
VideoChat: real-time voice-interactive digital person with customized image and tone cloning, supporting end-to-end voice solutions and cascading solutions

General Introduction
VideoChat is a real-time voice interaction digital human project based on open source technology, supporting end-to-end voice scheme (GLM-4-Voice - THG) and cascade scheme (ASR-LLM-TTS-THG). The project allows users to customize the image and timbre of the digital human, and supports timbre cloning and lip synchronization, video streaming output, and first packet delay as low as 3 seconds. Users can experience its features through online demos, or deploy and use it locally through detailed technical documentation.
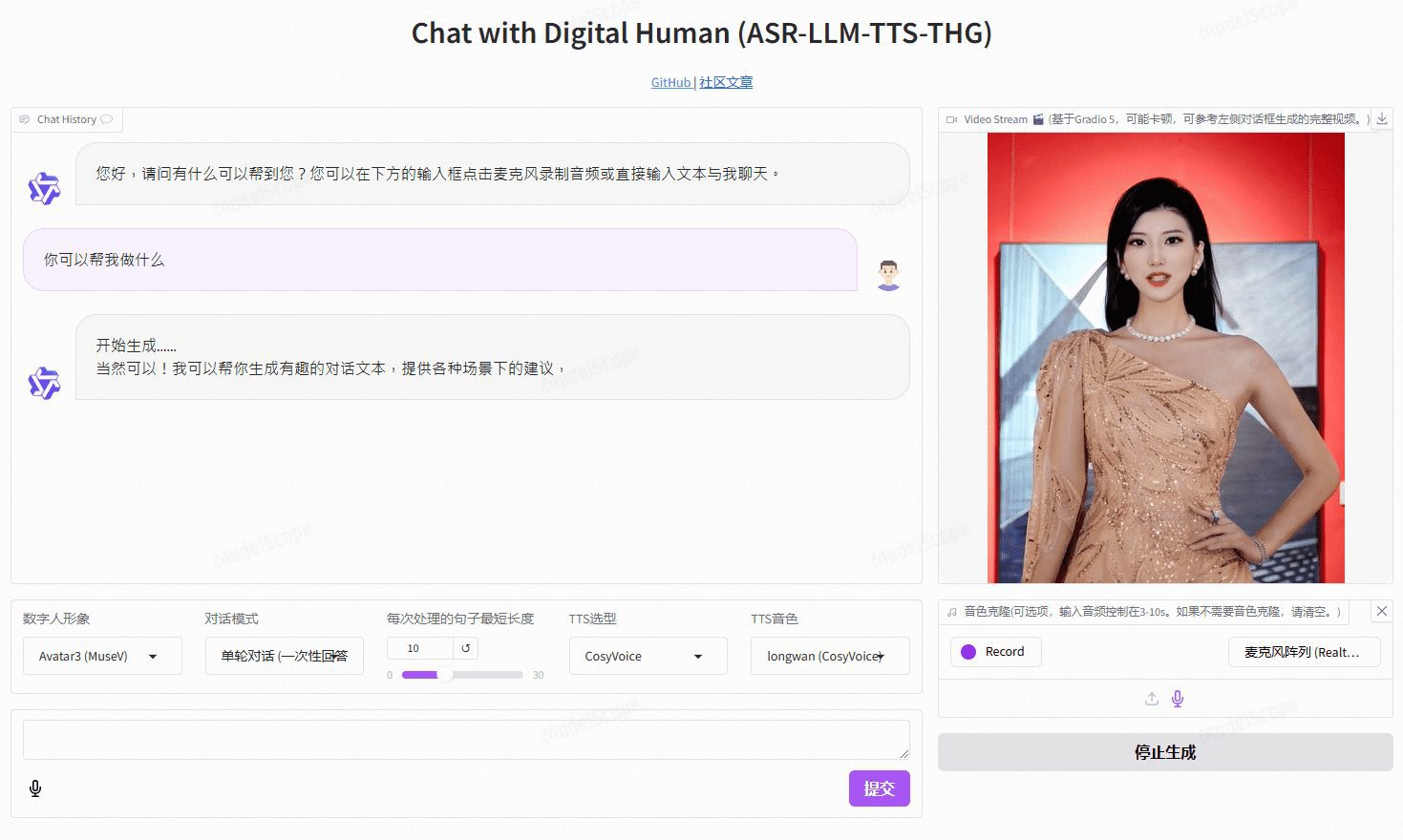
Demo address: https://www.modelscope.cn/studios/AI-ModelScope/video_chat
Function List
- Real-time voice interaction: support for end-to-end voice solutions and cascading solutions
- Customized Image and Tone: Users can customize the appearance and voice of the digital person according to their needs
- Voice cloning: supports cloning of user's voice to provide a personalized voice experience
- Low latency: first packet latency as low as 3 seconds to ensure smooth interaction experience
- Open source project: based on open source technology, users can freely modify and expand the function
Using Help
Installation process
- Environment Configuration
- Operating system: Ubuntu 22.04
- Python version: 3.10
- CUDA version: 12.2
- Torch version: 2.1.2
- cloning project
git lfs install git clone https://github.com/Henry-23/VideoChat.git cd video_chat - Create a virtual environment and install dependencies
conda create -n metahuman python=3.10 conda activate metahuman pip install -r requirements.txt pip install --upgrade gradio - Download the weights file
- Recommended to use CreateSpace to download, have set up git lfs to track weight files
git clone https://www.modelscope.cn/studios/AI-ModelScope/video_chat.git - Starting services
python app.py
Usage Process
- Configuring the API-KEY::
- If the performance of the local machine is limited, you can use the Qwen API and CosyVoice API provided by Aliyun's big model service platform, Hundred Refine, on the
app.pyConfigure the API-KEY in the
- If the performance of the local machine is limited, you can use the Qwen API and CosyVoice API provided by Aliyun's big model service platform, Hundred Refine, on the
- local inference::
- If you don't use the API-KEY, you can add the API-KEY to the
src/llm.pycap (a poem)src/tts.pyConfigure the local inference method in to remove unneeded API call code.
- If you don't use the API-KEY, you can add the API-KEY to the
- Starting services::
- (of a computer) run
python app.pyStart the service.
- (of a computer) run
- Customizing the digital persona::
- exist
/data/video/Catalog to add the recorded digital human image video. - modifications
/src/thg.pyin the avatar_list of the Muse_Talk class, adding the image name and bbox_shift. - exist
app.pyAfter adding the name of the digital persona to the avatar_name in Gradio, restart the service and wait for the initialization to complete.
- exist
Detailed Operation Procedure
- Customize image and tone: in
/data/video/directory to add a recorded video of the digital human image to thesrc/thg.pymodificationsMuse_Talkclassavatar_list, add the image name andbbox_shiftParameters. - voice cloning: in
app.pycentralized configurationCosyVoice APIor usingEdge_TTSPerform local reasoning. - End-to-end voice solutions: Use
GLM-4-Voicemodel to provide efficient speech generation and recognition.
- Visit the address of the locally deployed service and go to the Gradio interface.
- Select or upload a customized digital persona video.
- Configure the voice clone function to upload a user's voice sample.
- Start real-time voice interaction and experience low-latency conversational capabilities.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles



No comments...