uniOCR: cross-platform open source text recognition tool

General Introduction
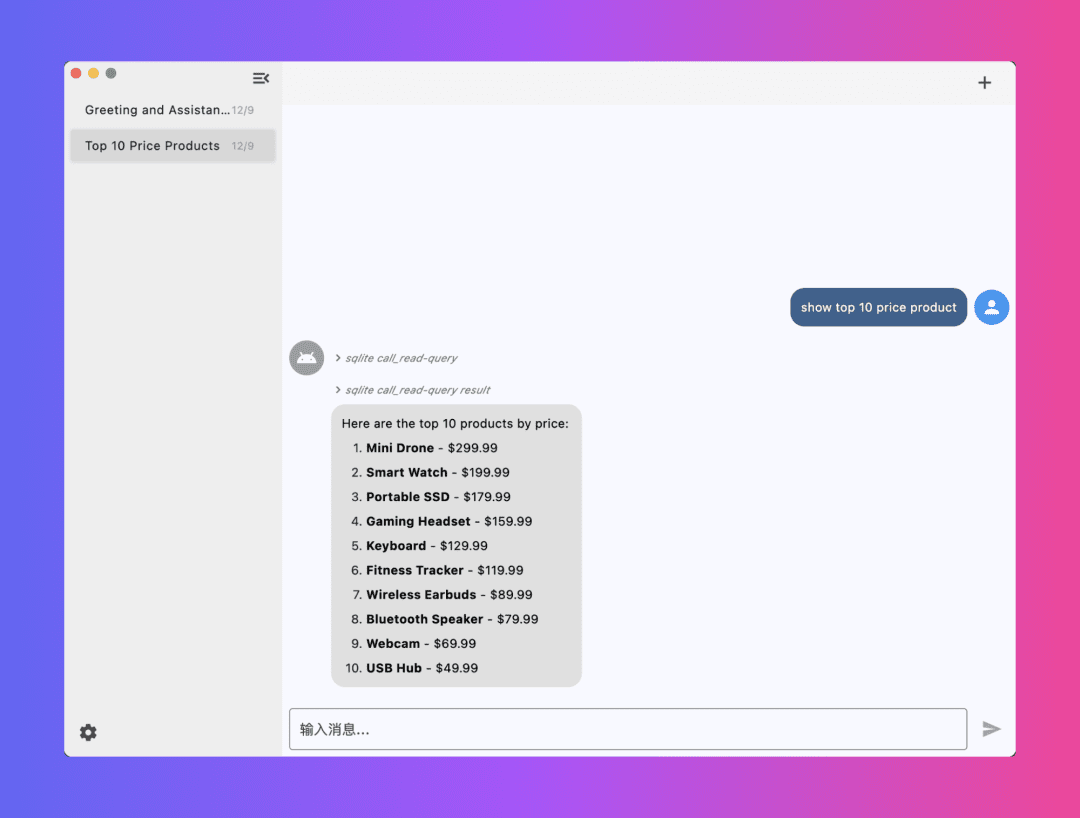
uniOCR is an open source text recognition tool developed by the mediar-ai team. It is based on the Rust language and supports macOS, Windows and Linux systems. Users can use it to extract text from images, the operation is simple and free. uniOCR's core features are cross-platform support and unified interface design. It integrates multiple OCR engines, including Vision Kit for macOS, Windows OCR and Tesseract, and also supports cloud OCR, which can be used by both individual users and developers to quickly handle image and text recognition tasks. The project code is open, allowing users to freely modify and extend it.

Function List
- Supports macOS, Windows and Linux systems and runs cross-platform.
- Multiple OCR engine options are available: macOS Vision, Windows OCR, Tesseract and Cloud OCR.
- Supports extracting text from a single image or multiple images.
- Provide a unified API interface to facilitate switching between different OCR engines.
- Support asynchronous operation and batch processing to enhance recognition efficiency.
- Allows customization of settings such as language, confidence thresholds and timeouts.
- Open source project, users can view and modify the code.
Using Help
Installation process
uniOCR requires a Rust environment and related dependencies to run. Below are the detailed steps:
- Installing Rust
- Open a terminal and enter the following command to install Rust:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh - After the installation is complete, run
rustc --versionCheck the version to make sure the installation was successful.
- Open a terminal and enter the following command to install Rust:
- Download uniOCR source code
- Use Git to clone your project locally:
git clone https://github.com/mediar-ai/uniOCR.git - Go to the project catalog:
cd uniOCR
- Use Git to clone your project locally:
- Install Tesseract (optional)
- If you want to use the Tesseract engine, you need to install it additionally:
- macOS: running
brew install tesseract - Ubuntu: running
apt-get install tesseract-ocr - Windows: running
winget install tesseractor download the installer manually.
- macOS: running
- No additional installation is required for macOS Vision and Windows OCR.
- If you want to use the Tesseract engine, you need to install it additionally:
- Compiling projects
- Run in the project directory:
cargo build --release - After compilation, the executable is located at
<项目目录>/target/release/The
- Run in the project directory:
- running program
- Enter the following command to start:
cargo run --release
- Enter the following command to start:
How to use
uniOCR achieves text recognition through code calls. The following is the basic operation:
- Prepare the picture
- Place the image to be recognized (e.g.
test.png) into the project catalog.
- Place the image to be recognized (e.g.
- Run the basic example
- compiler
<项目目录>/examples/basic.rsThe code is as follows:use uniocr::{OcrEngine, OcrProvider}; use anyhow::Result; #[tokio::main] async fn main() -> Result<()> { let engine = OcrEngine::new(OcrProvider::Auto)?; let text = engine.recognize_file("test.png").await?; println!("提取的文字: {}", text); Ok(()) } - Run the example:
cargo run --example basic - The program will output the text in the image.
- compiler
- Select OCR Engine
- modifications
OcrProviderparameter to switch engines:- macOS Vision:
OcrProvider::MacOS - Windows OCR:
OcrProvider::Windows - Tesseract:
OcrProvider::Tesseract
- macOS Vision:
- Sample code:
let engine = OcrEngine::new(OcrProvider::Tesseract)?;
- modifications
- batch file
- compiler
<项目目录>/examples/batch_processing.rs::use uniocr::{OcrEngine, OcrProvider}; use anyhow::Result; #[tokio::main] async fn main() -> Result<()> { let engine = OcrEngine::new(OcrProvider::Auto)?; let images = vec!["img1.png", "img2.png", "img3.png"]; let results = engine.recognize_batch(images).await?; for (i, text) in results.iter().enumerate() { println!("图片 {} 提取的文字: {}", i + 1, text); } Ok(()) } - Running:
cargo run --example batch_processing
- compiler
Featured Function Operation
Customized settings
- uniOCR supports adjusting recognition parameters. Sample code:
use uniocr::{OcrEngine, OcrProvider, OcrOptions};
let options = OcrOptions::default()
.languages(vec!["eng", "chi_sim"]) // 设置英文和简体中文
.confidence_threshold(0.8) // 置信度阈值
.timeout(std::time::Duration::from_secs(30)); // 超时 30 秒
let engine = OcrEngine::new(OcrProvider::Auto)?.with_options(options);
- After running, the recognition will be executed as set.
Multi-language support
- If you recognize Chinese, you need to install Tesseract's Chinese language pack:
- macOS/Ubuntu: run the
brew install tesseract-langmaybeapt-get install tesseract-ocr-chi-sim - Windows: Download
chi_sim.traineddatain the Tesseract installation directory.tessdataFolder. - Set the language parameter to
vec!["chi_sim"]The
performance optimization
- uniOCR uses asynchronous operation and parallel processing. For batch recognition, the program processes multiple images simultaneously to save time.
- On high-performance devices such as the M4 MacBook Pro, macOS Vision can process 3.2 images per second with an accuracy of 90%.
caveat
- Images need to be clear; blurriness or low light may affect recognition.
- Windows systems need to be Windows 10 or above.
- Cloud OCR (e.g. Google Cloud Vision) requires additional credentials to be configured, and a full official example is not available at this time.
application scenario
- document scanning
Users can take a photo of a paper document, extract the text using uniOCR and save it as an electronic version. - multilingual translation
After recognizing the foreign language in the image, it works with translation tools to generate multi-language text. - Automated workflows
Developers can integrate uniOCR into scripts to batch process images and extract text.
QA
- Which systems support uniOCR?
Supports macOS, Windows 10+, and Linux with no additional hardware required. - How to improve recognition accuracy?
Use high-quality images, adjust confidence thresholds, or choose a suitable OCR engine. - What if Tesseract does not recognize Chinese?
You need to install the Chinese language pack and setlanguages(vec!["chi_sim"])The
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...