¡AI full-stack herramienta de código abierto! ¡Tome usted con Ollama + Qwen2.5-Código runbolt.new, un clic para generar un sitio web!
Tutoriales prácticos sobre IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 43.4K 00

Las herramientas de programación de IA han estado muy de moda últimamente, desde Cursor, V0, Bolt.new y más recientemente Windsurf.
En este artículo, empezaremos hablando de la solución de código abierto Bolt.new, que ha generado unos ingresos de 4 millones de dólares en sólo cuatro semanas desde su lanzamiento.

El sitioLimitaciones de velocidad de acceso nacionalyEl cupo de fichas gratuitas es limitado.
Cómo hacerlo funcionar localmente para que más gente pueda utilizarlo y acelerar la llegada de la IA al terreno es la misión de Monkey.
La cuota de hoy.Le lleva a través de un gran modelo desplegado con Ollama local, la conducción bolt.newProgramación para la IA Ficha Libertad.
1. Introducción a Bolt.new
Perno.nuevo Se trata de una plataforma de codificación de IA basada en SaaS con inteligencias subyacentes basadas en LLM, combinada con la tecnología WebContainers, que permite codificar y ejecutar dentro del navegador, con las ventajas de:
- Desarrollo simultáneo de front-end y back-end.;
- Visualización de la estructura de carpetas del proyecto.;
- Entorno autoalojado con instalación automática de dependencias (por ejemplo, Vite, Next.js, etc.).;
- Ejecutar un servidor Node.js desde el despliegue hasta la producción
PernoEl objetivo de .new es hacer más accesible el desarrollo de aplicaciones web a un mayor número de personas, de modo que incluso los novatos en programación puedan materializar sus ideas mediante un lenguaje natural sencillo.
El proyecto ya es oficialmente de código abierto: https://github.com/stackblitz/bolt.new
Sin embargo, el código abierto oficial bolt.new tiene un soporte de modelos limitado, y muchos de nuestros socios nacionales no pueden llamar a la API LLM extranjera.
Hay un dios en la comunidad. bolt.new-any-llmEl apoyo local está disponible. Ollama echa un vistazo a continuación.
2. Despliegue local del código Qwen2.5
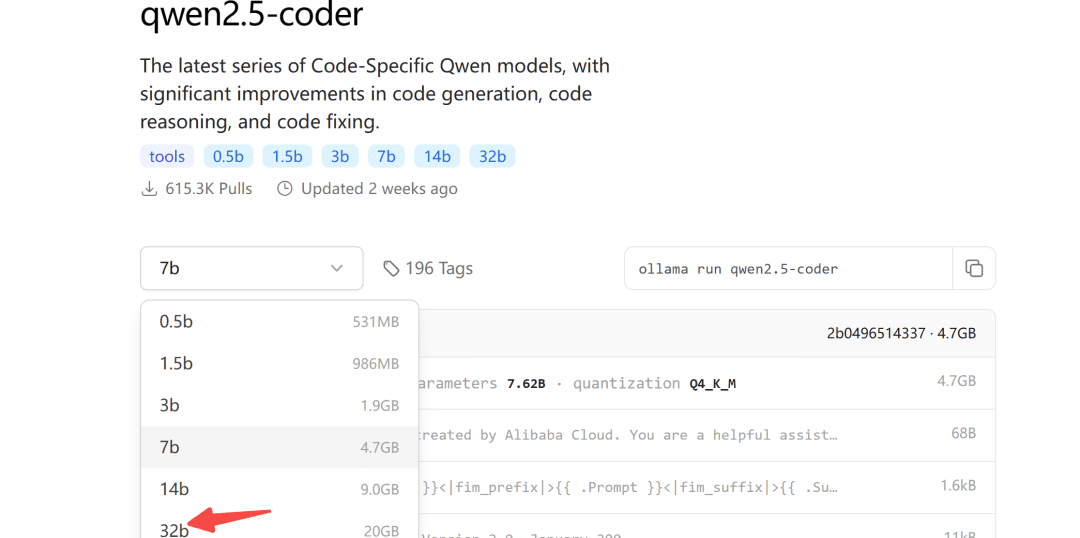
Hace algún tiempo, Ali puso en código abierto la serie de modelos Qwen2.5-Coder, de los cuales el modelo 32B ha obtenido los mejores resultados en código abierto en más de diez evaluaciones comparativas.
Merece ser el modelo de código abierto más potente del mundo, superando incluso al GPT-4o en una serie de capacidades clave.
El repositorio del modelo Ollama también está activo para qwen2.5-coder:
Ollama es una herramienta fácil de usar para desplegar grandes modelos.
2.1 Descarga de modelos
En cuanto al tamaño del modelo a descargar, puede elegirlo en función de su propia memoria de vídeo, se garantiza al menos 24G de memoria de vídeo para el modelo 32B.
A continuación lo demostramos con el modelo 7b:
ollama pull qwen2.5-coder
2.2 Modificaciones del modelo
Dado que la salida máxima por defecto de Ollama es de 4096 tokens, es claramente insuficiente para las tareas de generación de código.
Para ello, es necesario modificar los parámetros del modelo para aumentar el número de Token de contexto.
En primer lugar, cree un nuevo archivo Modelfile y rellénelo:
FROM qwen2.5-coder
PARAMETER num_ctx 32768
A continuación, comienza la transformación del modelo:
ollama create -f Modelfile qwen2.5-coder-extra-ctx
Tras una conversión correcta, vuelva a ver la lista de modelos:

2.3 Ejecuciones del modelo
Por último, compruebe en el lado del servidor si el modelo se puede llamar correctamente:
def test_ollama():
url = 'http://localhost:3002/api/chat'
data = {
"model": "qwen2.5-coder-extra-ctx",
"messages": [
{ "role": "user", "content": '你好'}
],
"stream": False
}
response = requests.post(url, json=data)
if response.status_code == 200:
text = response.json()['message']['content']
print(text)
else:
print(f'{response.status_code},失败')
Si no pasa nada, puedes llamarlo en bolt.new.
3. Bolt.new funcionando localmente
3.1 Despliegue local
paso1: Descarga bolt.new-any-llm que soporta modelos locales:
git clone https://github.com/coleam00/bolt.new-any-llm
paso2Haz una copia de las variables de entorno:
cp .env.example .env
paso3Modifica la variable de entorno aOLLAMA_API_BASE_URLSustitúyalo por el suyo:
# You only need this environment variable set if you want to use oLLAMA models
# EXAMPLE http://localhost:11434
OLLAMA_API_BASE_URL=http://localhost:3002
paso4: Instalar dependencias (con node instalado localmente)
sudo npm install -g pnpm # pnpm需要全局安装
pnpm install
paso5Funcionamiento con un solo clic
pnpm run dev
Ver la siguiente salida indica que el arranque fue exitoso:
➜ Local: http://localhost:5173/
➜ Network: use --host to expose
➜ press h + enter to show help
3.2 Demostración de los efectos
Abrir en el navegadorhttp://localhost:5173/Se selecciona el modelo tipo Ollama:
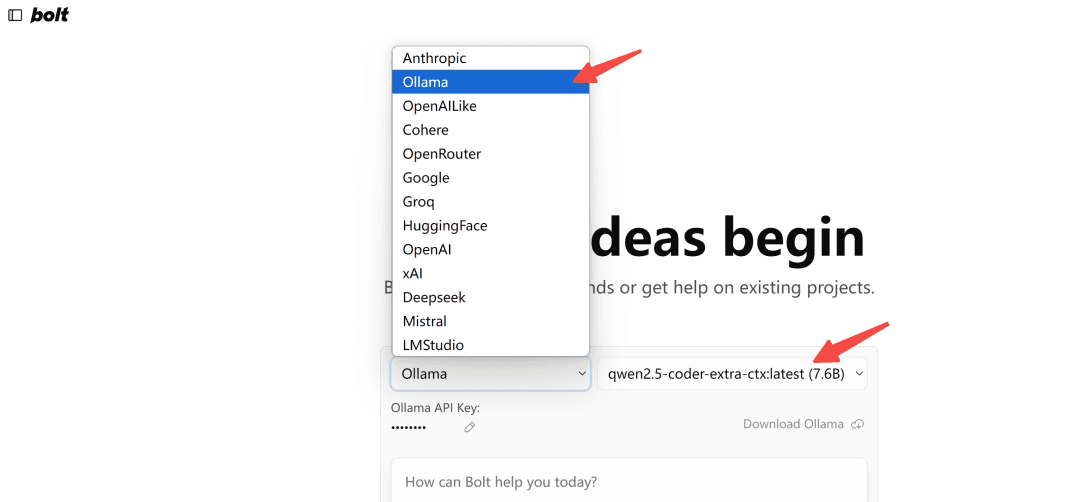
Nota: La primera vez que se cargue, si no aparece el modelo en Ollama, actualízalo unas cuantas veces para ver qué aspecto tiene.
Pongámoslo a prueba.
写一个网页端贪吃蛇游戏
A la izquierda.流程执行y a la derecha está el代码编辑zona, debajo de la cual se encuentra el终端Área. Escribir código, instalar dependencias, comandos de terminal... ¡la IA lo hace todo por ti!
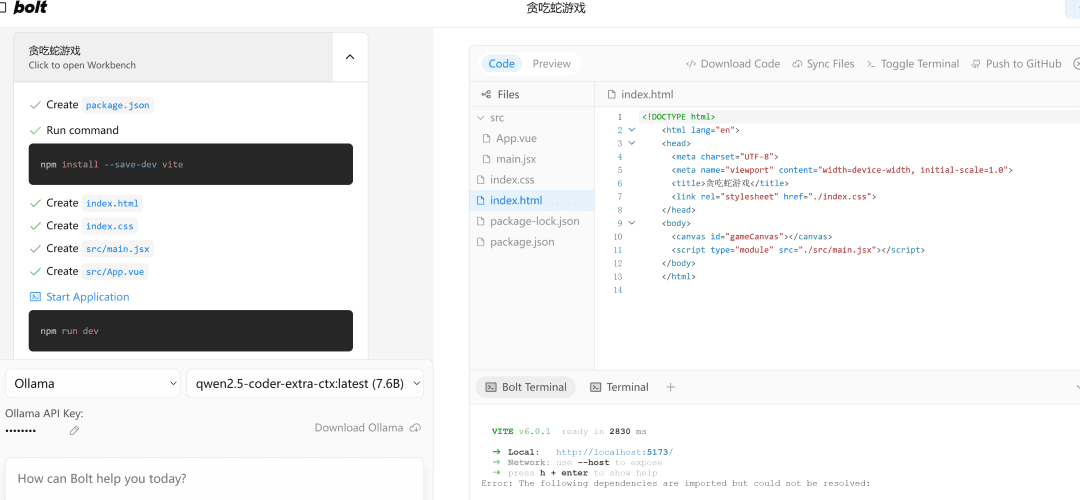
Si encuentra un error, simplemente lánzale el error, ejecútalo de nuevo, y si no hay nada mal, la parte derechaPreviewLa página se abrirá correctamente.
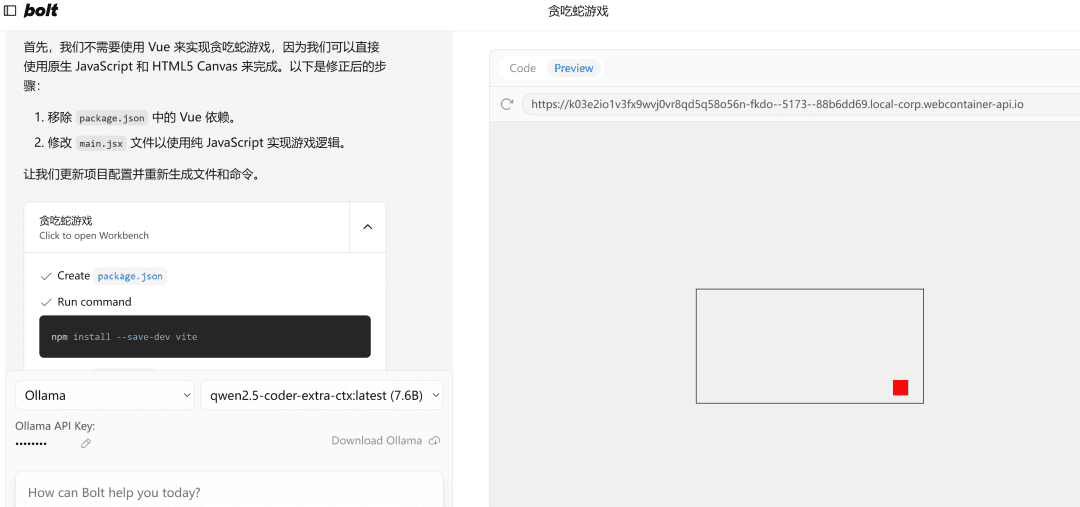
Nota: Dado que en el ejemplo se utiliza un modelo pequeño de 7b, si necesita probar a utilizar un modelo de 32b, los resultados mejorarán notablemente.
escribir al final
Este artículo te lleva a través de un despliegue local del modelo qwen2.5-code y maneja con éxito la herramienta de programación de IA bolt.new.
Utilizarlo para desarrollar el proyecto front-end sigue siendo bastante potente, por supuesto, para usarlo bien, conocer algunos conceptos básicos de front y back-end, será el doble de eficaz.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...