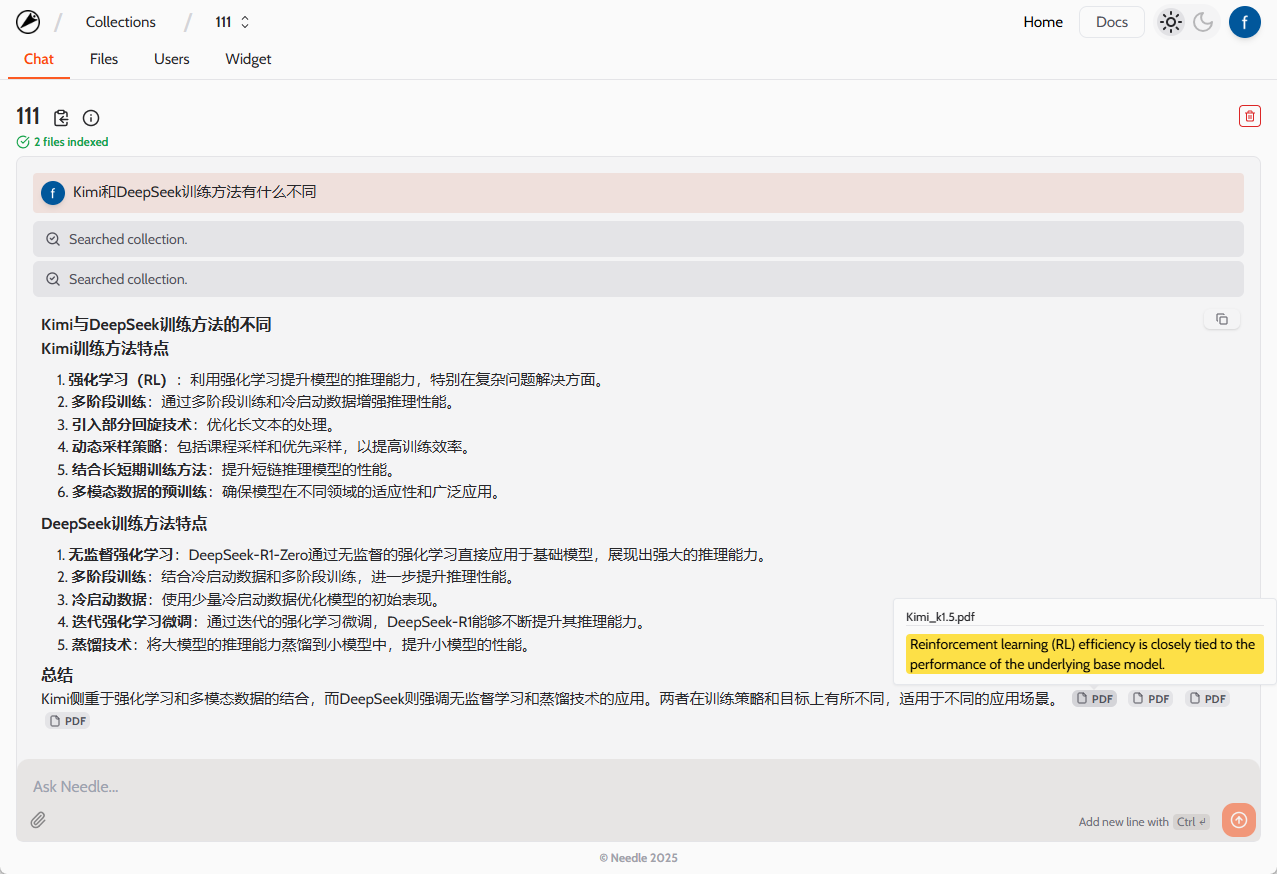
TPO-LLM-WebUI: An AI framework where you can input questions to train a model to output results in real time

General Introduction
TPO-LLM-WebUI is an innovative project open-sourced by Airmomo on GitHub, which enables real-time optimization of Large Language Models (LLMs) through an intuitive web interface. It adopts the TPO (Test-Time Prompt Optimization) framework, completely bidding farewell to the tedious process of traditional fine-tuning, and directly optimizing the model output without training. After the user inputs a question, the system uses rewarding models and iterative feedback to allow the model to dynamically evolve during the reasoning process, making it smarter and smarter, and improving the quality of the output by up to 50%. Whether it's for technical document touch-ups or security response generation, this lightweight and efficient tool provides powerful support for developers and researchers.


Function List
- Real-time evolution: Optimize the output through the inference phase, the more you use it, the more it meets the user's needs.
- No fine-tuning required: Not updating model weights and directly improving generation quality.
- Multi-model compatible: Support for loading different base and reward models.
- Dynamic preference alignment: Adjusting output based on reward feedback to approximate human expectations.
- Reasoning Visualization: Demonstrate the optimization iteration process for easy understanding and debugging.
- Lightweight and efficient: Computing is low cost and simple to deploy.
- Open Source Flexibility: Provides source code and supports user-defined development.
Using Help
Installation process
The deployment of TPO-LLM-WebUI requires some basic environment configuration. Below are the detailed steps to help users get started quickly.
1. Preparing the environment
Make sure the following tools are installed:
- Python 3.10: Core Operating Environment.
- Git: Used to get the project code.
- GPU (recommended): NVIDIA GPUs accelerate inference.
Create a virtual environment:
Use Condi:
conda create -n tpo python=3.10
conda activate tpo
or Python's own tools:
python -m venv tpo
source tpo/bin/activate # Linux/Mac
tpo\Scripts\activate # Windows
Download and install the dependencies:
git clone https://github.com/Airmomo/tpo-llm-webui.git
cd tpo-llm-webui
pip install -r requirements.txt
Install TextGrad:
TPO relies on TextGrad, which requires additional installation:
cd textgrad-main
pip install -e .
cd ..
2. Configuration model
You need to manually download the base model and the bonus model:
- basic modelAs
deepseek-ai/DeepSeek-R1-Distill-Qwen-32B(Hugging Face) - reward modelAs
sfairXC/FsfairX-LLaMA3-RM-v0.1(Hugging Face)
Place the model in the specified directory (e.g./model/HuggingFace/), and inconfig.yamlSet the path in the
3. Start the vLLM service
utilization vLLM Hosting base model. Take 2 GPUs as an example:
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
--dtype auto
--api-key token-abc123
--tensor-parallel-size 2
--max-model-len 59968
--port 8000
After the service is running, listen to the http://127.0.0.1:8000The
4. Running WebUI
Launch the web interface in a new terminal:
python gradio_app.py
browser access http://127.0.0.1:7860The following is an example of how to use it.
Main function operation flow
Function 1: Model initialization
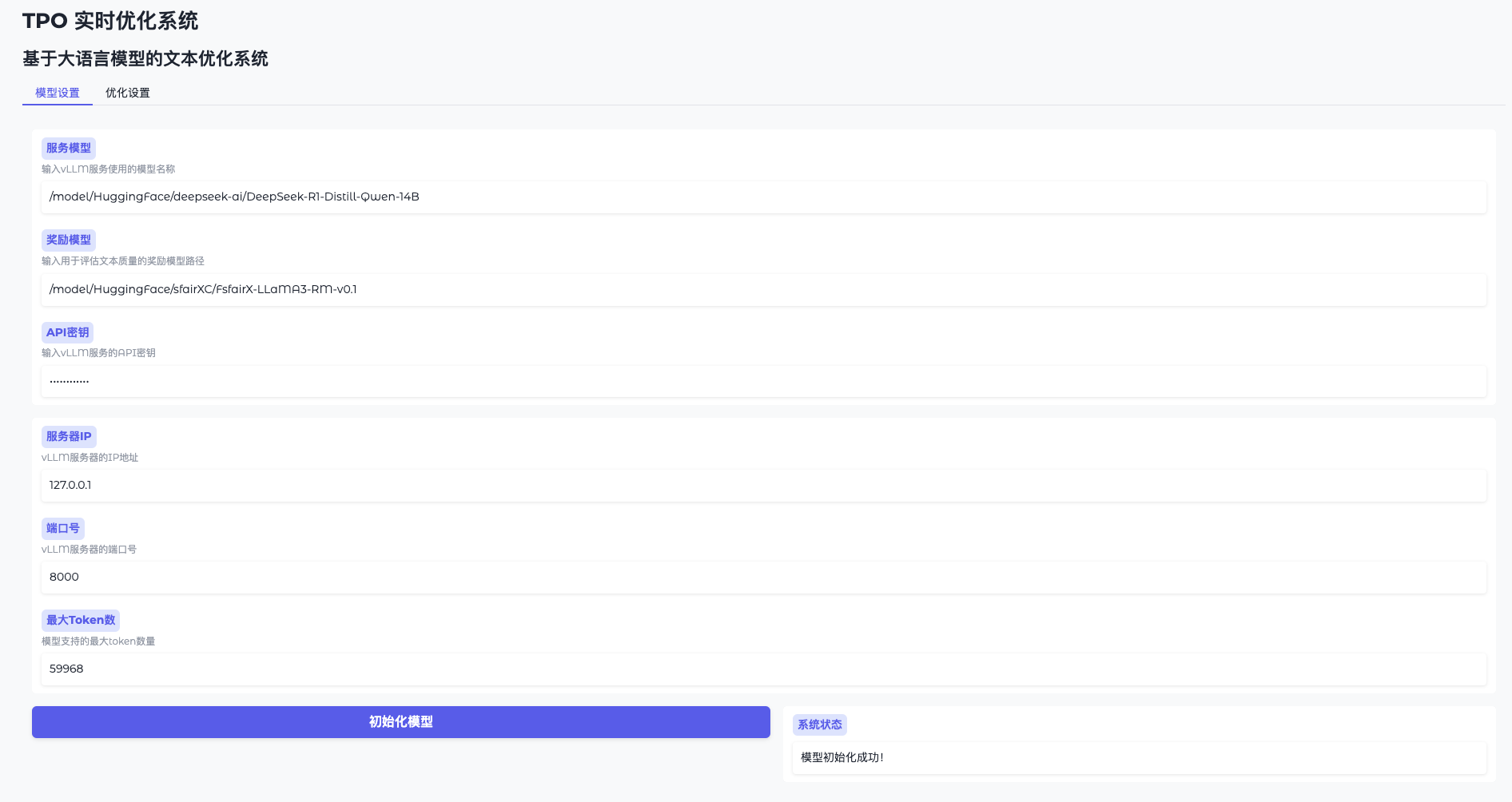
- Open Model Settings
Go to WebUI and click "Model Settings". - Connecting to vLLM
Enter the address (e.g.http://127.0.0.1:8000) and the key (token-abc123). - Loading Reward Models
Specify the path (e.g./model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1Click "Initialize" and wait for 1-2 minutes. - Confirmation of readiness
You can continue after the interface prompts "Model ready".
Function 2: Real-time optimized output
- Toggle Optimization Page
Go to "Optimize Settings". - Input Issues
Enter content such as "Touch up this technical document". - runtime optimization
Click "Start Optimization" and the system generates multiple candidate results and iteratively improves them. - Check out the evolutionary process
The results page displays the initial and optimized outputs with progressively higher quality.
Function 3: Script mode optimization
If you are not using the WebUI, you can run a script:
python run.py
--data_path data/sample.json
--ip 0.0.0.1
--port 8000
--server_model /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
--reward_model /model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1
--tpo_mode tpo
--max_iterations 2
--sample_size 5
Optimization results are saved to logs/ Folder.
Featured Functions Detailed Description
Say goodbye to fine-tuning and evolve in real time
- procedure::
- Enter the question and the system generates the initial response.
- Reward model evaluation and feedback to guide the next iteration.
- After several iterations, the output becomes "smarter" and the quality improves significantly.
- dominance: Save time and arithmetic by optimizing at any time without training.
The more you use it, the smarter you get.
- procedure::
- Use the same model multiple times with different inputs for different problems.
- The system accumulates experience based on each feedback and the output is better tailored to the needs.
- dominance: Dynamically learns user preferences for better results in the long run.
caveat
- hardware requirementRecommended 16GB or more of video memory, multiple GPUs need to ensure that resources are free and available.
export CUDA_VISIBLE_DEVICES=2,3Designation. - Problem solving: When the video memory overflows, lower the
sample_sizeor check GPU occupancy. - Community Support: See the GitHub README or Issues for help.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...