Voice-Pro: open source multifunctional video translation tool, voice transcription and translation into multiple languages, Windows one-click installation

General Introduction
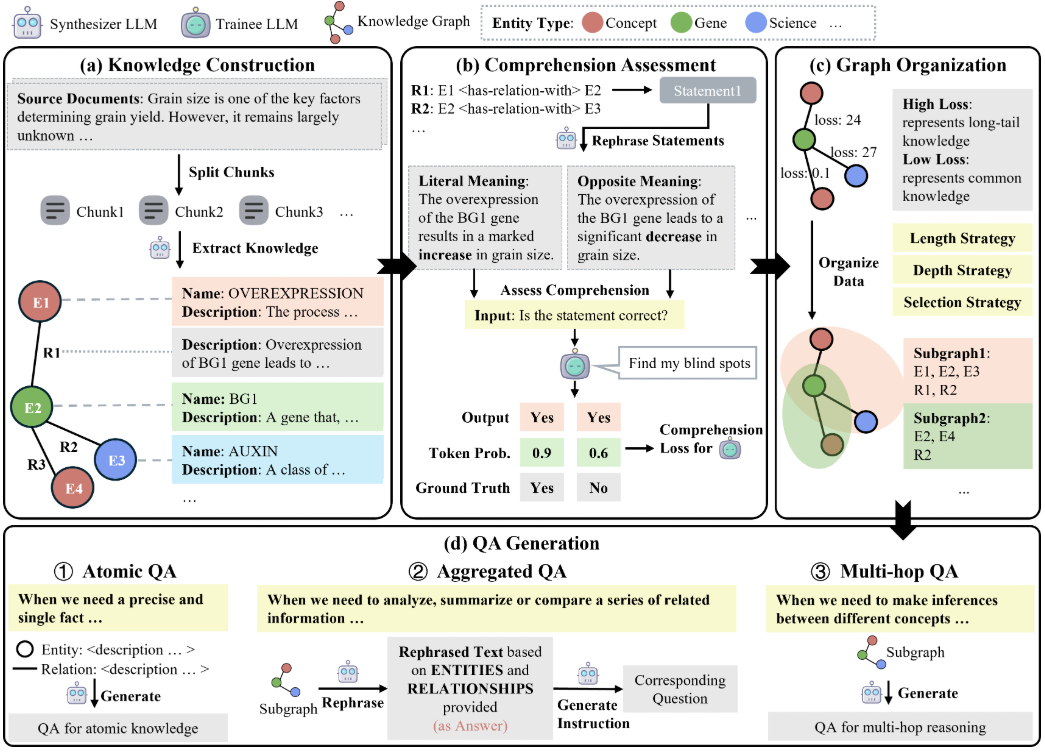
Voice-Pro is a multifunctional tool based on Gradio WebUI that supports speech-to-text, text-to-speech, real-time translation, YouTube video downloads, and human voice separation. It integrates Whisper, Faster-Whisper and Whisper-Timestamped technologies to provide efficient audio processing and translation for multiple languages and scenarios.


Function List
- speech-to-text: Supports Whisper, Faster-Whisper, and Whisper-Timestamped to provide highly accurate speech recognition.
- text-to-speech: Supports Edge-TTS and F5-TTS with multiple language and voice choices, speed, volume and pitch adjustments.
- real time translation: Supports real-time speech recognition and translation for multiple languages.
- YouTube Download: You can download YouTube videos and extract audio (mp3, wav, flac).
- vocal separation: Vocal and background sound separation using MDX-Net and Demucs engines.
- batch file: Supports subtitle generation, translation and text-to-speech processing of large batches of files.
- Subtitle Generation: Supports generation and editing of subtitles in more than 90 languages.
- Multi-format support: All video and audio formats supported by ffmpeg are supported.
Using Help
Installation process
- starter pack: Clone or download the latest version of the source code from GitHub.
git clone https://github.com/abus-aikorea/voice-pro.git
- Install and run the program::
- (of a computer) run
configure.batInstall the required dependencies (e.g. git, ffmpeg and CUDA). - (of a computer) run
start.batStart Voice-Pro and WebUI will run automatically. - When run for the first time, Voice-Pro will first install, which may take an hour or more, during which time do not close the Windows command window.
- (of a computer) run
Usage Functions
- speech-to-text::
- On the Studio tab, select Whisper Models and types of calculations.
- Upload an audio file or select an audio input source (such as a microphone).
- Click the "Start" button and wait for the speech recognition and subtitle creation to complete.
- rendering::
- Upload the text or subtitle file to be translated in the Translate tab.
- Select the target language and click the "Translate" button.
- Once the translation is complete, you can download the translated file.
- text-to-speech::
- Select Edge-TTS or F5-TTS in the TTS tab.
- Enter the text to be converted and select the speech parameters (e.g. speed, volume, pitch).
- Click the "Generate Voice" button and wait for the voice generation to complete.
- YouTube Download::
- Enter the YouTube video link in the YouTube Downloader tab.
- Select the audio format (mp3, wav, flac) and click the "Download" button.
- Once the download is complete, you can find the audio file in the specified folder.
- sound separation::
- Upload audio files in the Vocal Remover tab.
- Select the MDX-Net or Demucs engine and click on the Start button.
- Wait for the sound separation to complete and you can download the separated audio file.
- batch file::
- Upload multiple files in the Batch tab.
- Select the desired operation (subtitling, translation, text-to-speech).
- Click the "Start" button and wait for batch processing to complete.
common problems
- Browser not running automatically: Close the Windows command window and re-run
start.bat, or manually enter the displayed address in your browser (e.g. http://127.0.0.1:7892). - CUDA Out of Memory Error: Check the GPU memory status to adjust the noise reduction level or calculation type.
- Windows Defender Warning: Add the batch file as an exception or temporarily disable Windows Defender.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...