Xiaomi-MiMo-Audio - Xiaomi Open Source's First Native End-to-End Speech Big Model

What is Xiaomi-MiMo-Audio?
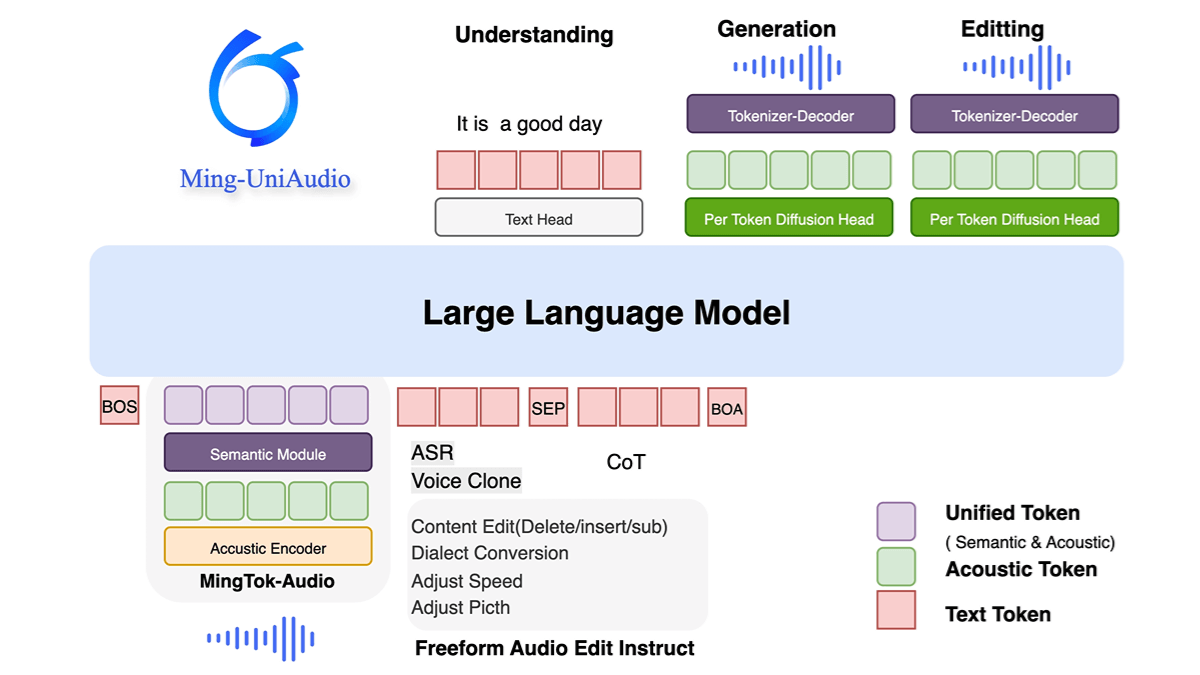
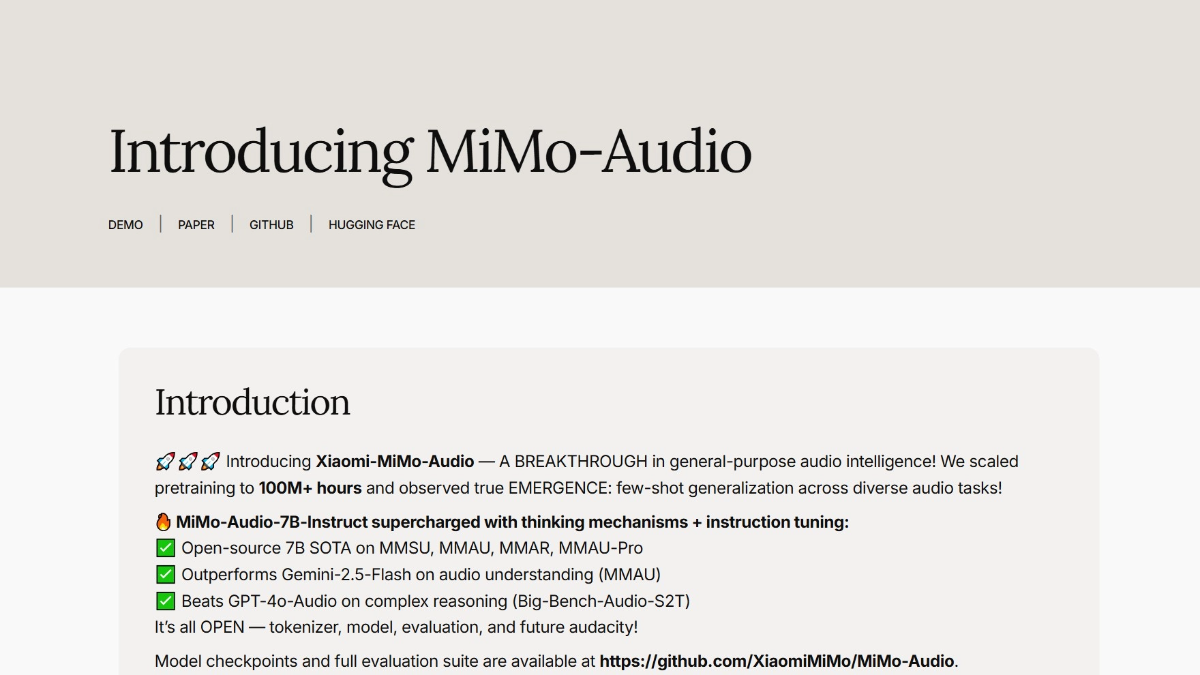
Xiaomi-MiMo-Audio is Xiaomi's open source 7-billion-parameter end-to-end speech macromodel with powerful features such as multi-language dialog, speech continuation, less-sample generalization, and audio understanding, which is able to reach the SOTA level in speech intelligence and audio understanding benchmarks, surpassing models such as Google Gemini-2.5-Flash. The model's innovative speech lossless compression pre-training and speech generative pre-training techniques enable the model to perform well in tasks such as speech conversion and style migration. Xiaomi has open-sourced the pre-training model MiMo-Audio-7B-Base, the command fine-tuning model MiMo-Audio-7B-Instruct, the MiMo-Audio Tokenizer model, the technical report, and the evaluation framework, to help the research of speech big models and the development of speech AGI.
Features of Xiaomi-MiMo-Audio
- multilingual dialogIt supports smooth communication with users, covers a wide range of topics such as philosophy, life ideals, etc., and enables you to learn Internet hot topics and spoken English.
- phonological sequel: Generates highly realistic speech content for stand-up comedy, recitation, live broadcasts and debates, preserving key acoustic characteristics such as speaker identity, rhythm and ambient sound.
- Sample less generalization: The absence of certain tasks in the training data (e.g., speech conversion, style migration, speech editing) can be easily coped with, showing strong generalization ability.
- Audio comprehension: Features audio captioning, audio reasoning, and long duration audio comprehension to process and analyze lengthy audio sequences, providing detailed descriptions and in-depth analysis.
MiMo-Audio's Core Advantages
- Ultra-large scale pre-training data: Pre-training based on over 100 million hours of speech data gives the model a strong generalization capability, enabling it to excel at complex tasks missing from the training data.
- Original lossless speech compression pre-training technology: A breakthrough in cross-task generalization in speech, allowing models to exhibit "emergent" behavior in low-sample learning to improve efficiency.
- First open source voice continuation capability: As the first model in the open source space with speech continuation capabilities, it can generate realistic speech content such as stand-up comedy and recitation, bringing new possibilities for creativity.
- Powerful audio comprehension: excels in audio captioning, inference and long audio comprehension, processing lengthy audio sequences and providing accurate analysis to help automate the annotation and analysis of audio content.
- Introduction of the thinking model: For the first time, thinking mode is introduced for speech understanding and generation process, and hybrid thinking is supported, which makes the model more flexible and natural in speech interaction and adapts to different scenarios and needs.
What is Xiaomi-MiMo-Audio's official website?
- Project website:: https://xiaomimimo.github.io/MiMo-Audio-Demo/
- GitHub repository:: https://github.com/XiaomiMiMo/MiMo-Audio
- HuggingFace Model Library:: https://huggingface.co/collections/XiaomiMiMo/mimo-audio-68cc7202692c27dae881cce0
- Technical Papers:: https://github.com/XiaomiMiMo/MiMo-Audio/blob/main/MiMo-Audio-Technical-Report.pdf
Who is Xiaomi-MiMo-Audio for?
- Speech technology developers: Provide developers with powerful voice models to use in developing voice assistants, voice interaction applications, etc., accelerating the development and innovation of voice technology products.
- Voice content creators: Help creators efficiently generate voice content for audiobooks, podcasts, talk shows, and other audio content to improve creation efficiency and quality.
- language learner: As a language learning tool, it facilitates language learning by providing learners with a simulated environment for oral practice and language communication.
- game developer: Use in-game voice dialog generation to give vivid voice performance to game characters and enhance game immersion.
- educator: Converting teaching content into audio lectures, producing audio courses and online lectures to enrich the form of teaching and improve the effectiveness of teaching.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles



No comments...