VTP - MiniMax Conch Video Team's Open Source Visual Generative Modeling Technology

What is VTP?
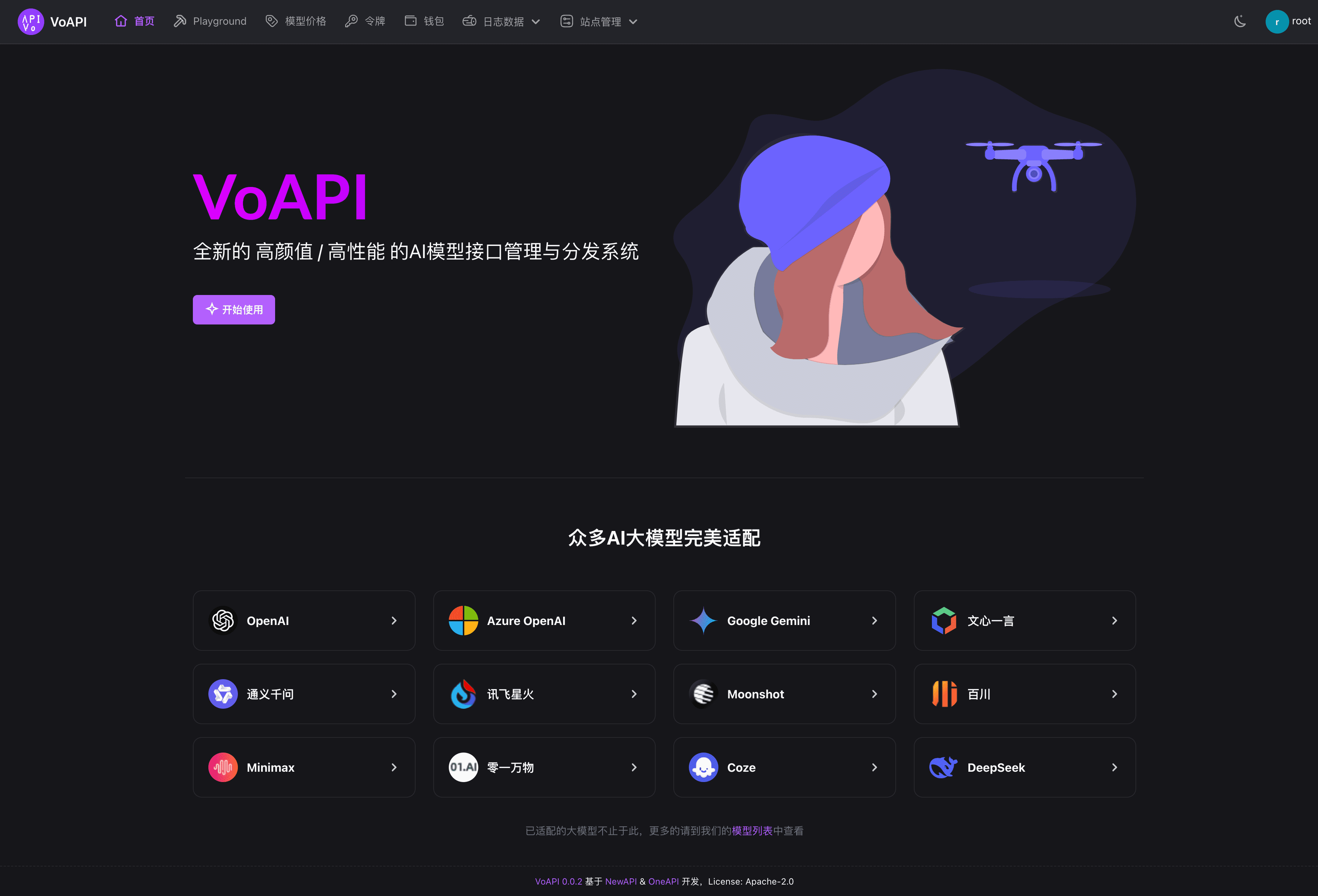
VTP (Visual Tokenizer Pre-training) is a key technology for visual generation models proposed by MiniMax Conch Video team, which improves the performance of the generation system by improving the pre-training method of visual tokenizer (tokenizer). In the traditional approach, tokenizer only focuses on image reconstruction, but VTP innovatively introduces semantic understanding capability, which becomes the core driver of generation quality. The framework adopts Vision Transformer architecture, and through a two-stage training strategy (optimizing representation learning in the pre-training stage, and improving image quality in the fine-tuning stage) and multi-tasking objectives (reconstruction, self-supervision, and graphic comparison), it achieves for the first time the scale-up of tokenizer, i.e., the generation effect is synchronously improved when the computational power and the amount of data are increased. Experiments show that VTP significantly outperforms traditional VAE under the same computational budget, providing a more efficient visual pedestal for diffusion models and multimodal macromodels.
Features of VTP
- Multi-task co-optimization: VTP improves the semantic understanding and spatial perception of the model by combining image-text contrast learning, self-supervised learning (e.g., self distillation and masked image modeling), and pixel-level reconstruction goals for joint multi-task training.
- Efficient scalability: VTP demonstrates excellent scalability, and its generation performance steadily improves with the increase of training computations (FLOPs), model parameters, and dataset size, breaking through the performance bottleneck of traditional self-encoders during large-scale pre-training.
- Excellent generation performance: On ImageNet, VTP achieves a zero-sample classification accuracy of 78.2% and an rFID of 0.36, which significantly outperforms other methods, and performs well in downstream generation tasks, where the generation quality can be significantly improved only by increasing the amount of pre-training computation.
- fast convergence: VTP has been redesigned from the pre-training stage to achieve a higher upper performance limit and 4.1 times faster convergence compared to methods based on distillation base models, greatly improving training efficiency.
- Open Source and Ease of Use: VTP provides detailed installation and usage guidelines, including downloads of pre-trained weights and quick-start scripts, to facilitate researchers and developers to quickly get started and apply them to real projects.
Core Benefits of VTP
- Multi-task learning integration: VTP integrates image-text contrast learning, self-supervised learning, and pixel-level reconstruction objectives, and enables the model to significantly improve its semantic understanding and generative capabilities through multi-task co-optimization.
- Strong scalability: VTP demonstrates excellent scalability in the pre-training phase, and its generation performance steadily improves with the increase of computation, model parameters and dataset size, breaking through the limitations of traditional self-encoders.
- Excellent generation quality: In benchmarks such as ImageNet, VTP achieves a zero-sample classification accuracy of 78.21 TP3T and an rFID of 0.36, significantly outperforming other methods in terms of generation quality and performing well in downstream generation tasks.
- Fast convergence capability: VTP has been redesigned from the pre-training stage to achieve a higher upper performance limit and 4.1 times faster convergence compared to traditional methods, greatly improving training efficiency.
- Open Source and Ease of Use: VTP provides detailed installation guides and pre-training weights so that users can quickly get started and apply them to real projects, lowering the threshold for use.
- Innovative pre-training paradigms: VTP proposes a new pre-training paradigm for visual disambiguators, which improves the generative capability through multi-task learning, and provides new ideas and methods for the field of visual generation.
What is the official website of VTP
- GitHub repository:: https://github.com/MiniMax-AI/VTP
- HuggingFace Model Library:: https://huggingface.co/collections/MiniMaxAI/vtp
- arXiv Technical Paper:: https://arxiv.org/pdf/2512.13687v1
People for whom VTP is intended
- Deep Learning Researchers: Researchers interested in visual generative modeling and wishing to explore new pre-training methods to improve generation quality and semantic understanding, VTP provides new technical frameworks and experimental ideas.
- Computer Vision Engineer: Engineers working on high-quality vision generation applications (e.g., image generation, video generation, etc.) can quickly implement and optimize their generation tasks thanks to VTP's efficient scalability and excellent performance.
- natural language processing (NLP) expert: A researcher focusing on cross-modal learning and multimodal fusion, VTP provides new perspectives and tools for joint modeling of vision and language through techniques such as image-text contrast learning.
- Machine Learning Developer: For developers who want to quickly deploy and apply pre-trained models in real projects, VTP's open source code and detailed user guide lower the barrier to use and facilitate rapid integration into projects.
- Academic researchers: Academic researchers working in fields related to artificial intelligence, computer vision and natural language processing, VTP provides them with new research directions and experimental platforms, which help to promote academic progress in related fields.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...