Voxtral - Open Source Speech Modeling from Mistral AI

What's Voxtral?
Voxtral, yes. Mistral AI Voxtral is a state-of-the-art open-source speech model that facilitates natural human-computer interaction through powerful speech transcription and comprehension capabilities. Available in two versions, 24B for mass production and 3B for local deployment, Voxtral is multi-lingual, automatically detects languages, and can handle up to 30 minutes of audio transcription and 40 minutes of audio comprehension. With built-in Q&A and summarization functions, Voxtral can generate structured content without the need for additional language models.Voxtral can directly trigger back-end function calls, optimizing the efficiency and cost of voice interaction.Voxtral combines deep learning technology to integrate speech recognition and natural language understanding, and is widely used in conference recording, customer service, content creation, education, and intelligent assistants, helping to popularize voice interaction. It is widely used in conference recording, customer service, content creation, education and intelligent assistants, helping to popularize voice interaction.
Voxtral's main features
- Long audio processing capability: Handles up to 30 minutes of audio transcription and 40 minutes of in-depth comprehension, making it easy to handle long-form content.
- Smart Q&A and Summary: Supports direct questioning of audio content to generate clear structured summaries without the need for additional speech recognition or language modeling assistance.
- Multi-language automatic recognition: Supports many mainstream languages (such as English, French, Spanish, etc.), can automatically detect the language to meet the needs of users in different regions.
- voice-command triggered: Trigger back-end functions or API calls directly based on voice commands, simplifying the operation process and improving interaction efficiency.
- Text comprehension and processing: Strong text comprehension with support for text input and processing.
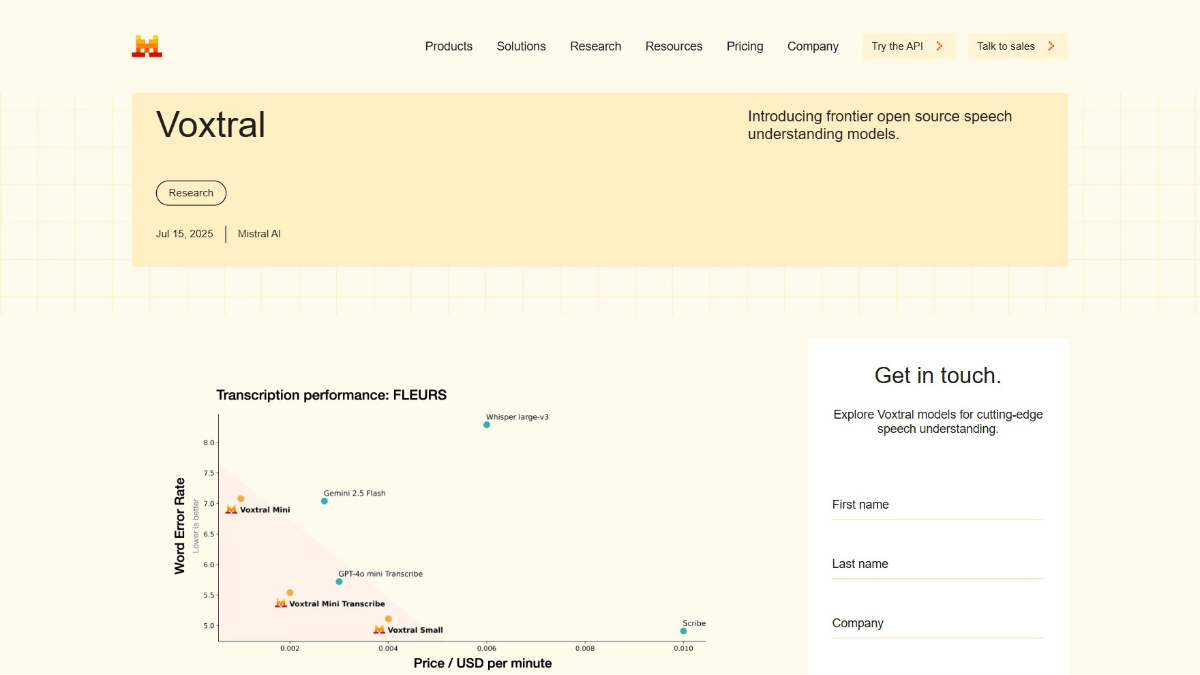
- Efficient transcription performance: Provides optimized transcription services at low cost for large-scale applications.
Voxtral's official website address
- Project website:: https://mistral.ai/news/voxtral
- HuggingFace Model Library::
- https://huggingface.co/mistralai/Voxtral-Small-24B-2507
- https://huggingface.co/mistralai/Voxtral-Mini-3B-2507
How to use Voxtral
- Visit the official website: Visit Voxtral's project website and the HuggingFace model library.
- Choose the right version::
- Voxtral-Small-24B-2507: Suitable for production scale with enhanced performance.
- Voxtral-Mini-3B-2507: Suitable for local deployment and less resource intensive.
- Installation of dependencies: Ensure that Python and the necessary dependencies are installed in your environment, such as
transformerscap (a poem)torch. UseThe following command installs::
pip install transformers torch- Loading Models: Using HuggingFace's
transformersThe library loads the Voxtral model:
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
model_name = "mistralai/Voxtral-Small-24B-2507" # 或者 "mistralai/Voxtral-Mini-3B-2507"
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_name)
processor = AutoProcessor.from_pretrained(model_name)- Prepare audio data: Ensure that the audio file format is one of the supported formats (e.g. WAV, MP3, etc.).
- Transcription Audio:Audio transcription with the Voxtral model:
from transformers import pipeline
# 创建一个语音转录 pipeline
transcriber = pipeline("automatic-speech-recognition", model=model_name)
# 转录音频文件
transcription = transcriber("path/to/your/audio/file.wav")
print(transcription)Voxtral's core strengths
- Powerful Speech Processing: Supports up to 30 minutes of audio transcription and 40 minutes of in-depth comprehension, with high transcription accuracy for complex, long-form content.
- Multi-language support: Automatically detects multiple languages (e.g. English, Spanish, French, etc.) without the need to manually switch to meet the needs of users around the world.
- Efficient Interaction Capabilities: Built-in Q&A and summary functions, directly triggering the call of back-end functions, simplifying the operation process and improving the efficiency of interaction.
- Optimized performance and cost: Provides high-performance transcription services that are cost-effective, suitable for large-scale applications, and lower the barrier to use.
- Flexible deployment options: Available in versions 24B and 3B for production-scale and local deployments, respectively, and easy to integrate.
- deep comprehension: Support for long text contexts (32k tokens), combined with speech recognition and natural language understanding to reduce error rates.
Who Voxtral is for
- business user: Customer service teams and meeting recorders use Voxtral to improve service efficiency and meeting summarization.
- educator: Teachers transcribe course content and provide real-time Q&A to enhance instructional interactivity.
- content creator: Journalists, podcast producers, and video creators efficiently transcribe content and increase creative productivity.
- Technology Developer: Integrate Voxtral into projects to develop voice interaction applications.
- research worker: Processing speech data with Voxtral to power language and data analysis research.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles



No comments...