
Vector Database Depth Comparison: Weaviate, Milvus & Qdrant

In the field of artificial intelligence and machine learning, especially when building applications such as RAG (Retrieval Augmented Generation) systems and semantic search, efficiently processing and retrieving massive unstructured data becomes crucial. Vector databases have emerged as a core technology to address this challenge. They are not only specialized databases for storing high-dimensional vector data, but also key infrastructures for driving the next generation of AI applications.
In this article, we will discuss the concepts, working principles, and application scenarios of vector databases, and compare and analyze the current mainstream open source vector databases Weaviate, Milvus, and Qdrant, aiming to provide readers with a comprehensive and in-depth guide to vector databases to help you understand their value and make informed technical choices in real projects.
What is a Vector Database? From traditional databases to vector searches
In order to understand what makes vector databases unique, we first need to understand what vectors are and why traditional databases are overwhelmed when dealing with vector data.
Vectors: mathematical representation of data
Simply put, a vector is a mathematical tool used to represent a feature or attribute of data, and can be thought of as a point in a multidimensional space. In the context of vector databases, we usually discuss thehigh dimensional vector, which means that these vectors have a large number of dimensions, ranging from tens to thousands of dimensions, depending on the complexity of the data and the granularity of the desired representation.
Vector embedding: structured representation of unstructured data
So how are these high-dimensional vectors generated? The answer is through theembedded functionthat converts raw unstructured data (e.g., text, images, audio, video, etc.) into vectors. This conversion process, calledVector Embedding, using methods such as machine learning models, word embedding techniques or feature extraction algorithms to compress the semantic information or features of the data into a compact vector space.
For example, for textual data, we can use a program such as Word2Vec, GloVe, FastText, or Transformer models (e.g., BERT, Sentence-BERT) and other techniques to convert each word, sentence, or even the whole text into a vector. In the vector space, texts that are semantically similar will have their vectors closer together.

The core strength of vector databases: similarity search
Traditional databases, such as relational databases (e.g., PostgreSQL, MySQL) and NoSQL databases (e.g., MongoDB, Redis), are primarily designed for storing and querying structured or semi-structured data, and they excel at data retrieval based on exact matches or predefined criteria. However, when it comes to data retrieval based onsemantic similaritymaybeContextual meaningFinding data makes traditional databases inefficient.
Vector databases have emerged to fill this gap. Their core strength is the ability toEfficiently perform similarity search and retrieval based on vector distance or similarity. This means that we can find data based on its semantic or feature similarity without having to do exact keyword matching.
Key differences between vector databases and traditional databases
In order to more clearly understand the uniqueness of vector databases, we summarize the key differences between them and traditional databases as follows:
| characterization | vector database | Traditional Database (Relational/NoSQL) |
|---|---|---|
| data type | Vector embedding (high dimensional vectors) | Structured data (Tabular data, JSON documents, etc.) |
| core operation | Similarity Search (Vector Similarity Calculation) | Exact match query, range query, aggregation analysis, etc. |
| Index Type | Vector indexes (ANN indexes, etc.) | B-tree indexes, hash indexes, inverted indexes, etc. |
| Inquiry Method | Based on vector distances (cosine distance, Euclidean distance, etc.) | SQL-based query, key-value query, full-text search, etc. |
| application scenario | Semantic Search, Recommender Systems, Recommender Systems RAG, image/audio/video retrieval | Transaction Processing, Data Analysis, Content Management, Caching |
| data model | vector space model | Relational model, document model, key-value model, graph model, etc. |
The Value of Vector Databases: A Cornerstone for AI Applications
Vector databases are playing an increasingly important role in the field of artificial intelligence and machine learning, especially in the following areas:
- Next Generation Search Engines: Implement semantic search to understand the intent of the user's query and return more relevant and contextualized search results, not just keyword matching.
- Intelligent Recommender System: Personalized recommendations based on users' historical behavior and item characteristics to improve recommendation accuracy and user experience.
- Large Language Model (LLM) applications: Provides long-term memory and efficient contextual retrieval capabilities for LLMs, supporting the construction of more powerful chatbots, Q&A systems, and content generation applications.
- Multimodal data retrieval: Enabling cross-modal similarity search, e.g., searching for related images or videos by textual descriptions.
In summary, vector databases are the key infrastructure for processing and retrieving unstructured data in the AI era, and they empower machines to understand semantics and reason about similarities, thus driving numerous innovative AI applications.
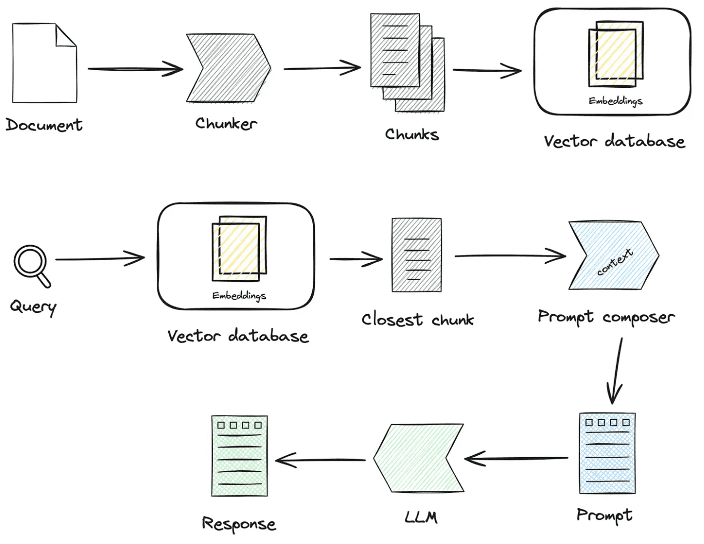
Vector Databases and RAG: Building a Powerful Search Enhancement Generation System
RAG (Retrieval-Augmented Generation) systems are currently a popular direction in the application area of large language modeling.The core idea of RAG is to retrieve relevant information from an external knowledge base before generating the text, and then use the retrieved information as a context to guide the language model in generating more accurate and reliable answers.
The central role of vector databases in the RAG system
In the RAG system, the vector database plays the role of therepositoryThe role of the RAG system is to store and efficiently retrieve vector representations of massive knowledge documents.The workflow of the RAG system is roughly as follows:
- Knowledge base construction:
- Vector embedding of knowledge documents (e.g., text, web pages, PDFs, etc.) into vector representations.
- Store these vectors and their corresponding document metadata in a vector database.
- Query Retrieval:
- Receive the user query and vector embed the query as well to get the query vector.
- A similarity search is performed in a vector database using the query vector to retrieve the document vector that is most similar to the query vector.
- Get the original document or document fragment corresponding to the retrieved document vector.
- Text Generation:
- The retrieved document fragments are fed into the Large Language Model (LLM) as context along with the user query.
- LLM generates the final answer or text based on contextual information.

Semantic Search for Images Implemented with Milvus
Why are vector databases ideal for RAG systems?
- Efficient semantic retrieval capabilities: Vector databases are able to retrieve documents based on semantic similarity, which is a perfect match for RAG systems that need to find contextual information from the knowledge base that is relevant to the user's query.
- Handle massive knowledge documents: RAG systems usually need to deal with a large number of knowledge documents, and vector databases can efficiently store and retrieve massive vector data to meet the scalability requirements of RAG systems.
- Quick response to user queries: The similarity search of vector databases is very fast and ensures that the RAG system responds quickly to user queries.
Vector Database Selection: Key Decisions for RAG Systems
Choosing the right vector database is critical to the performance and effectiveness of a RAG system. Different vector databases differ in terms of performance, functionality, and ease of use. In the following chapters, we will discuss the selection factors of vector databases and compare and analyze three excellent open source vector databases, namely Weaviate, Milvus and Qdrant, to help you choose the most suitable cornerstone for your RAG system.
Vector Database Selection: Focus on These Key Factors, Not Just Performance
Before we dive into comparing specific products, let's identify the core concerns of vector database selection. These factors will directly impact the performance, scalability, stability, and cost of the RAG system or AI application you build.
1. Open source vs. commercialization: autonomy vs. ease of use
- Open source vector databases (e.g. Milvus, Weaviate, Qdrant, Vespa):
- Advantage: Higher autonomy and flexibility for free customization and secondary development, better control of data security and system architecture. Supported by an active open source community, with fast iteration and rapid problem solving. Usually low cost or even free to use.
- Challenge: Deployment, operation and maintenance, and troubleshooting require some technical skills. Commercial support may be relatively weak, requiring reliance on the community or self-initiated problem solving.
- Applicable Scenarios: Projects that require a high degree of autonomy and control, are supported by a technical team, want to reduce costs, and can actively participate in community co-creation.
- Commercial vector databases (e.g., hosted vector databases from cloud providers such as Pinecone, etc.):
- Advantage: Typically provides complete managed services and technical support, simplifies deployment and O&M complexity, and is easy to get started and use. Performance and stability are commercially proven and service quality is guaranteed.
- Challenge: Higher costs and may incur significant expenses over time. Possible risk of vendor lock-in, limited customization and secondary development.
- Applicable Scenarios: Projects that are looking for ease of use and stability, want to get started quickly, reduce the O&M burden, have a good budget, and are not sensitive to vendor lock-in risks.
2. CRUD support: dynamic data vs. static data
- CRUD (Create, Read, Update, Delete) support:
- Importance: Critical for RAG systems and many dynamic data applications. If data needs to be updated, deleted or modified frequently, it is important to choose a vector database that supports full CRUD operations.
- Impact: A database that supports CRUD operations makes it easy to manage dynamically changing data and keep the knowledge base real-time and accurate.
- Static data scenarios:
- Demand: If the data is static, such as a pre-built knowledge base, and the data is updated very infrequently, a read-only vector library or a database that doesn't support full CRUD might also fit the bill.
- Select: In this case, some lightweight vector libraries can be considered, or some vector databases that focus on high-performance retrieval with a weak data update function.
3. Distributed architecture and scalability: coping with massive data and high concurrency
- Distributed Architecture:
- Necessity: RAG systems and many AI applications typically need to handle massive amounts of data and highly concurrent requests. Distributed architectures are key to meeting these challenges.
- Advantage: Distributed vector databases can decentralize the storage of data on multiple servers and support parallel queries, thus improving data processing power and query performance.
- Scalability:
- Horizontal expansion: A good vector database should be able to scale horizontally easily, by adding nodes to cope with the growth in data volume and requests.
- Elastic Stretch: It is desirable to support elastic scaling to dynamically adjust resources based on actual load to optimize cost and performance.
4. Data replication and high availability: guaranteeing data security and service stability
- Data copy:
- Role: The data copy mechanism is an important means of ensuring data security and high system availability.
- Realization: By storing identical copies of data on multiple servers, the system continues to operate normally without data loss even if some nodes fail.
- High Availability:
- Importance: High availability is critical for RAG systems and online applications that require high service stability.
- Safeguards: Mechanisms such as data copy, automatic fault transfer, and monitoring and alarming work together to ensure the continuous and stable operation of the system.
5. Performance: search speed and accuracy
- Latency:
- Indicators: Query latency, i.e., the time between initiating a query and obtaining results.
- Influencing factors: Indexing algorithms, hardware resources, data size, query complexity, etc.
- Demand: For applications with high real-time requirements, you need to choose a vector database with fast retrieval speed.
- Recall, Precision:
- Indicators: Recall and Precision, which measure the accuracy of similarity search results.
- Weighing: There is usually a trade-off between retrieval speed and precision, and the right balance needs to be chosen according to the application scenario. For example, for a RAG system, recall may be more important to ensure that as many relevant documents are retrieved as possible.
6. Ongoing maintenance and community support: a guarantee of long-term stable operation
- Ongoing maintenance:
- Importance: Vector database technology is evolving rapidly, and ongoing maintenance and updates are critical.
- Points of Concern: Whether the database is continuously maintained and updated by an active development team, fixing bugs in a timely manner and keeping up with the latest technology trends.
- Community Support:
- Value: An active community provides a wealth of documentation, tutorials, sample code, and answers to questions, lowering the barriers to learning and use.
- Assessment: Community support can be assessed by looking at metrics such as activity in GitHub repositories, buzz in community forums, number of users, and so on.
7. Cost considerations: open source vs. commercialization, self-build vs. hosting
- Open source vs. commercialization costs:
- Open Source: The database software itself is free, but there are hardware costs, operation and maintenance costs, and labor costs to consider.
- Commercialization: There are software license fees or cloud service fees to pay, but potentially lower O&M costs and better technical support.
- Self-build vs. hosting costs:
- Self-Build: You need to be responsible for hardware procurement, deployment, operation and maintenance, monitoring, etc., with high initial investment and long-term operation and maintenance costs.
- Hosting: Using a hosted vector database service from a cloud provider requires no concern for the underlying infrastructure, is pay-as-you-go, and has a more flexible cost structure, but may be more expensive to use in the long term.
Synthesis:
In vector database selection, you need to consider the above seven key factors and make trade-offs and choices based on specific application scenarios, needs and budgets. There is no absolute optimal database, only the most suitable database for a specific scenario.
Comparison of different types of vector database solutions: a panorama of technology selection
Faced with the many vector database solutions on the market, understanding their types and features will help you narrow down your choices and find the right one for you faster. We broadly categorize vector database solutions into the following five categories:
1. Vector libraries (FAISS, HNSWLib, ANNOY): lightweight indexes, static data acceleration tools
Vector libraries such as FAISS (Facebook AI Similarity Search), HNSWLib (Hierarchical Navigable Small World Graphs Library) and ANNOY (Approximate Nearest Neighbors Oh Yeah), which are essentiallySoftware libraries for building vector indexes and performing similarity searches. They usually run as libraries embedded in your application, rather than as standalone database services.
dominance::
- High performance: Focuses on vector indexing and similarity search algorithm optimization for extremely fast retrieval.
- Lightweight: Low resource footprint, simple to deploy and easy to integrate into existing applications.
- Mature and stable: After a long period of development and wide application, the technology is mature and reliable with good community support.
limitations::
- Static data is predominant: It is mainly used to store static data, and it is not easy to update the data after the index is constructed. Except for HNSWLib, most vector libraries do not support CRUD operations, which makes it difficult to update and delete data.
- Limited functionality: Usually only provides basic vector indexing and similarity searching functions, and lacks advanced database features such as distributed, data replica, rights management, monitoring and operation and maintenance.
- High operation and maintenance costs: You need to build your own deployment ecosystem, handle data replication and fault tolerance, and lack comprehensive O&M tools and management interfaces.
Applicable Scenarios::
- Similarity search for static datasets: For example, scenarios where the data is updated infrequently, such as offline constructed knowledge bases, product libraries, face libraries, and so on.
- Scenarios with very high performance requirements but low frequency of data updates: Examples include offline index construction for search engines and offline feature indexing for large-scale recommender systems.
- as a vector index acceleration component for other databases: For example, vector libraries are utilized in conjunction with the use of databases such as Redis, MySQL, etc. to accelerate similarity search.
Representative Products:
- FAISS (Facebook AI Similarity Search): Developed by Facebook AI Research, widely used in academia and industry. Provides a variety of efficient indexing algorithms, such as IVF, PQ, HNSW, etc., and is especially good at handling large-scale datasets.
- HNSWLib (Hierarchical Navigable Small World Graphs Library): Based on HNSW (Hierarchical Navigable Small World) algorithm implementation , known for its high performance and efficiency . HNSWLib compared to other vector libraries , more flexible , support CRUD operations and concurrent read and write .
- ANNOY (Approximate Nearest Neighbors Oh Yeah): Developed by Spotify, focuses on fast approximate nearest neighbor search. Known for its clean and efficient design, it is suitable for latency-sensitive application scenarios.
2. Full-text search databases (ElasticSearch, OpenSearch): complementary to vector searches, non-core capability
Full-text search databases, such as ElasticSearch and OpenSearch, are primarily designed to be used forFull text search and keyword searchThey are based on inverted indexing technology and are powerful in text retrieval and advanced analytics. In recent years, they have also begun to add vector retrieval capabilities, but vector retrieval is not their core strength.
dominance::
- Powerful full-text search capabilities: Supports complex text queries, word splitting, synonyms, spelling correction, relevance sorting (such as BM25) and other functions.
- Rich analytics: Provides aggregation, statistics, reporting, and data visualization for data analysis and business insights.
- Mature ecosystems: With a large user base and a well-established ecosystem, it is easy to integrate and use, with an abundance of peripheral tools and plug-ins.
limitations::
- Vector retrieval performance is weak: Compared to dedicated vector databases, vector similarity search performance is low, especially on high-dimensional data and large-scale datasets, where query latency is high and accuracy may be insufficient.
- High resource consumption: In order to support functions such as full-text search and analysis, resource consumption is high, and deployment and operation and maintenance costs are high.
- Not good at semantic search: It mainly relies on keyword matching and inverted indexing, with limited semantic comprehension, making it difficult to meet complex semantic search needs.
Applicable Scenarios::
- Keyword search-based and vector retrieval-based applications: For example, product search on e-commerce websites and article search on news websites mainly use keyword search, and vector search is used as an auxiliary function to improve the semantic relevance of search.
- Hybrid search scenarios that require a combination of full-text search and vector search: For example, the intelligent customer service system, which supports both keyword and semantic search, meets the diversified query needs of users.
- Log analysis, monitoring alarms and other scenarios that require powerful analytics: Utilize the powerful analysis capability of full-text search database for log analysis, monitoring alarms, security auditing, etc.
representative product::
- ElasticSearch: Built on Lucene , is one of the most popular open source full-text search engine , widely used in search , log analysis , data visualization and other fields .
- OpenSearch: Branching from AWS based on ElasticSearch and Kibana, it maintains compatibility with ElasticSearch and adds new features and improvements to ElasticSearch.
Conclusion: While ElasticSearch and OpenSearch provide vector retrieval capabilities, their performance and functionality still fall short of dedicated vector databases. For RAG systems or AI applications that focus on vector retrieval, dedicated vector databases are a better choice. Full-text search databases are more suitable as a complement to vector retrieval rather than an alternative.
3. Vector-enabled SQL databases (pgvector, Supabase, StarRocks): vector extensions to traditional databases, for lightweight applications.
SQL databases, such as PostgreSQL, support vector data types and similarity searching capabilities through extensions (e.g., pgvector). This allows users to store and query vector data in existing relational databases without having to introduce a new database system.
dominance::
- Easy to integrate: Seamless integration with existing SQL databases reduces the complexity of the technology stack and reduces learning and migration costs.
- Mature and stable: SQL database technology is mature and stable, with strong data management and transaction processing capabilities, and guaranteed data consistency and reliability.
- Low cost of learning: For developers familiar with SQL, the learning cost is low and you can quickly get started with the vector search functionality.
limitations::
- Vector retrieval performance is limited: Relational databases, whose architecture is not designed for vector retrieval, do not perform as well as specialized vector databases, especially when dealing with large-scale, high-dimensional vector data with high query latency.
- Scalability is limited: Relational databases have relatively weak scalability, which makes it difficult to cope with massive vector data and highly concurrent queries, and limited horizontal scalability.
- Vector dimension restrictions: For example, the upper limit of vector dimension supported by pgvector is 2000 dimensions, which is lower than that of specialized vector databases, and may not be able to meet the needs of high-dimensional vector data.
Applicable Scenarios::
- Applications with small vector data volumes (below the 100,000 level): For example, small recommender systems, simple image searches, personal knowledge bases, etc., have small amounts of vector data and low performance requirements.
- Application of vector data as an auxiliary function: For example, adding a product vector field to the product database of an e-commerce site for product recommendation or similar product lookup, vector search is just an auxiliary function of the database.
- Applications that already have mature SQL databases and want to quickly add vector retrieval capabilities: In projects that already use SQL databases such as PostgreSQL and want to quickly introduce vector retrieval functionality, consider using extensions such as pgvector.
representative product::
- pgvector: Extension to PostgreSQL, developed by Crunchy Data, providing vector datatypes (vector) and indexes (IVF, HNSW), as well as vector similarity searching capabilities.
- Supabase: Open source PaaS platform based on PostgreSQL , integrated pgvector , easy for users to quickly build applications that support vector retrieval .
- StarRocks: An OLAP-oriented MPP database that also adds vector retrieval functionality, but vector retrieval is not its core niche and is mainly used in OLAP analysis scenarios.
Conclusion: SQL databases that support vectors, such as pgvector, are more suitable for lightweight application scenarios where the vector data volume is small, the performance requirements are not high, and the vector data is only used as a complementary function of the application. If vector data is the core of the application, or if there is a high demand for scalability, a dedicated vector database would be a better choice.
4. Vector-enabled NoSQL databases (Redis, MongoDB): an emerging endeavor with both potential and challenges
NoSQL databases, such as Redis and MongoDB, have also begun to experiment with adding vector support, such as Redis Vector Similarity Search (VSS) and MongoDB Atlas Vector Search. this has given NoSQL databases the ability to work with vector data as well.
dominance::
- Inherent advantages of NoSQL databases: For example, Redis for its high-performance caching, low latency, and high throughput; and MongoDB for its flexible document model, ease of scalability, and rich document manipulation capabilities.
- Technical novelty: It represents the development trend of database technology, and integrates vector retrieval capability into mature NoSQL databases, which has certain innovation and development potential.
limitations::
- Functionality is not yet mature: Vector support functionality is still in its early stages, with features and performance to be refined and validated, and the ecosystem relatively immature.
- Poor ecosystems: There is a relative paucity of relevant tools, libraries and ecosystems, which can be costly to use and maintain, and community support is relatively weak.
- Performance to be considered: While Redis VSS claims excellent performance, the actual results need to be verified in more scenarios and may not perform as well as dedicated vector databases on high-dimensional data and large-scale datasets.
Applicable Scenarios::
- Scenarios with high performance requirements and small amounts of vector data: For example, Redis-based real-time recommender systems, online advertisement retrieval, etc., require low-latency, high-throughput vector retrieval.
- Scenarios where you want to try new technology and are willing to take some risk: For technology tasters, try using the vector support features of NoSQL databases to explore their potential.
- Already using a NoSQL database and would like to add vector retrieval capabilities to it: In projects that are already using Redis or MongoDB and want to quickly introduce vector retrieval functionality on top of it, consider using its vector extension module.
representative product::
- Redis Vector Similarity Search (VSS): A module for Redis that provides vector indexing (HNSW) and similarity search capabilities, emphasizing high performance and low latency for real-time demanding scenarios.
- MongoDB Atlas Vector Search: A new feature in Atlas, the MongoDB cloud service, is designed to integrate vector search into MongoDB's document database, providing more comprehensive data processing capabilities.
Conclusion: The newly added vector support features in NoSQL databases are still in the early stages of development, and their maturity and stability need to be further verified. Although they have some potential, they may still be less mature and powerful than dedicated vector databases in terms of functionality and performance. The choice needs to be evaluated carefully and their limitations fully considered.
5. Specialized vector databases (Pinecone, Milvus, Weaviate, Qdrant, Vespa, Vald, Chroma, Vearch): built for vectors, first choice for RAG systems and AI applications
Specialized vector databases, such as Pinecone, Milvus, Weaviate, Qdrant, Vespa, Vald, Chroma, Vearch, etc., are designed from the ground up to focus on theStorage, indexing and retrieval of vector data, are inherently well equipped to handle high-dimensional vector data. They are the preferred solution for building AI applications such as RAG systems, semantic search, recommendation systems, and more.
dominance::
- Excellent vector retrieval performance: Deeply optimized for vector similarity search, the retrieval is fast and accurate, and can efficiently handle large-scale high-dimensional vector data.
- Powerful scalability: Usually adopts distributed architecture, easy to horizontal expansion, can cope with massive data and high concurrency query, to meet the needs of large-scale applications.
- Rich functionality features: It usually provides perfect vector data management, index construction, query optimization, monitoring and operation and maintenance functions, as well as rich similarity search algorithms and distance metrics.
- Flexible indexing options: Supports multiple vector indexing algorithms (e.g. IVF, HNSW, PQ, tree indexing, etc.), which allows you to choose the optimal indexing strategy according to different application scenarios and data characteristics.
- Mature ecosystem (some products): Some of the products have active communities and well-established ecosystems, providing rich documentation, tools and integration solutions that are easy to use and integrate.
limitations::
- Higher learning costs: Compared to traditional databases, specialized vector databases may have a steeper learning curve and require an understanding of vector indexing, similarity search, and other related concepts.
- Technology selection is complex: There are many products with different functions and features, and selection requires careful evaluation to compare the advantages and disadvantages of different products.
- Commercialization of some products: Some of the best specialized vector databases are commercial products (e.g., Pinecone), which are more expensive to use and may be at risk of vendor lock-in.
Applicable Scenarios::
- Applications centered on vector retrieval: For example, RAG systems, semantic search, image search, audio search, video search, recommender systems, bioinformatics analysis, etc., vector retrieval is the core function of the application.
- Applications that need to handle massive amounts of high-dimensional vector data: For example, large-scale knowledge graphs, massive product libraries, and user behavior data analysis require the processing of large-scale high-dimensional vector data.
- Applications with high requirements for retrieval performance and accuracy: For example, financial risk control, security monitoring, and precise recommendation have strict requirements for retrieval speed and accuracy.
- Applications that require flexible scalability and high availability: For example, large-scale online services and cloud platforms need to support horizontal scaling and high availability to guarantee the stability and reliability of services.
representative product::
- Pinecone: Commercially available cloud-based vector database, maintained by a team of professionals, provides easy-to-use and highly scalable vector retrieval services. Known for its ease of use and high performance, it is a representative of cloud-based vector databases. However, there are limitations in open source nature and customization, and the free version has limited functionality.
- Milvus: Open source distributed vector database , led by Zilliz company , powerful performance , feature-rich , active community , is the benchmark of open source vector database . Supports a variety of index types , distance metrics and query methods , can be flexible to deal with a variety of application scenarios .
- Weaviate: Open source graph vector database , developed by the German company SeMI Technologies , combines vector search with graph database technology , providing unique data modeling and query capabilities . Supports GraphQL query language to facilitate complex data query and analysis.
- Qdrant: Open source vector database , developed by a Russian team , written in Rust language , focusing on performance and ease of use , lightweight architecture , low resource consumption . Popular for its high performance, low latency and ease of deployment.
- Vespa: Developed by Yahoo and open source search engine and vector database , powerful , excellent performance , but the architecture is more complex , steep learning curve . Suitable for scenarios with very high requirements for performance and functionality.
- Vald: Open source distributed vector database , developed by a Japanese team , focusing on high precision and high reliability vector retrieval . Emphasizing high precision and low latency, it is suitable for scenarios that require very high precision. However, there are deficiencies in the integration with Langchain, and the community size is small.
- Vearch: Open source distributed vector database , developed by a Chinese team , provides high-performance , highly available vector retrieval services . Focuses on ease of use and scalability, and is suitable for projects that need to quickly build vector retrieval applications. There are deficiencies in integration with Langchain and the community is small.
- Chroma: Chroma is an open source embedded vector database that focuses on lightweight and ease of use, using SQLite as the document store. Suitable for local development, prototyping, or small applications with relatively limited scalability and efficiency, Chroma is designed specifically for audio data, but is not optimized to handle text data, and there is a relative lack of comprehensive performance benchmarking information.
Conclusion: For RAG systems and most AI applications, specialized vector databases are the best choice. They are better in terms of performance, functionality and scalability to better meet the needs of these applications. Among the many dedicated vector databases, Weaviate, Milvus, Qdrant and Vespa are some of the most popular and widely used today.
In order to more visually compare three excellent open source vector databases, Weaviate, Milvus and Qdrant, we have summarized the table below:
| comprehensive database | Qdrant | Weaviate | Milvus |
|---|---|---|---|
| Open source and self-hosted | be | be | be |
| open source protocol | Apache-2.0 | BSD | Apache-2.0 |
| development language | Rust | Go | Go, C++ |
| Github Stars (as of 2024) | 17k+ | 9.2k+ | 26.2k+ |
| First release date | 2021 | 2019 | 2019 |
| SDK | Python, JS, Go, Java, .Net, Rust | Python, JS, Java, Go | Python, Java, JS, Go |
| Hosted Cloud Services | be | be | be |
| Built-in text embedding | FastEmbed | be | be |
| hybrid search | be | RRF*+RSF* | In-table multivector mixing |
| Meta-information filtering | be | be | be |
| BM25 Support | be | be | be |
| Text Search | be | be | be |
| single-point multivector (math.) | be | be | be |
| Tensor Search | be | be | be |
| Langchain Integration | be | be | be |
| Llama Index Integration | be | be | be |
| Geo Geographic Information Search | be | be | be |
| Multi-tenant support | via collections/metadata | be | be |

Summary:
- Qdrant: Lightweight architecture , low resource overhead , excellent performance , easy to deploy and use , Rust language development , focus on performance and efficiency .
- Weaviate: Comprehensive features, integration of vector search, object storage and inverted index, support for GraphQL queries, data modeling capabilities, Go language development, active community.
- Milvus: Strong performance, rich functionality, active community, support for a variety of index types and query methods, can flexibly deal with a variety of complex scenarios, Go and C++ language development, ecological perfection.
You can choose the vector database that best suits your needs, technology stack preferences and team capabilities.
Vector Database Search Methods Explained: Unlocking the Many Positions of Vector Retrieval
The core function of vector databases is similarity search, and different vector databases provide a variety of search methods to meet different application needs. Understanding these search methods will help you utilize vector databases more effectively to build more powerful AI applications.

6. Comparison of search methods for vector databases
We will focus on the main search methods of the three databases Milvus, Weaviate and Qdrant:
6.1 Milvus: Flexible and Varied Search Strategies for Different Scenarios
Milvus provides a rich and flexible search strategy, you can choose the appropriate search method according to different data structures and query requirements.
- Single Vector Search: This is the most basic way to search, using the
search()method that compares a query vector with existing vectors in the collection, returning the most similar entity IDs and their distances. You can choose the vector values and metadata of the returned results. Ideal for simple similarity search scenarios, e.g., finding the most similar product to a certain item, finding the most similar image to a certain image, etc. - Multi-Vector Search: for collections containing multiple vector fields, by
hybrid_search()method. The method executes multiple Approximate Nearest Neighbor (ANN) search requests simultaneously and fuses and rearranges the results to return the most relevant matches.The latest 2.4.x version of Milvus supports searches using up to 10 vectors. Multi-vector search is particularly suitable for complex scenarios that require high accuracy, such as:- The same data is processed using different embedding models: For example, the same sentence can be generated with different vector representations using different models such as BERT, Sentence-BERT, GPT-3, etc. Multi-vector search can fuse the vector representations of these different models to improve the accuracy of the search.
- Multimodal data fusion: For example, multiple modal information such as images, fingerprints, and voiceprints of an individual are converted into different vector formats for a comprehensive search. Multi-vector search can fuse the vector information of these different modalities to achieve a more comprehensive similarity search.
- Increase recall rates: By assigning weights to different vectors and utilizing the information of multiple vectors in a "multiple recall" strategy, the recall capability and the effectiveness of search results can be significantly improved to avoid missing relevant results.
- Basic Search Operations: In addition to univector and multivector searches, Milvus provides a rich set of basic search operations, including:
- Batch Vector Search: Submitting multiple query vectors at once improves search efficiency and is suitable for scenarios that require batch processing of queries.
- Partition Search: Search in the specified partition, narrowing the search scope and improving the search speed, applicable to large data volume scenarios, you can store the data by partition to improve the query efficiency.
- Specify Output Fields to search: Returns only the specified fields, reduces the amount of data transfer, improves the search efficiency, and is suitable for scenarios where only part of the field information is needed.
- Filter Search: Filtering conditions based on scalar fields to refine the search results, e.g., filtering based on conditions such as product price, user age, product category, etc., further filtering the results based on similarity search to improve the accuracy of the search.
- Range Search: Find vectors whose distance from the query vector is within a specific range, e.g., find products with a similarity of 0.8 or more to the target product, which is suitable for scenarios where the similarity range needs to be limited.
- Grouped Search: Grouping of search results based on specific fields ensures diversity of results and avoids too much concentration of results, which is suitable for scenarios that require diversity of results, e.g., recommender systems that want to recommend different categories of products.
6.2 Weaviate: a powerful hybrid search capability incorporating multiple search techniques
Weaviate provides a powerful hybrid search capability, which can flexibly combine vector similarity search, keyword search, generative search and other search methods to satisfy complex query requirements and provide a more comprehensive retrieval solution.
- Vector Similarity Search: Providing multiple proximity search methods to find the most similar object to the query vector is the core search capability of Weaviate.
- Image Search: Supports using images as input for similarity search to realize image search function, which is suitable for image retrieval scenarios.
- Keyword Search: The results are ranked using the BM25F algorithm, which supports efficient keyword retrieval for traditional keyword search scenarios.
- Hybrid Search: Combining BM25 keyword search and vector similarity search for fusion ranking of results, taking into account semantic relevance and keyword matching, is suitable for hybrid search scenarios where both keyword and semantic information need to be considered.
- Generative Search: Utilizing search results as hints for LLM to generate answers that better match the user's intent, combining search with generative AI technology to provide a smarter search experience.
- Re-ranking: Use the Re-rank module to further optimize the quality of your search results by re-ranking the retrieved results to improve their accuracy and relevance.
- Aggregation: Aggregate data from the result collection, perform statistical analysis, provide data analysis capabilities, and assist users in data mining and analysis.
- Filters: Apply conditional filtering to searches, e.g., based on metadata fields, to improve search accuracy and support complex filtering conditions.
6.3 Qdrant: focusing on vector search, taking full-text filtering into account, lightweight and efficient
Qdrant specializes in providing high-performance vector search services with a balance of full-text filtering, and is known for its lightweight, high performance and ease of use.
Basic search operations supported by Qdrant::
- Filtering by Score: Filtering based on vector similarity scores returns only results with higher similarity, improving the quality of search results.
- Multi-Search Requests with a single request load: Submitting multiple search requests at once improves search efficiency and is suitable for scenarios that require batch processing of queries.
- Recommend API: Provide specialized recommendation APIs for building recommendation systems and simplify the development process of recommendation systems.
- Grouping Operations: Grouping of search results improves the diversity of results for scenarios that require diversity of results.
Other search methods supported by Qdrant::
Qdrant's core positioning is a vector search engine , without affecting the performance of vector search , provides limited full-text search support to meet the basic full-text filtering needs .
- Search with Full-text Filtering: Vector data can be filtered using full-text filters, e.g., to find vector data containing specific keywords, to achieve simple full-text search functionality.
- Full-text Filter with Vector Search: Performs vector searches in records with specific keywords to achieve more accurate searches, combining full-text filtering and vector searches to improve the accuracy of searches.
- Prefix Search and Semantic Instant Search: Supports prefix search and semantic instant search to provide a more user-friendly experience, fuzzy search and real-time search.
Qdrant Future Planned Features::
- Sparse Vectors are supported: For example, sparse vectors used in SPLADE or similar models enhance the ability to handle sparse data and improve the efficiency and accuracy of vector retrieval.
Features not intended to be supported by Qdrant::
- BM25 or other Non-Vector Based Retrieval or Ranking Functions (Non-Vector Based Retrieval): Qdrant insists on vector search as its core, and does not intend to support traditional keyword-based retrieval methods, keeping the architecture simple and efficient.
- Built-in Ontology or Knowledge Graph, Query Analyzer and other NLP tools (Built-in Ontology or Knowledge Graph): Qdrant focuses on the underlying infrastructure of vector search, leaving upper layer applications and NLP functionality out of the picture, keeping the core functionality focused and performance optimized.
What is the difference between BM25 and a simple keyword search? An in-depth look at relevance scoring
In the field of keyword search, BM25 (Best Matching 25) algorithm is a more advanced and effective relevance scoring method than simple keyword matching. Understanding the difference between them will help you better choose the right search strategy, especially in scenarios that require keyword or hybrid searches.
1. Relevance scoring mechanism:
- Simple Keyword Search: Scoring is usually based on Term Frequency (TF - Term Frequency), i.e. the more times a keyword appears in a document, the more relevant the document is. This method is simple and straightforward, but it tends to ignore the length of the document and the importance of the keywords, which can lead to over-scoring of long documents, as well as interference in the results from commonly used and deactivated words.
- BM25 (Best Matching 25): Using a more complex algorithm that takes into account factors such as Term Frequency (TF), Inverse Document Frequency (IDF - Inverse Document Frequency) and document length to score the relevance of documents, BM25 can more accurately measure the relevance of a document to a query, and effectively address the limitations of simple keyword searches.
2. Document length processing:
- Simple keyword search: Document length may not be taken into account, resulting in long documents being more likely to be considered relevant because long documents have a higher probability of containing keywords, resulting in long document bias.
- BM25: By introducing the document length normalization factor, the problem of long document bias is solved to ensure the fairness of the relevance scoring between long and short documents, and to avoid the long documents obtaining too high scores because of the length advantage.
3. Importance of query terms:
- Simple keyword search: It is common to treat all keywords as equally important, ignoring the rarity of the keywords in the document collection and causing common and deactivated words to interfere with the results.
- BM25: Inverse Document Frequency (IDF) is utilized to measure the importance of keywords. keywords with higher IDF values (i.e., rarer keywords in the document collection) contribute more to the document relevance score, effectively differentiating the importance of keywords and improving the quality of search results.
4. Parameter tunability:
- Simple keyword search: There are usually fewer parameters, making it difficult to perform fine tuning and less flexible.
- BM25: Adjustable parameters (e.g., k1 and b) are provided to allow users to fine-tune the algorithm according to specific application scenarios and data characteristics, optimize the search results, and improve the flexibility and customizability of the search.
Summary:
Compared with simple keyword search, the BM25 algorithm is superior in relevance scoring, document length processing, query term importance measurement and parameter tunability, and can provide more accurate and user-expected search results. Therefore, the BM25 algorithm is a better choice in scenarios with high requirements on search quality, especially in scenarios where keyword search or hybrid search is required, the BM25 algorithm is a key technology to improve search results.
7. Performance benchmarking and metrics in detail: quantitative assessment of the strengths and weaknesses of vector databases
Performance is an important consideration in selecting a vector database. Benchmarking is an effective means to evaluate the performance of vector databases. However, it should be noted that benchmarking results are affected by a variety of factors, so when referring to benchmarking results, it is necessary to analyze them comprehensively with specific application scenarios and requirements.
7. Appendix
7.1 ANN Benchmarks: The Authoritative Performance Evaluation Platform
ANN-Benchmarks Approximate Nearest Neighbors Benchmarks (ANN-Benchmarks) is an authoritative performance evaluation platform for approximate nearest neighbor algorithms, created and maintained by Erik Bernhardsson. It provides a unified benchmarking framework and dataset for evaluating the performance of various Approximate Nearest Neighbor search algorithms and vector databases.ANN-Benchmarks provides an important reference for vector database performance evaluation, and is an important tool for understanding the performance differences between different vector databases.
Influencing factors for benchmarking:
- Search Type: Filtered Search vs. Regular Search, different search types have different impact on performance.
- Configuration settings: Database configuration parameters, such as index types, index parameters, cache settings, etc., can significantly affect performance.
- Indexing algorithms: Different indexing algorithms (e.g., IVF, HNSW, PQ) have different performance characteristics and are suitable for different data distribution and query scenarios.
- Data embedding: The quality and dimensionality of the data embedding affects the performance and accuracy of the vector database.
- Hardware Environment: CPU, memory, disk, network and other hardware resources directly affect the performance of the database.
Key factors to look for when selecting a model in addition to benchmarking:
- Distributed Capabilities: Whether it supports distributed deployment and can scale horizontally to cope with massive data and high concurrency.
- Data copies and caching: Whether to support data copy and caching mechanism to ensure data security and improve system performance.
- Indexing algorithms: What kind of indexing algorithm is used, the performance characteristics and applicable scenarios of the algorithm, and whether multiple indexing algorithms are supported.
- Vector similarity search capability: Whether to support hybrid search, filtering, multiple similarity metrics and other advanced search functions to meet the needs of complex queries.
- Segmentation mechanism: Whether to support data slicing, how to slice and manage data to improve data management and query efficiency.
- Cluster approach: How to build clusters, the scalability and stability of clusters, guaranteeing high availability and scalability of the system.
- Scalability potential: The upper limit of the system's scalability, whether it can meet the needs of future business growth, and predict the system's ability to expand.
- Data consistency: How to guarantee data consistency and reliability, especially in a distributed environment.
- Overall system availability: Stability and reliability of the system, whether it can ensure 7x24 hours stable operation and meet the business continuity requirements.
Angular metrics vs. Euclidean metrics: key metrics for text retrieval
In the field of text retrieval, vector databases inAngular Distance The performance on is usually better thanEuclidean Distance more important. This is because angular metrics are more sensitive to the semantic similarity of text documents, whereas Euclidean metrics focus more on the length and size of documents.
- Angular measure (e.g. cosine distance): Focus on the direction of the vector, not sensitive to the length of the vector, more suitable for measuring the semantic similarity of the text, suitable for text retrieval, document classification and other scenarios.
- Euclidean metric (e.g., Euclidean distance): It also considers the size and direction of vectors, is sensitive to the length of vectors, and is more suitable for measuring the absolute distance of vectors, which is suitable for scenarios such as image recognition and speech recognition.
Therefore, when selecting the RAG system, we should focus on the vector database in different dimensions of theAngle data setperformance on datasets such as glove-100-angular and nytimes-256-angular.

Performance analysis (glove-100-angular dataset):
- Throughput (Queries per Second, QPS): Milvus shows the highest throughput when the recall is lower than 0.95, which means that Milvus is able to handle higher query concurrency with better performance while guaranteeing a certain recall. When the recall exceeds 0.95, the throughput gap between databases narrows, and the performance gap is not obvious at high recall.
- Index Build Time: Vespa has the longest index build time, Weaviate and Milvus have similar build times, but Milvus is slightly longer. The index build time directly affects the database startup speed and data update efficiency, the shorter the build time, the faster the database startup and data update.
- Index Size: Weaviate has the smallest index and Milvus has the largest. The index size affects the storage cost and memory usage, the smaller the index, the lower the storage cost and memory usage. Although the index of Milvus is large, for a dataset containing 1.2 million 100-dimensional vectors, the index size is less than 1.5GB, which is still acceptable, and we need to evaluate the impact of the index size according to the data size in practical applications.
7.1.2 nytimes-256-angular dataset performance

Performance analysis (nytimes-256-angular dataset):
Performance on this dataset is similar to the glove-100-angular dataset, with a consistent overall trend.
- Index build time: Weaviate has the longest index build time, Milvus and Qdrant are relatively short, and the build time ordering is consistent with the glove-100-angular dataset.
- Index size: Weaviate's index is the smallest, Milvus' index is the largest but only 440MB (a dataset containing 290,000 256-dimensional vectors), and the index size ordering is consistent with the glove-100-angular dataset.
Summary:
ANN Benchmarks provide valuable performance reference data to help us understand the performance characteristics of different vector databases. Milvus excels in throughput and is suitable for highly concurrent query scenarios; Weaviate has an advantage in index size and saves storage space; and Vespa has a relatively longer build time and needs to be considered in terms of index building efficiency.
When actually selecting a model, it is necessary to combine specific application scenarios, data characteristics and performance requirements for a comprehensive assessment, and cannot rely only on benchmark test results.
7.2 Vector similarity metrics: choosing the right metric to improve retrieval results
Vector similarity metrics are used to measure the degree of similarity between two vectors, and different similarity metrics are applicable to different data types and application scenarios. Choosing the right similarity metrics directly affects the accuracy and effect of vector retrieval. Different vector databases support different similarity metrics, so you need to choose the right database and similarity metrics according to the actual needs.
| norm | descriptive | dominance | inferior | Applicable Scenarios | Supported databases |
|---|---|---|---|---|---|
| Cosine Distance | Measure the cosine of the angle between two vectors | Focus on vector direction, not sensitive to vector length; suitable for high-dimensional sparse data | Insensitive to vector length information; not applicable to non-convex datasets | Text similarity computation, document categorization, recommender systems | pgvector, Pinecone, Weaviate, Qdrant, Milvus, Vespa |
| Euclidean Distance (L2) | Calculate the straight-line distance between two vectors in a multidimensional space | Intuitive and easy to understand; consider both vector magnitude and direction | Performance degradation in high-dimensional spaces due to "dimensional catastrophe"; sensitivity to outliers | Image recognition, speech recognition, handwriting analysis | pgvector, Pinecone, Qdrant, Milvus, Vespa |
| Dot Product | Calculate the sum of the products of the corresponding components of the vector | Fast computation; reflect both vector magnitude and direction | Sensitive to vector scale; may require data normalization | Recommender systems, collaborative filtering, matrix decomposition | pgvector, Pinecone, Weaviate, Qdrant, Milvus |
| L2 Squared Euclidean Distance | Euclid's distance squared | Penalizes large differences between vector elements; more effective in some cases | Squaring operation may distort distances; more sensitive to outliers | Image processing, anomaly detection | Weaviate |
| Hamming Distance | Measurement of the number of different values corresponding to the position of a binary vector | Suitable for binary or categorical data; fast calculation speeds | Not applicable to continuous numeric data | Error detection and correction, DNA sequence matching | Weaviate, Milvus, Vespa |
| Manhattan Distance (L1) | Measure the sum of the distances between two vectors in the direction of the coordinate axes | More robust to outliers than Euclidean distance | Geometric meaning is less intuitive than Euclidean distance | Board distance calculations, city block distance calculations | Weaviate |
7.2.1 Cosine Distance: The First Choice for Text Similarity Calculation
Cosine distance measures the similarity of vectors by calculating the cosine of the angle between two vectors. The closer the cosine value is to 1, the more similar the vectors are; the closer the cosine value is to -1, the less similar the vectors are; and with a cosine value of 0, the vectors are orthogonal, indicating that they are not related.
- vantage::
- Focus on vector direction and ignore vector length: Cosine distance focuses on the direction of the vector and is not sensitive to the length of the vector. This makes it well suited for processing textual data, as the length of a document is often not the key factor in textual similarity calculations, while the subject matter and semantic direction of the document are important.
- For high-dimensional sparse data: In high-dimensional sparse data scenarios, the cosine distance can still maintain good performance and is suitable for similarity computation of high-dimensional sparse data such as text and user behavior.
- drawbacks::
- Insensitive to vector length information: In some scenarios, the length information of the vectors may also be important, e.g., in a recommender system, the user's activity level (vector length) may be an important feature. The cosine distance ignores this information and may lead to loss of information.
- Not applicable to non-convex datasets: If the data distribution is not a convex set, the cosine distance may not provide an accurate similarity measure, and a suitable similarity metric needs to be selected based on the data distribution.
- Applicable Scenarios::
- Text similarity calculation: For example, calculating the semantic similarity of two articles, two sentences or two paragraphs is a common metric for text similarity calculation.
- Document Categorization: The documents are classified into different categories based on the similarity of the document vectors.
- Recommended Systems: Recommendation based on user behavior or item characteristics, calculating the similarity between user vectors and item vectors for personalized recommendation.
- High-dimensional sparse data scenarios: For example, the similarity calculation of high-dimensional sparse data such as user behavior data and product feature data.
7.2.2 Euclidean Distance (L2): intuitive and easy to understand, but limited performance in higher dimensional spaces
The Euclidean distance, also known as the L2 norm, calculates the straight-line distance between two vectors in a multidimensional space. The smaller the distance, the more similar the vectors are; the larger the distance, the less similar the vectors are.
- vantage::
- Intuitive and easy to understand: The concept of Euclidean distance is simple and intuitive, easy to understand and use, and is one of the most common distance measures used by people.
- Consider both vector magnitude and direction: The Euclidean distance takes into account both the magnitude and direction of vectors, which provides a more complete picture of the differences in vectors, and is suitable for scenarios where the magnitude and direction of vectors need to be taken into account.
- drawbacks::
- The performance of higher dimensional space is degraded by "dimensional catastrophe": In high-dimensional space, the Euclidean distances between all points tend to be equal, leading to a decrease in the differentiation, affecting the accuracy of similarity search and limiting the performance in high-dimensional data scenarios.
- Sensitive to outliers: The Euclidean distance is sensitive to outliers, which significantly affect the distance calculation results and are less robust.
- Applicable Scenarios::
- Image Recognition: For example, face recognition, object recognition, etc., similarity comparison based on Euclidean distance of image feature vectors.
- Speech Recognition: For example, speech feature matching, similarity comparison based on Euclidean distance of speech feature vectors.
- Handwriting analysis: For example, handwritten character recognition, similarity comparison based on Euclidean distance of handwritten character feature vectors.
- Low-dimensional data scenarios: In low-dimensional data scenarios, Euclidean distance is still an effective similarity metric for similarity search in low-dimensional data.
7.2.3 Dot Product: Efficient calculation, suitable for recommender systems
The inner product, also known as the dot product, calculates the sum of the products of the corresponding components of two vectors. The larger the inner product, the more similar the vectors are; the smaller the inner product, the less similar the vectors are.
- vantage::
- Calculations are fast: The inner product is very fast, especially in the case of high vector dimensions, the performance advantage is more obvious, suitable for large-scale data and high concurrency scenarios.
- Reflects both vector magnitude and direction: The inner product takes into account both the magnitude and direction of the vectors, which reflects the overall similarity of the vectors, and is suitable for scenarios where the magnitude and direction of the vectors need to be taken into account.
- drawbacks::
- Sensitive to vector scales: The value of the inner product is affected by the scale of the vectors, and if the vectors have a large difference in scale, the similarity measure of the inner product may be distorted and sensitive to the scale of the vectors.
- Data normalization may be required: In order to eliminate the effect of vector scale differences, it is often necessary to normalize the data, e.g., normalize the vectors to unit length to ensure the accuracy of the similarity measure of the inner product.
- Applicable Scenarios::
- Recommended Systems: For example, to compute the similarity between user vectors and item vectors for personalized recommendations, the inner product is a commonly used similarity metric in recommender systems.
- Collaborative filtering: Recommendations are made based on the similarity of users or items, using the inner product to calculate the similarity between users or items.
- Matrix Decomposition: used for dimensionality reduction and feature extraction, and the inner product can be used to measure the similarity between vectors, aiding in the implementation of matrix decomposition algorithms.
- Scenarios requiring high performance computing: For example, large-scale online recommender systems, real-time retrieval systems, and other scenarios that require fast computation of vector similarity.
7.2.4 L2 Squared Euclidean Distance: amplifies differences, effective for specific scenes
L2 The square distance is the square of the Euclidean distance and is calculated as the square value of the Euclidean distance.
- vantage::
- penalize large differences between vector elements: The squaring operation magnifies the differences between vector elements, making the distance values more sensitive to differences. In some cases, this property may be more beneficial in distinguishing similarities and highlighting differences.
- Avoiding square root calculations improves computational efficiency: In some computational scenarios, square root calculations can be avoided, improving computational efficiency and simplifying the calculation process.
- drawbacks::
- Squaring operations may distort distances: The squaring operation changes the scale of the distance, which may result in a less interpretive meaning of the distance that is less intuitive than the Euclidean distance.
- More sensitive to outliers: The squaring operation further amplifies the effect of outliers, making the L2 squared distance more sensitive to outliers and less robust.
- Applicable Scenarios::
- Image Processing: For example, to compare two images at the pixel level, the L2 squared distance magnifies the pixel differences and compares the nuances of the images more effectively.
- Anomaly Detection: Amplifying the impact of outliers makes it easier to detect anomalous data and is suitable for outlier-sensitive anomaly detection scenarios.
- Specific scenarios where differences need to be amplified: The L2 square distance may be more effective than the Euclidean distance in certain specific scenarios where differentiation needs to be emphasized.
7.2.5 Hamming Distance: an exclusive metric for binary data
The Hamming distance measures the number of different values corresponding to the positions of two equal-length binary vectors, and is used to measure the degree of difference between binary vectors.
- vantage::
- For binary or categorical data: The Hamming distance is specifically used to measure differences in binary or categorical data and is suitable for similarity calculations for binary vectors.
- Calculations are fast: The calculation of the Hamming distance is very simple and efficient, and only requires comparing the corresponding positions of the binary vectors and counting the number of different values.
- drawbacks::
- Not applicable to continuous numeric data: The Hamming distance can only be used for binary or categorical data, and cannot handle continuous numeric data, and has limited applicability.
- Applicable Scenarios::
- Error detection and correction: For example, in communication coding, Hamming distance is used to measure the difference between code words for error detection and correction and is an important concept in coding theory.
- DNA sequence comparison: DNA sequences were converted to binary representation and sequence comparison was performed using the Hamming distance for bioinformatics analysis.
- Sub-type data similarity calculation: It is suitable for similarity calculation of sub-type data, e.g., similarity calculation of categorized data such as user labels and product attributes.
7.2.6 Manhattan Distance (L1): more robust distance metric, resistant to outliers
The Manhattan distance, also known as the L1 norm or city block distance, is calculated as the sum of the absolute differences between two vectors in all dimensions.
- vantage::
- More robust to outliers than the Euclidean distance: The Manhattan distance is not as sensitive to outliers as the Euclidean distance because it calculates only the absolute difference, not the squared difference, and is more robust and resistant to outlier interference.
- The calculations are relatively fast: The Manhattan distance is slightly faster than the Euclidean distance and is suitable for scenarios where the distance needs to be calculated quickly.
- drawbacks::
- The geometric significance is less intuitive than the Euclidean distance: The geometric significance of the Manhattan distance is less intuitive than the Euclidean distance, less easily understood, and less geometrically interpreted.
- Applicable Scenarios::
- Board distance calculation: For example, to calculate the distance between two squares on a chess board, the Manhattan distance is commonly used to calculate the board distance.
- Urban neighborhood distance calculations: For example, to calculate the distance between two locations in a city, ignoring distances in diagonal directions, the Manhattan distance is also known as the city block distance.
- The shortest path problem in logistics planning: The Manhattan distance can be used to evaluate path lengths in logistics planning and assist in the implementation of shortest path algorithms.
- Scenarios that are less sensitive to outliers: In scenarios where the effect of outliers needs to be reduced, the Manhattan distance is more applicable and robust than the Euclidean distance.
8. References
- https://github.com/milvus-io/milvus
- Powering Al With Vector Databases: A Benchmark - Part I - Data - Blog - F-Tech
- Fundamentals - Qdrant
- Milvus documentation
- Home | Weaviate - Vector Database
- Qdrant Documentation - Qdrant
- Vector Database Use Cases - Qdrant
- Vector Databases: Intro, Use Cases, Top 5 Vector DBs
- ANN-Benchmarks
- Distance Metrics in Vector Search - Weaviate
- BM25 - Baidu Encyclopedia
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles


No comments...