Recommended 12 Free Digital People Software for Local Deployment

In the rapid development of AI, Digital Humans (Digital Humans) have matured and can be generated quickly at low cost. Because of the wide range of commercial application scenarios, it has received attention. Whether in virtual reality (VR), augmented reality (AR) or film and television production, game development, brand promotion, Digital Humans play an important role.
Broadly speaking, there are 3D modeling (including motion capture) digital people, static 2D image digital people (including real people), and real face-swapping type digital people.
This paper focuses on personal image cloning image class digital man, belongs to the static 2D image digital man, contains three basic function points: real image, voice cloning, mouth synchronization.
Note 1: Some projects do not include voice generation (cloning) part, this is not the point, please can be deployed separately, there are many excellent marketAI Speech Cloning ProgramThe
Note 2: Currently, the quality of 2D static figures varies mainly in the synchronization of their mouths and the naturalness of their "video movements". You can try to optimize them individuallylip syncNodes.
Note 3: Face changing + voice cloning is also a fast way to generate a digital person, suitable for maintaining the image and voice of a public speaker unchanged, and is not included in the following programs. The advanced video face-swapping popularization technology is risky, so it is not introduced.
AIGCPanel: open source clone of the digital man integration system, one-click deployment of free digital man client
AigcPanel is a one-stop AI digital human production system for all users, developed with electron+vue3+typescript technology stack, supporting one-click deployment on Windows system. The system is designed with user-friendliness as the core, so that even users with a weak technical foundation can easily master it. The main functions include video digital human synthesis, speech synthesis, speech cloning, etc., and provides perfect local model management functions. The system supports multi-language interface (including Simplified Chinese and English) and integrates MuseTalk, cosyvoice and many other mature models of one-click startup packages. Particularly worth mentioning is that the system supports video picture and voice transcription matching technology in video synthesis, and provides rich sound parameter setting options in speech synthesis. As an open source project, AigcPanel is released based on the AGPL-3.0 protocol, while emphasizing compliant use and explicitly prohibiting its use for any illegal and illicit business.

DUIX: Real-time interactive intelligent digital people with multi-platform one-click deployment support
DUIX (Dialogue User Interface System) is an AI-driven digital human interaction platform created by Silicon Intelligence. With open source digital human interaction features, developers can easily integrate large-scale models, automatic speech recognition (ASR) and text-to-speech (TTS) functions to achieve real-time interaction with digital humans.DUIX supports one-click deployment on multiple platforms such as Android and iOS, making it easy for every developer to create intelligent and personalized digital human agents that can be applied to various industries. With low deployment cost, low network dependency, and diverse functionality, the platform is able to meet the needs of a wide range of industries, including video, media, customer service, finance, radio and television.

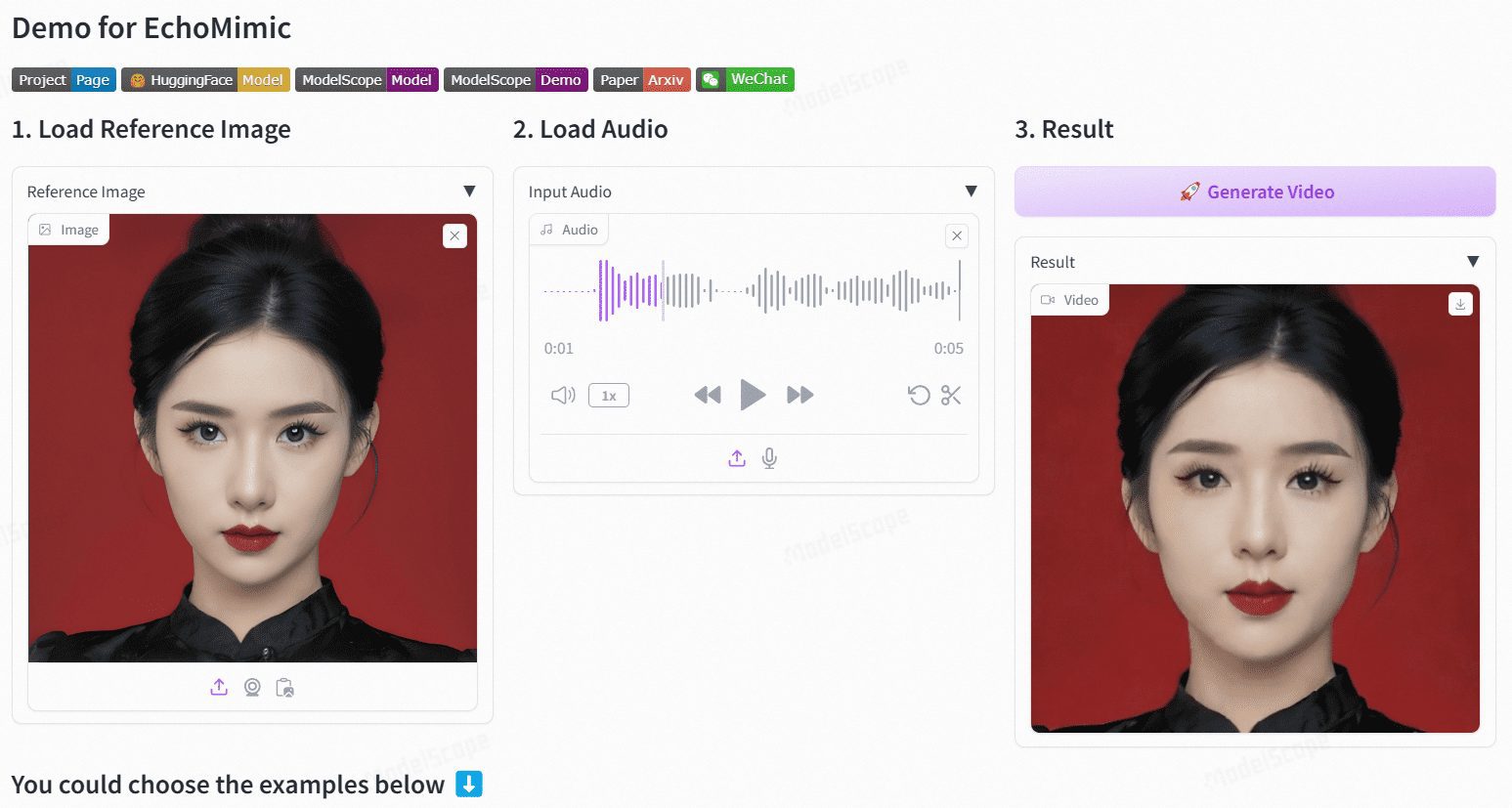
EchoMimic: audio-driven realistic portrait animation
EchoMimic is an open source project designed to generate realistic portrait animations through audio-driven generation. Developed by Ant Group's Terminal Technologies division, the project utilizes editable marker point conditions that combine audio and facial marker points to generate dynamic portrait videos.EchoMimic has been comprehensively compared across multiple public and proprietary datasets, demonstrating its superior performance in both quantitative and qualitative evaluations.
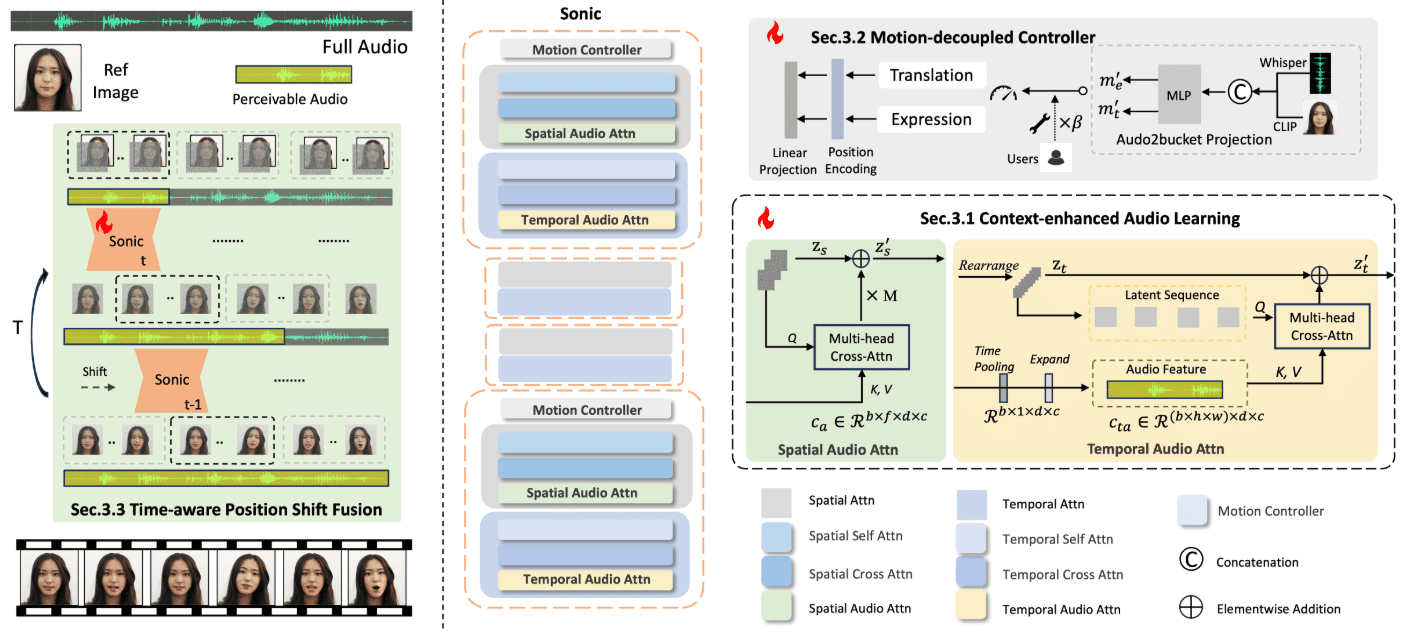
Sonic: A new open source solution for digital humans, audio driven to generate digital demo videos with vivid facial expressions
Sonic Sonic is an innovative platform focused on global audio perception, designed to generate vivid portrait animations driven by audio. Developed by a team of researchers from Tencent and Zhejiang University, the platform utilizes audio information to control facial expressions and head movements to generate natural and smooth animated videos.Sonic's core technologies include context-enhanced audio learning, motion decoupled controllers, and time-aware position shift fusion modules. These technologies enable Sonic to generate long, stable and realistic videos with different styles of images and various types of audio inputs.
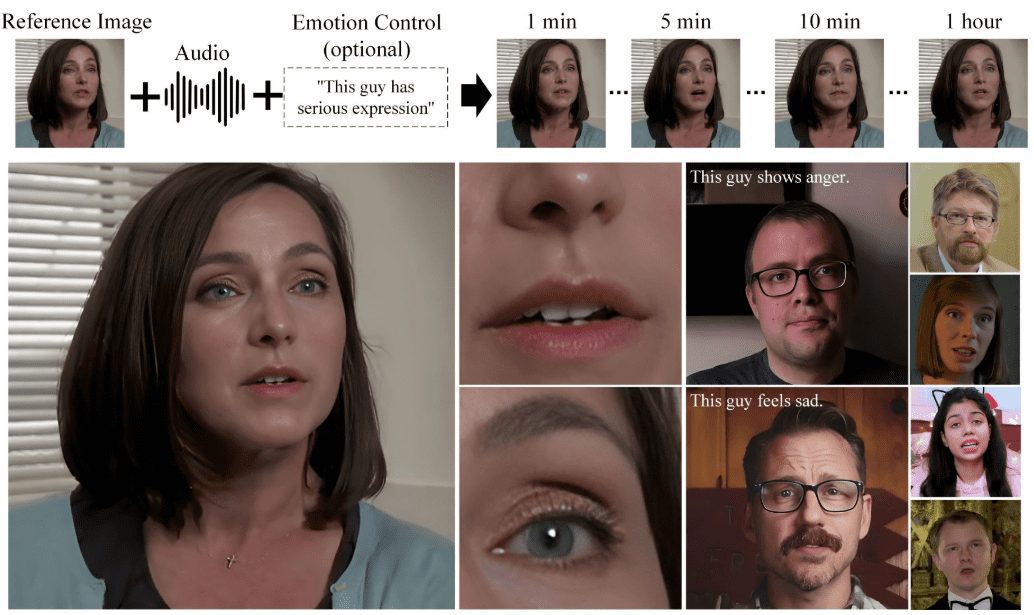
Hallo2: Audio-driven generation of lip-synchronized/expression-synchronized portrait video (with Windows one-click installation)
Hallo2 is an open source project jointly developed by Fudan University and Baidu to generate high-resolution portrait animations through audio-driven generation. The project utilizes advanced Generative Adversarial Networks (GAN) and time alignment techniques to achieve 4K resolution and up to 1 hour of video generation.Hallo2 also supports text prompts to enhance the diversity and controllability of generated content.
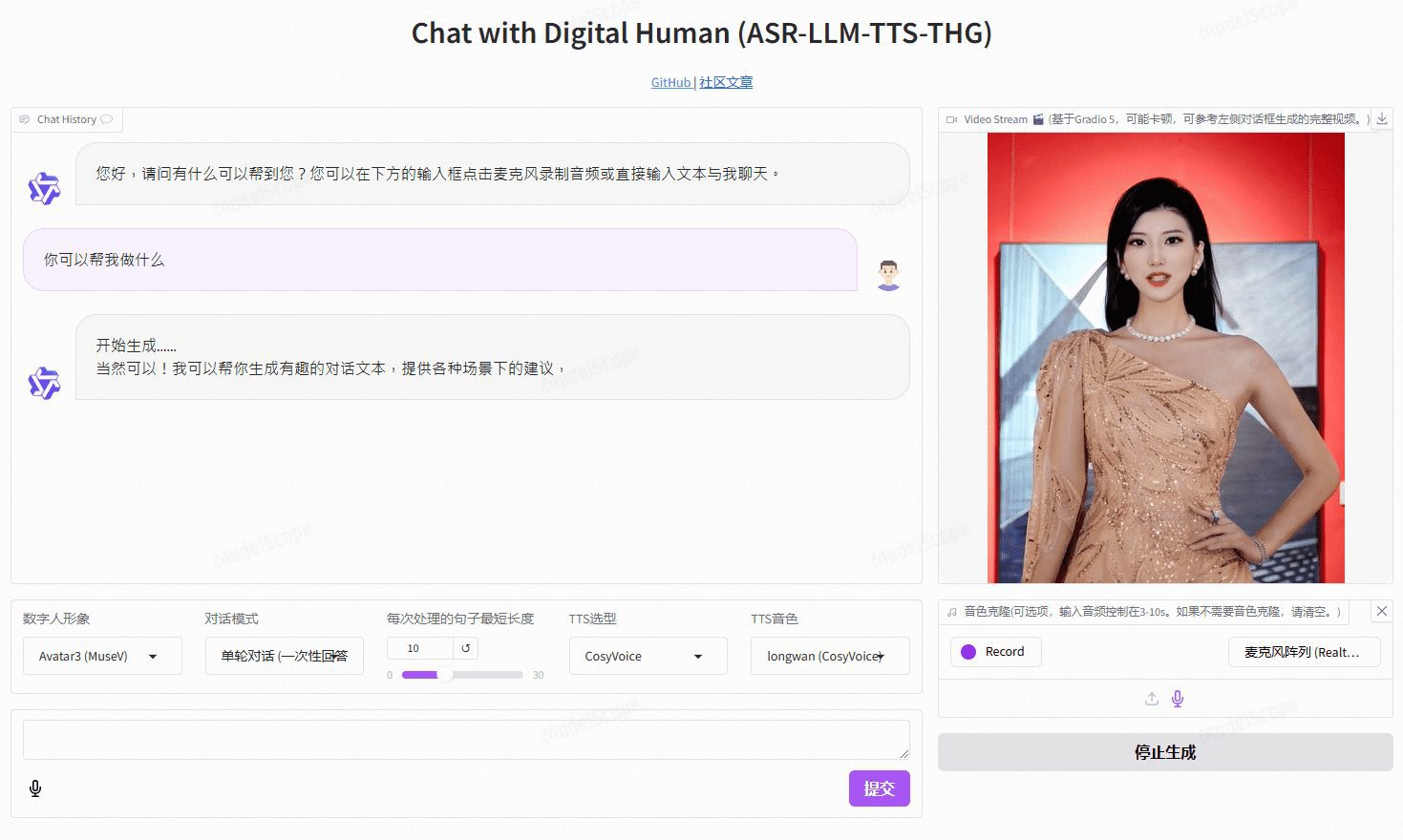
VideoChat: real-time voice-interactive digital person with customized image and tone cloning, supporting end-to-end voice solutions and cascading solutions
VideoChat is a real-time voice interaction digital human project based on open source technology, supporting end-to-end voice scheme (GLM-4-Voice - THG) and cascade scheme (ASR-LLM-TTS-THG). The project allows users to customize the image and timbre of the digital human, and supports timbre cloning and lip synchronization, video streaming output, and first packet delay as low as 3 seconds. Users can experience its features through online demos, or deploy and use it locally through detailed technical documentation.
TalkingAvatar: AI avatar video platform for creating and editing AI avatars, based on native arithmetic Windows client
TalkingAvatar is a leading AI avatar platform that offers a complete AI digital person solution. Offers users a revolutionary way to create, edit and personalize video content. With advanced AI technology, users can easily rewrite videos, clone voices, synchronize lips, and create custom videos. Whether it's re-dubbing an existing video or creating a new story from scratch, TalkingAvatar has you covered.

SadTalker: Make Photos Talk | Mouth Synchronized Audio | Synthesized Mouth Synchronized Video | Free Digital People
SadTalker is an open source tool that combines a single still portrait photo with an audio file to create realistic talking head videos for a wide range of scenarios such as personalized messages, educational content, and more. The revolutionary use of 3D modeling technologies such as ExpNet and PoseVAE excels in capturing subtle facial expressions and head movements. Users can utilize SadTalker technology in both personal and commercial projects such as messaging, teaching or marketing.

AniPortrait: Audio-driven picture or video motion to generate realistic digital human speech video
AniPortrait is an innovative framework for generating realistic portrait animations driven by audio. Developed by Huawei, Zechun Yang, and Zhisheng Wang of Tencent Game Know Yourself Lab, AniPortrait is capable of generating high-quality animations from audio and reference portrait images, and can even beProvide video for facial reenactment. By using advanced 3D intermediate representation and 2D facial animation techniques, the framework is able to generate natural and smooth animation effects for a variety of application scenarios such as film and television production, virtual anchors and digital people.

MuseV+Muse Talk: Complete Digital Human Video Generation Framework | Portrait to Video | Pose to Video | Lip Synchronization
MuseV is a public project on GitHub that aims to enable the generation of avatar videos of unlimited length and high fidelity. It is based on diffusion technology and provides various features such as Image2Video, Text2Image2Video, Video2Video and more. Details of the model structure, use cases, quick start guide, inference scripts and acknowledgements are provided.

DreamTalk: Generate expressive talking videos with a single avatar image!
DreamTalk is a diffusion model-driven expressive talking head generation framework, jointly developed by Tsinghua University, Alibaba Group and Huazhong University of Science and Technology. It consists of three main components: a noise reduction network, a style-aware lip expert and a style predictor, and is capable of generating diverse and realistic talking heads based on audio input. The framework is capable of handling both multilingual and noisy audio, providing high-quality facial motion and accurate mouth synchronization.

Translation Starter: Open Source Video Content Translation Synchronization Tool|Language Conversion|Lip Synchronization
Translation Starter is an open source project developed by Sync Labs to help developers quickly integrate multilingual support for video content. It provides the necessary APIs and documentation for developers to easily create applications that require video translation with lip sync. It is based on powerful AI technologies such as Sync Lab's Perfect Lip Synchronization, Open AI's Whisper Translation Technology and Eleven Labs' Sound Synthesis.

© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles

No comments...