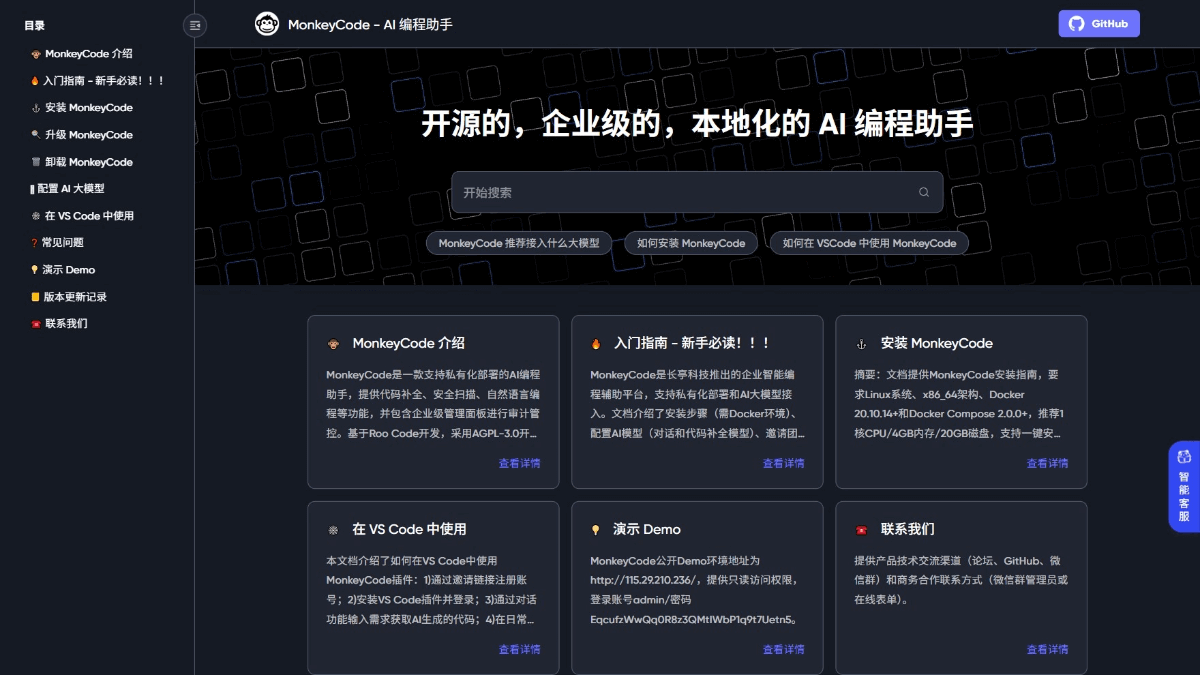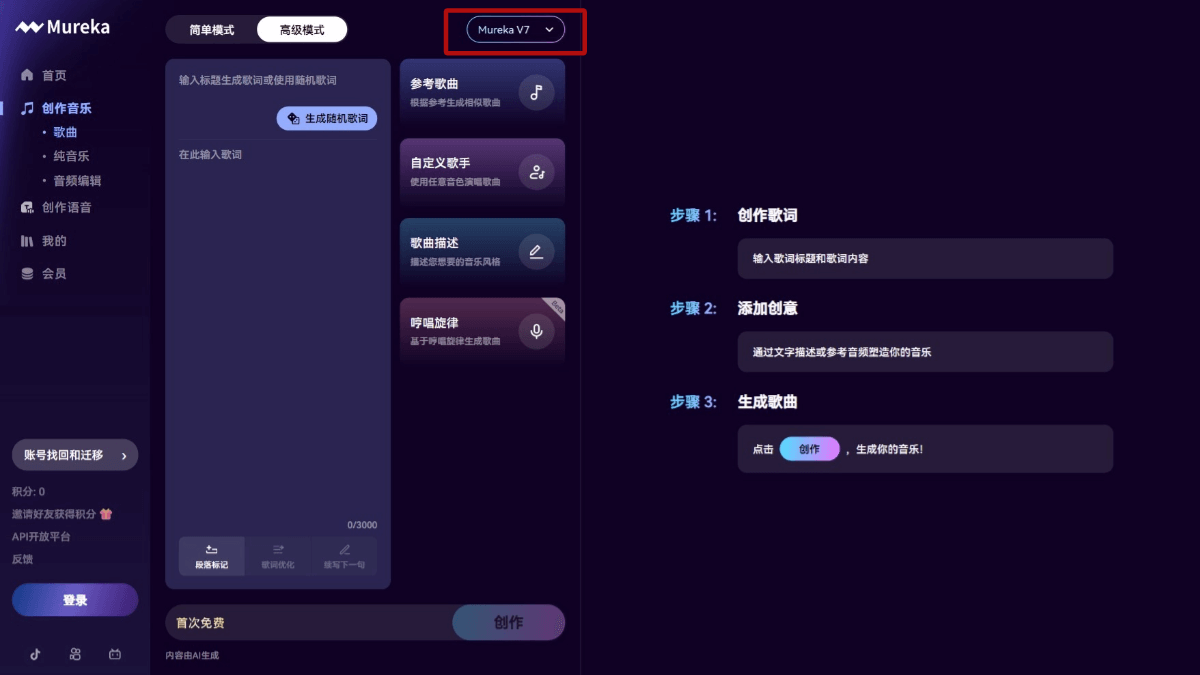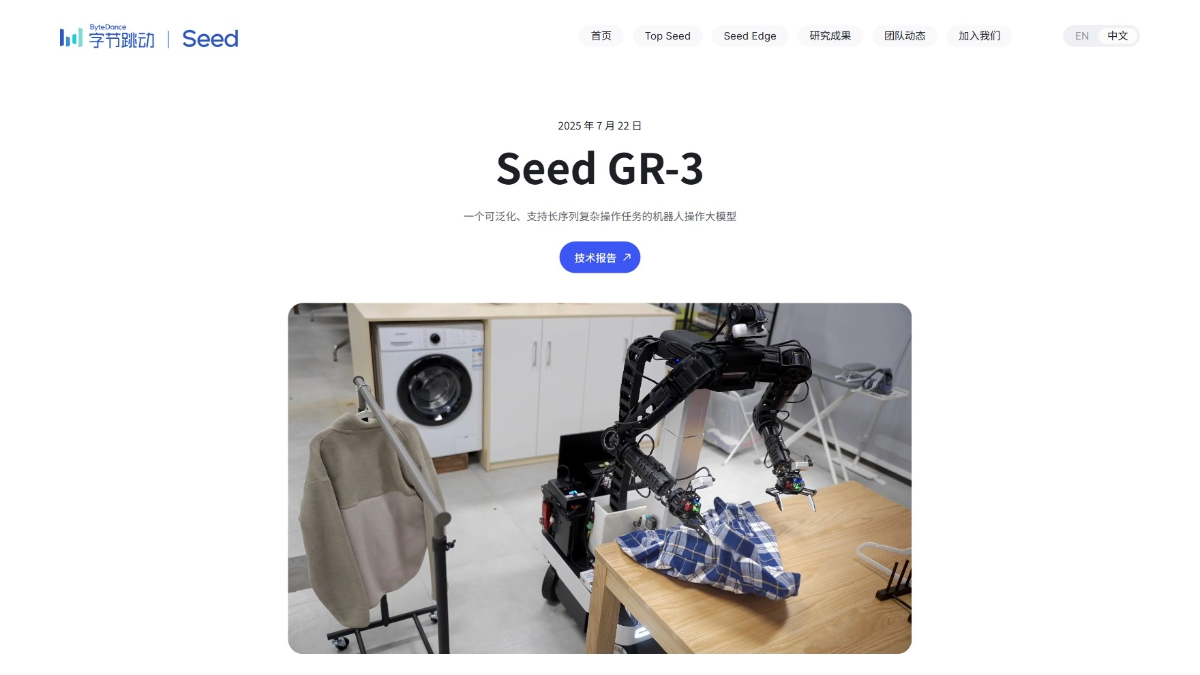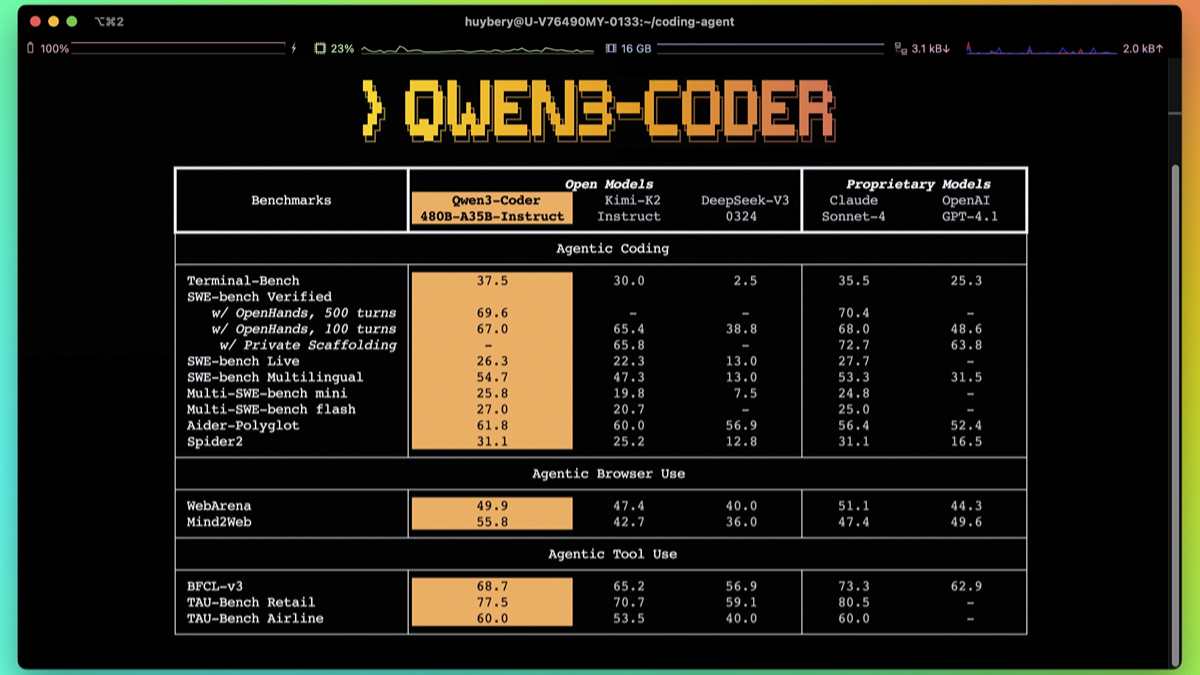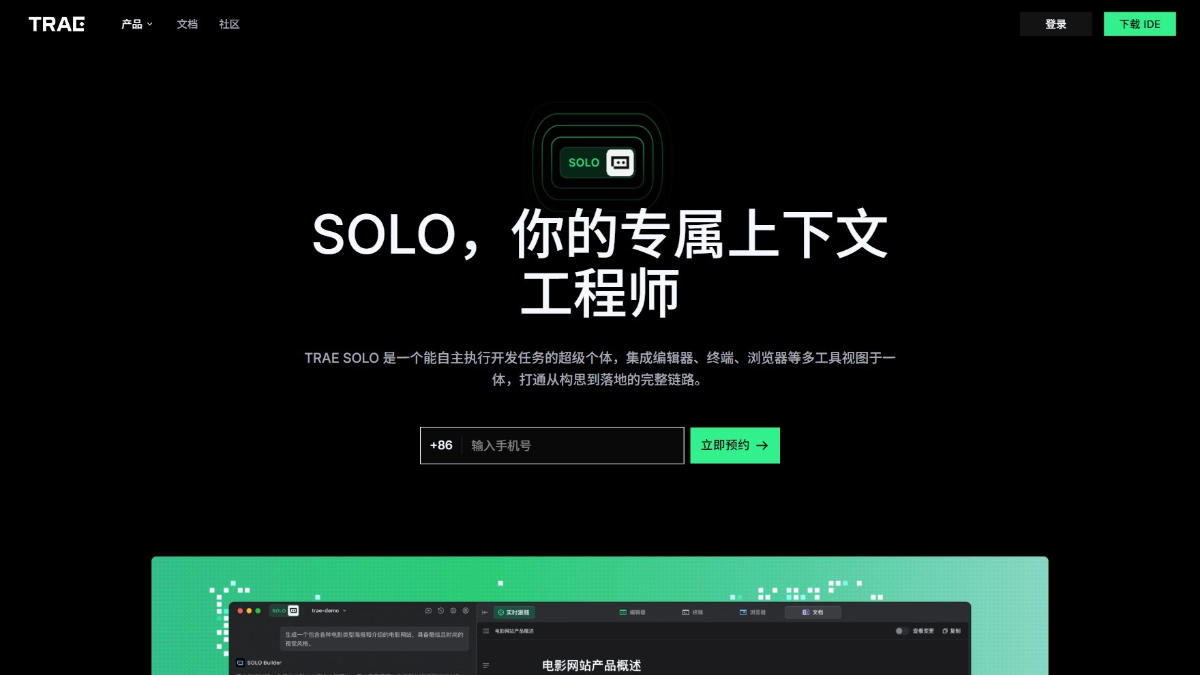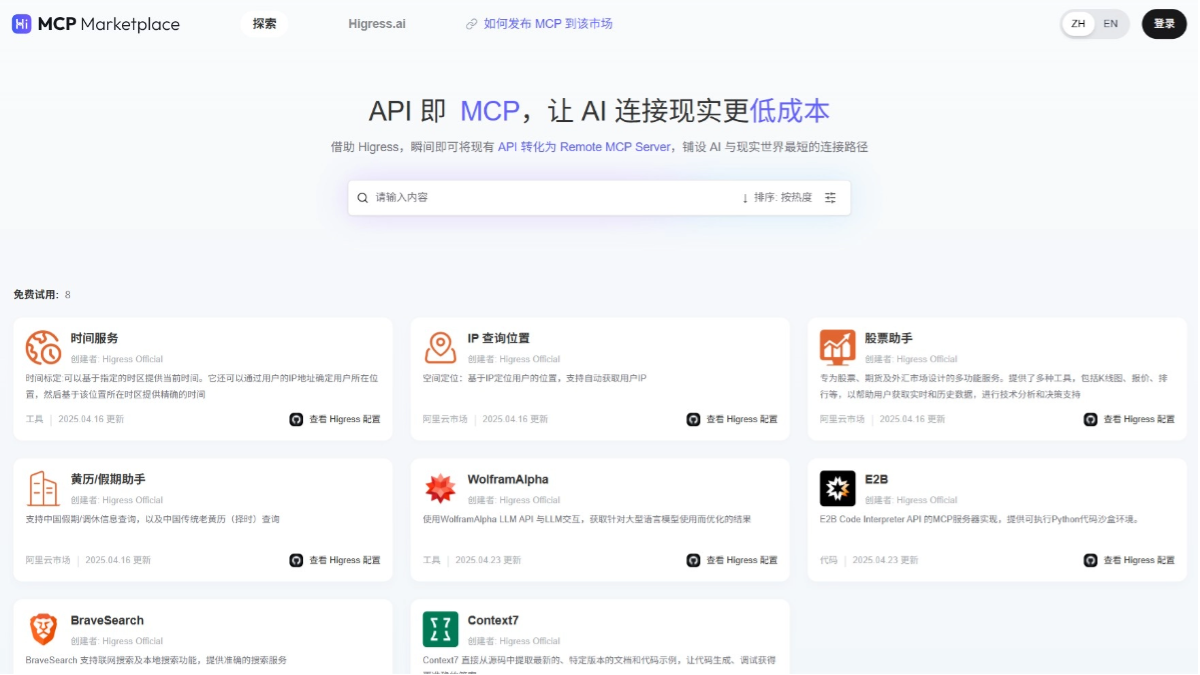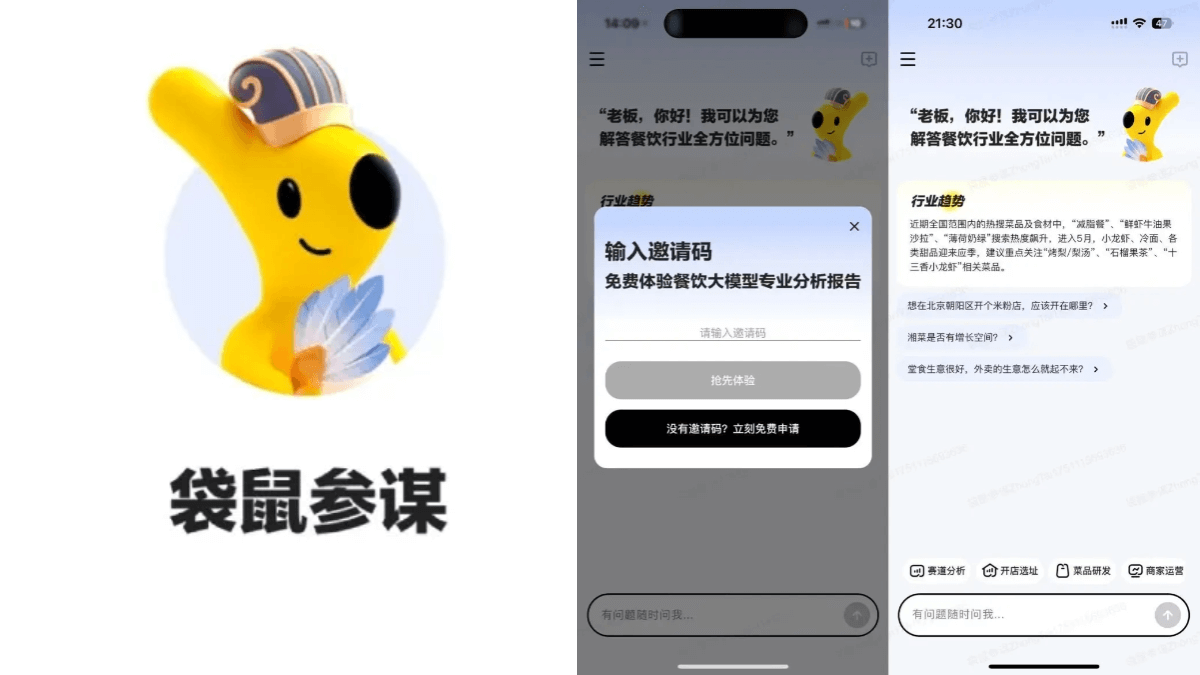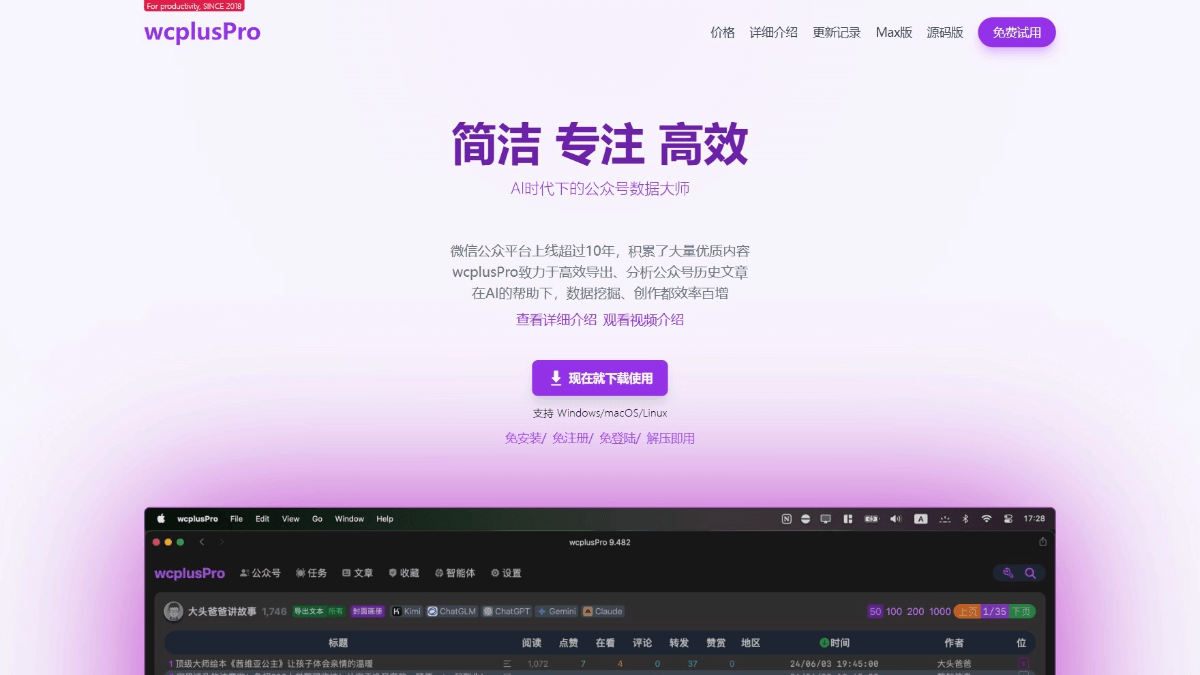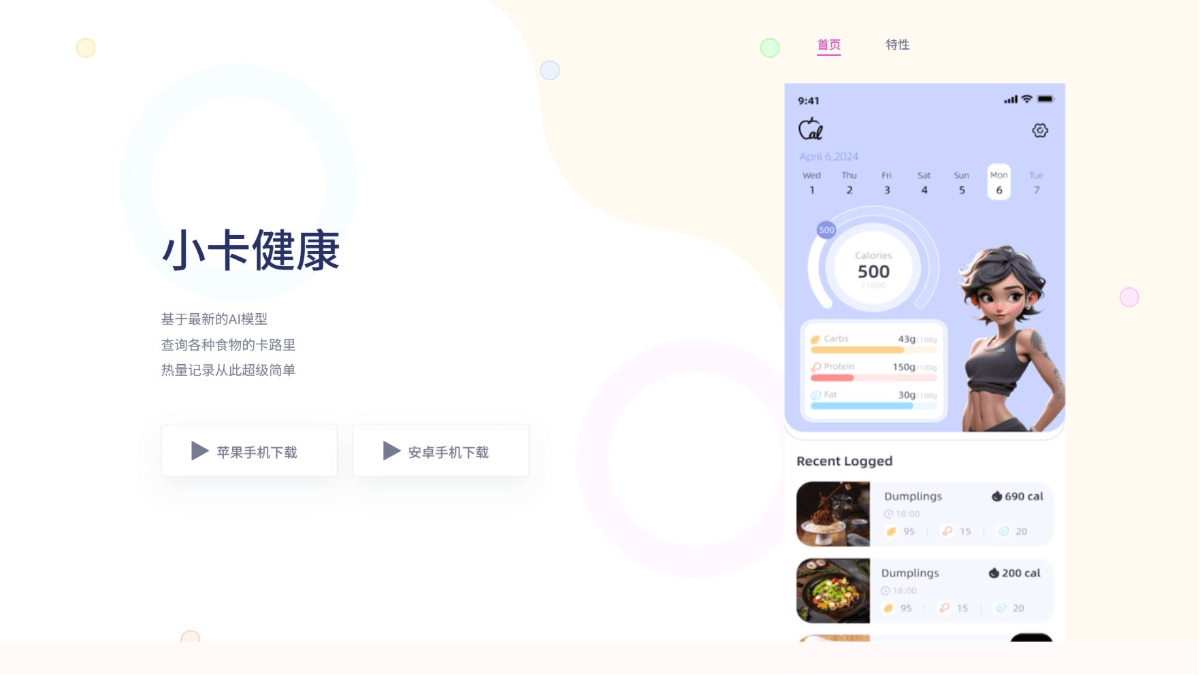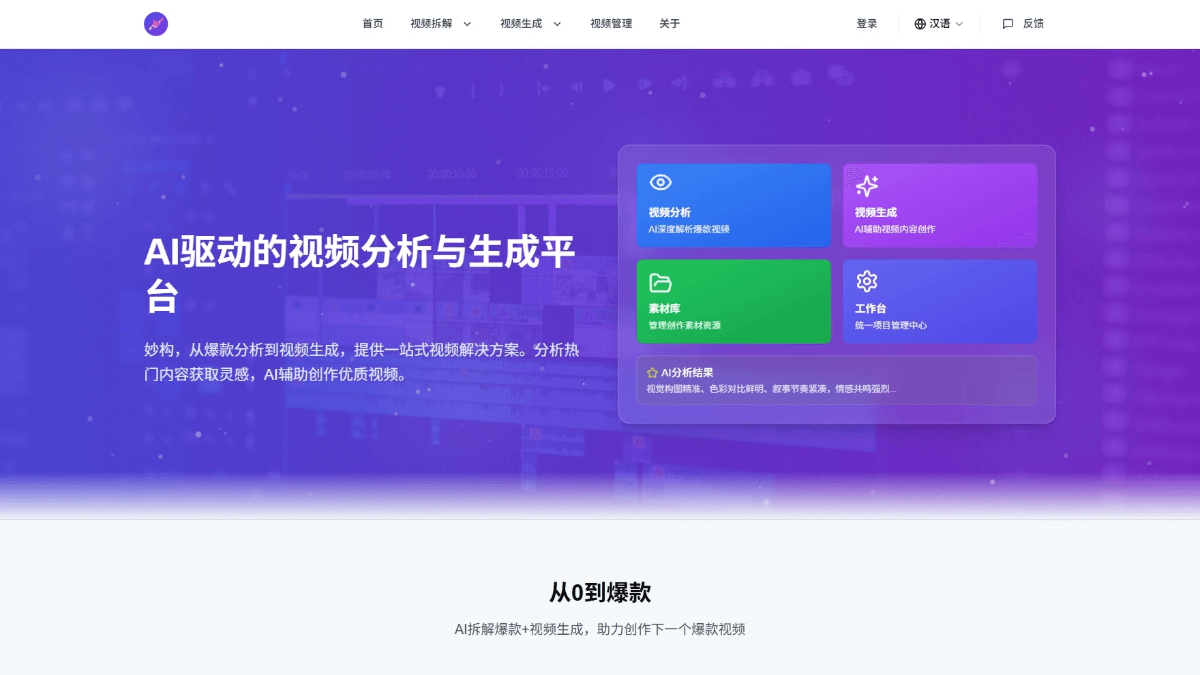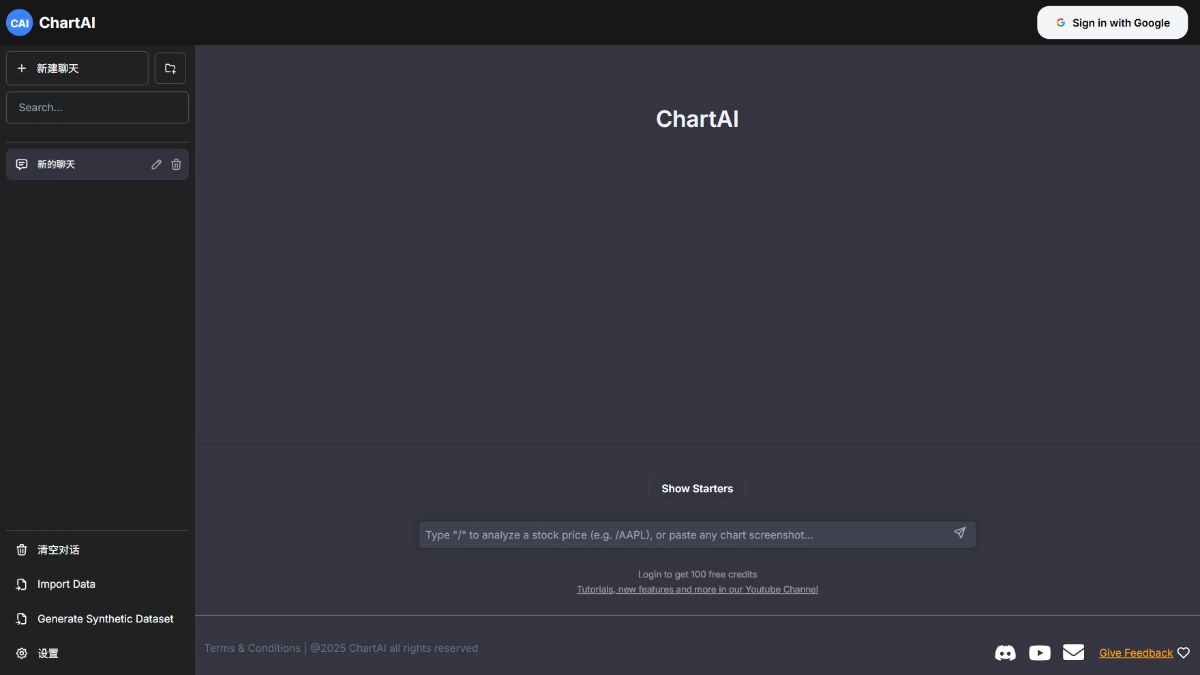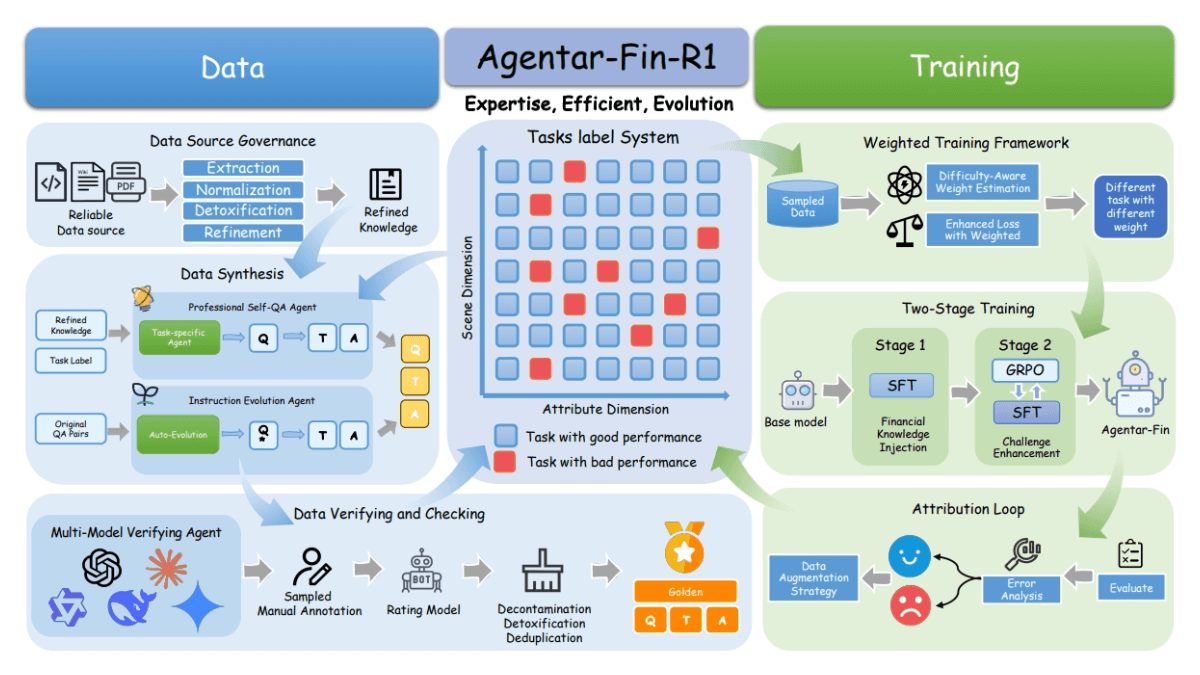
Agentar-Fin-R1 - A Grand Model for Reasoning in Finance by Anthem Digital
Agentar-Fin-R1 is a state-of-the-art large language model for the financial domain introduced by Anthem. Developed based on the powerful Qwen3 architecture, the model provides two parameter scale versions, 8B and 32B, and can accurately handle complex financial reasoning tasks, including multi-step analysis, risk assessment and war...