
A 10,000-word article comprehending the development process of LLM-based Text-to-SQL

OlaChat AI Digital Intelligence Assistant 10,000-word in-depth analysis to take you through the past and present of Text-to-SQL technology.
Thesis: Next-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL
Generating accurate SQL from natural language problems (text-to-SQL) is a long-standing challenge because of the complexity in user problem understanding, database schema understanding, and SQL generation. Traditional text-to-SQL systems, includingArtificial Engineering and Deep Neural Networks, substantial progress has been made. Subsequently.Pre-trained language models (PLMs) have been developed and used for text-to-SQL tasks, achieving promising performance. As modern databases have become more complex, the corresponding user problems have become more challenging, leading to parameter-constrained PLMs (pre-trained models) producing incorrect SQL.This requires more sophisticated custom optimization methods, which in turn limits the application of PLM-based systems.
Recently, Large Language Models (LLMs) have demonstrated significant capabilities in natural language understanding as the size of the models grows. Therefore, integrating LLM-based implementationscan bring unique opportunities, improvements, and solutions to text-to-SQL research. In this survey, the paper presents a comprehensive review of LLM-based text-to-SQL. specifically, the authors present a brief overview of the technical challenges and evolutionary process of text-to-SQL. Then, the authors provide a detailed description of the datasets and evaluation metrics designed to assess text-to-SQL systems. Afterwards, the paper systematically analyzes recent advances in LLM-based text-to-SQL. Finally, remaining challenges in the field are discussed and expectations for future research directions are presented.
The papers specifically referred to by "[xx]" in the text can be consulted in the references section of the original paper.
introductory
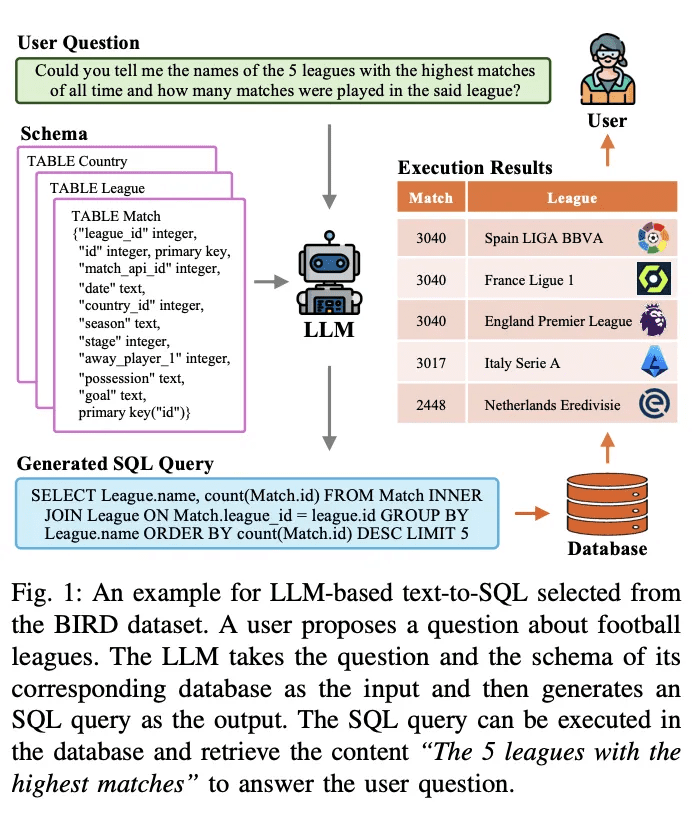
Text-To-SQL is a long-standing task in natural language processing research. It aims at converting (translating) natural language problems into database-executable SQL queries. Figure 1 provides an example of a text-to-SQL system based on a large-scale language model (LLM-based). Given a user question, e.g., "Can you tell me the names of the 5 most played leagues in history and how many games were played in that league?", the LLM translates the question and its corresponding query into an executable SQL query. LLM takes the question and its corresponding database schema as input and analyzes it. It then generates an SQL query as output. This SQL query can be executed in the database to retrieve relevant content to answer the user's question. The above system uses LLM to build a natural language interface to the database (NLIDB).
Since SQL is still one of the most widely used programming languages, with half (51.52%) of professional developers using SQL in their work, and notably, only about one-third (35.29%) of developers are trained in the system, NLIDB enables unskilled users to access structured databases like professional database engineers [1 , 2] and also accelerates human-computer interaction [3]. In addition, among the research hotspots in LLM, text-to-SQL can fill the knowledge gap in LLM by combining real content in databases, providing potential solutions to the pervasive problem of illusions [4, 5] [6]. The great value and potential of text-to-SQL has triggered a series of studies on its integration and optimization with LLM [7-10]; thus, text-to-SQL based on LLM remains a highly discussed research area in the NLP and database communities.
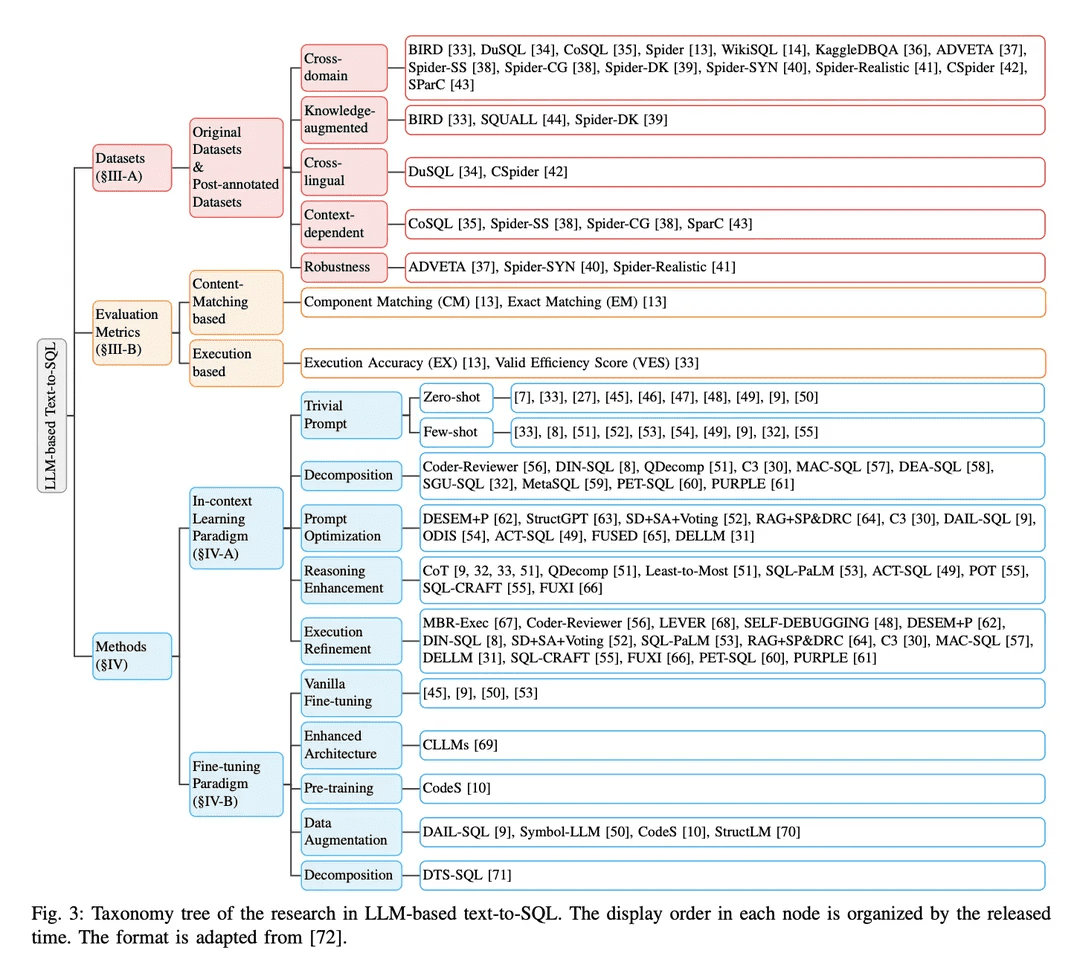
Previous research has made significant progress in implementing text-to-SQL and has undergone a long evolutionary process. Most of the early research was based on well-designed rules and templates [11], which were particularly suitable for simple database scenarios. In recent years, designing rules or templates for each scenario has become increasingly difficult and impractical with the high labor costs associated with rule-based approaches [12] and the growing complexity of database environments [13 - 15]. Advances in text-to-SQL have been fueled by the development of deep neural networks [16, 17], which automatically learn mappings from user questions to the corresponding SQL [18, 19]. Subsequently, pre-trained language models (PLMs) with powerful semantic parsing capabilities became the new paradigm for text-to-SQL systems [20], taking their performance to a new level [21 - 23]. Progressive research on PLM-based optimizations (e.g., table content encoding [ 19 , 24 , 25 ] and pre-training [ 20 , 26 ]) has further advanced the field. Recently.The LLM-based approach implements text-to-SQL transformation through context learning (ICL) [8] and fine-tuning (FT) [10] paradigmsThe company achieves state-of-the-art accuracy with a well-designed framework and greater understanding than PLM.
The overall implementation details of LLM-based text-to-SQL can be divided into three areas:
1) Understanding of the problem: NL questions are semantic representations of user intent, and the corresponding generated SQL queries should be consistent with them;
2) Pattern Understanding: The schema provides the table and column structure of the database, and the text-to-SQL system needs to recognize the target components that match the user's problem;
3) SQL Generation: this involves combining the above parsing and then predicting the correct syntax to generate an executable SQL query to retrieve the desired answer. It has been shown that LLMs can implement text-to-SQL functionality well [7, 27], thanks to the enhanced semantic parsing capabilities that come with richer training corpora [28, 29]. Further research on enhancing LLMs for problem understanding [8, 9], pattern understanding [30, 31] and SQL generation [32] is growing.
Despite significant progress in text-to-SQL research, there are still challenges that hinder the development of robust and generalized text-to-SQL systems [ 73 ]. Relevant research in recent years has surveyed text-to-SQL systems in deep learning approaches and provided insights into previous deep learning approaches and PLM-based research. The aim in this survey is to catch up with the latest advances and to provide a comprehensive review of current state-of-the-art models and approaches for LLM-based text-to-SQL. The basic concepts and challenges associated with text-to-SQL are first introduced, emphasizing the importance of this task in various domains. Then, an in-depth look at the evolution of implementation paradigms for text-to-SQL systems is presented, discussing the main advances and breakthroughs in the field. The overview is followed by a detailed description and analysis of recent advances in text-to-SQL with LLM integration. Specifically, this survey paper covers a range of topics related to LLM-based text-to-SQL, including:
● Data sets and benchmarks: A detailed description of commonly used datasets and benchmarks for evaluating LLM-based text-to-SQL systems. Their characteristics, complexity, and the challenges they pose for text-to-SQL development and evaluation are discussed.
● Assessment of indicators: The evaluation metrics used to assess the performance of LLM-based text-to-SQL systems will be presented, including content-matching-based and execution-based examples. The characteristics of each metric are then briefly described.
● Methods and models: This paper presents a systematic analysis of different approaches and models used for LLM-based text-to-SQL, including examples based on contextual learning and fine-tuning. Their implementation details, advantages, and adaptations for text-to-SQL tasks are discussed from different implementation perspectives.
● Expectations and future directions: This paper discusses the remaining challenges and limitations of LLM-based text-to-SQL, such as real-world robustness, computational efficiency, data privacy, and scaling. Potential future research directions and opportunities for improvement and optimization are also outlined.
summarize
Text-to-SQL is a task that aims to transform natural language questions into corresponding SQL queries that can be executed in a relational database. Formally, given a user question Q (also known as a user query, a natural language question, etc.) and a database schema S, the goal of the task is to generate an SQL query Y that retrieves the required content from the database to answer the user question. Text-to-SQL has the potential to democratize data access by allowing users to interact with the database using natural language without requiring expertise in SQL programming [75]. By enabling unskilled users to easily retrieve targeted content from databases and facilitating more effective data analysis, this can benefit areas as diverse as business intelligence, customer support, and scientific research.
A. Challenges in Text-to-SQL
The technical challenges of the text-to-SQL implementation can be summarized as follows:
1)Linguistic complexity and ambiguity: Natural language problems often contain complex linguistic representations such as nested clauses, co-references, and ellipses, which make it challenging to accurately map them to the corresponding parts of SQL queries [41]. Furthermore, natural language is inherently ambiguous, with multiple possible representations for a given user problem [76, 77]. Resolving these ambiguities and understanding the intent behind the user problem requires deep natural language understanding and the ability to integrate context and domain knowledge [33].
2)Pattern understanding and representation: In order to generate accurate SQL queries, text-to-SQL systems require a thorough understanding of the database schema, including table names, column names, and relationships between individual tables. However, database schemas can be complex and vary widely between domains [13]. Representing and encoding schema information in a way that can be effectively utilized by text-to-SQL models is a challenging task.
3)Rare and complex SQL operations: Some SQL queries involve rare or complex operations and syntax in challenging scenarios, such as nested subqueries, outer joins, and window functions. These operations are less common in the training data and pose a challenge for accurate generation of text-to-SQL systems. Designing models that generalize to a variety of SQL operations, including rare and complex scenarios, is an important consideration.
4)cross-domain generalization: Text to SQL systems are often difficult to generalize across various database scenarios and domains. Due to the diversity of vocabularies, database schema structures, and problem patterns, models trained in a specific domain may not handle problems posed in other domains well. Developing systems that can be effectively generalized to new domains using minimal domain-specific training data or fine-tuned adaptations is a major challenge [78].
B. Evolutionary processes
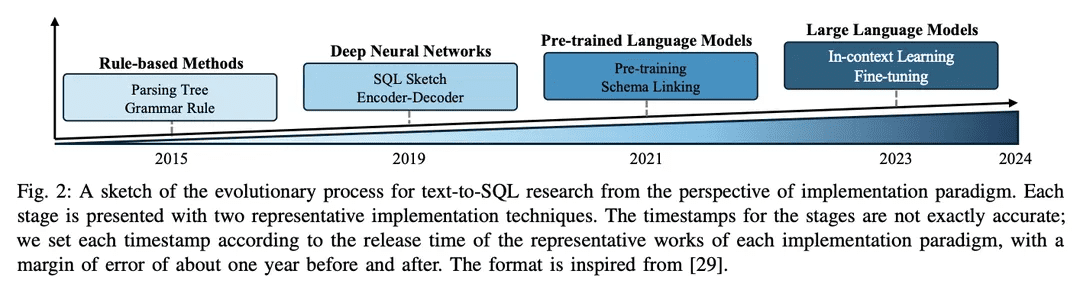
The field of text-to-SQL research has made great strides in the NLP community over the years, evolving from rule-based to deep learning-based approaches, and more recently to integrating pre-trained language models (PLMs) and large-scale language models (LLMs), with a sketch of the evolutionary process shown in Figure 2.
1) Rule-based approach: Early text-to-SQL systems relied heavily on rule-based approaches [11, 12, 26], i.e., the use of manually formulated rules and heuristics to map natural language problems to SQL queries. These approaches typically involve significant feature engineering and domain-specific knowledge. While rule-based approaches have been successful in specific simple domains, they lack the flexibility and generalization capabilities needed to handle a wide range of complex problems.
2)Deep learning based approach: With the rise of deep neural networksSequence-to-sequence model and encoder-decoder architecture(e.g., LSTM [ 79] and converters [17]) are used to generate SQL queries from natural language input [ 19 , 80 ]. Typically, RYANSQL [19] introduces techniques such as intermediate representations and sketch-based slot filling to handle complex problems and improve cross-domain generalization. Recently, researchers have utilized schema-dependentGraphs capture relationships between database elementsThe first step was to introduce a new text-to-SQL task, called theGraph Neural Networks (GNN)[18,81].
3) PLM-based implementation: Pre-trained Language Models (PLMs) have emerged as powerful solutions for text-to-SQL by leveraging the vast linguistic knowledge and semantic understanding gained during pre-training.Early applications of PLMs in text-to-SQL focused on fine-tuning off-the-shelf PLMs on standard text-to-SQL datasets, such as BERT [24] and RoBERTa [82] [13, 14]. These PLMs are pre-trained on a large training corpus, capturing rich semantic representations and language comprehension capabilities. By fine-tuning them in text-to-SQL tasks, researchers aim to utilize the semantic and linguistic understanding capabilities of PLMs to generate accurate SQL queries [ 20, 80, 83]. Another research direction is to incorporate schema information into PLMs in order to improve the way these systems can help users understand database structures and generate more executable SQL queries. Schema-aware PLMs are designed to capture the relationships and constraints present in the database structure [21].
4) LLM-based implementation: Large Language Models (LLMs), such as the GPT family [ 84 -86 ], have received much attention in recent years for their ability to generate coherent and fluent text. Researchers have begun to explore the potential of text-to-SQL by utilizing the extensive knowledge base and superior generative capabilities of LLMs [7, 9]. These approaches typically involve directing the hint engineering of proprietary LLMs during SQL generation [47], or fine-tuning open-source LLMs on text-to-SQL datasets [9].
Integrating LLM in text-to-SQL is still an emerging research area with great potential for further exploration and improvement. Researchers are investigating how to better utilize the knowledge and reasoning capabilities of LLM, incorporate domain-specific knowledge [31, 33 ], and develop more efficient fine-tuning strategies [ 10 ]. As the field continues to evolve, it is expected that more advanced and superior LLM-based implementations will be developed that will take text-to-SQL performance and generalization to new heights.
Benchmarking and assessment
In this section, the paper presents text-to-SQL benchmarks, including well-known datasets and evaluation metrics.
A. Data sets
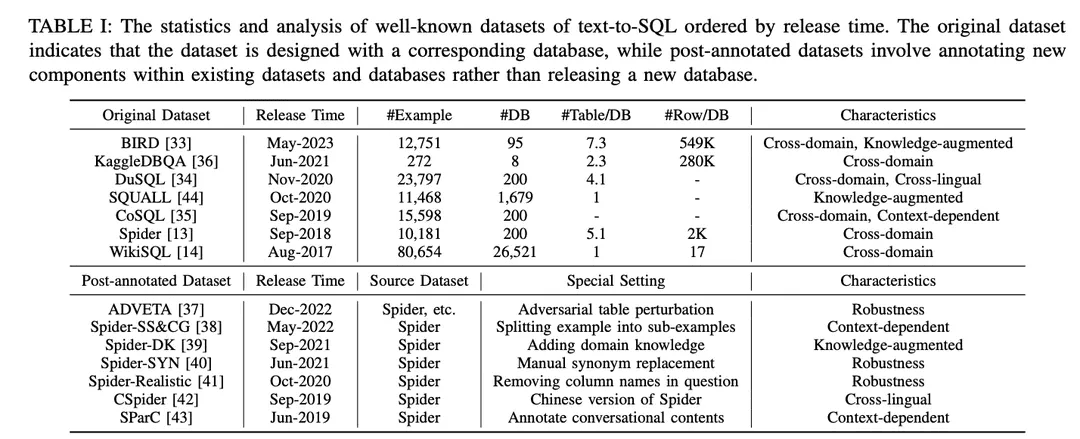
The datasets are categorized into "Original datasets" and "Post-annotation datasets" as shown in Table I. The datasets are categorized into "original datasets" and "post-annotation datasets" according to whether the datasets are published with the original datasets and databases or created by making special settings to the existing datasets and databases. For the original dataset, a detailed analysis is provided, including the number of examples, the number of databases, the number of tables per database, and the number of rows per database. For the annotated datasets, their source datasets are identified and the particular settings applied to them are described. To illustrate the potential opportunities of each dataset, it is annotated according to its characteristics. The annotations are listed on the far right side of Table I. They are discussed in more detail below.
1) Cross-domain datasets: refers to datasets where the background information for different databases comes from different domains. Since real-world text-to-SQL applications usually involve databases from multiple domains, most of the original text-to-SQL datasets [13,14,33 - 36] and post-annotation datasets [37 -43] are in a cross-domain setup, which is a good fit for cross-domain applications.
2) Knowledge-enhanced datasets: In recent years, there has been a significant increase in interest in incorporating domain-specific knowledge into text-to-SQL tasks.BIRD [ 33 ] utilizes human database experts to annotate each text-to-SQL sample with external knowledge categorized as numerical reasoning knowledge, domain knowledge, synonym knowledge, and value descriptions. Similarly, Spider-DK [ 39] manually edited a version of the Spider dataset [13] for human editors: the SELECT column was omitted, simple reasoning was required, synonym substitutions in cell-valued words, a non-cell-valued word generates a condition, and is prone to conflict with other domains. Both studies found that manually annotated knowledge significantly improved SQL generation performance for samples requiring external domain knowledge. In addition, SQUALL [44] manually annotates the alignment between words in NL problems and entities in SQL, providing finer-grained supervision than in other datasets.
3) Contextually relevant datasets: SParC [43] and CoSQL [35] explore context-sensitive SQL generation by building a query system for conversational databases. Unlike traditional text-to-SQL datasets that have a single question SQL pair with only one example, SParC decomposes the question SQL examples in the Spider dataset into multiple sub-question SQL pairs to build simulated and meaningful interactions, including interrelated sub-questions that contribute to SQL generation, and unrelated sub-questions that enhance data diversity. In contrast, CoSQL involves conversational interactions in natural language, simulating real-world scenarios to increase complexity and variety. Furthermore, Spider-SS&CG [38] splits the NL problem in the Spider dataset [13] into multiple subproblems and sub-SQLs, demonstrating that training on these subexamples improves the generalization ability distribution samples of the text-to-SQL system.
4) Robustness datasets: Evaluating the accuracy of a text-to-SQL system in the presence of contaminated or scrambled database content (e.g., schemas and tables) is crucial for assessing robustness.Spider-Realistic [ 41] removes explicitly schema-related terms from NL questions, while Spider-SYN [ 40] replaces them with manually selected synonyms.ADVETA [ 37 ] introduced adversarial table perturbation (ATP), which perturbs the table by replacing the original column names with misleading alternatives and inserting new columns with high semantic relevance but low semantic equivalence. These perturbations can lead to a significant drop in accuracy, as less robust text-to-SQL systems can be misled by mis-matches between tokens and database entities in NL problems.
5) Cross-language datasets: SQL keywords, function names, table names, and column names are often written in English, which poses a challenge for applications in other languages.CSpider [ 42 ] translates the Spider dataset into Chinese, and discovers new challenges in word segmentation and cross-language matching between Chinese questions and English database content.DuSQL [34] introduces a practical text-to-SQL dataset with Chinese questions and English and Chinese database contents.
B. Assessment indicators
The following four widely used evaluation metrics are introduced for text-to-SQL tasks: "Component Matching" and "Exact Matching" based on SQL content matching, and "Execution Accuracy" based on execution results " and "Effective Efficiency Score".
1) Metrics based on content matching: The SQL content matching metric is primarily based on the structural and syntactic similarity of the predicted SQL query to the underlying real SQL query.
Component Matching (CM)[13] The performance of a text-to-SQL system is evaluated by measuring the exact match between predicted SQL components (SELECT, WHERE, GROUP BY, ORDER BY, and KEYWORDS) and real SQL components (GROUP BY, ORDER BY, and KEYWORDS) using F1 scores. Each component is decomposed into a set of sub-components and compared for exact matches taking into account SQL components with no order constraints.
Exact Match (EM))[ 13] measures the percentage of examples where the predicted SQL query is exactly the same as the ground truth SQL query. A predicted SQL query is considered correct only if all of its components (as described in CM) exactly match the components of the ground truth query.
2) Implementation-based indicators: The Execution Results metric evaluates the correctness of the generated SQL query by comparing the results obtained by executing the query on the target database with the expected results.
Execution accuracy (EX)[13] The correctness of a predicted SQL query is measured by executing the query in the corresponding database and comparing the execution results with those obtained from the base true query.
Effective Efficiency Score (VES)The definition of [33] is to measure the efficiency of an effective SQL query. An effective SQL query is a predicted SQL query whose execution result is identical to the underlying true result. Specifically, VES simultaneously evaluatesPredicting the efficiency and accuracy of SQL queries. For a text dataset containing N examples, VES is computed as:

R(Y_n, Y_n) denotes the relative execution efficiency of the predicted SQL query compared to the real query.
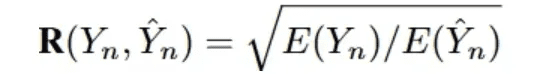
Most recent LLM-based text-to-SQL research has focused on these four datasets, Spider [13], Spider-Realistic [41], Spider-SYN [40], and BIRD [33]; and the three evaluation methods, EM, EX, and VES, which will be the focus of the following analysis.
methodologies
Current implementations of LLM-based applications rely heavily on the contextual learning (ICL) (immediate engineering) [87-89] and fine-tuning (FT) [90,91] paradigms, as powerful proprietary and well-architected open-source models are being released in large numbers [45,86,92-95]. LLM-based text-to-SQL systems follow these paradigms for implementation. In this survey, they will be discussed accordingly.
A. contextual learning
Through extensive and well-recognized research, hint engineering has been shown to play a decisive role in the performance of LLMs [28 , 96 ], as well as influencing SQL generation under different hint styles [9 , 46]. Therefore, the development of text-to-SQL methods in the contextual learning (ICL) paradigm is valuable for realizing promising improvements. An implementation of an LLM-based text-to-SQL process that generates an executable SQL query Y can be formulated as follows:

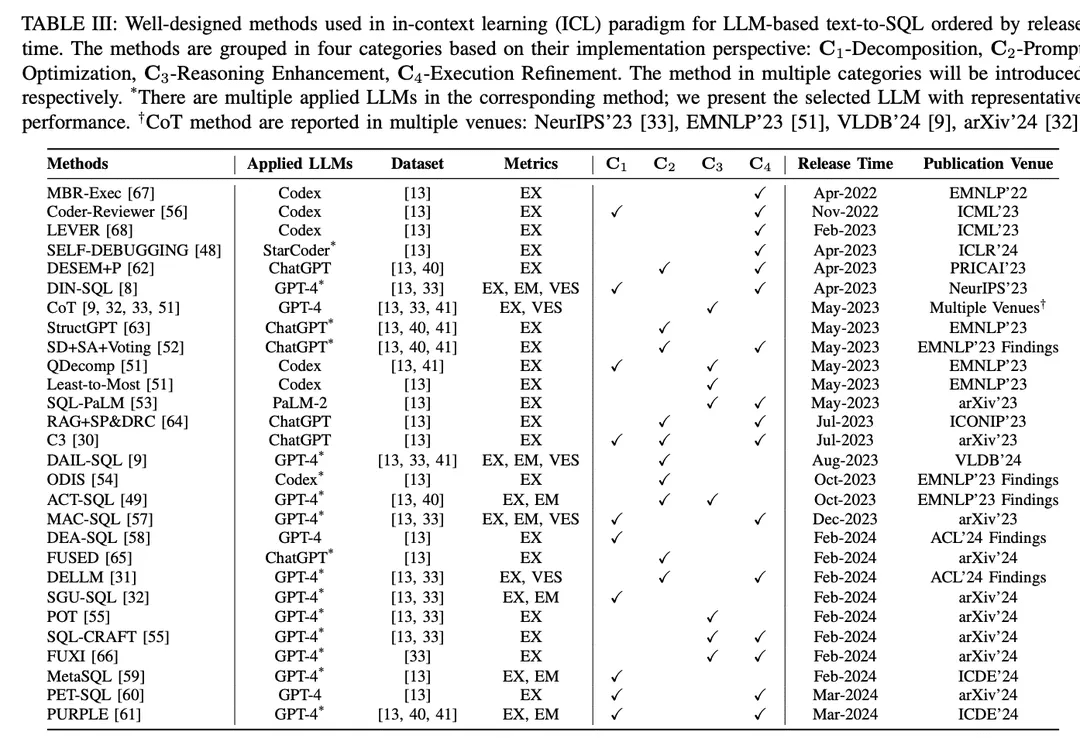
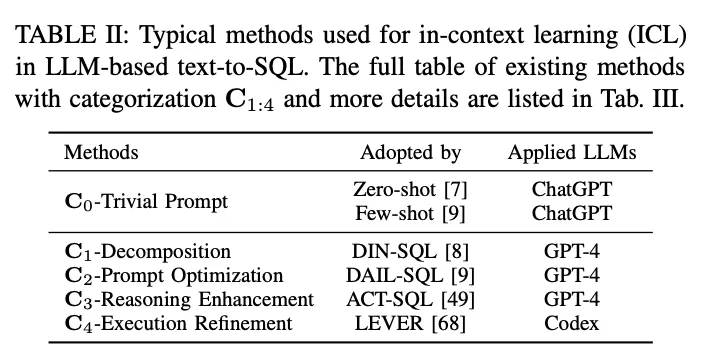
In the contextual learning (ICL) paradigm, an off-the-shelf text-to-SQL model (i.e., the model's parameter θ is frozen) is utilized to generate predicted SQL queries. LLM-based text-to-SQL tasks employ a variety of well-designed methods in the ICL paradigm. They are classified into five categories C0:4, including C0-Simple Hinting, C1-Decomposition, C2-Hint Optimization, C3-Inference Enhancement, and C4-Execution Refinement. Table II lists the representatives of each category of methods.
C0-Trivial Prompt: Trained on massive data, LLM has strong overall proficiency in different downstream tasks with zero-sample and small number of cues [90 , 97, 98 ], which is widely recognized and applied in practical applications. In the survey, the aforementioned prompting methods without elaborate framing were categorized as trivial prompts (false prompt engineering). As mentioned above, Eq. 3 describes the LLM-based text-to-SQL process, which can also denote zero-sample prompting. The overall input P0 is obtained by concatenating I, S, and Q. The input P0 is the same as the overall input P0:
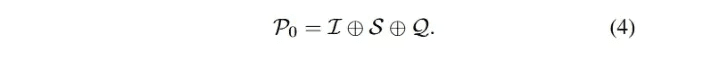
In order to standardize the prompting process, OpenAI demo2 was set up as a standard (simple) prompt for text to SQL [30].
zero sample: Many research works [7,27,46] have utilized zero-sample hinting, focusing on the impact of hint construction styles and various LLMs on the zero-sample performance of text-to-SQL. As an empirical evaluation, [7] evaluated the performance of different early developed LLMs [85, 99, 100] for baseline text-to-SQL functionality as well as for different hinting styles. The results show that on-the-fly design is critical for performance, and through an error analysis, [7] suggests that more database content can harm overall accuracy. Since ChatGPT with impressive capabilities in dialog scenarios and code generation [101], [27] evaluated its text-to-SQL performance. With a zero-sample setting, the results show that ChatGPT has encouraging text-to-SQL performance compared to state-of-the-art PLM-based systems. For fair comparability, [47] revealed effective prompting constructs for LLM-based text-to-SQL; they investigated different styles of prompting constructs and concluded a zero-sample prompting design based on the comparison.
Primary and foreign keys carry continuous knowledge of different tables. [49] studied their impact by incorporating these keys into various hinting styles for different database contents and analyzing zero-sample hinting results. The impact of foreign keys was also investigated in a benchmark evaluation [9], where five different hint representation styles, each of which can be considered as a permutation of instructions, rule meanings and foreign keys, were included. In addition to external keys, this study also explored the combination of zero-sample hints and "no-interpretation" rule implications to collect concise output. Supported by the annotation of human experts' external knowledge, [33 ] followed the standard hints and realized improvements by combining the provided annotated oracle knowledge.
With the explosion of open-source LLMs, these models are also capable of zero-sample text-to-SQL tasks according to similar evaluations [45, 46, 50], especially code generation models [46, 48]. For zero-sample hinting optimization, [46] presented the challenge of designing effective hinting templates for LLMs; previous hinting constructs lacked structural unity, which made it difficult to identify specific elements in the hinting constructs' templates that affect the performance of LLMs. To address this challenge, they investigated a series of more uniform cue templates tuned with different prefixes, suffixes, and prefix-postfixes.
A Few Tips: The small number of hints technique has been widely used in both practical applications and well-designed research, and it has been shown to be effective in improving the performance of LLM [ 28 , 102 ]. The overall input hinting of the LLM-based text-to-SQL hinting method for small number of hints can be formulated as an extension of Equation 3:

As an empirical study, few-shot hinting for text-to-SQL was evaluated across multiple datasets and various LLMs [8 , 32], and showed good performance in comparison with zero-sample hinting. [33] provides a detailed example of a one-shot trigger of a text-to-SQL model to generate accurate SQL. [55] investigates the impact of a small number of examples. [52] focuses on sampling strategies by investigating the similarity and diversity between different examples, benchmarking random sampling, and evaluating different strategies8 and their combinations for comparison. Furthermore, on top of similarity-based selection, [9] evaluates the upper bounds of similarity selection for masking problems and similarity methods with various numbers of fewer sample exemplars. A study of sample selection at difficulty levels [51] compares the performance of the small-sample Codex [100] with random and difficulty-based selection of small-sample instances on the difficulty-categorized dataset [13, 41]. Three difficulty-based selection strategies were designed based on the number of samples selected at different difficulty levels. [49] utilized a hybrid strategy for selecting samples that combines static examples and similarity-based dynamic examples for a small number of cues. In their setup, they also evaluate the effects of different input pattern styles and various static and dynamic sample sizes.
The impact of a small number of examples across domains is also under study [54 ]. When different numbers of in-domain and out-of-domain examples were included, the in-domain examples outperformed the zero-order and out-of-domain examples, theAs the number of examples increases, the performance of the in-domain examples gets better. In order to explore the detailed construction of input hints, [53] compared the design approaches of concise and verbose hints. The former splits the schema, column names, primary and foreign keys by entries, while the latter organizes them into natural language descriptions.
C1-Decomposition: As an intuitive solution, decomposing challenging user problems into simpler sub-problems or implementing them using multiple components can reduce the complexity of the overall text-to-SQL task [8, 51]. Dealing with less complex problems, LLM has the potential to generate more accurate SQL.LLM-based text-to-SQL decomposition methods fall into two paradigms:(1) Breakdown of subtasksIn addition, by breaking down the entire text-to-SQL task into more manageable and efficient subtasks (e.g., schema linking [71], domain categorization [54]), additional parsing is provided to assist in the final SQL generation.(2) Subproblem decomposition: Decompose the user problem into sub-problems to reduce the complexity and difficulty of the problem, and then derive the final SQL query by solving these problems to generate sub-SQL.
DIN-SQL[8] proposed a decomposed context learning method, including four modules: schema linking, classification and decomposition, SQL generation, and self-correction.DIN-SQL first generates the schema link between the user problem and the target database; the subsequent module decomposes the user problem into related sub-problems and classifies the difficulty. Based on the above information, the SQL generation module generates the corresponding SQL, and the self-correction module identifies and corrects potential errors in the predicted SQL. This approach treats the sub-problem decomposition as a module of the subtask decomposition.The Coder-Reviewer [56] framework proposes a reordering approach that combines a Coder model for generating instructions and a Reviewer model for evaluating the likelihood of instructions.
Referring to Chain-of-Thought [103] and Least-to-Most hints [104], theQDecomp[51] introduced the problem decomposition cue, which follows the problem reduction phase from the last-to-most cue and instructs the LLM to perform the decomposition of the original complex problem as an intermediate reasoning step
C3 [ 30 ] consists of three key components: clear hints, calibration bias hints, and consistency; these components are realized by assigning different tasks to ChatGPT. First, the clear prompts component generates schema links and refined question-related schemas as clear prompts. Then, multiple rounds of dialogs about text-to-SQL hints are utilized as calibration bias hints, which are combined with clear hints to guide SQL generation. The generated SQL queries are filtered by consistency and execution-based voting to obtain the final SQL.
MAC-SQL[57] proposed a multi-agent collaborative framework; the text-to-SQL process is accomplished with the collaboration of agents such as selectors, decomposers and refiners. The Selector keeps relevant tables for the user problem; the Decomposer decomposes the user problem into sub-problems and provides solutions; finally, the Refiner validates and optimizes the defective SQL.
DEA- SQL [58] introduces a workflow paradigm that aims to improve the attention and problem-solving scope of LLM-based text-to-SQL through decomposition. The approach decomposes the overall task so that the SQL generation module has corresponding prerequisite (information determination, problem classification) and subsequent (self-correction, active learning) subtasks. The workflow paradigm enables LLM to generate more accurate SQL queries
SGU-SQL [ 32 ] is a structure-to-SQL framework that utilizes inherent structural information to assist in SQL generation. Specifically, the framework builds graph structures for user questions and corresponding databases, respectively, and then uses encoded graphs to build structural links [105 , 106]. Meta-operators are used to decompose user problems using syntax trees, and finally meta-operators in SQL are used to design input prompts.
MetaSQL [ 59 ] introduces a three-phase approach to SQL generation: decomposition, generation, and ordering. The decomposition phase uses a combination of semantic decomposition and metadata to deal with user problems. Taking the previously processed data as input, a number of candidate SQL queries are generated using the text-to-SQL model generated by metadata conditionals. Finally, a two-stage sorting pipeline is applied to get the global optimal SQL query.
PET-SQL [ 60] presents a cue-enhanced two-stage framework. First, well-designed hints instruct the LLM to generate preliminary SQL (PreSQL), where a few small demonstrations are selected based on similarity. Then, schema links are found based on PreSQL and combined to prompt the LLM to generate Final SQL (FinSQL). Finally, FinSQL is generated using multiple LLMs to ensure consistency based on execution results.
C2-Prompt Optimization: As previously presented, few-order learning for cueing LLMs has been extensively studied [85]. For LLM-based text-to-SQL (text-to-SQL) and context learning, trivial few-minute methods have yielded promising results [8, 9, 33], and further optimization of few-minute hints has the potential for better performance. Since the accuracy of generating SQL in off-the-shelf LLMs depends heavily on the quality of the corresponding input hints [107], many determinants affecting the quality of hints have been the focus of current research [9] (e.g., quality and quantity of the organization of the minuscule hints, similarity between the user 9 problem and the minuscule hints instances, external knowledge/hints).
DESEM [ 62 ] is a cue engineering framework with de-semanticization and skeleton retrieval. The framework first employs a domain-specific word masking module to remove semantic tokens that preserve intent in user questions. It then utilizes a tunable hinting module that retrieves a small number of examples with the same intent as the question and combines it with pattern relevance filtering to guide SQL generation for the LLM.
QDecomp [ 51 ] The framework introduces an InterCOL mechanism that incrementally combines decomposed subproblems with associated table and column names. Through difficulty-based selection, a small number of examples of QDecomp are sampled for difficulty. In addition to similarity-diversity sampling, [ 52 ] proposed the SD+SA+Voting (similarity-diversity+pattern augmentation+voting) sampling strategy. They first sample a small number of examples using semantic similarity and k-Means clustering diversity, and then enhance the cues using pattern knowledge (semantic or structural enhancement).
C3 The [ 30 ] framework consists of a clear hint component, which takes questions and schemas as input to the LLMs, and a calibration component that provides hints, which generates a clear hint that includes a schema that removes redundant information unrelated to the user's question, and a schema link.The LLMs use their composition as a context-enhanced hint for SQL generation. The retrieval enhancement framework introduces sample-aware hints [64], which simplify the original problem and extract the problem skeleton from the simplified problem, and then complete sample retrieval in the repository based on the similarity of the skeletons. The retrieved samples are combined with the original problem for a small number of hints.
ODIS [54] introduces sample selection using out-of-domain presentations and in-domain synthetic data, which retrieves a small number of presentations from a mixture of sources to enhance cue characterization
DAIL- SQL[9] proposed a new approach to address the problem of sampling and organizing a small number of examples, achieving a better balance between the quality and quantity of a small number of examples.DAIL Selection first masks the domain-specific vocabulary of users and small number of example problems, and then ranks the candidate examples based on the embedded Euclidean distance. At the same time, the similarity between pre-predicted SQL queries is computed. Finally, the selection mechanism obtains candidate examples sorted by similarity based on predefined criteria. By this approach, it is ensured that a small number of examples have good similarity with both the problem and the SQL query.
ACT-SQL[49] presented dynamic examples of selection based on similarity scores.
FUSED[65] proposes to build a high diversity pool of presentations through manual-free multiple iterations of synthesis to improve the diversity of few-shot presentations.FUSED's pipeline samples presentations that need to be fused by clustering, and then fuses the sampled presentations in order to build a pool of presentations, thus improving the effectiveness of few-shot learning.
Knowledge-to-SQL [31] The framework aims to build Data Expert LLMs (DELLMs) to provide knowledge for SQL generation.
DELLM is trained through supervised fine-tuning using human expert annotations [33] and further refined through preference learning based on feedback from the database.DELLM generates four types of knowledge and well-designed methods (e.g., DAIL-SQL [9], MAC-SQL [57 ]) combine the generated knowledge to achieve better performance for LLM-based text-to-SQL through contextual learning.
C3-Reasoning Enhancement:LLMs have shown good abilities in tasks involving common-sense reasoning, symbolic reasoning, and arithmetic reasoning [108]. In text-to-SQL tasks, numerical reasoning and synonymous reasoning often appear in real-world scenarios [ 33 , 41 ].Hinting strategies for LLMs reasoning have the potential to improve SQL generation. Recent research has focused on integrating well-designed reasoning enhancement methods for text-to-SQL adaptation, improving LLMs to meet the challenges of complex problems requiring sophisticated reasoning3 , and self-consistency in SQL generation.
The Chain-of-Thoughts (CoT) hinting technique [103] consists of a comprehensive reasoning process that guides the LLM to precise reasoning and stimulates the LLM's reasoning ability. LLM text-to-SQL-based studies have utilized CoT hints as rule hints [9], with "let's think step-by-step" instructions set in the hint construction [9, 32, 33, 51]. However, the straightforward (primitive) CoT strategy for text-to-SQL tasks has not shown the potential it has for other reasoning tasks; research on adaptation of CoT is still ongoing [51]. Since CoT hints are always demonstrated using static examples with manual annotations, this requires empirical judgment to effectively select a small number of examples for which manual annotations are essential.
As a solution.ACT-SQL [ 49] proposes a method for automatically generating CoT examples. Specifically, ACT-SQL, given a problem, truncates the set of slices of the problem and then enumerates each column that appears in the corresponding SQL query. Each column will be associated with its most relevant slice via a similarity function and appended to a CoT hint.
QDecomp [51] Through a systematic study of enhancing SQL generation for LLMs in conjunction with CoT hints, a novel framework is proposed to address the challenge of how CoT proposes reasoning steps for predicting SQL queries. The framework utilizes each fragment of a SQL query to construct the logical steps of CoT inference, and then uses natural language templates to elaborate each fragment of a SQL query and arrange them in the logical order of execution.
Least-to-Most [ 104 ] is another hinting technique that breaks the problem into subproblems and then solves them sequentially. As an iterative hint, pilot experiments [51] suggest that this approach may not be needed for text-to-SQL parsing. Using detailed reasoning steps tends to create more error propagation problems.
As a variant of CoT, theProgram-of-Thoughts (PoT)Hinting strategies [109] have been proposed to enhance the arithmetic reasoning of LLM.
By evaluating [55], PoT enhances SQL-generated LLMs, especially in complex datasets [33].
SQL-CRAFT [ 55 ] is proposed to enhance LLM-based SQL generation by incorporating PoT hints for Python-enhanced reasoning.The PoT strategy requires the model to generate both Python code and SQL queries, forcing the model to incorporate Python code into its reasoning process.
Self-Consistency[110] is a hinting strategy for improving LLM reasoning that exploits the intuition that a complex reasoning problem typically allows for multiple different ways of thinking to arrive at a single correct answer. In text-to-SQL tasks, self-consistency applies to sampling a set of different SQLs and voting on consistent SQLs through execution feedback [30 , 53 ].
Likewise.SD+SA+Voting [52] The framework weeds out execution errors that are recognized by a deterministic database management system (DBMS) and selects predictions that receive a majority of votes.
In addition, driven by recent research on the use of tools to extend the functionality of the LLMFUXI [66] is proposed to enhance SQL generation for LLM by efficiently invoking well-designed tools.
C4-Execution Refinement: When designing standards for accurate SQL generation, the priority is always whether the generated SQL can be successfully executed and retrieve the content to correctly answer the user's question [ 13 ]. As a complex programming task, generating correct SQL in one go is very challenging. Intuitively, considering execution feedback/results during SQL generation helps to align with the corresponding database environment, thus allowing the LLM to collect potential execution errors and results in order to either refine the generated SQL or take a majority vote [30]. Text-to-SQL execution-aware approaches incorporate execution feedback in two main ways:
1) Re-generating feedback with a second round of promptsFor each SQL query generated in the initial response, it will be executed in the appropriate database to get feedback from the database. This feedback may be errors or results that will be appended to the second round of prompts. By learning this feedback in context, LLM is able to refine or regenerate the original SQL to improve accuracy.
2) Use Execution-Based Selection Policy for Generated SQL, sample multiple generated SQL queries from the LLM and execute each query in the database. Based on the execution result of each SQL query, a selection strategy (e.g., self-consistency, majority voting [60]) is used to define a SQL query from the SQL set that satisfies the conditions as the final predicted SQL.
MRC-EXEC [ 67 ] proposed a natural language to code (NL2Code) translation framework with execution that ranks each sampled SQL query and selects the example with the smallest execution result based on Bayes risk [111].LEVER [68] proposes a method to validate NL2Code by execution, utilizing the generation and execution modules to collect samples of the SQL set and its execution results, respectively, and then using a learning validator to output the probability of correctness.
In a similar vein.SELF-DEBUGGING [ 48] The framework also teaches LLM to debug its predicted SQL with a small number of demonstrations. the model is able to correct errors without human intervention by investigating execution results and interpreting the generated SQL in natural language.
As mentioned earlier, the two-stage implication was used extensively in order to combine a well-designed framework with implementation feedback:1. sampling a set of SQL queries. 2. majority voting (self-consistent).Specifically.C3[30] The framework eliminates errors and identifies the most consistent SQL;The Retrieval Enhancement Framework [64] introduces dynamic revision chainsThe SQL library was designed to be a self-rectifying module that combines fine-grained execution messages with database content to prompt LLMs to convert generated SQL queries to natural language interpretations; LLMs were asked to identify semantic gaps and modify their own generated SQL.Although schema filtering methods enhance SQL generation, the generated SQL may be unexecutable.DESEM [62] merged a fallback revision to address this issue; it modifies and regenerates SQL libraries based on different types of errors and sets termination conditions to avoid loops.DIN-SQL [8] designed generic and gentle hints in its self-correction module; the generic hints require the LLM to identify and correct errors, and the gentle hints require the model to check for potential problems.
multiagent frameworkMAC-SQL[57] includes a refinement agent that detects and automatically corrects SQL errors, employs SQLite error and exception classes to regenerate fixed SQL. since different issues may require different numbers of revisions.SQL-CRAFT [55] The framework introduces interactive calibration and automatic control of the determination process to avoid overcorrection or undercorrection. FUXI [66] considers error feedback in tool-based reasoning for SQL generation. Knowledge-to-SQL [31] introduced a preference learning framework that combines database execution feedback with direct preference optimization [112] to improve the proposed DELLM.PET-SQL[60] proposed cross-consistency, which consists of two variants: 1) plain voting: multiple LLMs are instructed to generate SQL queries, and then a majority vote is utilized to decide on the final SQL based on the different execution results, and 2) fine-grained voting: the plain voting is refined based on the difficulty level to mitigate voting bias.
B. Fine-tuning
Since supervised fine-tuning (SFT) is the dominant approach for training LLMs [29, 91], for open-source LLMs (e.g., LLaMA-2 [94 ], Gemma [113]), the most straightforward way to quickly adapt the model to a specific domain is to perform SFT on the model using collected domain labels.The SFT phase is usually the initial phase of a well-designed training framework [112, 114], and the text-to-SQL fine-tuning phase. 114], as well as the text-to-SQL fine-tuning phase.The auto-regression generation process for SQL query Y can be formulated as follows:

The SFT approach is also a fictional fine-tuning method for text-to-SQL and has been widely adopted by various open-source LLMs in text-to-SQL research [9, 10 , 46 ]. The fine-tuning paradigm favors LLM-based text-to-SQL starting points over contextual learning (ICL) approaches. Several studies exploring better fine-tuning methods have been published. The well-designed fine-tuning methods are categorized into different groups according to their mechanisms, as shown in Table IV:
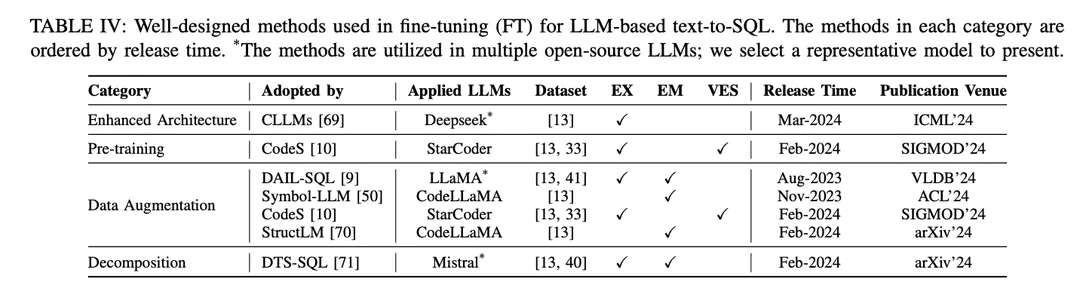
Enhanced Architecture: The widely used generative pretrained transformer (GPT) framework utilizes a decoder-only transformer architecture and traditional autoregressive de-encoding to generate text. Recent studies on the efficiency of LLMs have revealed a common challenge: the latency of LLMs is high due to the need to incorporate an attention mechanism when generating long sequences using autoregressive patterns [115 , 116 ]. In LLM-based text-to-SQL, generating SQL queries is significantly slower compared to traditional language modeling [21 , 28 ], which becomes a challenge for building efficient local NLIDBs. As one of the solutions, CLLM [ 69 ] aims to address the above challenges and speed up SQL generation through an enhanced modeling architecture.
data enhancement: In the fine-tuning process, the most direct factor affecting the performance of the model is the quality of the training labels [117]. Fine-tuning with low quality or lack of training labels is a "no-brainer", and fine-tuning with high-quality or augmented data always outperforms well-designed fine-tuning methods on low-quality or raw data [29, 74]. Substantial progress has been made in data-enhanced fine-tuning from text to SQL, with a focus on improving data quality in the SFT process.
[117] "Learning from noisy labels with deep neural networks: a survey,"[74] Recent advances in text-to-SQL: a survey of what we have and what we expect[29] "A survey of large language models"DAIL-SQL [9] is designed as a contextual learning framework that utilizes a sampling strategy to obtain better fewer sample instances. Incorporating sampled instances into the SFT process improves the performance of open source LLMs.Symbol-LLM [50] proposes data augmentation instructions tuned to the injected and infused phases.CodeS [10] enhances the training data through bidirectional generation with the help of ChatGPT.StructLM [70] is trained on multiple structural knowledge tasks to improve the overall capability.
pre-training: Pre-training is the fundamental stage of the whole fine-tuning process, aiming at obtaining text generation capabilities through automatic regression training on a large amount of data [118]. Traditionally, current powerful proprietary LLMs (e.g., ChatGPT [119], GPT-4 [86], Claude [120]) are pre-trained on hybrid corpora, which mainly benefit from dialog scenarios showing text generation capabilities [85]. Code-specific LLMs (e.g., CodeLLaMA [ 121 ], StarCoder [ 122 ]) are pre-trained on code data [100 ], and the mixture of various programming languages enables LLMs to generate code that conforms to user instructions [123 ]. The main challenge for pre-training techniques targeting SQL as a sub-task of code generation is that SQL/database related content is only a small portion of the entire pre-trained corpus.
As a result, open-source LLMs with relatively limited synthesis capabilities (compared to ChatGPT, GPT-4) do not have a good understanding of how to transform NL problems into SQL during pre-training.The pre-training phase of the CodeS [10] model consists of three stages of incremental pre-training. Starting from a basic code-specific LLM [122 ], CodeS performs incremental pre-training on a mixed training corpus (including SQL-related data, NL-to-Code data, and NL-related data). Text-to-SQL comprehension and performance are significantly improved.
decomposition: Decomposing a task into multiple steps or solving a task using multiple models is an intuitive solution to solving complex scenarios, as the ICL paradigm, previously introduced in Chapter IV-A, shows. The proprietary models used in ICL-based approaches have a large number of parameters, which are at a different parameter level than the open-source models used in fine-tuning approaches. These models are inherently capable of performing the assigned subtasks well (through mechanisms such as learning with fewer samples) [30, 57]. Therefore, to replicate the success of this paradigm in an ICL approach, it is important to rationalize the assignment of appropriate subtasks (e.g., generating external knowledge, schema linking, and refining schemas) to open-source models in order to fine-tune them for specific subtasks and to construct the appropriate data for fine-tuning to assist in the generation of the final SQL.
DTS-SQL [71] proposes a two-stage decomposition framework for text-to-SQL fine-tuning and designs a schema-link 12 pre-generation task prior to final SQL generation.
have expectations
Despite significant progress in text-to-SQL research, there are still some challenges that need to be addressed. In this section, the remaining challenges that are expected to be overcome in future work are discussed.
A. Robustness in practical applications
Text-to-SQL, implemented by LLMs, promises to be generalizable and robust in real-world complex application scenarios. Despite the recent substantial progress in robustness specific datasets [ 37 , 41], their performance is still not sufficient for real-world applications [ 33]. There are still some challenges to overcome in future research. From the user's side, there is a phenomenon that the user is not always an explicit question poser, which means that the user's question may not have exact database values or may be different from the standard dataset, where synonyms, misspellings, and fuzzy expressions may be included [40].
For example, in the fine-tuning paradigm, the model is trained on explicitly indicative problems with concrete representations. Since the model does not learn the mapping of real-world problems to the corresponding databases, there is a knowledge gap when applied to real-world scenarios [33]. As reported in the corresponding evaluations on datasets with synonyms and incomplete instructions [7 , 51], SQL queries generated by ChatGPT contain about 40% of incorrect executions, which is 10% lower than the original evaluation [51]. Also, fine-tuning using native text to SQL datasets may contain non-standardized samples and labels. For example, the names of tables or columns are not always accurate representations of their contents, which leads to inconsistencies in the construction of the training data.
B. Computational efficiency
Computational efficiency is determined by the speed of reasoning and the cost of computational resources, which is worth considering in both applications and research efforts [49, 69]. With the increasing complexity of databases in the latest text-to-SQL benchmarks [15, 33], databases will carry more information (including more tables and columns) and the token length of the database schema will increase accordingly, presenting a number of challenges. When dealing with ultra-complex databases, using the corresponding schema as input may encounter the challenge that the cost of invoking proprietary LLMs will increase significantly, potentially exceeding the maximum token length of the model, especially when implementing open source models with short context lengths.
Meanwhile, another obvious challenge is that most studies use complete patterns as model inputs, which introduces a large amount of redundancy [57]. Providing the LLM with the exact filtered patterns relevant to the problem directly from the user's end to reduce cost and redundancy is a potential solution to improve computational efficiency [30]. Designing an accurate pattern filtering method remains a future direction. While the context learning paradigm has achieved promising accuracy, well-designed multi-stage frameworks or extended context methods increase the number of API calls, which improves performance from a computational efficiency point of view, but also leads to a significant increase in cost [8].
In related approaches [49], the trade-off between performance and computational efficiency should be carefully considered, and the design of a comparable (or even better) context learning approach with a lower application program interface cost would be a practical implementation that is still being explored. Compared to PLM-based approaches, LLM-based approaches have significantly slower reasoning [ 21, 28]. Speeding up inference by shortening the input length and reducing the number of stages in the realization process is intuitive for the contextual learning paradigm. For localized LLM, from the starting point [69], more speedup strategies can be investigated to enhance the architecture of the model in future explorations.
To address this challenge, tuning LLMs to intentional biases and designing training strategies for noisy scenarios would be beneficial to recent progress. Meanwhile, the amount of data in real-world applications is relatively smaller than research-based benchmarks. Since scaling a large amount of data through manual annotation incurs high labor costs, designing data expansion methods to obtain more question-SQL pairs will provide support for LLMs when data is scarce. Additionally, fine-tuning open-source LLM for local adaptation studies on small-scale datasets is potentially beneficial. Furthermore, extensions for multilingual [ 42 , 124 ] and multimodal scenarios [ 125 ] should be comprehensively investigated in future research, which would benefit more linguistic communities and help build more generalized database interfaces.
C. Data privacy and interpretability
As part of LLM research, LLM-based text-to-SQL also faces some general challenges that exist in LLM research [4 , 126 , 127 ]. From a text-to-SQL perspective, these challenges also lead to potential improvements that can greatly benefit LLM research. As mentioned earlier in Chapter IV-A, contextual learning paradigms have dominated recent research in terms of both volume and performance, with most of the work implemented using proprietary models [8, 9]. An immediate challenge is posed in terms of data privacy, as invoking proprietary APIs to handle the confidentiality of local databases may pose a risk of data leakage. The use of local fine-tuning paradigms can partially address this issue.
Nonetheless, the performance of vanilla fine-tuning is currently suboptimal [9], and advanced fine-tuning frameworks may rely on proprietary LLMs for data augmentation [10]. Based on the current state of affairs, more tailored frameworks in the text-to-SQL local fine-tuning paradigm deserve extensive attention. Overall, the development of deep learning has always faced challenges in terms of interpretability [127 , 128 ].
As a long-standing challenge, a great deal of research has been conducted to address this issue [ 129 , 130 ]. However, the interpretability of LLM-based implementations remains undiscussed in text-to-SQL research, either in contextual learning or fine-tuning paradigms. Approaches with decomposition phases explain text-to-SQL implementations from a step-by-step generative perspective [8, 51]. Building on this, combining advanced research in interpretability [131, 132] to improve text-to-SQL performance and explaining local model architectures in terms of database knowledge remains a future direction.
D. Expansion
As a subfield of LLM and natural language understanding research, much of the research in these areas has been driven by the use of text-to-SQL tasks [103 , 110 ]. However, text-to-SQL research can also be extended to the larger body of research in these areas. For example, SQL generation is part of code generation. Well-designed code generation methods also achieve good performance in text-to-SQL [48, 68] and can be generalized across a variety of programming languages. The possibility of extending some customized text-to-SQL frameworks to NL-to-code research can also be discussed.
For example, frameworks that integrate execution output in NL-to-code also achieve excellent performance in SQL generation [8]. Attempts to extend the execution-aware approach in text-to-SQL with other advancement modules [30, 31] to code generation are worth discussing. From another perspective, it was previously discussed that text-to-SQL can enhance LLM-based question answering (QA) by providing factual information. Databases can store relational knowledge as structural information, and structure-based QA has the potential to benefit from text-to-SQL (e.g., knowledge-based question answering, KBQA [ 133 , 134 ]). Utilizing database structures to construct factual knowledge and then combining it with a text-to-SQL system to enable information retrieval has the potential to aid further QA in obtaining more accurate factual knowledge [ 135 ]. It is expected that more text-to-SQL extensions will be investigated in future work.
OlaChat Digital Intelligence Assistant Product Introduction

OlaChat Digital Intelligence Assistant is a new intelligent data analysis product launched by Tencent's PCG Big Data Platform Department utilizing big models in the field of data analysis in the field of landing practice, and has been integrated into DataTalk, OlaIDE and other Tencent's internal mainstream data platforms to provide intelligent support for the whole process of data analysis scenarios. It contains a series of capabilities such as text2sql, indicator analysis, SQL intelligent optimization, etc. From data analysis (drag-and-drop analysis, SQL query), data visualization, to result interpretation and attribution, OlaChat comprehensively assists and makes data analysis work easier and more efficient!
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles



No comments...