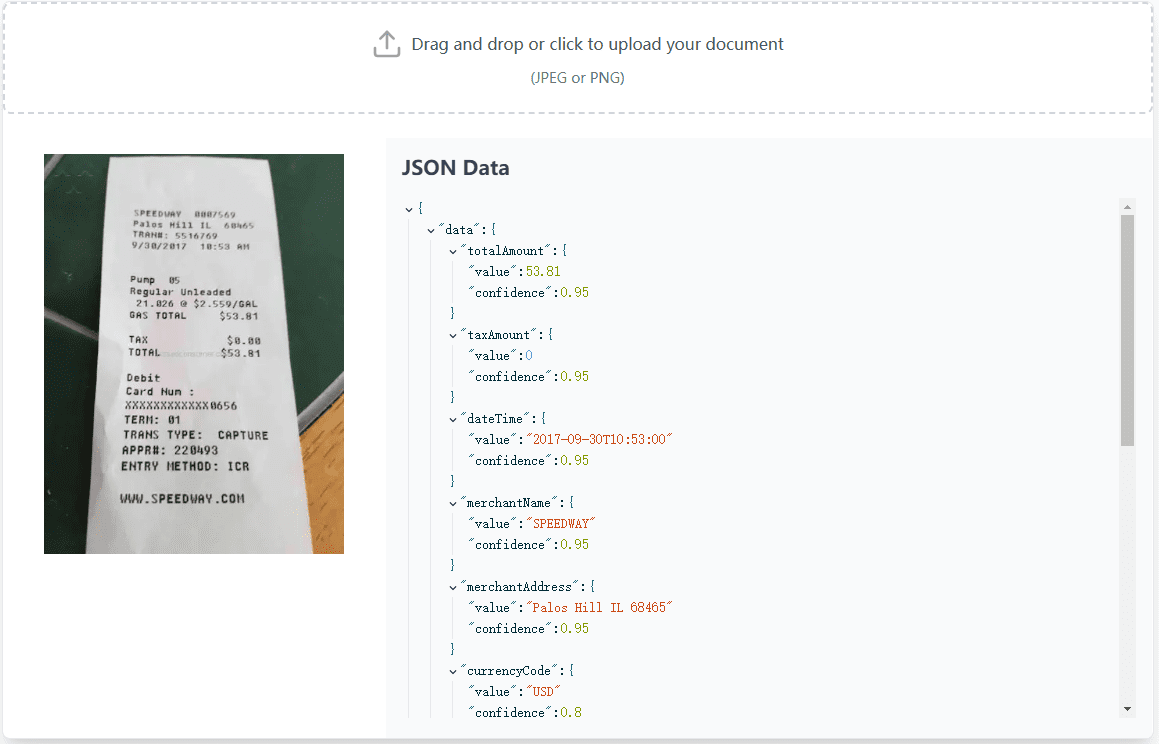
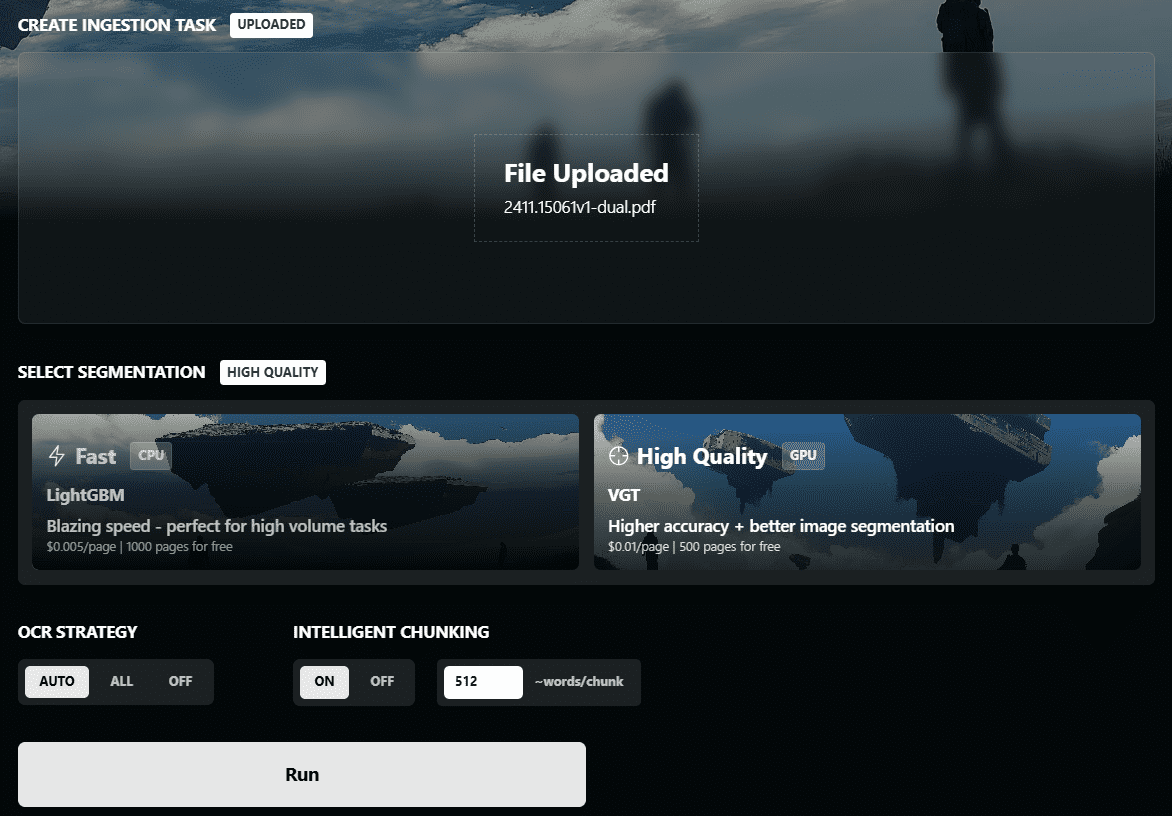
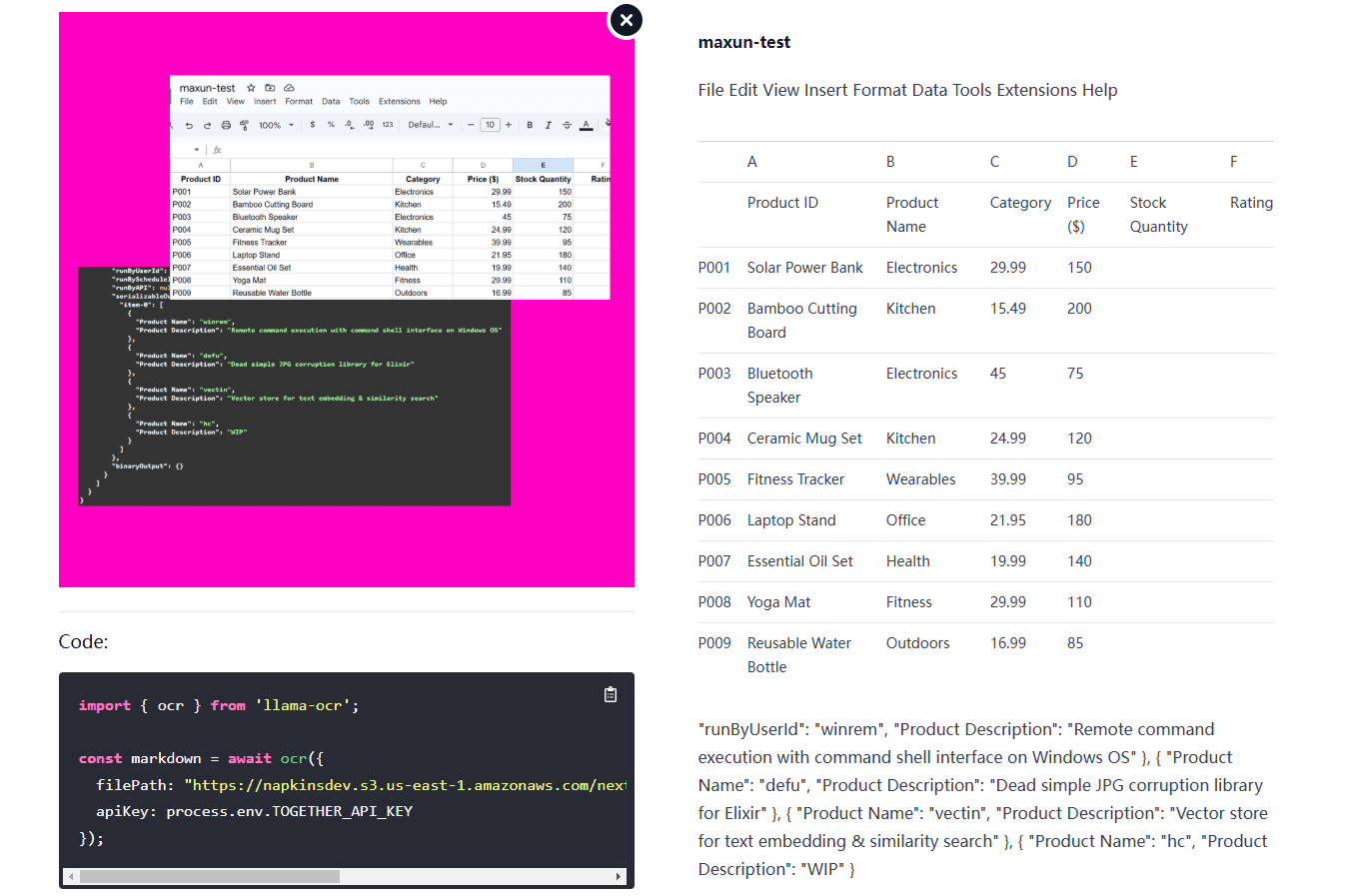
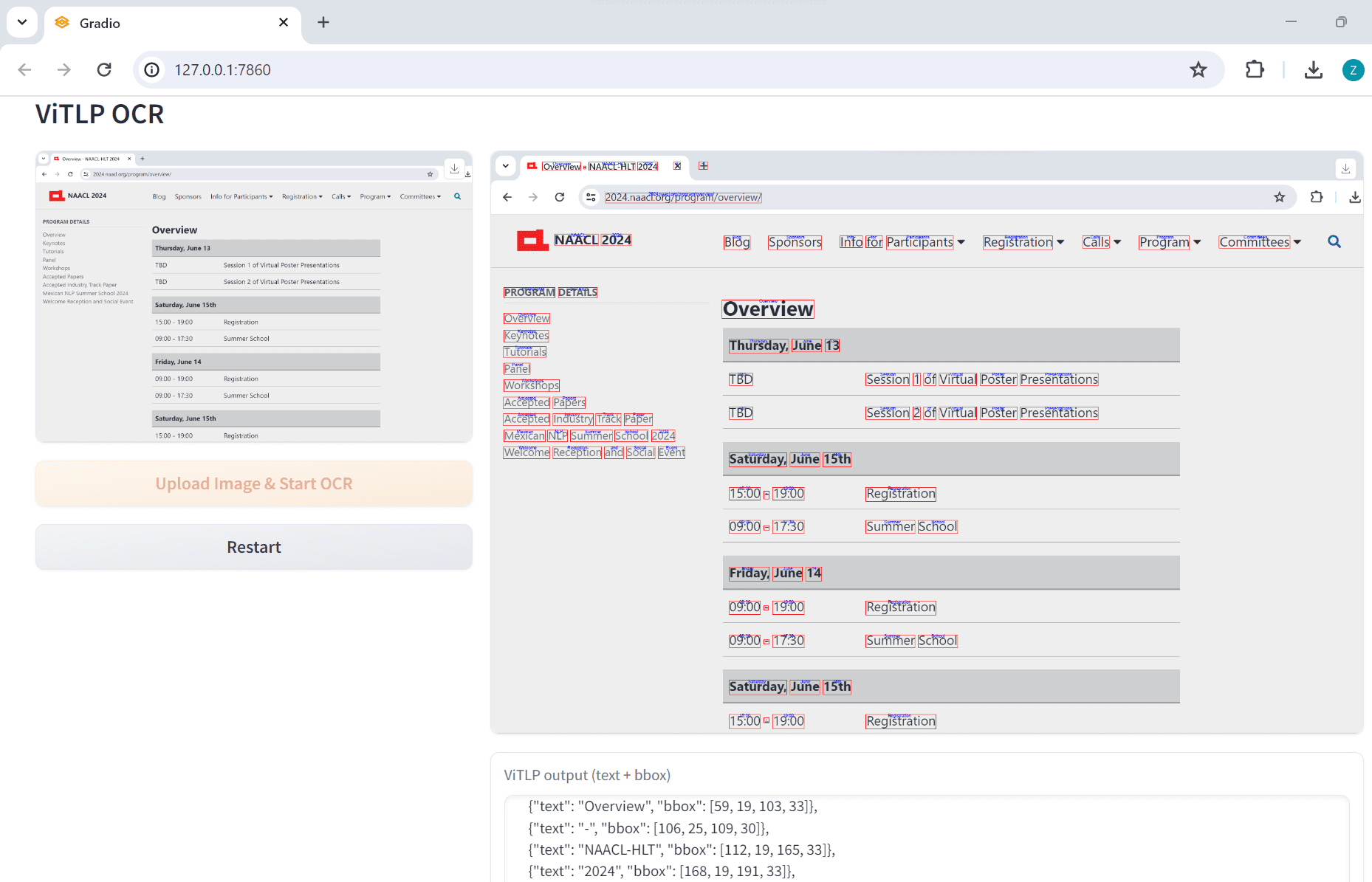
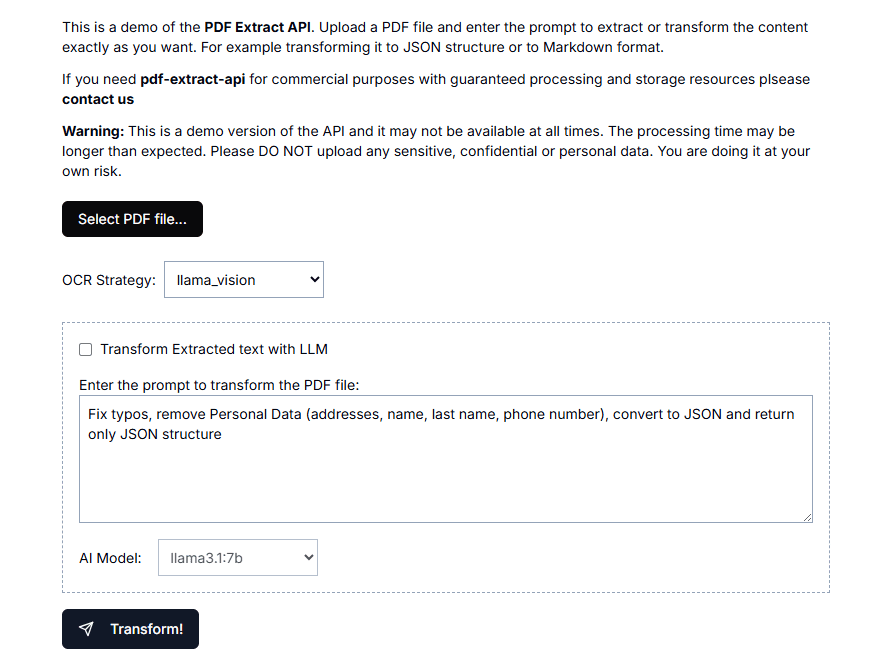
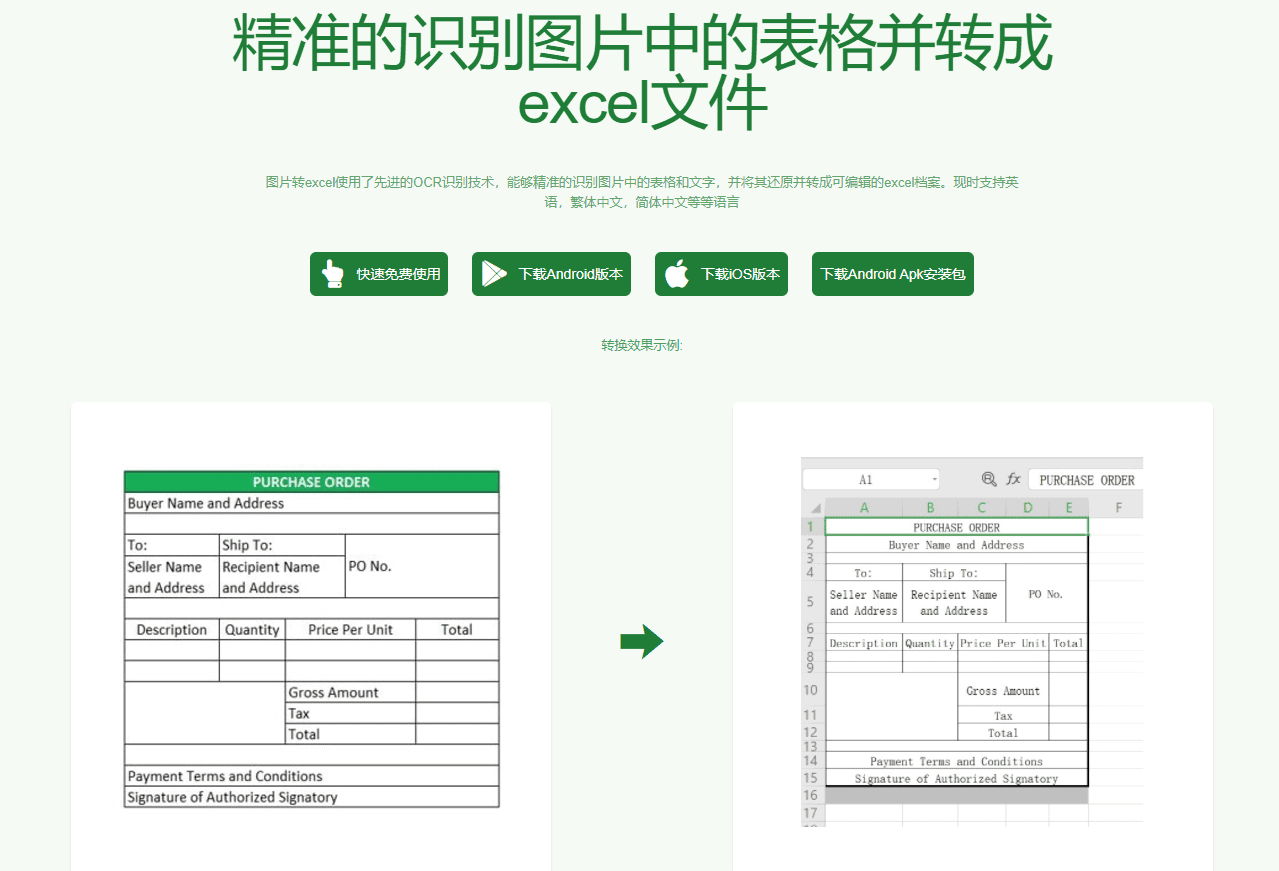
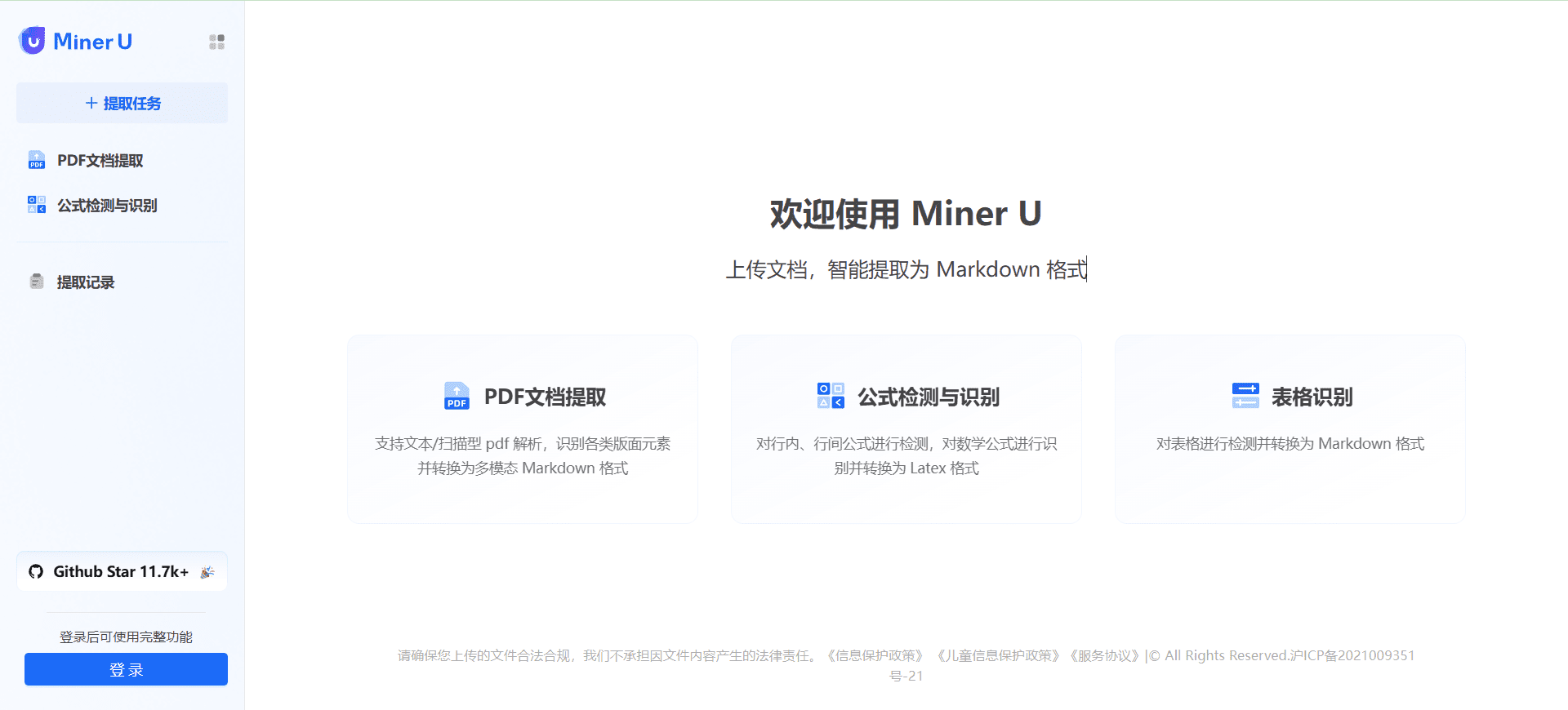
VOP: OCR Tool for Extracting Complex Diagrams and Math Formulas
Comprehensive Introduction Versatile OCR Program is an open source Optical Character Recognition (OCR) tool designed specifically for working with complex academic and educational documents. It can extract text, tables, mathematical formulas, charts and diagrams from PDFs, images and other documents and generate...