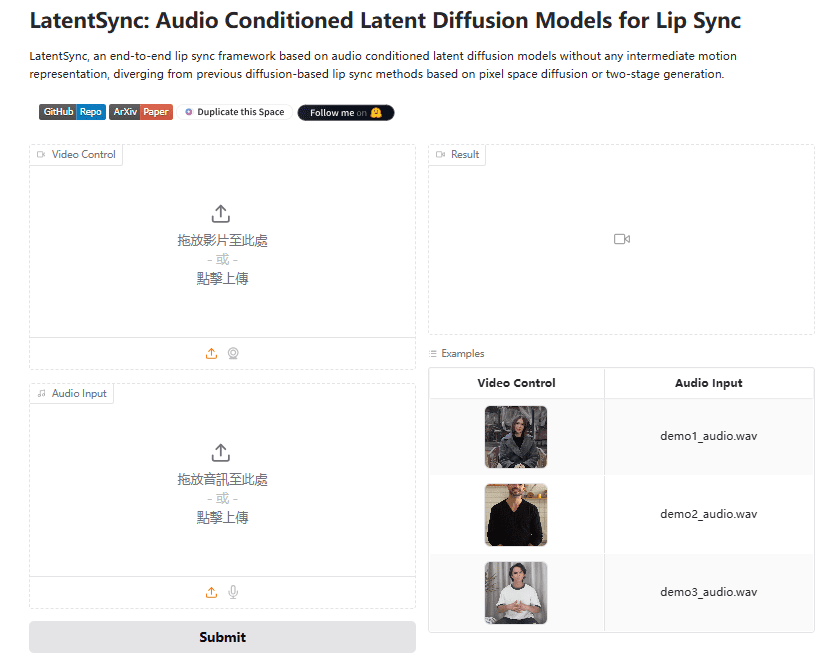
LatentSync: an open source tool for generating lip-synchronized video directly from audio
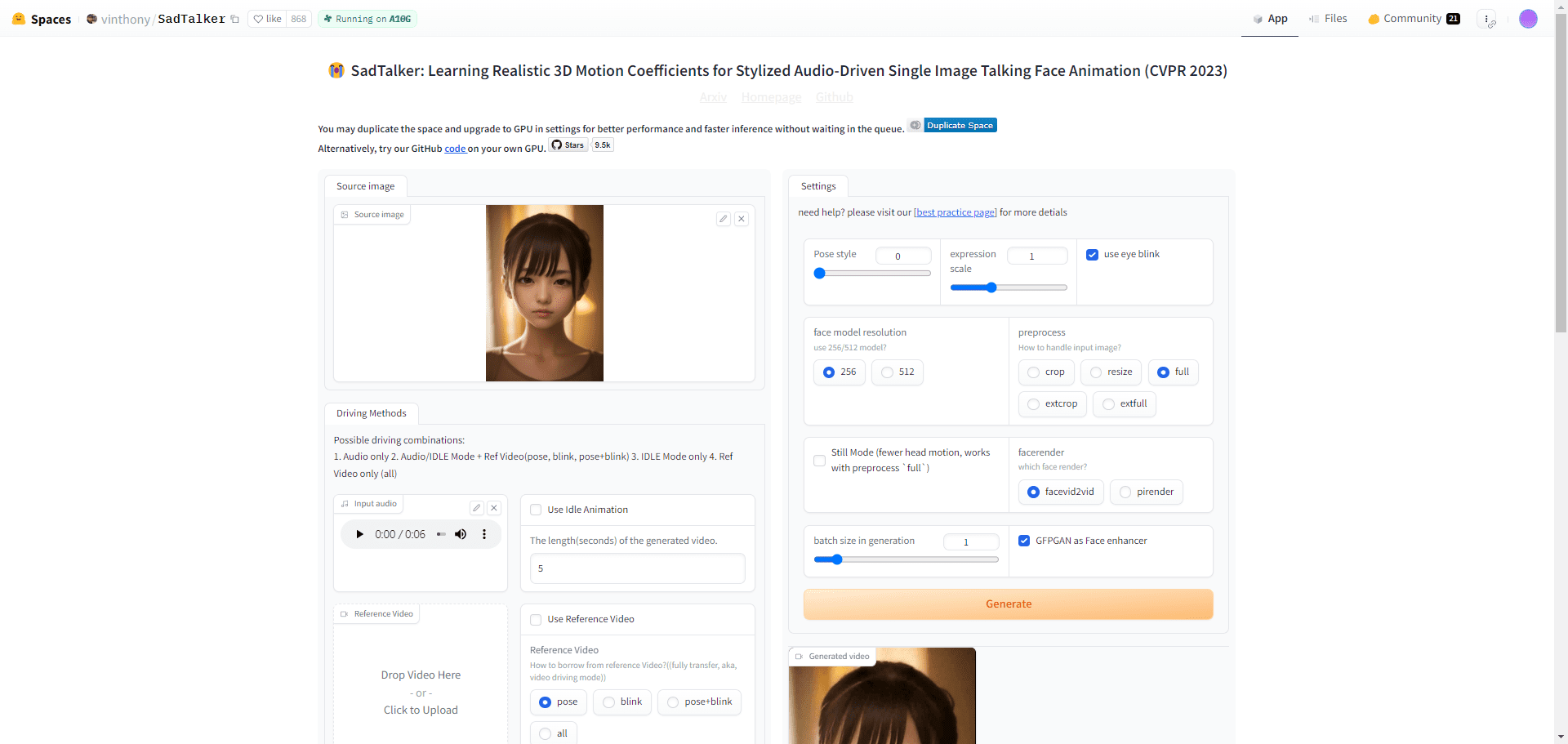
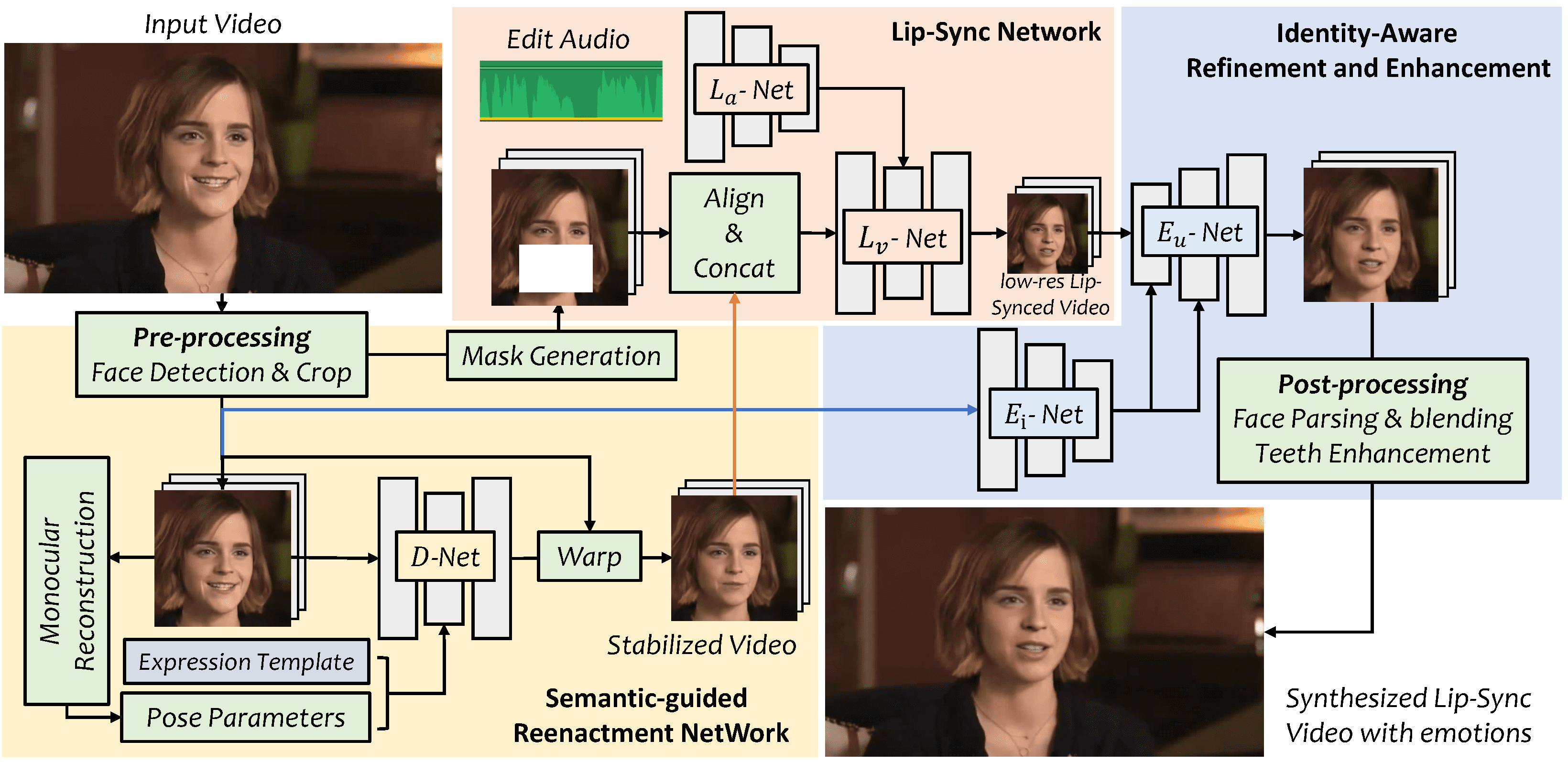
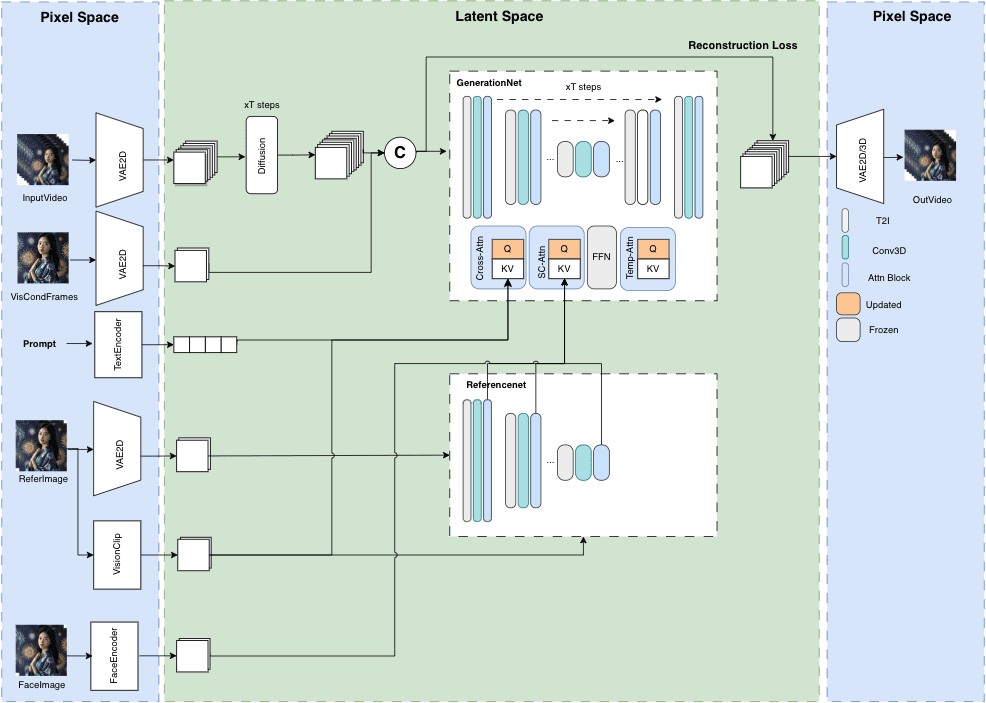
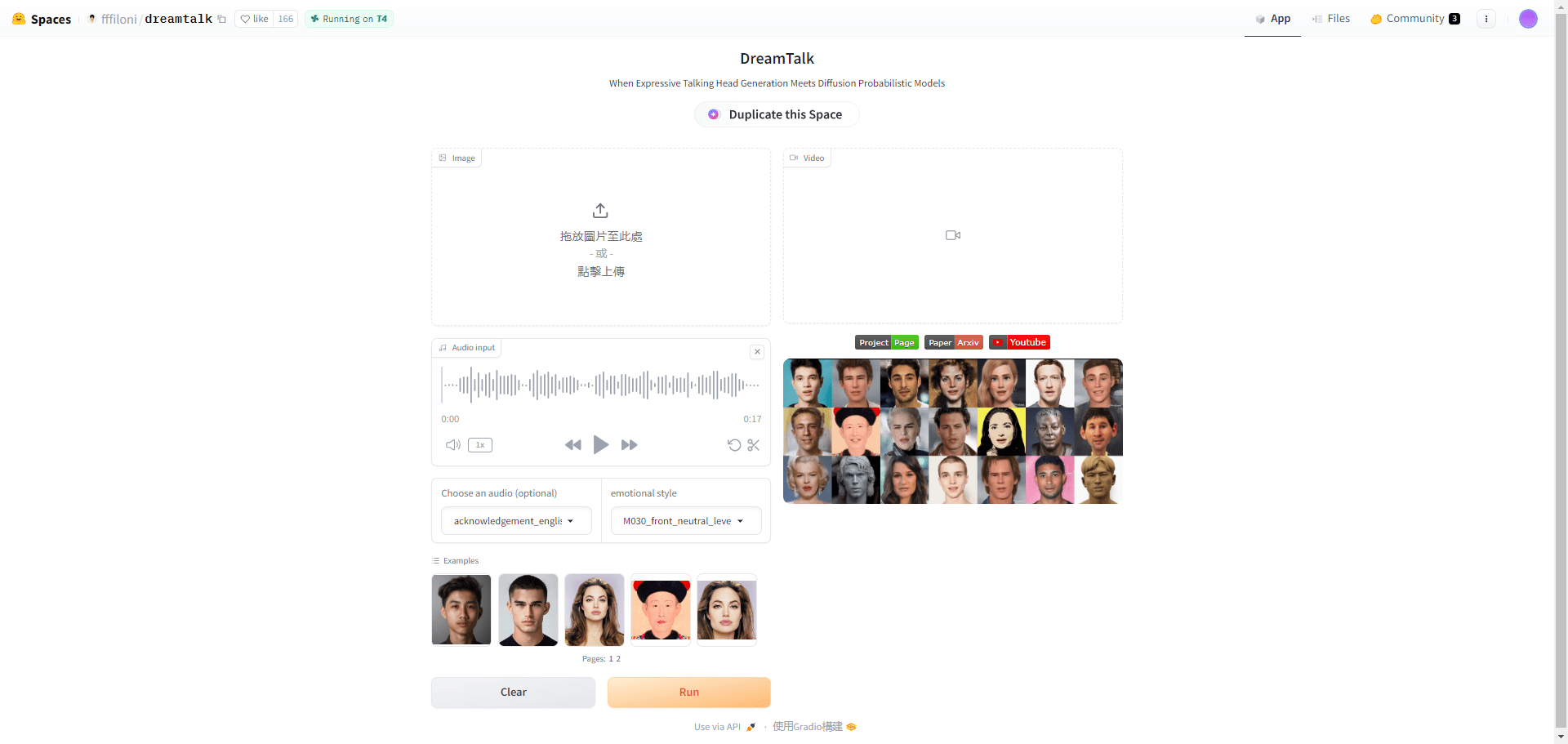
General Introduction LatentSync is an open source tool developed by ByteDance and hosted on GitHub. It drives the lip movements of characters in a video directly through audio, allowing the mouth shape to match the voice precisely. The project is based on Stable Di...