Free course on how Transformer LLMs work by Enda Wu

How do Transformer LLMs work?
Transformer How LLMs Work is a course from DeepLearning.AI in collaboration with Jay Alammar and Maarten Grootendorst, authors of Hands-On Large Language Models. The course provides an in-depth look at the Transformer architecture that supports Large Language Models (LLMs). The course starts with the evolution of the numerical representation of languages and covers topics such as disambiguation, the attention mechanism and feedforward layer of Transformer blocks, and how to improve performance by caching computations. After completing the course, users will have an in-depth understanding of how LLMs process languages, be able to read and understand relevant papers, and improve their ability to build LLM applications.
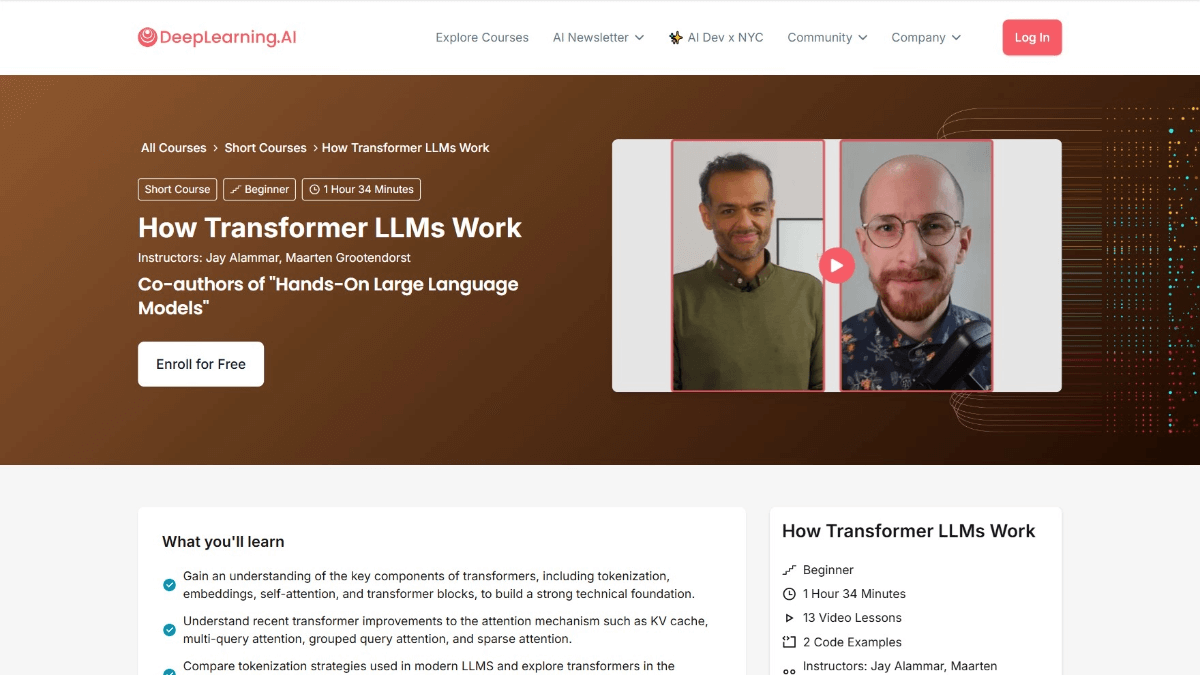
Course Objectives for How Transformer LLMs Work
- Understanding the evolution of numerical representation of language: Understand how language is represented digitally, from simple Bag-of-Words models to complex Transformer architectures.
- Mastering participle processing: Learning how to decompose input text into "tokens" and understanding how the tokens are fed into the language model.
- Diving into the Transformer Architecture: A detailed look at the three main phases of the Transformer architecture: disambiguation and embedding, Transformer block stacking, and language modeling headers.
- Understanding the details of the Transformer block: Includes attention mechanisms and feedforward layers, and how they work together to process and generate text.
- Learning Performance Optimization: Learn how to improve the performance of Transformer through techniques such as cache computing.
- Practical Application Exploration: Exploring recent model implementations for enhanced practical applications through the Hugging Face Transformer library.
Course Outline for How Transformer LLMs Work
- Overview of Transformer LLMs: Introduces the course objectives, structure, and importance of the Transformer architecture in modern large language models (LLMs).
- Evolution of linguistic representation: Learn about the evolution of language modeling from Bag-of-Words to Word2Vec to the Transformer architecture.
- participle and embedding: Learn how input text is decomposed into tokens, and how to convert tokens into embedding vectors, including the application of positional coding.
- Transformer block: Understand the structure of the Transformer block, including the self-attention mechanism and the role of feedforward networks.
- Long Attention: Explore how multi-head attentional mechanisms can improve model performance by capturing different aspects of the input through multiple "heads".
- Transformer Block Stacking: Learn how to build deep models by stacking multiple Transformer blocks, and the role of residual linking and layer normalization.
- Language Model Header: Understand how Transformer implements text generation by generating the probability distribution of the next token from the language model header.
- caching mechanism: Learn how to improve the inference speed of Transformer models through caching mechanisms, and practical applications of caching.
- Latest Architectural Innovations: Introduces the latest innovations in Mixture-of-Experts (MoE) and other Transformer architectures.
- Implementing the Transformer with Hugging Face: Learn how to load and fine-tune pre-trained Transformer models with the Hugging Face Transformers library.
- Transformer's hands-on coding: Learn how to implement the key components of the Transformer and build a simple Transformer model through practical coding exercises.
- Reading and Comprehension Research Paper: Learn how to read and understand Transformer-related research papers, analyzing recent papers and their contributions to the field.
- Building LLM Applications: Explore how to develop LLM-based applications and discuss future directions and potential applications of the Transformer architecture.
Address of the course on how Transformer LLMs work
- Course Address::DeepLearning.AI
Who Transformer LLMs Work For
- natural language processing (NLP) researcher: In-depth study of the Transformer architecture, exploring cutting-edge applications in the fields of language understanding, generation and translation, and promoting the development of natural language processing technology.
- Machine Learning Engineer: Master the workings of Transformer to be able to optimize model performance, improve model accuracy and efficiency, and develop more powerful language model applications.
- data scientist: Processing and analyzing large-scale text data with the Transformer architecture, mining the data for patterns and information to support decision-making.
- software developer: Integrate Transformer LLMs into various software applications, such as chatbots, content recommendation systems, etc., to enhance product intelligence.
- Artificial Intelligence Enthusiasts: Interested in the Transformer architecture and looking to learn how it works, gain a deeper understanding of AI technology and expand your technical horizons.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...