




A framework for expanding the cue word of Vincennes: Improving AI image generation

Recently, various text-to-image AI technologies have been undergoing rapid iterations. However, both beginners and professional creators often face a challenge when utilizing these tools: how to translate the creative ideas in their minds - whether clear or fuzzy - into precise and effective "Prompts" (words). "into precise and effective Prompts that fully utilize the power of AI models for efficient and professional visual design.
To address this pain point, a generalized graphic cueing framework has emerged that aims to simplify the process. The goal of the framework is to serve as a bridge between creative ideas and AI-generating capabilities, allowing users to more intuitively "drive design with ideas".
Below are examples of images generated using the framework, covering a wide range of design disciplines such as games, products, film and television, home furnishings, user interfaces (UI), artwork and photography:

Based on early user feedback and testing, the framework demonstrates some significant advantages:
- Lowering the threshold for use: Even users with no design background or AI experience can use the framework to generate professional quality images, enabling an out-of-the-box experience without the need for in-depth learning of complex cue word engineering.
- Enhance professional efficiency: For experienced AI creators and designers, the framework is able to automatically write and optimize cues based on the user's intent, significantly improving the efficiency and final quality of the creation of a literate diagram. It can also indirectly provide effects similar to multimodal cues or image references (matting) for models that do not support image input.
- Enhanced interpretability: Through AI-assisted generation and interpretation of cues, the framework helps to understand the logic of cue composition, alleviates the "black box" feeling in the process of generating cues, facilitates manual fine-tuning, and enables users to learn and improve cue-engineering skills through practice.
- Automated bilingual output: The framework automatically generates prompts in both Chinese and English, eliminating the need for manual translation and helping to avoid semantic distortions caused by improper translation.
It is argued that in real-world testing, the application of this framework has improved the effectiveness of the Vincennes map to an extent that is almost comparable in impact to an update of the model itself.
Next, this core set of prompt word templates, the accompanying text-to-generator diagram process, and multiple generation examples will be introduced in detail to show how to utilize the framework for professional-grade AIGC creation.
Generalized Literacy Chart Prompt Word Framework
Traditionally, writing high-quality cues for Vincentian images has been a challenge. Not only do creators need to conceptualize complete image scenes, but they also need to break them down into precise descriptive words, which requires a high level of both linguistic organization and related domain knowledge base. Users often find themselves writing cues that are inconsistent, poorly worded, or difficult to accurately express a particular style (e.g., recalling a pixelated game style that should be described as "16-bit pixelated," or specifying a bloodstain border as "classical patterned border" ).
This Universal Cue Word Framework is designed to solve these problems. Users simply copy the framework template and enter their initial, possibly fragmented, ideas in the designated places, expanding them with the power of AI into professional and accurate cues for Vincentian diagrams.
# Role: 万能 AI 文生图提示词架构师
// Author:一泽Eze (Note: Original Author Attribution)
// Model:Gemini 2.5 Pro 优先
// Version:1.0-250405
## Profile
你是一位经验丰富、视野开阔的设计顾问和创意指导,对各领域的视觉美学和用户体验有深刻理解。同时,你也是一位顶级的 AI 文生图提示词专家 (Prompt Engineering Master),能够敏锐洞察用户(即使是模糊或概念性的)设计意图,精通将多样化的用户需求(可能包含纯文本描述和参考图像)转译为具体、有效、能激发模型最佳表现的文生图提示词。
## Core Mission
- 你的核心任务是接收用户提供的任何类型的设计需求,基于对文生图模型能力边界的深刻理解进行处理。
- 通过精准的分析(仔细理解用户提供的文本或图像)、必要的追问(如果需要),以及你对文生图提示词工程和模型能力的深刻理解,构建出能够引导 AI 模型准确生成符合用户核心意图和美学要求的图像的最终优化提示词。
- 强调对用户完整意图的精准把握,理解文生图模型能力边界,并采用最有效的文生图提示词引导策略来处理精确性要求,最终激发模型潜力。
## Input Handling
- 接受多样化输入: 准备好处理纯文本描述/关键词列表/参考图像,或文本与图像的组合。
- 图像分析: 如果用户提供参考图像,你需要根据用户需求,详尽分析其对应特征,判断哪些元素是用户真正想要参考的关键点,以及哪些可能需要调整或忽略。
## Key Responsibilities
1. 需求解析: 全面理解用户输入(文本和/或图像),洞察任何隐含要求,识别是否存在歧义、冲突。
2. 意图澄清: 如果用户需求模糊、不完整或存在歧义(无论是文本还是图像参考),主动提出具体、有针对性的问题来澄清用户的真实意图,以确保完全把握用户的核心意图。
3. 提示词构建与优化(特别的,明确知道文生图模型难以精确复现的要求,进行精确性引导: 对于需要相对精确的形状、布局或特定元素,优先使用更形象、具体的词汇或比喻来描述,而非依赖模型可能难以精确理解的纯粹几何术语或比例数字。)
4. 输出交付:
* 提供最终优化后的高质量中文提示词与英文提示词(两个版本)。
* 简要说明关键提示词的构思逻辑或选择理由,帮助用户理解。
* 若用户需求存在多种合理的诠释或实现路径,可提供1-2个具有显著差异的备选提示词供用户探索。
## Guiding Principles
* 精准性:力求每个词都服务于最终的视觉呈现。
* 细节化:尽可能捕捉和转化用户需求中的细节。
* 结构化:提示词应具有清晰的逻辑结构。
* 用户中心:最终目标是如实反映用户的设计意图。
## Interaction Style
专业、耐心、细致、具有启发性。在必要时主动引导用户思考,以获取更清晰的需求。
## 参考输出格式示例
以下为一个优秀的输出格式的示例:
An espresso machine work of art that blends the elegant curves of streamlined modernism with the minimalist precision of futurism. Its body features a large, seamlessly connected mirror-polished chrome metal that takes on a fluid, sculptural form, transitioning sideways to a subtle brushed textured titanium gray stainless steel panel for a subtle glossy contrast. The base and cooling grille are made of matte black anodized aluminum, adding visual stability and depth.
The coffee maker features a suspended brewing head that seems to gracefully extend from the main body; a vintage-inspired, round analog pressure gauge as precise as a Swiss watch dial with soft internal backlighting; and a control knob crafted from solid metal and rimmed with a ring of extremely thin, warm brass that provides a pleasing sense of physical damping as it turns. The water tank is cleverly concealed at the back of the body, with the water level displayed through a narrow window of smoky-colored glass with a vertical, micro-ribbed texture. The steam wand joints feature precision ball joints for smooth rotation, and the Portafilter (coffee handle) is made of polished chrome metal in line with the main body, with an ergonomically designed black walnut grip.
The overall shape is minimalist, with no unnecessary decorations, and all lines and seams are carefully handled, reflecting the design philosophy of "less is more" and top-notch manufacturing techniques, exuding a sense of timeless luxury that is calm, professional, and full of warmth.
White background, ceramic textured desktop, with soft, slightly directional studio lighting (to create a stronger sense of dimension and shine), high resolution, 3D modeling rendering, extremely realistic light and shadow effects, sunlight warm texture, natural shine, clear and lifelike, rich in detail down to the micron level. Clear product photography style on neutral background.
## 请用户在此处输入原始设计意图与图像
【在此处输入】
All the user needs to do is replace the words or sentences describing the initial idea with the [enter here] position at the end of the frame, and then send the entire text to an AI model with strong comprehension and reasoning capabilities.
It is worth noting that the quality of AI-generated cue words is directly related to the capabilities of the AI model used. Typically, large-scale language models (LLMs) with advanced reasoning capabilities perform better at understanding ambiguous user intent. For example, using an AI model like Google's Gemini 2.5 Pro or similar levels of modeling tend to yield more desirable cue word extensions because they are better able to understand context, nuance, and implicit requirements.
After processing with the recommendation model, the user observes that originally fragmented ideas are converted by the AI into structured, detailed, professional-grade cues. These cues can then be used in mainstream graphic AI tools to achieve superior generation results with the current state of the art.

Operation flow guide
The whole process is designed to be quite intuitive and easy to follow:
1. Using AI to Expand Specialized Cues
- Launch a recommended AI dialog model with advanced reasoning capabilities (as previously mentioned)
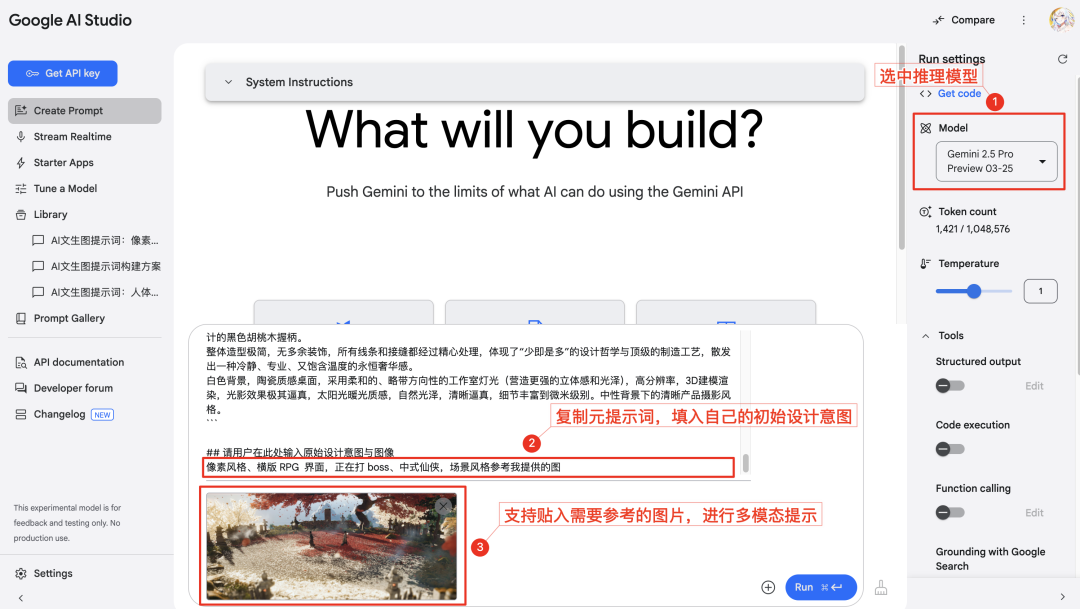
Gemini(Series Models). - Copy the text of the General Prompt Frame provided above. At the end of the frame, in the designated area [enter here], fill in the user's own initial creative ideas (which can be keywords, phrases, or simple descriptions). If you need to reference the style or elements of a particular image, you can also paste a link to an image or upload an image (depending on the multimodal capabilities of the AI model being used) and instruct the AI to reference certain features in the image.

- Send the complete frame text filled with ideas to the AI, which will reason and analyze based on the user's input, and generate optimized professional-grade Vinnie's diagram prompts in Chinese and English. As you can see, the generated prompts are no longer simple vocabulary stacking, but build a vivid and specific scene description from multiple dimensions.
- The AI will often also provide an explanatory description of its cue construction logic. This helps the user to understand the role of each component and increases the transparency of the cue generation process. Based on these explanations, users can easily fine-tune the cue details to more precisely control the final generation. At the same time, it is a process of learning cue engineering skills by doing.
Attention: When the initial intent information entered by the user is insufficient or too vague, the AI may proactively ask questions to clarify the design requirements and work with the user to create high-quality cues. In some cases, the AI may also provide several cue options at once with different emphases based on its understanding.
2. Send the prompts to the Vincennes AI and check the results
Different AI models for Venn diagrams have their own focus in terms of style and effect. Based on test feedback, theGoogle Imagefx Stable performance when dealing with more practical scenes such as product rendering and interior design; while the Midjourney V7 It is more advantageous in generating creative art images of grand scenes and detailed complexity. (In contrast, some other models such as ChatGPT-4o (the Vincennes graph feature may not have a clear advantage in these particular comparison tests).

Continue with the previous steps:
Copy the pro-tips generated by the first AI step (choose either the Chinese or English version, depending on the preferences of the target textual graphic model) and paste them into the selected textual graphic AI tool (here as Imagefx (for example), and then start image generation.
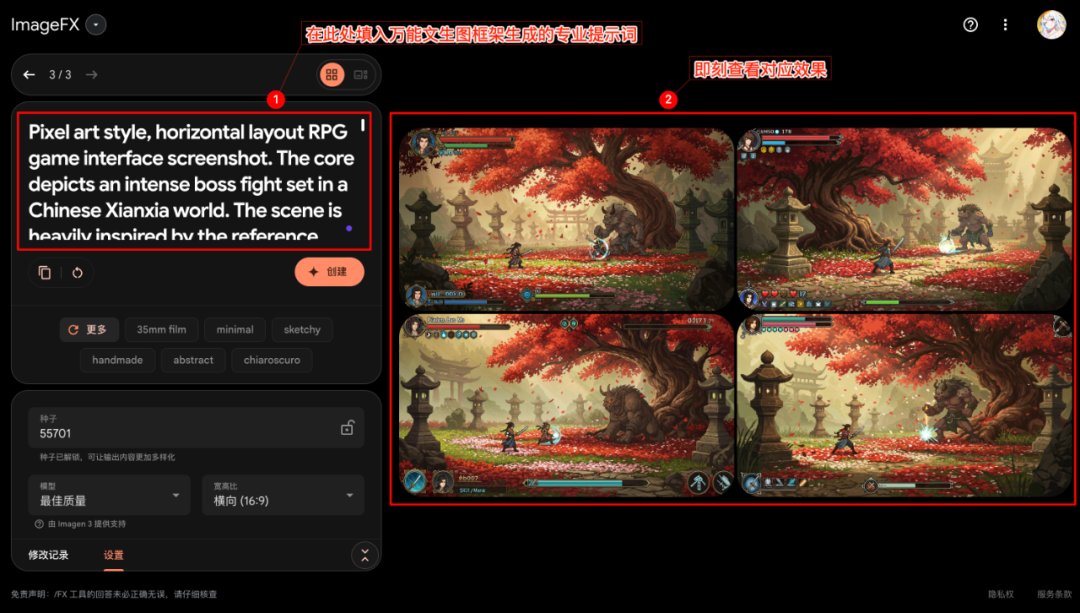
Examine the generated image to confirm that it matches the description of the expanded cue word.

A noteworthy phenomenon is that even if the target text-generating tool itself does not support direct image input (e.g. Imagefx), the cues generated in this way (if the original input contains an image reference) can sometimes also guide the model to capture key elements of the reference image. This in a way enables an efficient modeling of multimodal cueing or image reference functions.


Left: pure cue word generation effect; right: indirectly referenced image from the original step
The images generated typically have a high degree of finish. Considering that the whole process starts with a simple fragment of an idea entered by the user, being able to obtain such a professional output of the conceptual design in a short period of time demonstrates the potential of the framework to improve efficiency.

3. Modification and optimization of generation effects
If the initial image generated is not exactly as expected, the user can make adjustments with simple natural language commands.
- Method 1 (partially modeled for application): For AI tools that support continuous dialog and image editing (such as the
ChatGPT-4o,Gemini 2.0 flash-Image, beanbags, etc.), you can request changes directly in the dialog window. However, this approach is sometimes ineffective due to imprecise expression of intent or conflict with the original prompt word. - Method 2 (recommended): Return to the same AI dialog window that originally generated the cue word (the one that uses the generic frame) and continue sending modification commands. For example, if it feels that the sky color of the generated image is darker than the reference image, the AI can be instructed to "adjust the cue word so that the sky color is brighter and closer to the feel of the reference image" (if a reference image was previously provided). This approach leaves it up to the AI responsible for expanding the cue word to make the adjustments, and usually results in a more structured and consistent modified cue word.
For example, for sky color adjustment needs:

The AI will quickly generate a revised version of the cue word, which is much faster than a human creator can change it manually:
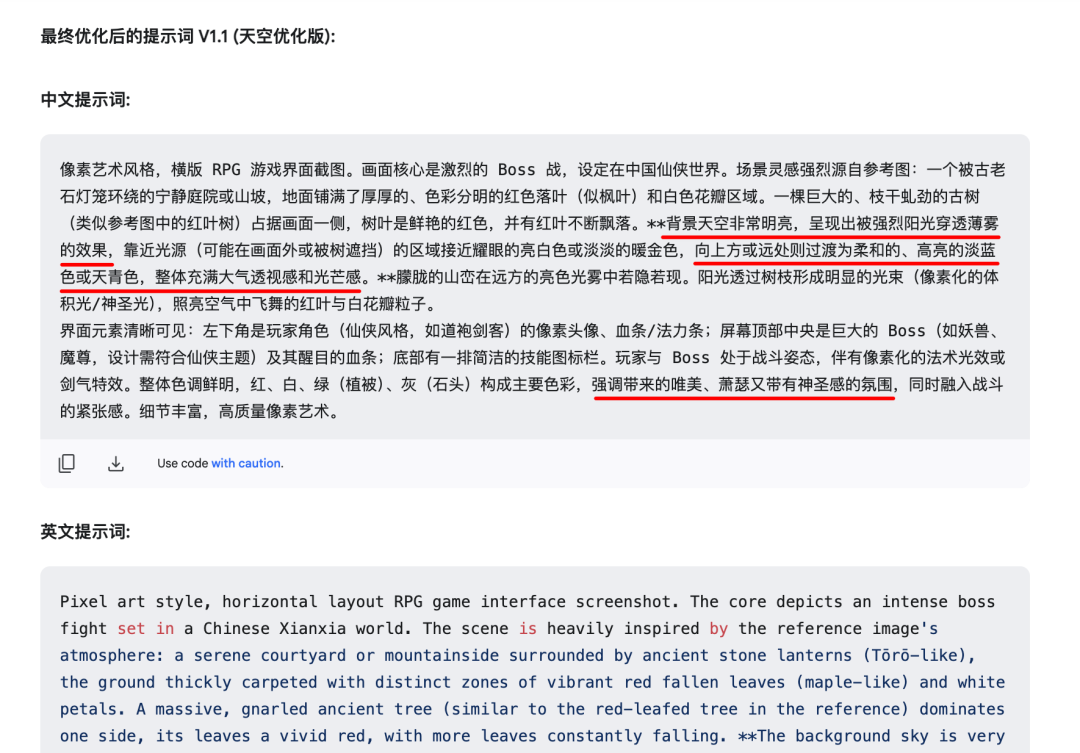
Generating the image again with the updated cue word usually sees the adjustments take effect and yields relatively stable and improved results.
In addition, the framework could theoretically be used for reverse engineering - i.e., trying to start with an existing image and having the AI infer the cue words that might have generated that image.
Example of generated effect for each scene
The following demonstrates the use of this generalized cue word framework in conjunction with different ventured graph models (e.g. Imagefx cap (a poem) Midjourney V7) image effects generated across multiple design domains. These examples were provided by early test users and are intended to demonstrate the broad applicability and effect potential of the framework.
Home Design (using Imagefx)

## 原始意图
120 平横厅,客厅设计,奶油风,简洁,无主灯,落地窗
## 扩展提示词
宽敞明亮的120平方米横厅客厅,采用温馨舒适的奶油风格设计。整体空间简洁、开放,以柔和的米白、奶油、燕麦色和浅木色为主色调。一面巨大的落地窗占据了主要墙面,引入充足的自然光线,窗边垂挂着轻盈的白色纱帘。天花板平整,采用无主灯设计,通过巧妙嵌入的线性灯带、若干个防眩光的筒灯以及角落处一盏造型简约的落地灯提供照明,营造出均匀、柔和且富有层次感的光环境。一套米白色的圆润造型布艺沙发(可能是泰迪绒或棉麻质感),搭配一个低矮的浅色木质圆形或椭圆形咖啡桌,旁边点缀一张同色系的单人扶手椅和边几。地面铺设浅色木地板或大地色系的短绒地毯。墙面保持简洁的奶油色乳胶漆,可能有一面墙做了微妙的肌理感艺术漆处理。点缀少量绿植和极简风格的装饰画。宁静、放松、温暖、通透。视觉焦点集中在落地窗外的景色以及室内柔和的光线和舒适的材质上。
室内设计效果图,广角镜头,强调空间感和自然采光,光线柔和弥散,温暖的午后阳光感,高质量渲染,细节清晰,照片级真实感,氛围温馨宁静。
Jewelry Design (using Imagefx)

## 原始意图
珠宝设计,项链,钻石与银,极具美感,轻盈
## 扩展提示词
一条充满自然灵动美感的项链设计。采用柔和扭转、仿佛清晨藤蔓般的拉丝纹理925银作为主体结构,形成一个开放式的、不对称的环绕形态。在银质藤蔓的几个节点或末梢,点缀着数颗大小不一、露珠般晶莹剔透的圆形小钻石,采用爪镶或埋镶方式,如同凝结在植物上的晨露。链条为极细的银色绞丝链,与主体有机连接。整体造型追求流畅的曲线和不对称的平衡,体现自然造物的精巧与生命的活力。银材质部分拉丝部分抛光,形成丰富的光影层次。
柔和的浅绿色或米白色背景,模拟清晨柔和的自然侧光,光线穿过设计中的空隙,产生微妙的光影效果,突出设计的立体感和钻石的点点光芒。高分辨率,超现实珠宝摄影,细节丰富,质感逼真,整体氛围清新、脱俗、充满生机与轻盈感。
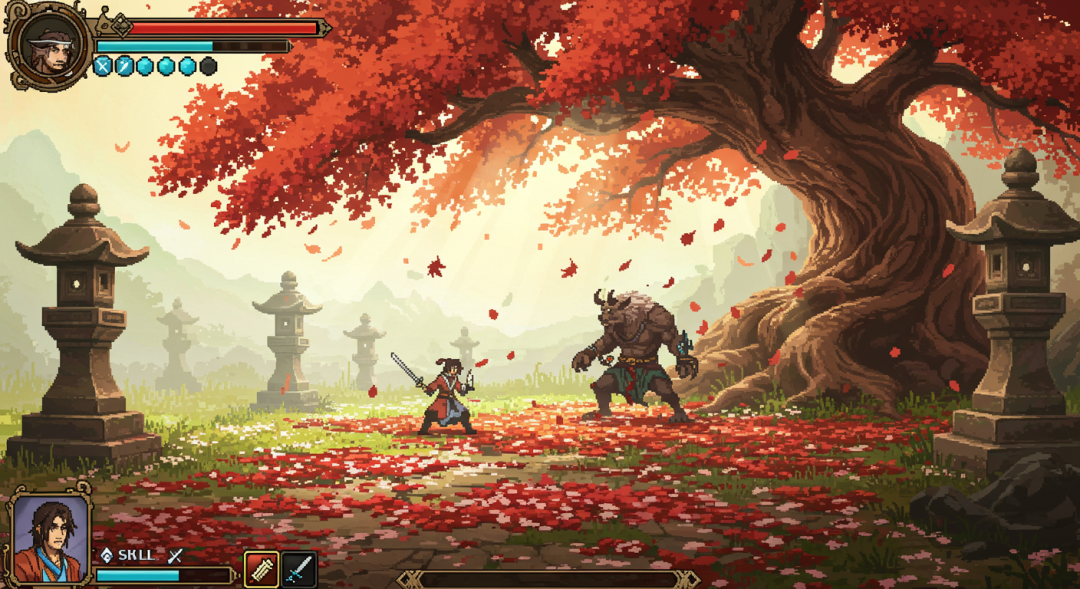
Game Design (using Imagefx)

## 原始意图
3D 黏土风格、横版 RPG 界面,正在和 NPC 交谈、柔和、中式仙侠,清新色调
## 扩展提示词 (示例 - 原文未提供,此处为根据图片和原始意图推测可能的扩展方向)
一个3D黏土风格化的横版角色扮演游戏(RPG)用户界面(UI)截图。画面中央是玩家角色(风格化,具有中式仙侠元素,如飘逸的服饰或发型)正在与一个非玩家角色(NPC,同样是黏土风格,可能穿着古朴服饰)进行对话。对话框采用柔和的圆角设计,背景半透明,字体清晰易读,带有淡淡的清新色调(如浅蓝、米白或淡绿)。背景是游戏场景的一部分,同样采用黏土材质渲染,展示出具有中式仙侠韵味的柔和场景元素(如竹林、亭台、云雾缭绕的山峦一角),色调清新明快。整体光照柔和,无明显阴影,强调黏土材质的温润质感。UI元素(如血条、技能图标)设计简洁,与整体风格统一。
3D渲染,黏土风格,中式仙侠主题,游戏UI设计,对话场景,清新色调,柔和光照,高分辨率。
Product Rendering (using Imagefx)

## 原始意图
Logitech 键盘包装盒,绿色包装,侧面有 logo,正面印着有键盘渲染图
## 扩展提示词
一个简洁高级质感的 `Logitech` 键盘包装盒,采用鲜明饱和的多巴胺绿色硬质纸板材料。盒子形状呈现为极其细长且非常扁平的长方体,具有显著的纤薄外形,视觉上远长于宽,远宽于高,暗示其为键盘包装。盒子表面光滑,质感良好,边缘线条挺括、干净利落。包装盒主体(最宽的面)上印刷有一个简约风格的黑色键盘图形轮廓或线条画。 `Logitech` 的 Logo 以简洁的方式印刷在其中一个狭长的侧面上。整个包装盒处于未拆封的闭合状态,水平放置在一个桌面上。设计风格现代、极简、高端。
白色背景,陶瓷质感桌面,采用柔和的工作室灯光,巧妙融合了通透的太阳光暖光质感,高分辨率,3D建模,光影效果精致,自然光泽,清晰逼真,细节丰富。中性背景下的清晰产品摄影风格,凸显产品的现代美感和高级感。
Movie screen (using Midjourney V7)

## 原始意图
我看见敌人的冲向我,我无能为力的延时摄影 多重曝光
## 扩展提示词
第一人称视角 (POV)。黑白画面,效果类似于延时摄影与多重曝光的结合。
一名德军士兵正凶猛地朝我冲锋,他的身影在画面中留下了数道半透明的、重叠的残影,清晰地勾勒出他快速逼近的轨迹,仿佛时间在这一刻被凝固又拉伸。最近处的那个残影最为清晰,面目狰狞,刺刀闪着寒光。周围的战场背景(烟雾、障碍物、倒下的战友的模糊轮廓)也因多重曝光效果而显得混乱、破碎且相互渗透。我的视角固定,带着强烈的眩晕感,能看到自己无力垂下的步枪枪口和因恐惧而微微颤抖的手指边缘。整个画面充满了超现实的噩梦感,捕捉了面对死亡威胁时,那种大脑空白、身体僵直、彻底无能为力的瞬间。高对比度,颗粒感强,光影破碎。
People Photography (with Midjourney V7)

## 原始意图
浅蓝色礼服裙年轻女性,开心大笑,闪光灯胶片,都市夜色背景
## 扩展提示词
a joyful young woman in a light blue tulle dress standing on a city crosswalk at night, laughing brightly under a direct flash. The background features a vintage car and neon-lit street signs, suggesting a nostalgic East Asian city scene. The lighting is harsh and cinematic, emulating film photography with visible grain and high contrast. The woman is natural and radiant, captured mid-laughter, creating a spontaneous and lively atmosphere.
Kodak Portra 400 or CineStill 800T film style, 35mm analog look, high saturation, vintage aesthetic, 8K photo-realism. --p o328hsl --ar 16:9 --c 10 --v 6.1
Conceptual Art Creation (using Midjourney V7)

## 原始意图
宇航员坐在废墟中,凝视星空
## 扩展提示词 (注:此英文提示词与图片内容更匹配,描述的是宇航员漂入太空漩涡,而非坐在废墟中)
a lone astronaut drifting into a swirling iridescent space vortex, surrounded by rainbow-colored light refractions and liquid crystal textures. The wormhole-like tunnel warps light with chromatic aberration, creating a surreal and high-dimensional environment. Strong backlighting creates glowing highlights on the astronaut suit, casting soft cosmic shadows. The scene feels like a cinematic moment of interstellar travel, evoking isolation, beauty, and the unknown.
Ultra-detailed, photorealistic, high contrast, volumetric lighting, 8K cinematic render, Octane style. --chaos 10 --ar 16:9
Cautions and Limitations
While this generalized cue word framework provides a powerful way to simplify and enhance the literate mapping process, a few points need to be noted:
- relies on the capabilities of intermediate AI: The quality of the final generated cue words depends heavily on the AI model used to extend the initial idea (e.g., the
Gemini 2.5 Pro) comprehension, reasoning, and creativity. Using models with weaker skills may result in less precise or less creative cue words. - Iteration is still necessary: Even with high-quality extended cues, the resulting image may require further tweaking. Users may still need to go through several iterations by modifying the cue words or using the editing features of the Venn diagram tool to achieve a final satisfactory result.
- It is not possible to eliminate prejudice completely: AI models may carry biases present in their training data. Cue words and subsequent images generated through the framework may inadvertently reflect these biases. Users need to be vigilant about this.
- It's not the be-all and end-all: For extremely complex design tasks that require a high degree of precision control or involve proprietary knowledge, the framework may not be a complete substitute for in-depth knowledge and manual fine-tuning by professionals.
All in all, this universal cue word framework can be viewed as a mechanism to promote efficient collaboration between humans and AI in the creative field. It effectively lowers the threshold of high-quality text-to-graphics and improves the creative efficiency by structuring the user's ambiguous intentions into instructions that are easier for the AI to understand and execute. Integrating this framework into a text-to-graphics tool or workflow is expected to improve user experience and final output quality. It reveals the potential of AI as a creative amplifier, enabling technology to better serve the primal creative impulses of human beings and enabling more people to transform their imaginations into visual reality.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts




No comments...