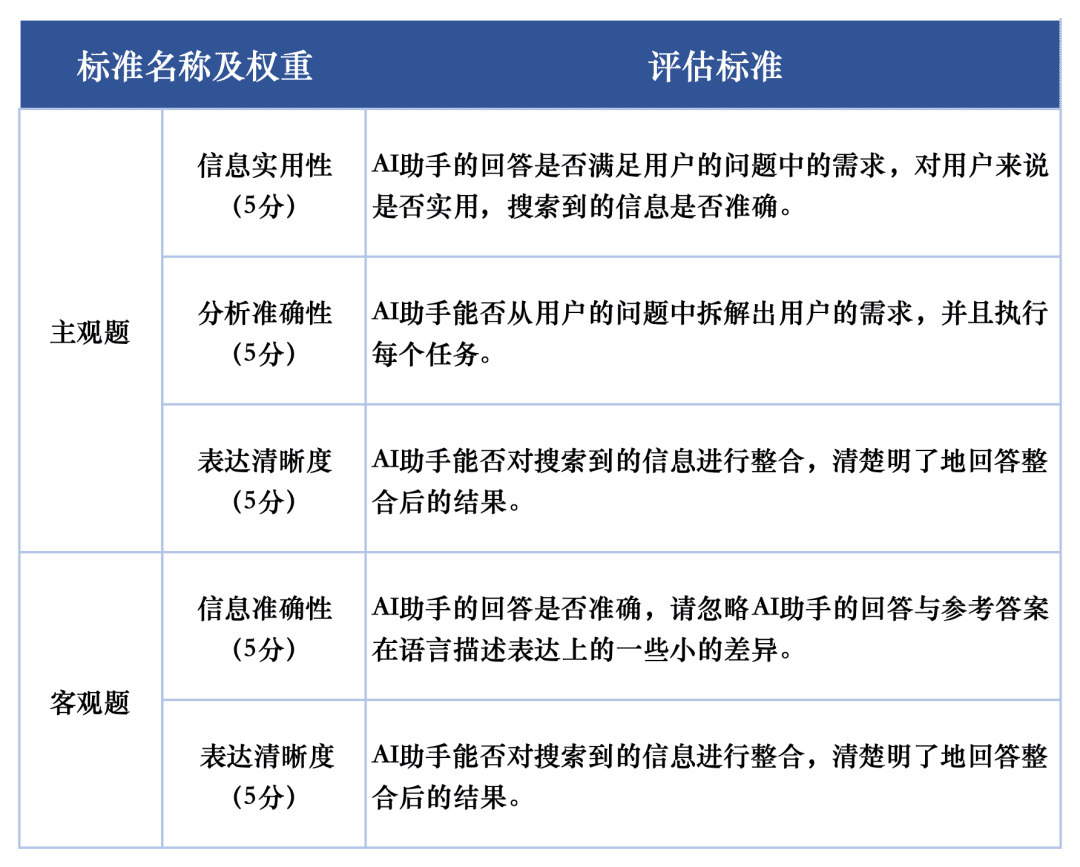
Ejemplo de evaluación
Prompt word Prompt: ¿cuándo y dónde se lanzó la nave espacial tripulada Shenzhou 19 y quiénes eran los astronautas en esta ocasión?
Respuesta: En la madrugada del 30 de octubre, el lanzamiento de la nave espacial tripulada Shenzhou XIX desde el Centro de Lanzamiento de Satélites de Jiuquan fue todo un éxito. La tripulación de la misión tripulada Shenzhou-19 estaba formada por tres astronautas, Cai Xuzhe, Song Lingdong y Wang Haize.
Respuesta modelo:
Supermodelo (chatgpt-4o-latest) árbitro:
Evalúe esta respuesta del siguiente modo:
La respuesta del asistente de IA proporcionó con precisión la hora de lanzamiento y la ubicación de la nave espacial tripulada Shenzhou XIX, así como la lista de astronautas. Sin embargo, la respuesta no mencionaba los objetivos principales ni el contenido de la misión, por lo que no satisfacía plenamente la necesidad del usuario de conocer los detalles de la misión. Además, la sección sobre los perfiles personales de los astronautas, aunque detallada, puede haber excedido el ámbito de interés de los usuarios. Por lo tanto, se recomienda añadir a la respuesta una breve descripción de los objetivos y principales tareas de la misión para satisfacer mejor las necesidades de los usuarios.1. Utilidad de la información (5 puntos):
El asistente de IA proporcionó la hora de lanzamiento, la ubicación y la lista de astronautas de Shenzhou XIX, satisfaciendo la necesidad del usuario de esta información básica. Sin embargo, no se mencionaron los objetivos principales ni el contenido de la misión, lo que no satisfizo plenamente la necesidad del usuario de conocer los detalles de la misión. Por lo tanto, la puntuación de la utilidad de la información fue de 4.
Puntuación: 4/52. Precisión del análisis (5 puntos):
El asistente de IA extrajo con precisión información clave como la hora de lanzamiento, la ubicación y la lista de astronautas a partir de la pregunta del usuario y proporcionó un perfil personal detallado. Sin embargo, no abordó los objetivos ni el contenido principal de la misión, y no logró satisfacer plenamente las necesidades del usuario. Por tanto, la puntuación de la precisión del análisis fue de 4.
Puntuación: 4/53. claridad de expresión (5 puntos):
Las respuestas del asistente de IA están claramente estructuradas, con información bien organizada y fácil de entender. La sección del perfil personal es detallada, lo que facilita a los usuarios la comprensión de los antecedentes del astronauta. Por lo tanto, la claridad de expresión se puntúa con un 5.
Puntuación: 5/5 puntuación compuesta = 4*0,6 + 4*0,2 + 5*0,2 = 4,2 Combinada, la puntuación compuesta para la respuesta del asistente de IA es 4,2. (sobre 5 puntos)
Modelos participantes
Para medir de forma exhaustiva el nivel de desarrollo actual de los grandes modelos nacionales e internacionales en cuanto a capacidad de búsqueda de IA, se seleccionaron para esta evaluación 4 modelos extranjeros y 10 modelos nacionales representativos.
En vista de que muchos modelos a gran escala nacionales y extranjeros suelen ofrecer dos o más versiones, incluida la versión ordinaria y la versión de exploración en profundidad, en este proceso de selección de modelos adoptamos un criterio unificado: si un modelo está equipado con una versión de búsqueda o análisis en profundidad, seleccionaremos la versión con mayor capacidad de búsqueda para una evaluación exhaustiva. 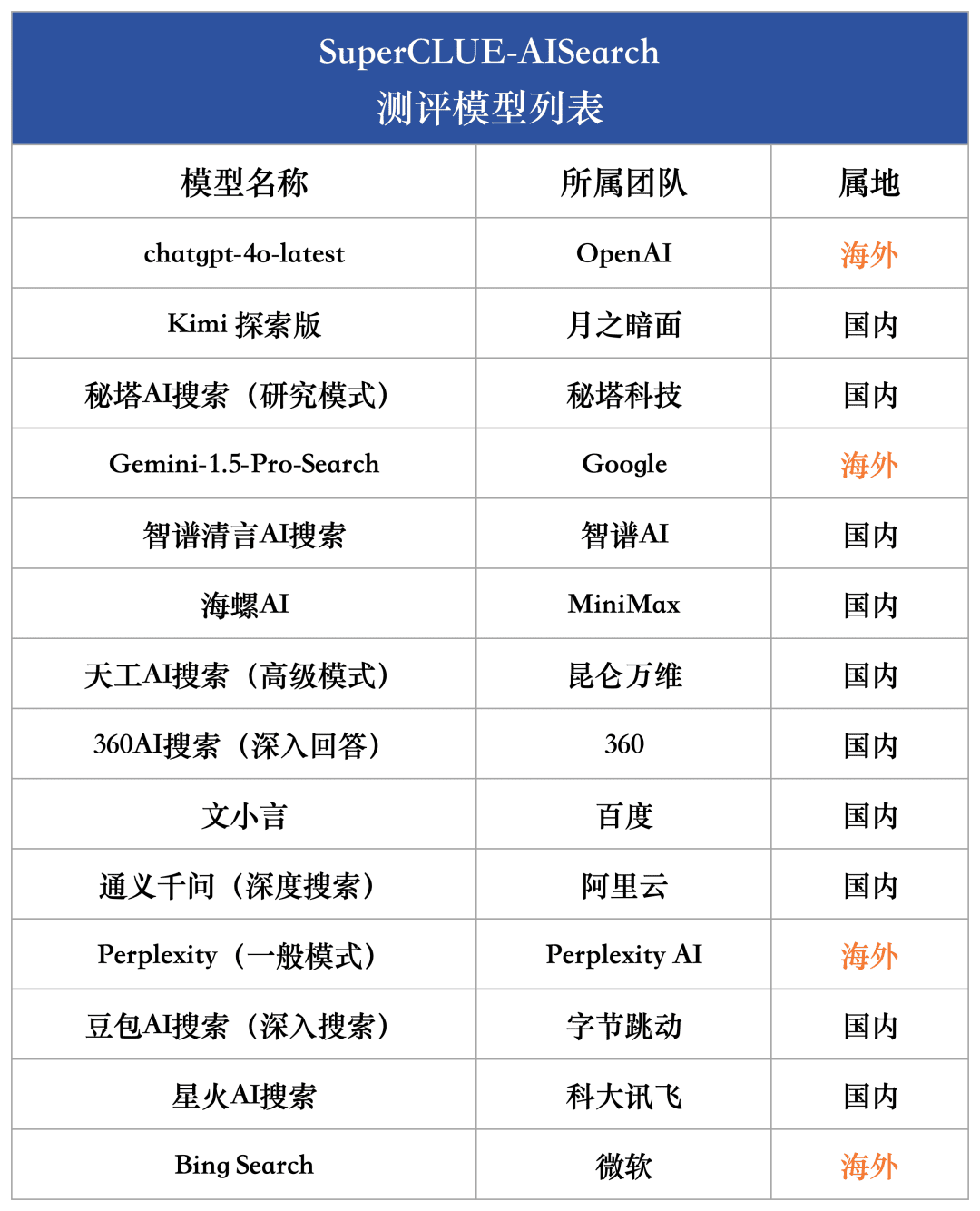
Resultados de la evaluación
lista general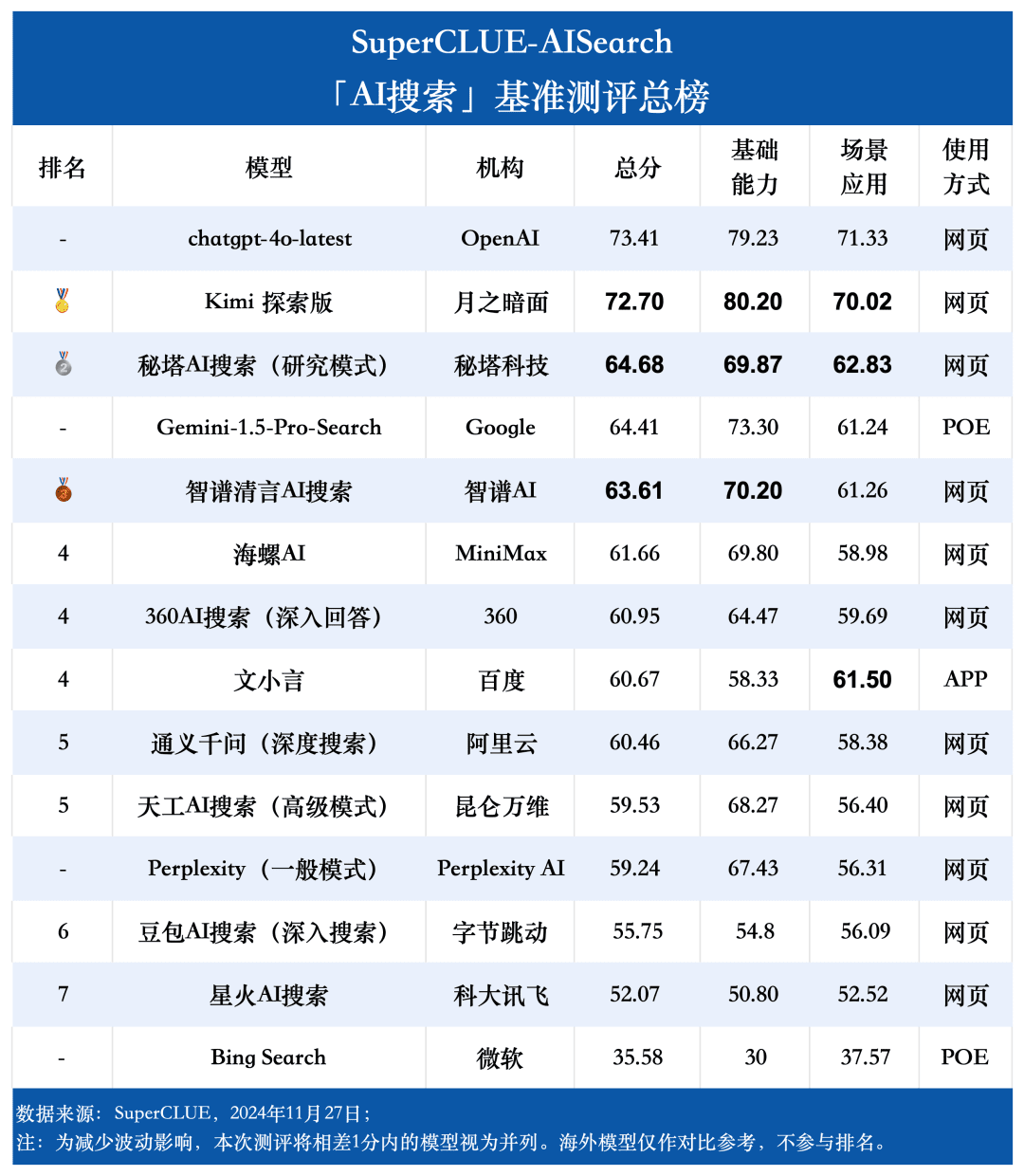
Lista de capacidades básicas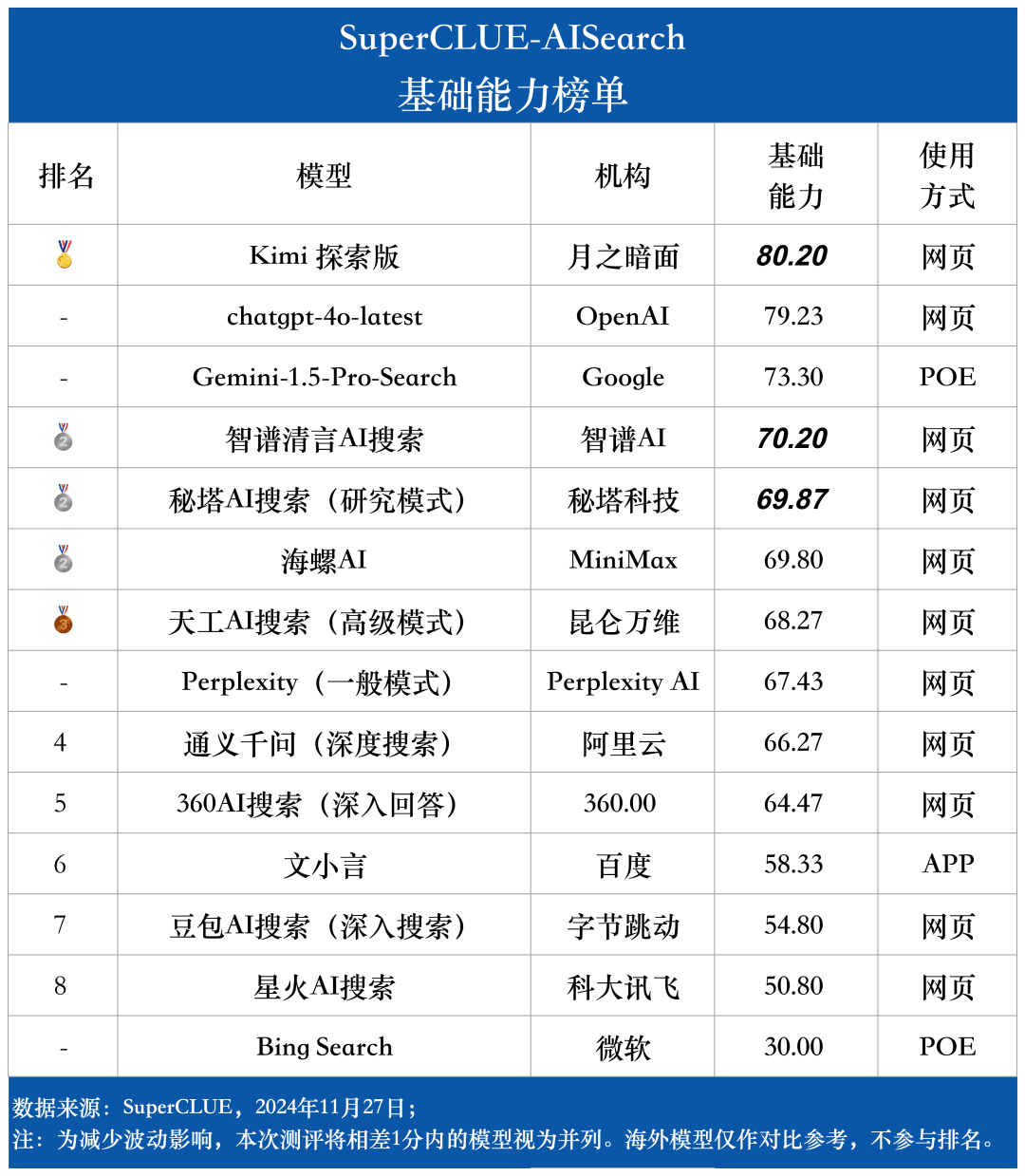
Escenario Lista de aplicaciones
Lista de preguntas subjetivas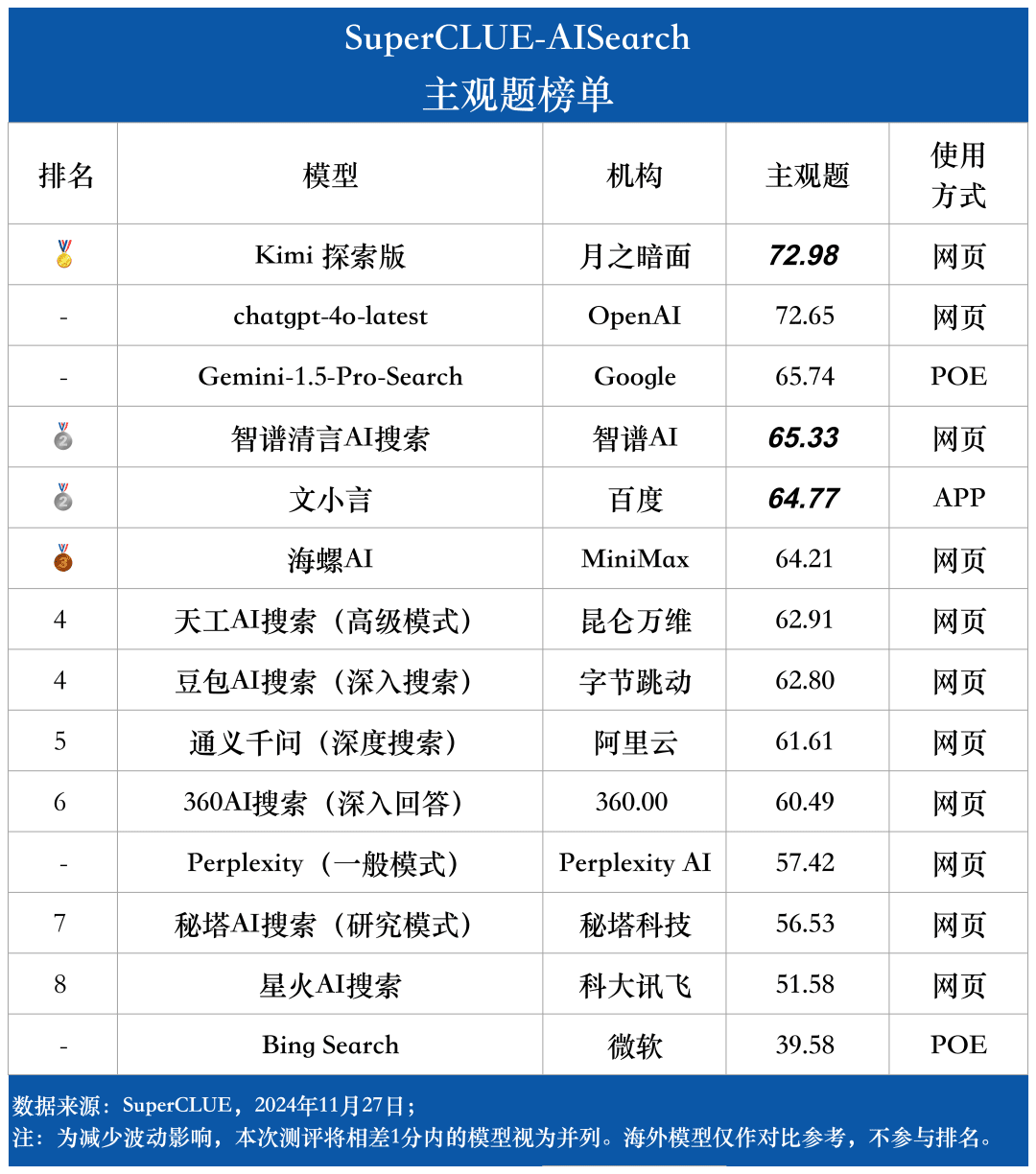
Lista de preguntas objetivas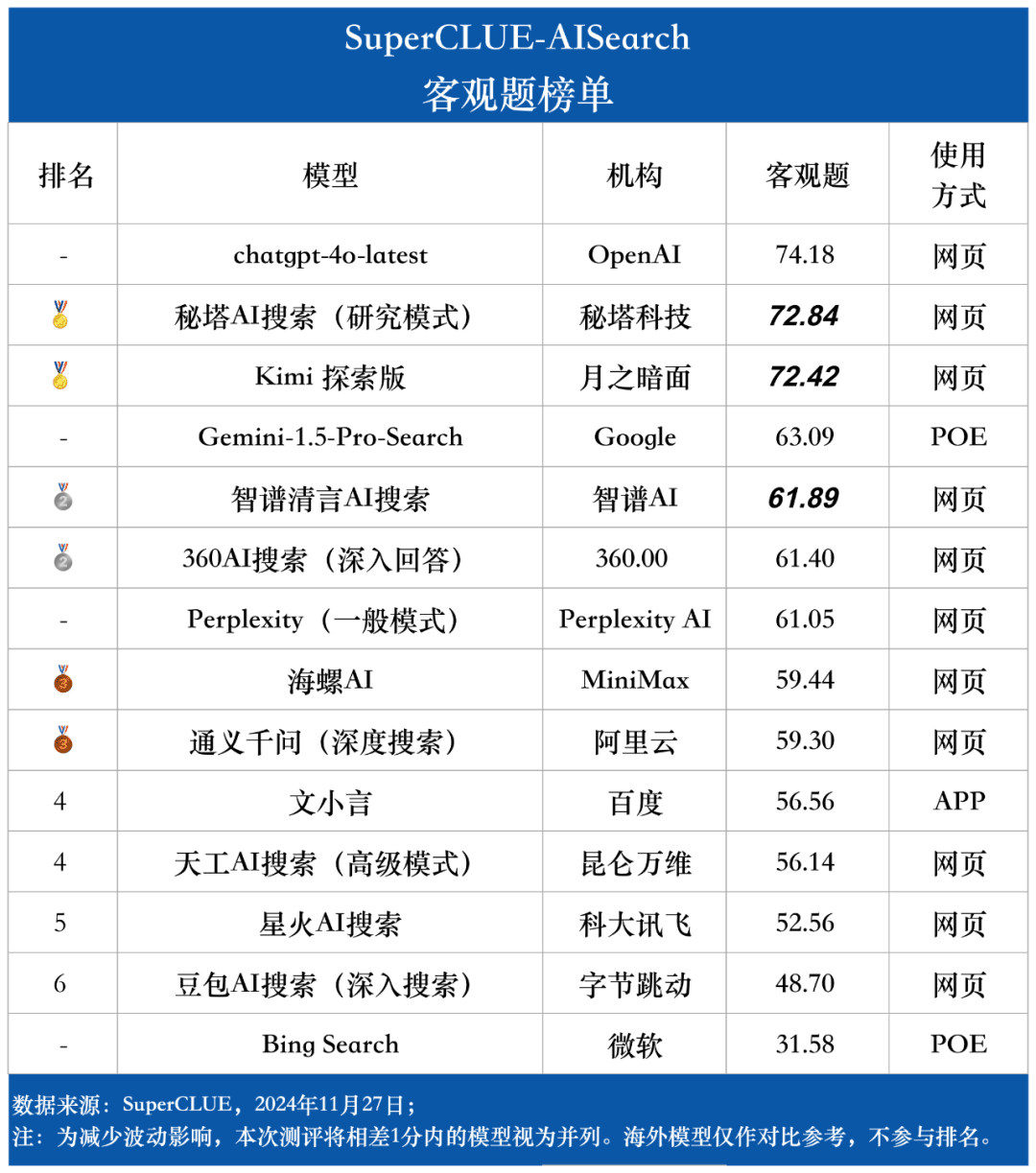
Ejemplo de comparación de modelos
Ejemplo 1 Competencias básicas: razonamiento y análisis
Pregunta: "¿Por qué se utiliza la estructura del modelo GPT-1? Transformador ¿En lugar de LSTM?"
Comparación de las respuestas de los modelos (sobre 5):
[Kimi Explorer]: 4 puntos 
[chatgpt-4o-latest]: 3,9 puntos 
[Skyworks AI Search (Modo avanzado)]: 3,4 puntos 
Ejemplo 2 Competencias básicas - vínculos transversales
PromptPrompt: "Por favor, ayúdame a averiguar cuáles son todas las aplicaciones de la tecnología de visión por ordenador en la agricultura y elige 3 de ellas y describe brevemente cada una."
Comparación de las respuestas de los modelos (sobre 5):
[Búsqueda de la IA en la Torre Secreta (Modo Investigación)]: 4 puntos 
[Wen Xiaoyan]: 3,4 puntos 
[Starfire AI Search]: 3 puntos 
Ejemplo 3 Aplicación del escenario - Acciones
PromptPrompt: "Por favor, dígame varios mercados alcistas importantes en acciones A en los últimos años y sus datos relacionados (por ejemplo, hora de inicio, duración, tasa de aumento, puntos más altos y más bajos, etc.)". Comparación de las respuestas de los modelos (sobre 5 puntos): [Gemini-1.5-Pro-Search]: 3,2 puntos 
[Smart Spectrum Clear Speech AI Search]: 3,3 puntos 
Bing Search]: 2,6 puntos 
Ejemplo 4 Escena Aplicación-Vida
Pregunta: "De enero a octubre de este año, la producción y las ventas de automóviles en China alcanzaron, respectivamente, cuántos millones de unidades, y en qué porcentaje aumentaron en comparación con el mismo periodo del año anterior".
Comparación de las respuestas de los modelos (sobre 5):
[Tongyi Mil Preguntas (búsqueda exhaustiva)]: 4,2 puntos 
[Búsqueda 360AI (respuesta en profundidad)]: 3,8 puntos 
Evaluación de la coherencia humana
Para garantizar la validez científica de la evaluación automatizada de grandes modelos, evaluamos la consistencia humana de GPT-4o-0513 en la tarea de evaluación de búsqueda de IA.
El método operativo específico es el siguiente: se seleccionan cinco modelos, y cada modelo es puntuado independientemente por una persona, respectivamente, para diferentes dimensiones de preguntas subjetivas y objetivas, y luego se pondera para promediar según los criterios de puntuación. Calculamos la diferencia entre las puntuaciones humanas y las puntuaciones de los modelos para cada pregunta y, a continuación, sumamos y promediamos para obtener la diferencia media de cada pregunta como resultado de la evaluación de la coherencia humana.
Los resultados medios finales obtenidos fueron los siguientes: El resultado medio de la varianza fue (en porcentaje): 5,1 puntos
Debido a la alta fiabilidad de esta evaluación automatizada.
Análisis de evaluación y conclusión
1.AI capacidad de búsqueda integral, chatgpt-4o-latest mantener el liderazgo.
Como se desprende de los resultados de la evaluación, chatgpt-4o-latest (73,41 puntos) tiene una capacidad global excelente y lidera la prueba comparativa SuperCLUE-AISearch. Sólo supera en 0,71 puntos al mejor modelo nacional, Kimi Explorer.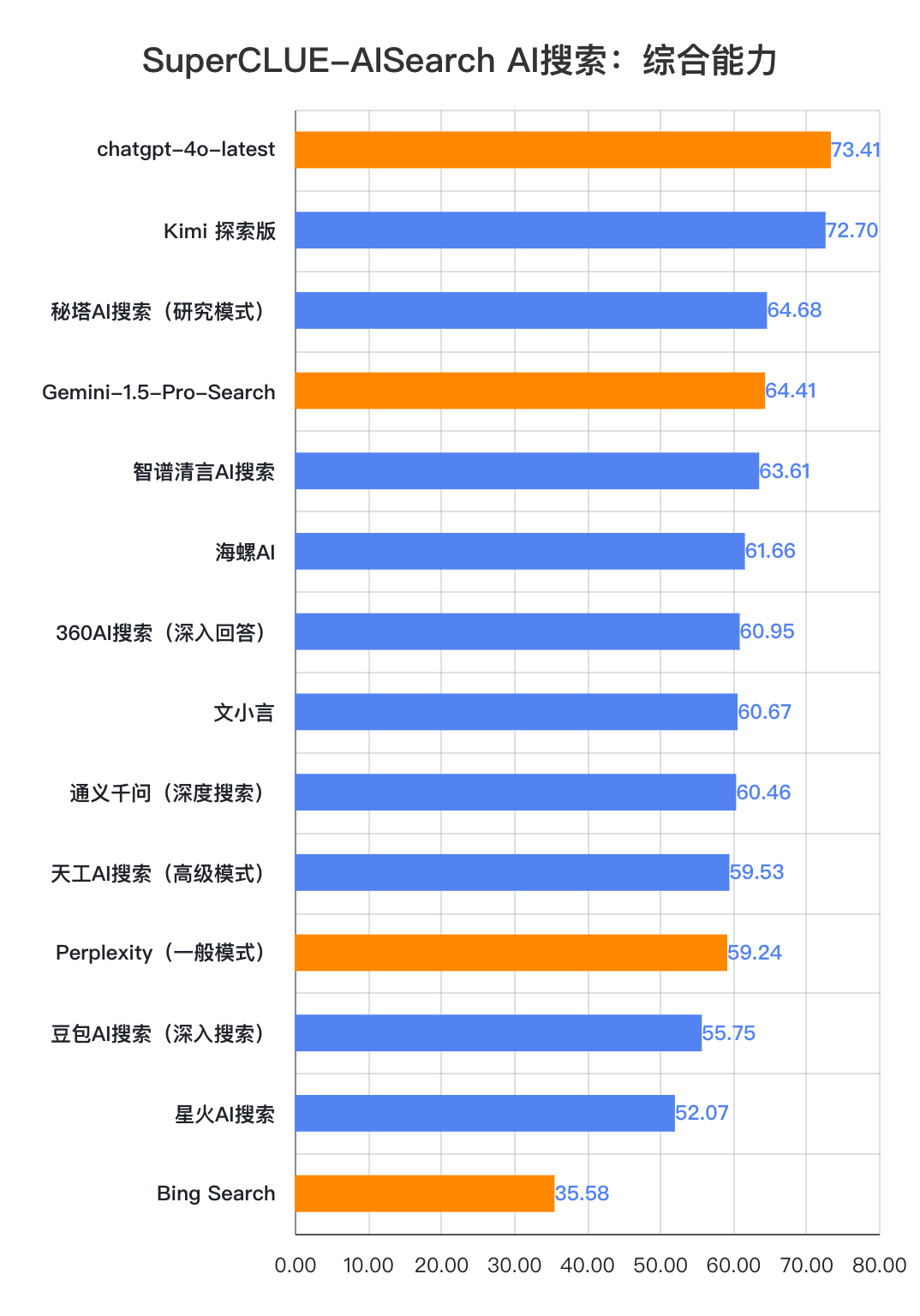
2. El rendimiento global de los grandes modelos domésticos es bastante impresionante, con diferencias relativamente pequeñas entre modelos.
A partir de los resultados de la evaluación, los modelos nacionales como Secret Tower AI Search (modelo de investigación), Wisdom Spectrum Clear Speech AI Search y Conch AI obtienen resultados relativamente buenos en términos de capacidades básicas, y tienen el impulso necesario para alcanzar al gran modelo extranjero Gemini-1.5-Pro-Search. En general, el rendimiento de varios modelos nacionales situados en la mitad de los resultados globales, como Conch AI, Wen Xiaoyin y Tongyi Qianqian (búsqueda profunda), no es comparable entre los modelos, mostrando una pequeña diferencia.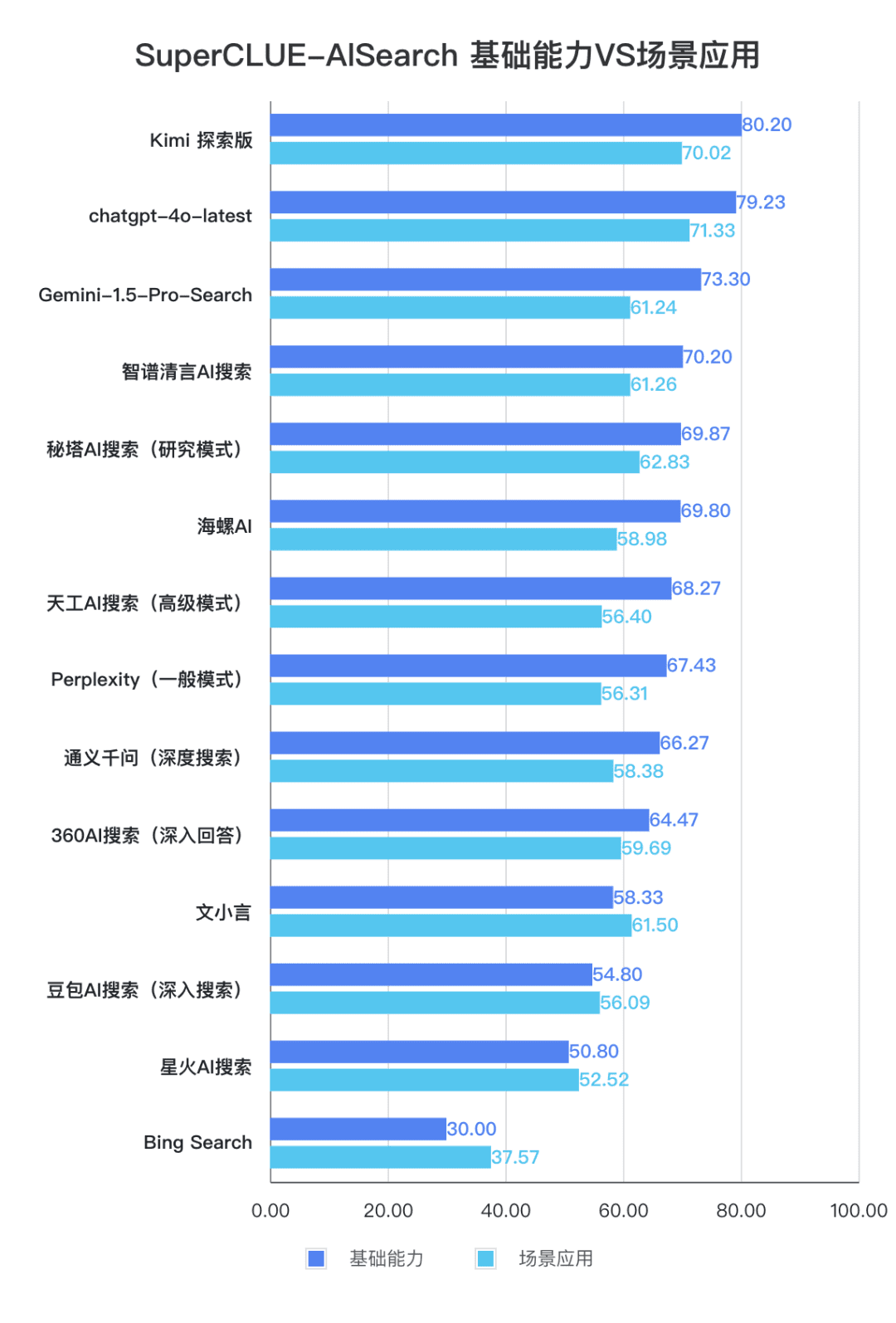
3. El modelo muestra diferentes niveles de rendimiento en diferentes aplicaciones de escenarios.
En el examen de la búsqueda por IA, nos centramos en el rendimiento de los modelos en distintos escenarios de aplicación. El modelo nacional de gran tamaño funciona relativamente bien en los ámbitos de la ciencia y la tecnología, la cultura, los negocios y el ocio, y puede captar con precisión la actualidad de la información, al tiempo que muestra una buena capacidad para recuperar e integrar información. Sin embargo, en los ámbitos bursátil y deportivo, los modelos nacionales de gran tamaño aún pueden mejorar.
Por ejemplo, en el proceso de búsqueda de IA, el modelo tiene que desmontar con precisión las necesidades de búsqueda del usuario, buscar las páginas web relevantes correctas con información precisa en función del tiempo y, por último, integrar la información para formar una copia de los resultados de la respuesta que tenga utilidad para el usuario. De la observación actual se desprende que los big models nacionales a veces no pueden analizar con precisión las necesidades de búsqueda y, en ocasiones, remiten a contenidos web irrelevantes en el proceso de integración de la información, lo que provoca el bajo rendimiento de los big models nacionales en determinados escenarios.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados




Sin comentarios...