
V-JEPA 2 - The Most Powerful World Large Model from Meta AI

What is V-JEPA 2
V-JEPA 2 Yes Meta AI Launched a world-sized model based on video data with 1.2 billion parameters. The model is trained based on self-supervised learning from over 1 million hours of video and 1 million images to understand objects, actions, and motions in the physical world and predict future states. The model uses an encoder-predictor architecture, combined with action condition prediction, to support zero-sample robot planning, allowing robots to complete tasks in new environments. The model is equipped with video Q&A capabilities and supports combining language models to answer questions related to video content.V-JEPA 2 excels in tasks such as action recognition, prediction, and video Q&A, providing powerful technical support for robot control, intelligent surveillance, education, and healthcare, and is an important step towards advanced machine intelligence.
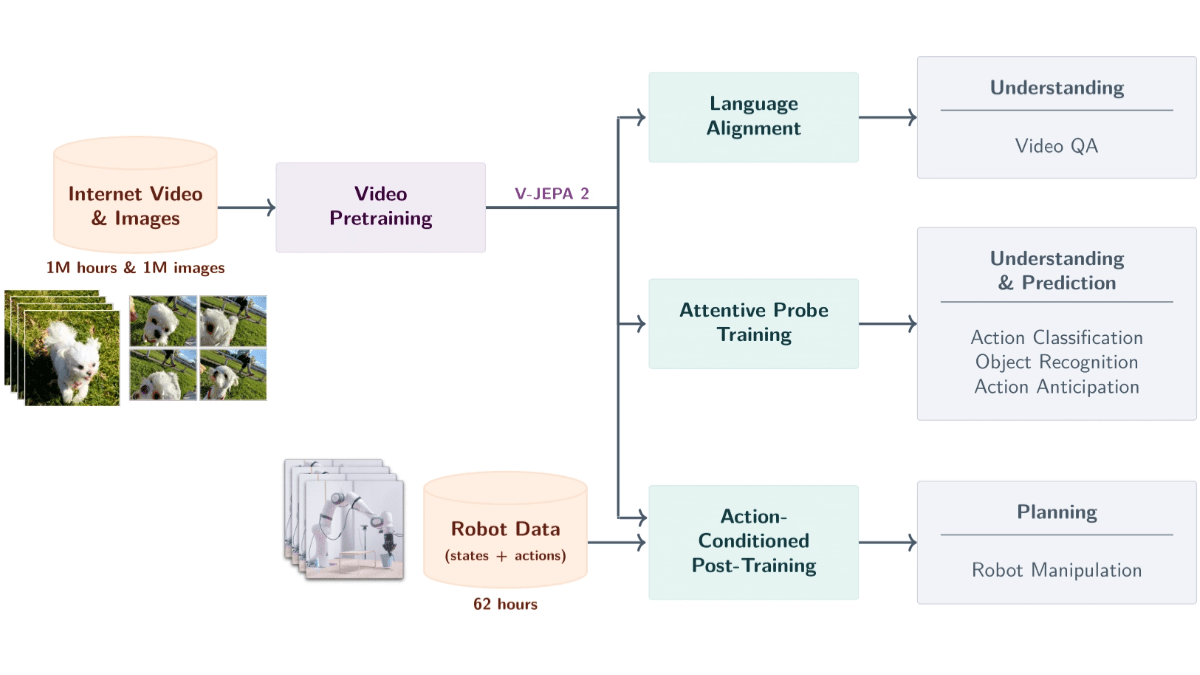
Key Features of V-JEPA 2
- Video Semantic Parsing: Recognize objects, actions and motions from videos and accurately extract semantic information about the scene.
- Forecast of future events: Predicts future video frames or action results based on current state and actions, supporting both short-term and long-term predictions.
- Robot zero sample planning: Planning tasks for robots in new environments, such as grasping and manipulating objects, based on predictive capabilities, without additional training data.
- Video Q&A Interaction: Answer questions related to the content of the video in conjunction with language modeling, covering physical causation and scene comprehension.
- Cross-scene generalization: performs well on unseen environments and objects and supports zero-sample learning and adaptation in new scenes.
V-JEPA 2's official website address
- Project website::https://ai.meta.com/blog/v-jepa-2
- GitHub repository::https://github.com/facebookresearch/vjepa2
- Technical Papers::https://scontent-lax3-2.xx.fbcdn.net/v/t39.2365-6
How to use V-JEPA 2
- Getting Model Resources: Download the pre-trained model files and associated code from the GitHub repository. Model files are provided in .pth or .ckpt format.
- Setting up the development environment::
- Installing Python: Make sure Python is installed (Python 3.8 or higher is recommended).
- Installation of dependent libraries: Use pip to install the dependency libraries required by the project. Typically, projects provide a requirements.txt file to install dependencies based on the following commands:
pip install -r requirements.txt- Installation of deep learning frameworksV-JEPA 2 is based on PyTorch and requires PyTorch to be installed, depending on your system and GP configuration, get the installation commands from the PyTorch website.
- Loading Models::
- Loading pre-trained models: Load pre-trained model files with PyTorch.
import torch
from vjepa2.model import VJEPA2 # 假设模型类名为 VJEPA2
# 加载模型
model = VJEPA2()
model.load_state_dict(torch.load("path/to/model.pth"))
model.eval() # 设置为评估模式- Preparing to enter data::
- Video data preprocessing: V-JEPA 2 requires video data as input. The video data is converted to the format (usually tensor) required by the model. Below is a simple preprocessing example:
from torchvision import transforms
from PIL import Image
import cv2
# 定义视频帧的预处理
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整帧大小
transforms.ToTensor(), # 转换为张量
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])
# 读取视频帧
cap = cv2.VideoCapture("path/to/video.mp4")
frames = []
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = Image.fromarray(frame)
frame = transform(frame)
frames.append(frame)
cap.release()
# 将帧堆叠为一个张量
video_tensor = torch.stack(frames, dim=0).unsqueeze(0) # 添加批次维度- Forecasting with models::
- Implementation projections: Input the preprocessed video data into the model to get the prediction results. The following is the sample code:
with torch.no_grad(): # 禁用梯度计算
predictions = model(video_tensor)- Parsing and applying forecast results::
- Analyzing the forecast results: Parses the output of the model according to the needs of the task.
- Applying to real-world scenarios: Apply predictions to real-world tasks such as robot control, video quizzing, or anomaly detection.
Core Benefits of V-JEPA 2
- Strong understanding of the physical world: V-JEPA 2 can accurately recognize object actions and movements based on video inputs, capturing semantic information about the scene and providing basic support for complex tasks.
- Efficient future state prediction: Based on the current state and actions, the model can predict future video frames or action outcomes, supporting both short-term and long-term predictions, powering applications such as robot planning and intelligent monitoring.
- Zero-sample learning and generalization capabilities: V-JEPA 2 performs well on unseen environments and objects, supports zero-sample learning and adaptation, and requires no additional training data to accomplish new tasks.
- Video Q&A capability combined with language modeling: When combined with a language model, V-JEPA 2 can answer questions related to video content, covering physical causality and scene understanding, expanding applications in areas such as education and healthcare.
- Efficient training based on self-supervised learning: Learning generic visual representations from large-scale video data based on self-supervised learning without manually labeling the data, reducing cost and improving generalization.
- Multi-stage training and prediction of movement conditions: Based on multi-stage training, V-JEPA 2 pre-trains the encoder and then trains the motion condition predictor, combining visual and motion information to support accurate predictive control.
People for whom V-JEPA 2 is intended
- Artificial intelligence researchers: Academic research and technological innovation with V-JEPA 2's cutting-edge technology to promote machine intelligence.
- Robotics Engineer: Developing robotic systems adapted to new environments and accomplishing complex tasks with the help of model zero-sample planning capabilities.
- Computer Vision Developer: Enhance the efficiency of video analytics with V-JEPA 2 for use in intelligent security, industrial automation, and more.
- natural language processing (NLP) expert: Combining visual and linguistic modeling to develop intelligent interaction systems such as virtual assistants and intelligent customer service.
- educator: Develop immersive educational tools based on video quiz functions to enhance teaching and learning.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...