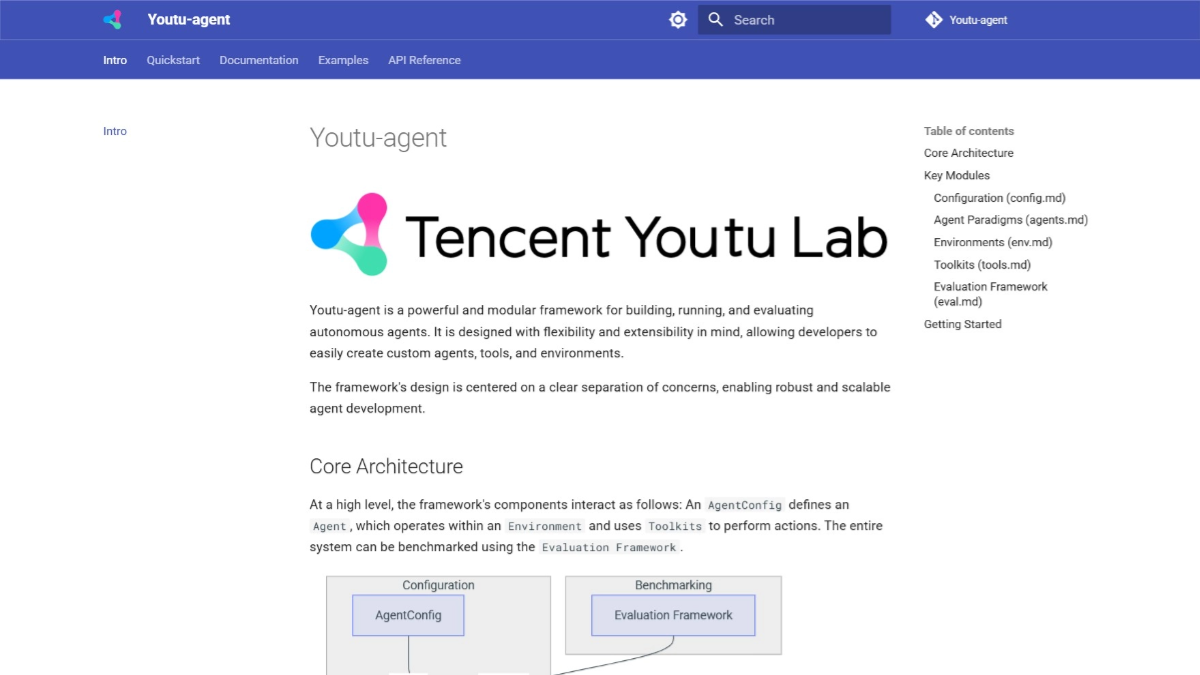
ThinkSound - Audio Generation Model launched by Ali Tongyi

What is ThinkSound?
ThinkSound is the first CoT (Chain Thinking) audio generation model introduced by Ali Tongyi's speech team. The model can generate precisely matched sound effects for video images, based on the introduction of CoT reasoning, to solve the problem that traditional technology is difficult to capture the dynamic details and spatial relationships of the image. The model is based on a third-order chain of thought that drives audio generation, including basic sound inference, object-level interaction, and command editing. The model is equipped with AudioCoT dataset, which contains audio data annotated with thought chains and has excellent performance on the VGGSound dataset.ThinkSound is supported in film and television production, game development, advertising and marketing, and virtual reality (VR) and augmented reality (AR) to enhance the realism and immersion of synchronized audio and video.

ThinkSound's main features
- Basic sound generation: Based on the content of the video, generate basic sound effects that match the semantics and timing of the screen to provide a suitable audio background for the video, so that the video is no longer monotonous and silent.
- Interactive object-level refinement: The user clicks on a specific object in the video to refine and optimize the sound effects of the specific object, so that the sound effects more accurately fit the specific visual elements and enhance the coordination of the sound and picture.
- Command-driven audio editing: It supports users to edit the generated audio with natural language commands, such as adding, deleting or modifying specific sound effects, to meet different creative needs and make the audio generation more flexible and diversified.
ThinkSound's official website address
- Project website:: https://thinksound-project.github.io/
- GitHub repository:: https://github.com/liuhuadai/ThinkSound
- HuggingFace Model Library:: https://huggingface.co/liuhuadai/ThinkSound
- arXiv Technical Paper:: https://arxiv.org/pdf/2506.21448
How to use ThinkSound
- environmental preparation::
- Installing Python: Ensure that Python is installed on your system (Python 3.8 and above is recommended).
- Installation of dependent libraries: Install the required dependency libraries for ThinkSound based on the following commands:
pip install -r requirements.txt- The specific dependency file requirements.txt can be found in the GitHub repository.
- Download model::
- GitHub Repository Download: Visit ThinkSound's GitHub repository (https://github.com/liuhuadai/ThinkSound) to clone the repository locally:
git clone https://github.com/liuhuadai/ThinkSound.git
cd ThinkSound- Hugging Face Download: Download the mold directly from the Hugging Face model library (https://huggingface.co/liuhuadai/ThinkSound).
- Data preparation::
- Preparing the video file: Make sure there is a video file, ThinkSound will generate audio based on that video.
- Preparing the command file: If natural language instructions are needed to edit the audio, prepare a text file containing the instructions.
- operational model::
- Basic sound generation: Run the following command to generate the base sound:
python generate.py --video_path <path_to_your_video> --output_path <path_to_output_audio>- Interactive object-level refinement: If you need to refine the sound effects for a specific object, you can do so by modifying the relevant parameters in the code or by using the interactive interface (if supported).
- Command-driven audio editing: Edit the audio with natural language commands, based on the following commands:
python edit.py --audio_path <path_to_generated_audio> --instruction_file <path_to_instruction_file> --output_path <path_to_edited_audio>- View Results::
- Checking the generated audio: In the specified output path, find the generated audio file, play and check it based on the audio player.
- Adjustment parameters: According to the generated audio effect, adjust the model parameters or input commands to obtain a more satisfactory audio effect.
ThinkSound's Core Benefits
- Chained Thinking Reasoning (CoT): Based on multi-step reasoning to mimic the creative process of human sound engineers, it accurately captures the dynamic details and spatial relationships of the screen, generates highly-matched audio, and enhances the realism of synchronized sound and picture.
- Multimodal Large Language Model (MLLM): Extracting video spatio-temporal information and semantic content based on models such as VideoLLaMA2, generating structured inference chains for semantically matched audio generation, and enhancing audio-picture coordination.
- Unified Audio Base Model: Generate high-fidelity audio based on conditional flow matching technology combined with multimodal context information, supporting flexible input modal combinations to meet diverse generation and editing needs.
- Interactive object-level refinementThe sound effects are optimized for users clicking on specific objects in the video, so that the sound effects precisely match the visual elements, enhancing the coordination and realism of the sound and picture, and the operation is intuitive and convenient.
- Command-driven audio editing: Supports natural language commands for audio editing, such as adding, deleting or modifying specific sound effects, enabling highly customized audio generation to meet different creative needs and enhance creative freedom.
- Powerful dataset support: Equipped with AudioCoT dataset with structured CoT annotations, used in training optimization models to enhance the understanding and generation of audio-visual relationships and ensure the quality of audio generation.
Who ThinkSound is for
- moviemaker: Movie and TV series production teams and short video creators, quickly generate realistic background sound effects and scene-specific sound effects to enhance audience immersion and content appeal.
- game developerThe company generates dynamic ambient and interactive sound effects that enhance player immersion and interactivity, saving sound production costs and time.
- Advertising and marketing staff: Ad agencies and social media content creators to generate engaging sound effects and soundtracks for advertising videos and social media videos to enhance content appeal and user engagement.
- Education and training personnel: Online education platforms and corporate trainers generate sound effects for educational videos and simulated training environments that match the content, helping students to better understand and memorize, and enhancing training effectiveness.
- Virtual Reality (VR) and Augmented Reality (AR) Developers: VR/AR application developers and experience designers to generate highly-matched sound effects in virtual environments, enhance user immersion and interaction, and provide personalized experiences.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...