
La palabra "agente" es deprimente, los modelos GPT-4 ya no merecen mención y los grandes programadores hacen balance del "Gran Modelo 2024".

En general, los expertos coinciden en que 2024 será el año de la AGI. Es el año en que la industria de los grandes modelos cambia para siempre:
La GPT-4 de OpenAI ya no está fuera de nuestro alcance; los trabajos sobre modelos de generación de imágenes y vídeos son cada vez más realistas; se han logrado grandes avances en modelos de lenguaje multimodal, modelos de inferencia e inteligencias (agentes); y los humanos se preocupan cada vez más por la IA ......
Para un experto del sector, ¿cómo ha cambiado la industria de las grandes modelos a lo largo del año?
Hace unos días, el conocido programador independiente, cofundador del directorio de conferencias sociales Lanyrd y cocreador del framework web Django Simon Willison en el informe titulado Cosas que aprendimos sobre los LLM en 2024 El artículo examina en detalle la Cambios, sorpresas y carencias en la industria de los grandes modelos en 2024.

A continuación se exponen algunos puntos:
- En 2023, entrenar a un modelo clasificado GPT-4 es un gran logro. Sin embargo, en 2024, ni siquiera es un logro especialmente destacable.
- En el último año, hemos conseguido increíbles mejoras en la formación y el rendimiento de las inferencias.
- Hay dos factores que hacen bajar los precios: el aumento de la competencia y la mejora de la eficiencia.
- Quienes se quejan de la lentitud del LLM tienden a ignorar los grandes avances de la modelización multimodal.
- La generación de aplicaciones impulsada por la demanda se ha convertido en una mercancía.
- Atrás quedaron los días de acceso gratuito a los modelos SOTA.
- Intelligentsia, aún no ha nacido realmente.
- Escribir buenas evaluaciones automatizadas para sistemas basados en LLM es la habilidad más necesaria para construir aplicaciones útiles sobre estos modelos.
- o1 Nuevos enfoques de los modelos ampliados: resolver problemas más difíciles dedicando más cálculos a la inferencia.
- La normativa estadounidense sobre las exportaciones de GPU chinas parece haber inspirado algunas optimizaciones de formación muy eficaces.
- En los últimos años, el consumo de energía y el impacto ambiental del funcionamiento rápido se han reducido considerablemente.
- Los contenidos no solicitados ni censurados generados por inteligencia artificial son "bazofia".
- La clave para sacar el máximo partido del LLM es aprender a utilizar técnicas poco fiables pero poderosas.
- El LLM tiene un valor real, pero darse cuenta de ese valor no es intuitivo y requiere orientación.
Sin cambiar la orientación general del texto original, el contenido global se ha condensado del siguiente modo:
En 2024 están ocurriendo muchas cosas en el campo de la modelización de grandes lenguajes (LLM). He aquí una retrospectiva de lo que hemos descubierto en este campo en los últimos 12 meses, junto con mis intentos de identificar los temas y momentos clave. Incluye 19 Aspectos:
1. El foso de GPT-4 fue "violado".
En mi reseña de diciembre de 2023 escribí: "Aún no sabemos cómo construir GPT-4.-- En aquel momento, GPT-4 llevaba casi un año en el mercado, pero otros laboratorios de inteligencia artificial aún no habían creado un modelo mejor.
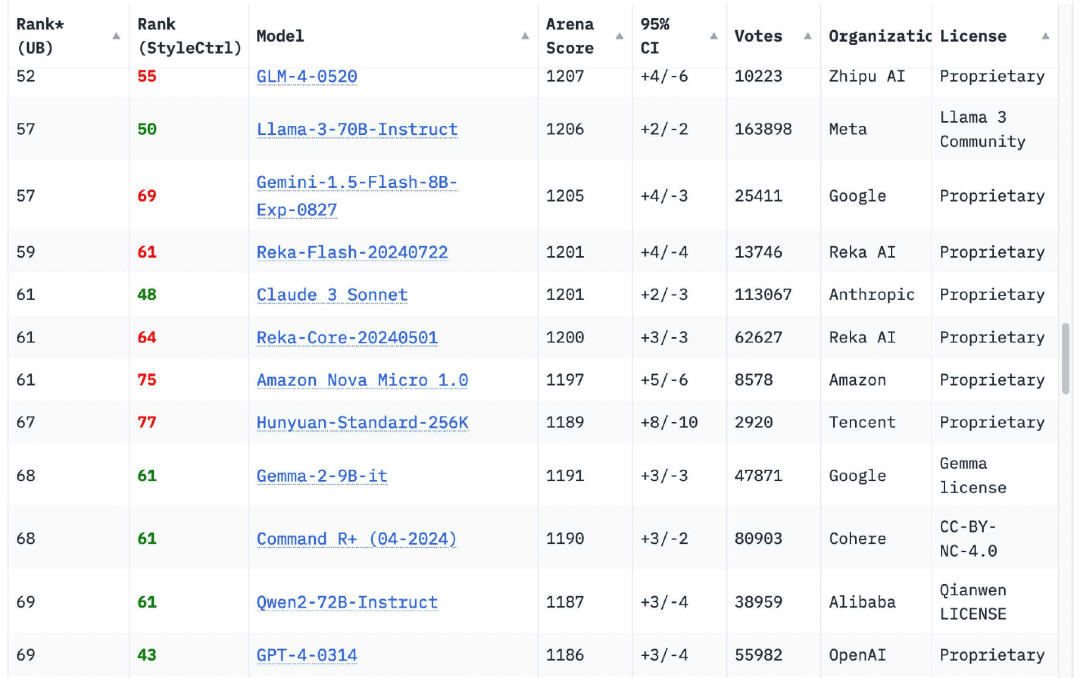
Para mi alivio, esto ha cambiado por completo en los últimos 12 meses. La clasificación de Chatbot Arena tiene ahoraModelos de 18 organizacionesEsta cifra, superior a la de la versión original de GPT-4 (GPT-4-0314) lanzada en marzo de 2023, alcanza el 70
El primer rival fue Google, que lanzó en febrero de 2024 el Géminis 1.5 Pro. Además de ofrecer una salida de nivel GPT-4, aporta varias funciones nuevas, entre ellas elLo más notable es la longitud del contexto de entrada de 1 millón de tokens (más tarde 2 millones), y la capacidad de introducir vídeo.
Gemini 1.5 Pro desencadena uno de los temas clave de 2024: el aumento de la longitud del contexto.En 2023, la mayoría de los modelos sólo podrán aceptar 4096 u 8192 fichasJamahiriya Árabe Libia Claude La excepción es el modelo 2.1, que acepta 200.000 fichas. En la actualidad, todos los proveedores de modelos aceptan más de 100.000 fichas. ficha la serie Gemini de Google puede aceptar hasta 2 millones de fichas.
Las entradas más largas aumentan enormemente la gama de problemas que se pueden resolver con LLM: ahora se puede teclear un libro entero y hacer preguntas sobre su contenido, pero lo que es más importante, se puede teclear una gran cantidad de código de ejemplo para ayudar al modelo a resolver correctamente el problema de codificación. Para mí, los casos de uso de LLM que implican entradas largas son mucho más interesantes que las preguntas cortas que se basan puramente en información sobre los pesos del modelo. Muchas de mis herramientas se basan en este modelo.
Pasando a los modelos que "superaron" al GPT-4: la serie Claude 3 de Anthropic se lanzó en marzo, y el Claude 3 Opus se convirtió rápidamente en mi modelo favorito. en junio, siguieron con el Claude 3.5 Sonnet, y seis meses después, ¡sigue siendo mi favorito! Seis meses después, sigue siendo mi favorito.
Por supuesto, hay otros. Si navegas hoy por la Chatbot Arena Leaderboard, verás que elGPT-4-0314 ha caído al puesto 70 aproximadamente.. Las 18 organizaciones con puntuaciones de modelo elevadas son Google, OpenAI, Alibaba, Anthropic, Meta, Reka AI, Zero One Thing, Amazon, Cohere, DeepSeek, NVIDIA, Mistral, NexusFlow, Smart Spectrum, xAI, AI21 Labs, la Universidad de Princeton y Tencent.
Formar a un modelo de nivel GPT-4 en 2023 es una gran cosa. Sin embargo, elEn 2024, ni siquiera es un logro digno de mención...pero personalmente sigo celebrando cada vez que una nueva organización se une a la lista.
2. Portátil, listo para ejecutar modelos de nivel GPT-4
Mi portátil personal es un MacBook Pro 2023 M2 de 64 GB. Es una máquina potente, pero también tiene casi dos años - y lo que es más importante, es el mismo portátil que he estado utilizando desde marzo de 2023, cuando ejecuté por primera vez LLM en mi propio ordenador.
En marzo de 2023, este portátil aún sólo podrá ejecutar un modelo de nivel GPT-3¡El modelo GPT-4 es ahora capaz de ejecutar múltiples modelos de nivel GPT-4!
Esto me sigue sorprendiendo. Creía que se necesitarían uno o varios servidores de centros de datos con GPU de más de 40.000 dólares para alcanzar la funcionalidad y calidad de salida de la GPT-4.
Los modelos ocupan 64 GB de mi memoria, así que no los ejecuto muy a menudo; no dejan mucho espacio para nada más.
El hecho de que funcionen es un testimonio de las increíbles mejoras en el rendimiento de la formación y la inferencia que hemos conseguido el año pasado. Hemos cosechado muchos frutos visibles en términos de eficacia de los modelos. Espero que haya más en el futuro.
Los modelos de la serie Llama 3.2 de Meta merecen una mención especial. Puede que no tengan clasificación GPT-4, pero en tamaños 1B y 3B muestran resultados que superan las expectativas.
3. Los precios de los LLM han bajado considerablemente gracias a la competencia y al aumento de la eficiencia
En los últimos doce meses, el coste del LLM se ha reducido drásticamente.
Diciembre de 2023, OpenAI cobra 30 $/millón de tokens de entrada por GPT-4(mTok) costesAdemás, se cobró una tasa de 10 USD/mTok por el GPT-4 Turbo, introducido entonces recientemente, y de 1 USD/mTok por el GPT-3.5 Turbo.
¡Hoy, el modelo o1 más caro de OpenAI está disponible por 30 $/mTok!La GPT-4o cuesta 2,50 dólares (12 veces más barata que la GPT-4), y la GPT-4o mini cuesta 0,15 dólares/mTok, casi siete veces más barata que la GPT-3.5 y más potente.
Otros proveedores de modelos cobran incluso menos, con el Claude 3 Haiku de Anthropic a 0,25 $/mTok, el Gemini 1.5 Flash de Google a 0,075 $/mTok, y el Gemini 1.5 Flash 8B a 0,0375 $/mTok, 27 veces más barato que el GPT-3.5 Turbo en 2023. Turbo en 2023.
Hay dos factores que hacen bajar los precios: el aumento de la competencia y la mejora de la eficiencia.. Las mejoras de la eficiencia son importantes para todos aquellos preocupados por el impacto medioambiental de la LLM. Estas reducciones de precios están directamente relacionadas con la energía consumida para hacer funcionar el sistema.
Todavía hay mucho de qué preocuparse en cuanto al impacto medioambiental de la construcción de centros de datos de IA, pero la preocupación por los costes energéticos de cada uno de ellos ya no es creíble.
Hagamos un cálculo interesante: ¿cuánto costaría generar descripciones breves para cada una de las 68.000 fotos de mi fototeca personal utilizando el Gemini 1.5 Flash 8B más barato de Google?
Cada foto requiere 260 fichas de entrada y unas 100 fichas de salida.
260 * 68000 = 17680000 Introducir ficha
17680000 * 0,0375 $/millón = 0,66
100 * 68000 = 6800.000 Ficha de salida
6800000 * 0,15 $/millón = 1,02 $.
El coste total de procesar 68.000 imágenes es de 1,68 $.. Era tan barato que incluso hice los cálculos tres veces para asegurarme de que los había hecho bien.
¿Qué tan buenas son estas descripciones? Obtuve la información de este comando:
llm -m gemini-1.5-flash-8b-latest describe -a IMG_1825.jpeg
Esta es una foto de una mariposa de la Academia de Ciencias de California:

En la foto hay un plato rojo poco profundo que podría ser un comedero para colibríes o mariposas. El plato tiene rodajas de fruta de color naranja.
Hay dos mariposas en el comedero, una es una mariposa marrón oscuro/negro con marcas blancas/crema. La otra era una mariposa marrón más grande con marcas de color marrón claro, beige y negro, incluidas manchas prominentes en los ojos. Esta mariposa marrón más grande parece estar comiendo fruta de un plato.
260 fichas de entrada, 92 fichas de salida, con un coste aproximado de 0,0024 céntimos (menos de la 400ª parte de un céntimo).
Mayor eficiencia y precios más bajos son mis tendencias favoritas para 2024.Quiero la utilidad de LLM a una fracción del coste energético, y eso es exactamente lo que estamos consiguiendo.
4. La visión multimodal se ha generalizado, el audio y el vídeo empiezan a "emerger
Mi ejemplo de la mariposa anterior también ilustra otra tendencia clave para 2024: el auge del Modelo Multimodal de Grandes Lenguajes (MLLM).
El GPT-4 Vision, lanzado hace un año en el DevDay de OpenAI en noviembre de 2023, es el ejemplo más notable de ello. Google, por su parte, lanzó Gemini 1.0 multimodal el 7 de diciembre de 2023.
En 2024, casi todos los proveedores de modelos han lanzado modelos multimodales.Lo vimos en marzo. Antrópico s Claude 3, vio el Gemini 1.5 Pro (imagen, audio y vídeo) en abril, y en septiembre vio el Mistral Pixtral 12B y los modelos visuales Llama 3.2 11B y 90B de Meta. Obtuvimos entradas y salidas de audio de OpenAI en octubre, SmolVLM de Hugging Face en noviembre, y modelos de imagen y vídeo de Amazon Nova en diciembre.
Creo.Quienes se quejan de la lentitud de los LLM suelen ignorar los grandes avances de estos modelos multimodales. La posibilidad de ejecutar preguntas a partir de imágenes (además de audio y vídeo) es una nueva y fascinante forma de aplicar estos modelos.
5. Modos de voz y vídeo en tiempo real para hacer realidad la ciencia ficción
En particular, empiezan a aparecer modelos de audio y vídeo en tiempo real.
junto con ChatGPT La función de diálogo debuta en septiembre de 2023, pero esto es en gran medida una ilusión: OpenAI utiliza su excelente Susurro modelo de voz a texto y un nuevo modelo de texto a voz (denominado tts-1) para permitir el diálogo con ChatGPT, pero el modelo real sólo puede ver texto.
El GPT-4o de OpenAI, publicado el 13 de mayo, incluye una demostración de un nuevo modelo de habla, el GPT-4o ("o" significa "omni"), un modelo verdaderamente multimodal que puede recibir señales de audio y producir un habla increíblemente realista sin necesidad de un modelo TTS o STT independiente. sin necesidad de un modelo TTS o STT independiente.
Cuando por fin se introdujo el modo de voz avanzado de ChatGPT, los resultados fueron sorprendentes.Suelo utilizar este modo cuando paseo a mi perro y el tono ha mejorado tanto que es increíble.. También me he divertido mucho utilizando la API de audio OpenAI.
OpenAI no es el único equipo con un modelo de audio multimodal. Gemini, de Google, también acepta entradas de audio y además puede hablar de forma similar a ChatGPT. Amazon también anunció un modelo de voz para Amazon Nova antes de lo previsto, pero ese modelo estará disponible en el primer trimestre de 2025.
Google CuadernoLM Lanzado en septiembre, llevó la salida de audio a un nuevo nivel, con dos "anfitriones de podcast" que podían mantener conversaciones realistas sobre cualquier cosa que escribieras, y más tarde añadió comandos personalizados.
El cambio más reciente, también de diciembre, es el vídeo en tiempo real.El modo de voz ChatGPT ofrece ahora la opción de compartir imágenes de la cámara con modelos y hablar sobre lo que se está viendo en tiempo real. Gemini, de Google, también ha lanzado una versión preliminar con las mismas funciones.
6. la generación de aplicaciones impulsada por la rapidez, que se ha convertido en una mercancía
GPT-4 ya puede conseguirlo en 2023, pero su valor sólo se hace patente en 2024.
LLM es conocido por tener un talento asombroso para escribir código. Si puedes escribir un prompt correctamente, pueden construirte una aplicación interactiva completa usando HTML, CSS y JavaScript, a menudo en un solo prompt.
Anthropic llevó esta idea al siguiente nivel con el lanzamiento de Claude ArtifactsArtifacts es una nueva característica innovadora. Con Artifacts, Claude puede escribir una aplicación interactiva bajo demanda para ti y luego permitirte usarla directamente en la interfaz de Claude.
Se trata de una app para extraer URLs, generada íntegramente por Claude:
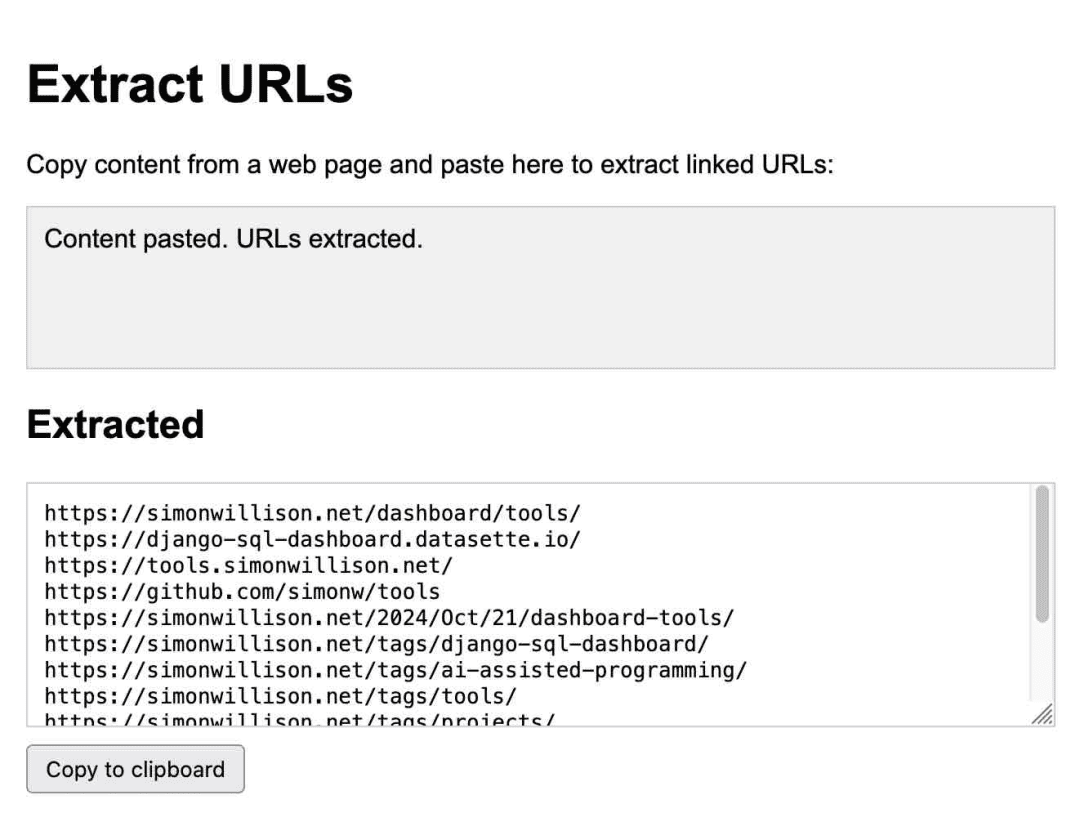
Lo utilizo con regularidad. En octubre me di cuenta de lo mucho que dependía de él, laHe creado 14 gadgets en siete días con Artifacts..

Desde entonces, muchos otros equipos han creado sistemas similares y, en octubre, GitHub publicó su versión, GitHub Spark, y en noviembre, Mistral Chat lo añadió como una función llamada Canvas.
Steve Krause de Val Town respondió a Cerebras Se construyó una versión para mostrar cómo LLM con 2000 tokens por segundo puede iterar la aplicación y ver los cambios en menos de un segundo.
En diciembre, el equipo de Chatbot Arena lanzó una nueva tabla de clasificación para esta función, en la que los usuarios crean la misma aplicación interactiva dos veces utilizando dos modelos diferentes y votan las respuestas. Sería difícil argumentar de forma más convincente que esta función es ahora un producto básico que puede competir eficazmente con todos los modelos líderes.
He estado dándole vueltas a esta versión para mi proyecto Datasette, con el objetivo de permitir a los usuarios utilizar prompt para construir e iterar sobre gadgets personalizados y visualizar datos basados en sus propios datos. También he encontrado un patrón similar para escribir programas de Python a través de uv.
Este tipo de interfaz personalizada es tan potente y fácil de crear (una vez que se entienden los entresijos del sandboxing del navegador) que espero que aparezca como función en una gran variedad de productos de aquí a 2025.
7. En pocos meses se han popularizado modelos potentes
Dentro de unos meses, en 2024, los modelos más potentes estarán disponibles gratuitamente en la mayoría de los países del mundo.
OpenAI puso GPT-4o a disposición de todos los usuarios en mayo, mientras que Claude 3.5 Sonnet pasó a ser gratuito con su lanzamiento en junio. Se trata de un cambio significativo, ya que durante el último año los usuarios gratuitos sólo han podido utilizar modelos del nivel GPT-3.5, lo que en el pasado habría provocado una falta de claridad para los nuevos usuarios sobre las capacidades reales del LLM.
Con el lanzamiento de ChatGPT Pro de OpenAI, la era parece haber terminado, ¡probablemente de forma permanente!Esta suscripción de 200 $/mes es la única forma de acceder a su modelo más potente, el o1 Pro. Este servicio de suscripción de 200 $/mes es la única forma de acceder a su modelo más potente, el o1 Pro.
La clave de la serie o1 (y de los futuros modelos que sin duda la inspirarán) es dedicar más tiempo de cálculo para obtener mejores resultados. Como tal, creo que los días de acceso gratuito a los modelos SOTA han pasado.
8. Cuerpos inteligentes, aún no han nacido realmente
En mi opinión personal.La palabra "agente" es muy frustrante.. Carece de un significado único, claro y ampliamente comprendido ...... Pero los que utilizan el término nunca parecen reconocerlo.
Si me dice que está construyendo un "agente", entonces no me está comunicando nada. Sin leer tu mente, no tengo forma de saber a cuál de las docenas de posibles definiciones te refieres.
Veo dos tipos principales de personasUn grupo considera que un agente es obviamente algo que actúa en tu nombre -un agente viajero- y el otro piensa que un agente es un LLM con acceso a herramientas que se pueden ejecutar en bucle como parte de un problema. También se habla mucho de "autonomía", pero sin una definición clara. (Hace unos meses, incluso tuiteé una colección de 211 definiciones de agente, y gemini-exp-1206 intentó resumirlas).
Sea cual sea el significado del término.Agente, sigue habiendo una sensación de perpetuo "muy pronto".. Terminología aparte.Sigo siendo escéptico sobre su viabilidad.Se trata de un reto basado en la credulidad: los LLM creerán cualquier cosa que se les diga. Cualquier sistema que intente tomar decisiones significativas en tu nombre se topa con el mismo obstáculo: ¿qué utilidad tiene una agencia de viajes, un asistente digital o incluso una herramienta de investigación si no puede distinguir entre lo que es verdad y lo que es mentira?
Hace tan sólo unos días, en una búsqueda en Google se encontró una descripción completamente falsa de la inexistente película Encanto 2.
La inyección a tiempo es una consecuencia natural de esta credulidad. Veo muy pocos avances en 2024 para abordar esta cuestión, que llevamos debatiendo desde septiembre de 2022
Los ataques de inyección puntual son una consecuencia natural de esta "credulidad". Veo pocos avances en la industria en 2024 para abordar esta cuestión, que llevamos debatiendo desde septiembre de 2022.
Empiezo a pensar que el concepto de agente más popular se basará en la AGI.Hacer que los modelos sean resistentes a la "credulidad" es mucho pedir..
9. Evaluación, muy importante
Amanda Askell de Anthropic (para Claude's). Carácter la mayor parte del trabajo que hay detrás) había dicho:
Hay un secreto aburrido pero vital detrás de un buen aviso del sistema, y es el desarrollo basado en pruebas. No escribes un aviso del sistema y luego averiguas cómo probarlo. Escribes pruebas, y luego encuentras un aviso del sistema que pase esas pruebas.
En el transcurso de 2024, ha quedado meridianamente claro que laEscribir excelentes autoevaluaciones para sistemas basados en LLMes la habilidad más necesaria para crear aplicaciones útiles a partir de estos modelos. Si dispone de un conjunto de evaluación sólido, podrá adoptar nuevos modelos más rápido que sus competidores, iterar mejor y crear funciones de producto más fiables y útiles.
En opinión de Malte Ubl, Director de Tecnología de Vercel:
Cuando se introdujo por primera vez v0 (un agente de desarrollo web), estábamos paranoicos con la protección de los avisos con todo tipo de complejos preprocesamientos y postprocesamientos.
Nos hemos volcado por completo en dejarlo correr libremente. Sin evaluación, modelado, y sobre todo UX indicaciones son como una máquina ASML roto sin instrucciones.
Sigo intentando encontrar un modelo mejor para mi propio trabajo. Todo el mundo sabe que las evaluaciones son importantes, pero para elSiguen faltando orientaciones adecuadas sobre la mejor manera de realizar la evaluación..
10. ¡La Inteligencia de Apple apesta, pero MLX es genial!
Como usuario de Mac, ahora me siento mucho mejor con la plataforma que he elegido.
En 2023, siento que no tengo una máquina Linux/Windows con una GPU NVIDIA, lo que es una gran desventaja para probar nuevos modelos.
En teoría, un Mac de 64 GB debería ser una buena máquina para ejecutar modelos porque la CPU y la GPU pueden compartir la misma cantidad de memoria. En la práctica, muchos modelos se publican como pesos de modelos y bibliotecas, y se favorece CUDA de NVIDIA frente a otras plataformas.
llama.cpp El ecosistema ayudó mucho, pero el verdadero avance fue la biblioteca MLX de Apple, que es fantástica.
El soporte mlx-lm Python de Apple ejecuta una variedad de modelos compatibles con mlx en mi Mac con un rendimiento excelente. la comunidad mlx en Hugging Face proporciona más de 1000 modelos que han sido convertidos a los formatos necesarios. el proyecto mlx-vlm del príncipe Canuma es excelente y avanza rápidamente, y también ha traído LLM visual a Apple El proyecto mlx-vlm de Prince Canuma es excelente y avanza rápidamente, y también ha llevado los LLM visuales a Apple Silicon.
Mientras que MLX supuso un cambio en las reglas del juego, las funciones de Apple Intelligence de Apple fueron en su mayoría decepcionantes.. Escribí un artículo sobre su lanzamiento inicial en junio, y en ese momento me mostré optimista de que Apple se hubiera centrado en proteger la privacidad de los usuarios y minimizar el engaño a los usuarios sobre las aplicaciones LLM.
Ahora que estas funciones están disponibles, siguen siendo relativamente ineficaces. Como gran usuario de LLM, sé de lo que son capaces estos modelos, y las funciones de LLM de Apple no son más que una pálida imitación de las funciones de vanguardia de LLM. En su lugar, obtenemos resúmenes de notificaciones que desvirtúan los titulares de las noticias, y ni siquiera creo que la herramienta Asistente de escritura sea útil en absoluto. Aun así, Genmoji es bastante divertido.
11. El escalado de la inferencia, el auge de los modelos de "razonamiento
El acontecimiento más interesante del último trimestre de 2024 fue la aparición de una nueva morfología LLM, ejemplificada por los modelos o1 de OpenAI: o1-preview y o1-mini se publicaron el 12 de septiembre. Una forma de entender estos modelos es como una extensión de la técnica de la cadena de pensamiento.
El truco consiste principalmente en queSi se consigue que un modelo piense detenidamente (que hable en voz alta) sobre el problema que está resolviendo, normalmente se obtendrá un resultado que el modelo no habría podido obtener de otra forma..
o1 integra este proceso en el modelo. Los detalles son un poco confusos: el modelo o1 gasta "tokens de razonamiento" para pensar sobre el problema, que el usuario no puede ver directamente (aunque la interfaz de ChatGPT mostrará un resumen), y luego emite el resultado final.
La mayor innovación aquí es que abre una nueva forma de ampliar el modelo: ahora los modelos pueden resolver problemas más difíciles dedicando más esfuerzo computacional a la inferencia, laEn lugar de mejorar el rendimiento del modelo únicamente aumentando la cantidad de cálculo en el momento del entrenamiento.
El sucesor de o1, o3, salió a la venta el 20 de diciembre y obtuvo unos resultados impresionantes en las pruebas de ARC-AGI, ¡a pesar de que los costes de tiempo de cálculo podrían haber superado el millón de dólares!
El lanzamiento de o3 está previsto para enero. Dudo que haya mucha gente con problemas reales que se beneficiarían de este nivel de gasto computacional, ¡yo desde luego no! Pero parece ser un verdadero siguiente paso en la arquitectura LLM para resolver problemas más difíciles.
OpenAI no es el único participante. El 19 de diciembre, Google lanzó su primer producto en este ámbito: gemini-2.0-flash-thinking-exp.
El equipo Qwen de Alibaba publicó el modelo QwQ el 28 de noviembre bajo la licencia Apache 2.0. Posteriormente, el 24 de diciembre, publicó el modelo de inferencia visual QvQ. El 24 de diciembre publicaron un modelo de inferencia visual llamado QvQ.
DeepSeek El modelo DeepSeek-R1-Lite-Preview se puso a prueba a través de la interfaz de chat el 20 de noviembre.
Nota del editor: Wisdom Spectrum también se publicó el último día de 2024.Modelos de razonamiento profundo GLM-Zero.
Anthropic y Meta aún no han avanzado nada, pero me sorprendería mucho que no tuvieran su propio modelo de extensión de inferencias.
12. ¿Se forma actualmente el mejor LLM en China??
No exactamente, pero casi. Es un gran titular que llama la atención.
DeepSeek v3 es un enorme modelo paramétrico de 685B - uno de los mayores modelos con licencia pública disponibles, y mucho mayor que el mayor de la familia Llama de Meta, Llama 3.1 405B.
Los análisis comparativos muestran que está a la altura del Claude 3.5 Sonnet, y los análisis comparativos de Vibe lo sitúan actualmente en el puesto 7, por detrás de los modelos Gemini 2.0 y OpenAI 4o/o1. Se trata del modelo con licencia pública mejor clasificado hasta la fecha.
Lo realmente impresionante es queDeepSeek v3Costes de formaciónEl modelo se entrenó en 2788000 horas GPU H800 con un coste estimado de 5576000 dólares. El modelo se entrenó en 2788000 horas de GPU H800 con un coste estimado de 5576000 dólares.Llama 3.1 405B se entrenó en 30840000 horas de GPU, 11 veces más que DeepSeek v3, pero el rendimiento de referencia del modelo fue algo peor.
La normativa estadounidense sobre las exportaciones de GPU chinas parece haber inspirado algunas optimizaciones de formación muy eficaces.
13. Se mejora el impacto ambiental de los avisos de funcionamiento.
Tanto si se trata de un modelo alojado como de uno que ejecuto localmente, uno de los gratos resultados del aumento de la eficiencia es que el consumo de energía y el impacto medioambiental del funcionamiento rápido se han reducido considerablemente en los últimos años.
Las tarifas de OpenAI son 100 veces inferiores a las de GPT-3 en ese momento.Sé de buena tinta que ni Google Gemini ni Amazon Nova (los dos proveedores de modelos más baratos) funcionan con pérdidas.
Esto significa que, como usuarios individuales, no tenemos que sentirnos culpables en absoluto por la energía que consume la gran mayoría de los avisos. Comparado con conducir por la calle, o incluso con ver un vídeo en YouTube, el impacto puede ser insignificante.
Lo mismo ocurre con la formación. La formación de deepSeek v3 cuesta menos de 6 millones de dólares, lo que es una muy buena señal de que los costes de formación pueden y deben seguir bajando.
14. ¿Siguen siendo necesarios los nuevos centros de datos?
Y el problema mayor es que habrá una importante presión competitiva para construir la infraestructura que estos modelos necesitarán en el futuro.
Empresas como Google, Meta, Microsoft y Amazon están gastando miles de millones de dólares en nuevos centros de datos, lo que está teniendo un enorme impacto en la red eléctrica y el medio ambiente. Se habla incluso de construir nuevas centrales nucleares, pero eso llevará décadas.
¿Es necesaria esta infraestructura? Los 6 millones de dólares que costó la formación de DeepSeek v3 y la continua reducción de los precios de los LLM pueden bastar para afirmarlo. Pero, ¿le gustaría ser el gran ejecutivo tecnológico que argumentó en contra de esta infraestructura, para que unos años más tarde se demostrara que estaba equivocado?
Un contraste interesante es el desarrollo de los ferrocarriles en todo el mundo en el siglo XIX. La construcción de estos ferrocarriles requirió enormes inversiones, tuvo un gran impacto en el medio ambiente y muchas de las líneas construidas resultaron innecesarias.
Las burbujas resultantes provocaron varios colapsos financieros, y nos dejaron muchas infraestructuras útiles y muchas quiebras y daños medioambientales.
15.2024, el año de la "bazofia"
2024 es el año en que la palabra "bazofia" se convierte en un término de arte. escribió @deepfates en twitter:
Al igual que "spam" se convirtió en el nombre propio del correo electrónico no deseado, "slop" aparecerá en el diccionario como el nombre propio de los contenidos no deseados generados por la IA.
En mayo escribí un post en el que ampliaba un poco esta definición:
"Slop" se refiere a contenidos no solicitados ni censurados generados por inteligencia artificial.
Me gusta la palabra "bazofia" porque resume sucintamente una de las formas en que no deberíamos utilizar la IA generativa.
16. Datos de entrenamiento sintéticos, muy eficaces
Sorprendentemente, la noción de "colapso del modelo" -es decir, que los modelos de IA se rompen cuando se entrenan con datos generados recursivamente- parece estar profundamente arraigada en la conciencia pública. .
La idea es seductora: a medida que la "bazofia" generada por la IA inunde Internet, los propios modelos se degradarán, alimentándose de su propia producción y conduciendo a su inevitable desaparición.
Obviamente, esto no ocurrió. En su lugar, vemos cómo los laboratorios de IA se entrenan cada vez más en contenidos sintéticos, creando datos artificiales que ayudan a dirigir sus modelos en la dirección correcta.
Una de las mejores descripciones que he visto procede del informe técnico Phi-4A continuación se enumeran algunos de los elementos del programa:
Los datos sintéticos son cada vez más habituales como parte importante del preentrenamiento, y la familia de modelos Phi siempre ha hecho hincapié en la importancia de los datos sintéticos. En lugar de ser una alternativa barata a los datos reales, los datos sintéticos tienen varias ventajas directas sobre los datos reales.
Aprendizaje progresivo estructurado. En los conjuntos de datos reales, las relaciones entre los tokens suelen ser complejas e indirectas. Pueden ser necesarios muchos pasos de inferencia para asociar el token actual con el siguiente, lo que dificulta que el modelo aprenda eficazmente de la predicción del siguiente token. En cambio, cada token generado por un modelo lingüístico se predice a partir del token anterior, lo que facilita que el modelo siga el patrón de inferencia resultante.
Otra técnica habitual consiste en utilizar modelos más grandes para ayudar a crear datos de entrenamiento para modelos más pequeños y menos costosos, y cada vez son más los laboratorios que utilizan esta técnica.
DeepSeek v3 utiliza DeepSeek-R1 Datos de "inferencia" creados.El ajuste fino Llama 3.3 70B de Meta utiliza más de 25 millones de ejemplos generados sintéticamente.
El diseño cuidadoso de los datos de entrenamiento utilizados para el LLM parece ser la clave para crear estos modelos. Atrás quedaron los días en los que se cogían todos los datos de la web y se introducían indiscriminadamente en las series de entrenamiento.
17. ¡Utilizar correctamente el LLM no es fácil!
Siempre he insistido en que los LLM son potentes herramientas para el usuario: son motosierras disfrazadas de helicópteros. Parecen fáciles de usar: ¿tan difícil puede ser introducir información en un chatbot? Pero en realidad.Para sacarles el máximo partido y evitar sus numerosos escollos, hay que conocerlos a fondo y tener mucha experiencia con ellos.
Este problema se agrava aún más en 2024.
Hemos construido sistemas informáticos a los que se puede hablar en lenguaje humano que pueden responder a tus preguntas, ¡y normalmente aciertan! ...... Depende de cuál sea la pregunta, de cómo se formule y de si puede reflejarse con precisión en un conjunto de entrenamiento secreto no registrado.
Hoy en día, el número de sistemas disponibles está proliferando. Los diferentes sistemas tienen diferentes herramientas que se pueden utilizar para resolver tu problema, como Python, JavaScript, búsqueda web, generación de imágenes, e incluso consultas a bases de datos ....... Así que es mejor que entiendas qué son estas herramientas, qué pueden hacer y cómo saber si LLM las está utilizando.
¿Sabías que ChatGPT tiene ahora dos formas completamente diferentes de ejecutar Python?
Si quieres construir un artefacto Claude que hable con una API externa, es una buena idea aprender sobre las cabeceras HTTP CSP y CORS.
Las capacidades de estos modelos pueden haber mejorado, pero la mayoría de las limitaciones permanecen. o1 de OpenAI puede finalmente ser capaz de (en su mayoría) calcular la "r" en fresa, pero sus capacidades siguen estando limitadas por su naturaleza como un LLM, y por sus arneses de tiempo de ejecución. o1 no puede hacer búsquedas en la web o utilizar un intérprete de código, pero GPT-4o puede - ambos están en la misma ChatGPT UI. GPT-4o puede - ambos están en el mismo ChatGPT UI.
¿Qué hemos hecho al respecto? Nada. La mayoría de los usuarios son "novatos". La interfaz de chat por defecto de LLM es como poner a un usuario novato en un terminal Linux y esperar que se encargue de todo por sí mismo.
Al mismo tiempo, cada vez es más común que los usuarios finales desarrollen modelos mentales inexactos de cómo funcionan estos dispositivos. He visto muchos ejemplos de esto, con personas que intentan ganar discusiones con capturas de pantalla de ChatGPT, lo cual es una propuesta absurda, dada la falta de fiabilidad inherente de estos modelos, junto con el hecho de que puedes conseguir que digan cualquier cosa si les das la indicación correcta.
La otra cara de la moneda es que muchos "veteranos" han abandonado por completo el LLM porque no entienden cómo puede alguien beneficiarse de una herramienta que tiene tantos defectos. La clave para sacar el máximo partido de LLM es aprender a utilizar esta técnica poco fiable pero poderosa. Está claro que no se trata de una habilidad obvia.
Aunque existen muchos contenidos educativos útiles, tenemos que hacer algo mejor que subcontratarlos a los farsantes de la IA que tuitean y despotrican sobre ellos.
18. Poca cognición, aún presente
Ahora.La mayoría de la gente ha oído hablar de ChatGPT, pero ¿cuántos han oído hablar de Claude?
Entre los que se preocupan activamente por estas cuestiones y los 99% que no, hay unLa gran brecha del conocimiento.
El mes pasado vimos la popularidad de las interfaces en tiempo real, en las que puedes apuntar con la cámara de tu teléfono a algo y hablar de ello con una voz ....... También existe la opción de hacerlo pasar por Papá Noel. La mayoría de los autodidactas (sic "nerd") aún no lo han probado.
Teniendo en cuenta el impacto continuo (y potencial) de esta tecnología en la sociedad, creo que la actualEsta división no es saludable. Me gustaría ver más esfuerzos para mejorar la situación.
19.LLM, se necesitan mejores críticas
Mucha gente odia de verdad los LLM. En algunos de los sitios que frecuento, incluso la sugerencia de que "el LLM es muy útil" basta para iniciar una guerra.
Lo comprendo. Hay muchas razones por las que a la gente no le gusta esta tecnología: impacto medioambiental, falta de fiabilidad de los datos de formación, aplicaciones poco positivas, impacto potencial en los puestos de trabajo de las personas.
LLM sin duda merece críticas.Tenemos que debatir estas cuestiones, encontrar formas de mitigarlas y ayudar a la gente a aprender a utilizar estas herramientas de forma responsable para que sus aplicaciones positivas compensen sus efectos negativos.
Me encanta la gente escéptica sobre esta tecnología. Desde hace más de dos años, el bombo ha crecido y mucha desinformación ha inundado las ondas. Se han tomado muchas decisiones equivocadas basadas en este bombo.La crítica es una virtud.
Si queremos que las personas con poder de decisión tomen las decisiones correctas sobre cómo aplicar estas herramientas, primero tenemos que reconocer que existen realmente buenas aplicaciones, y luego ayudar a explicar cómo ponerlas en práctica evitando muchos de los escollos no prácticos.
Creo.Decirle a la gente que todo el campo es una máquina de plagio ambientalmente desastrosa que inventa cosas constantemente, sin importar cuánta verdad represente, es un flaco favor para estas personas.. Aquí hay un valor real, pero darse cuenta de ese valor no es intuitivo y requiere orientación.
Los que entendemos de estas cosas tenemos la responsabilidad de ayudar a los demás a entenderlas.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...