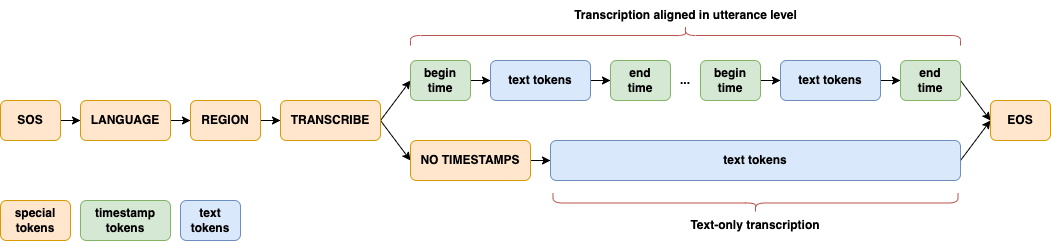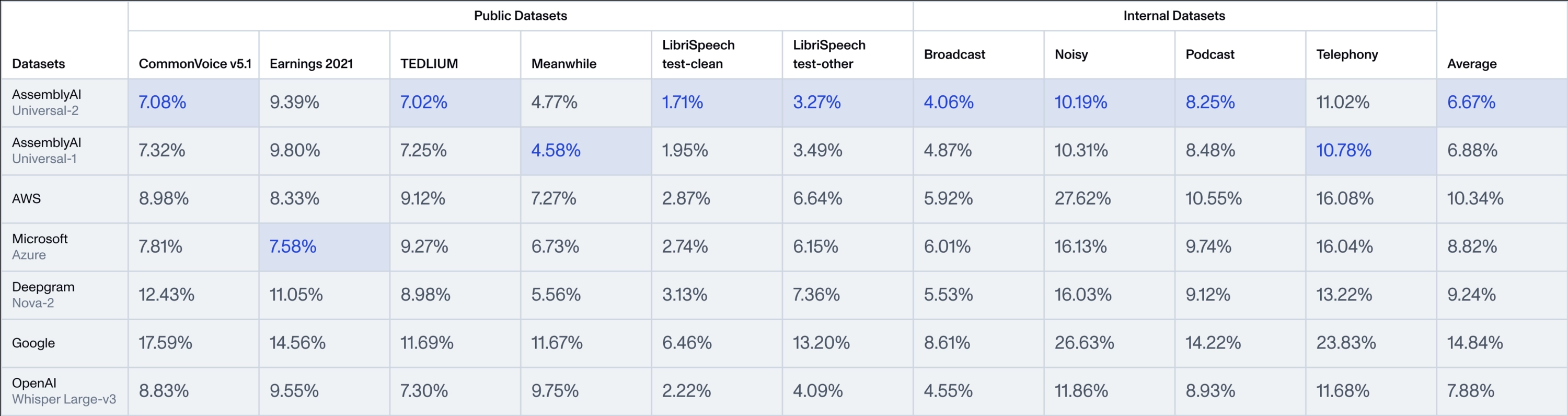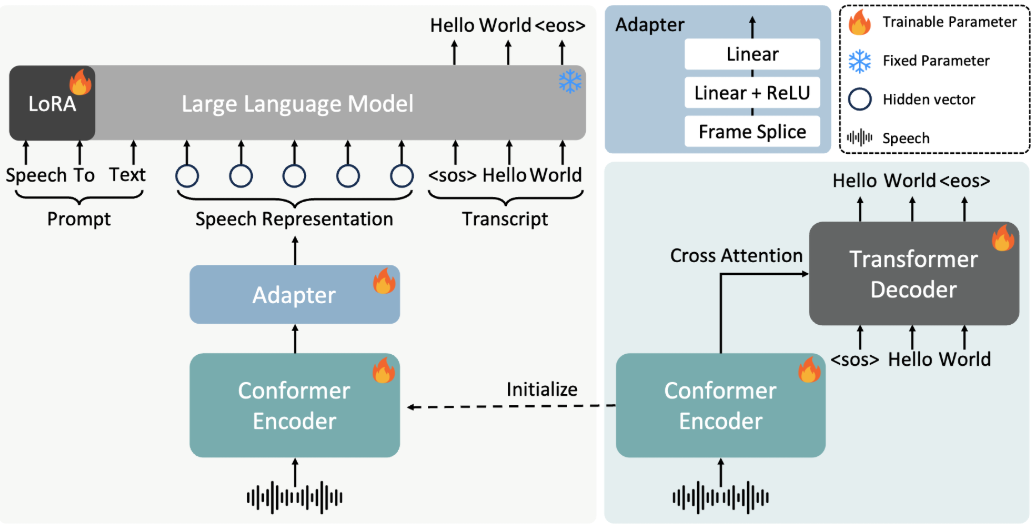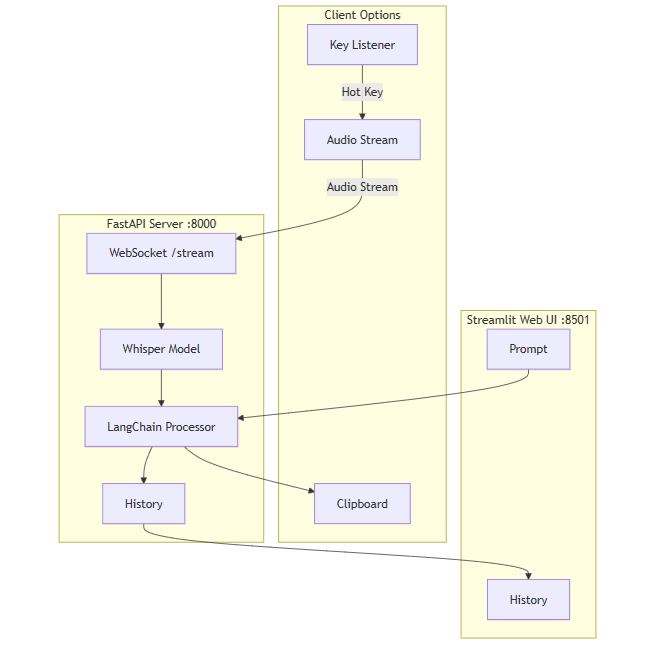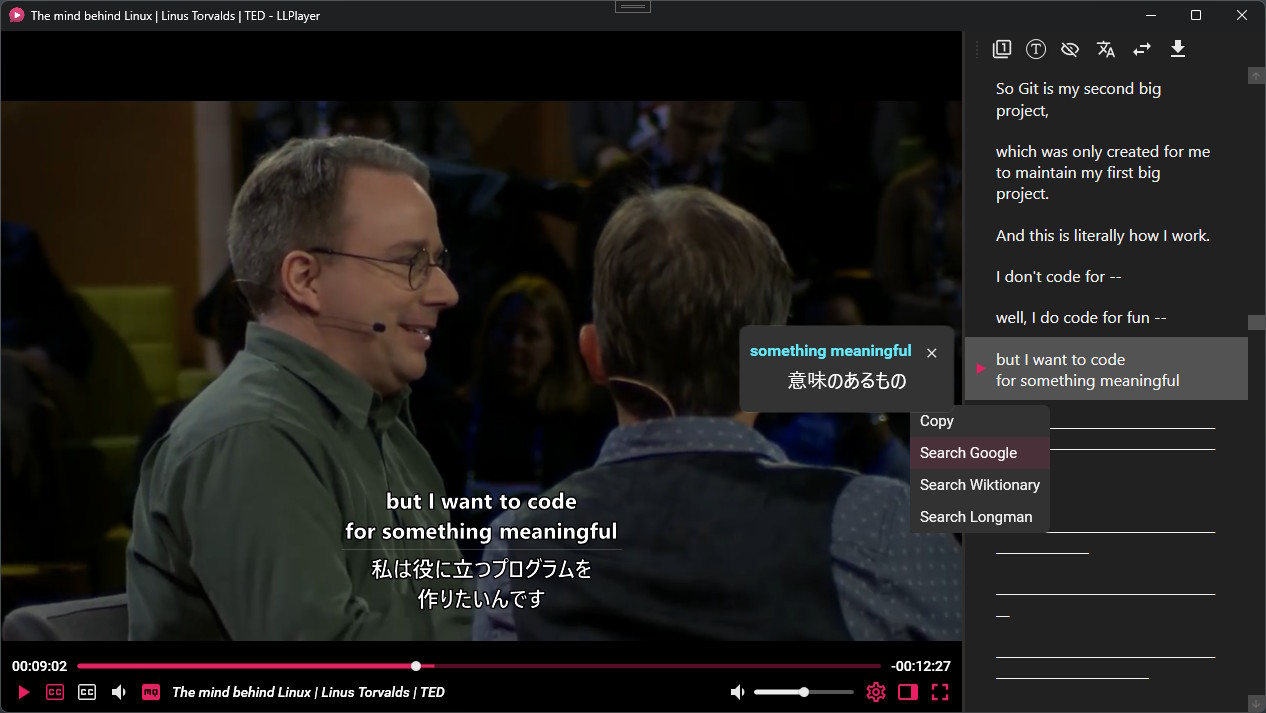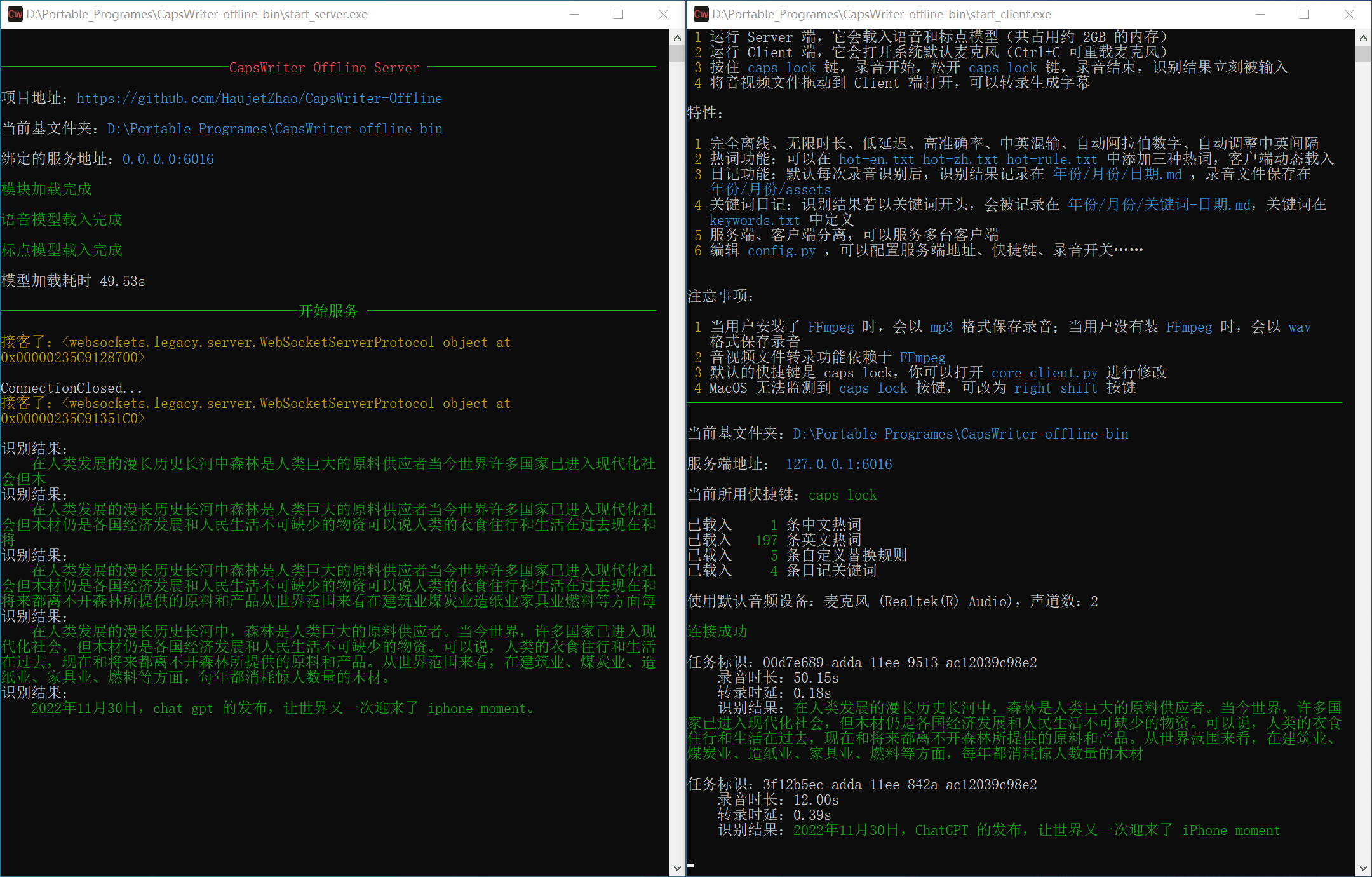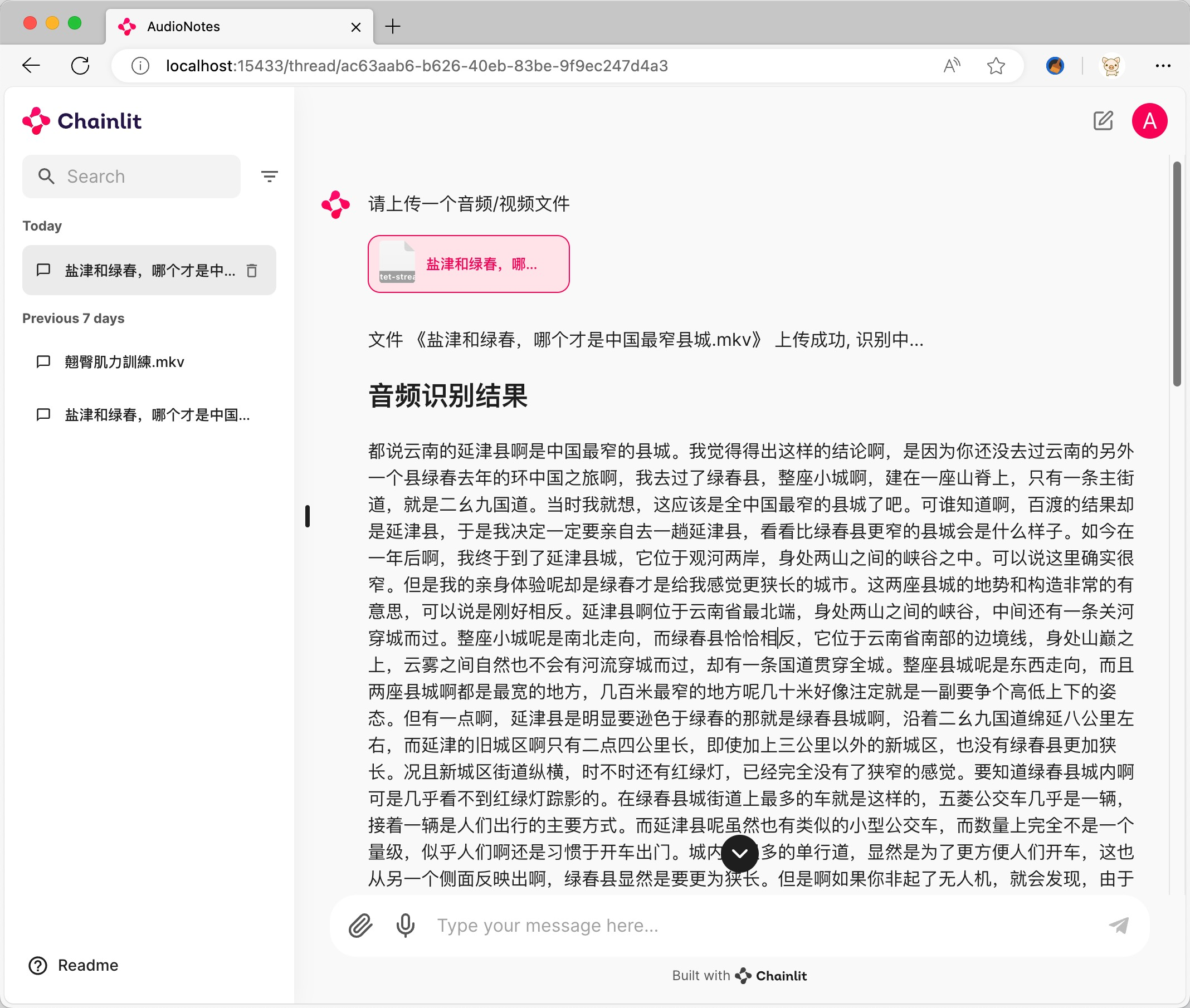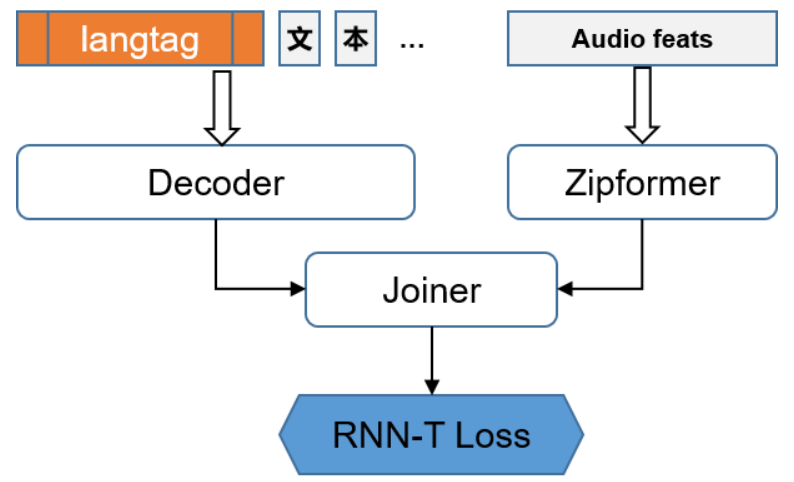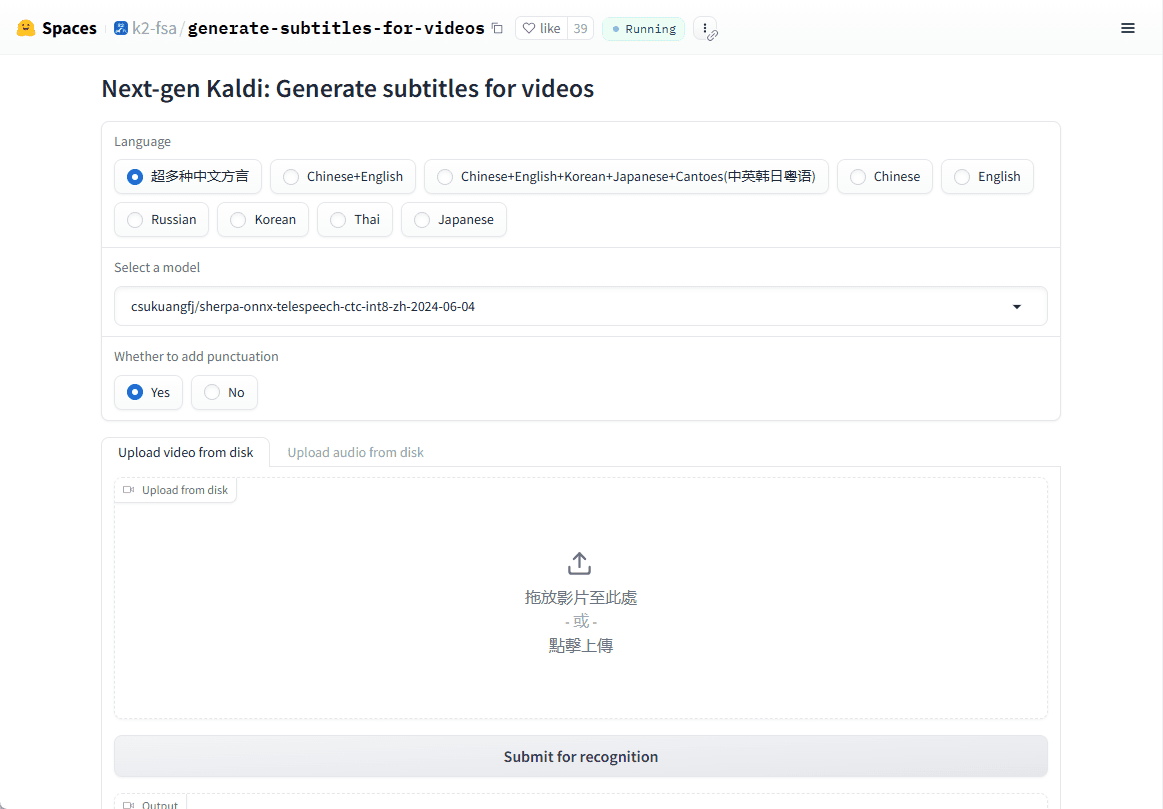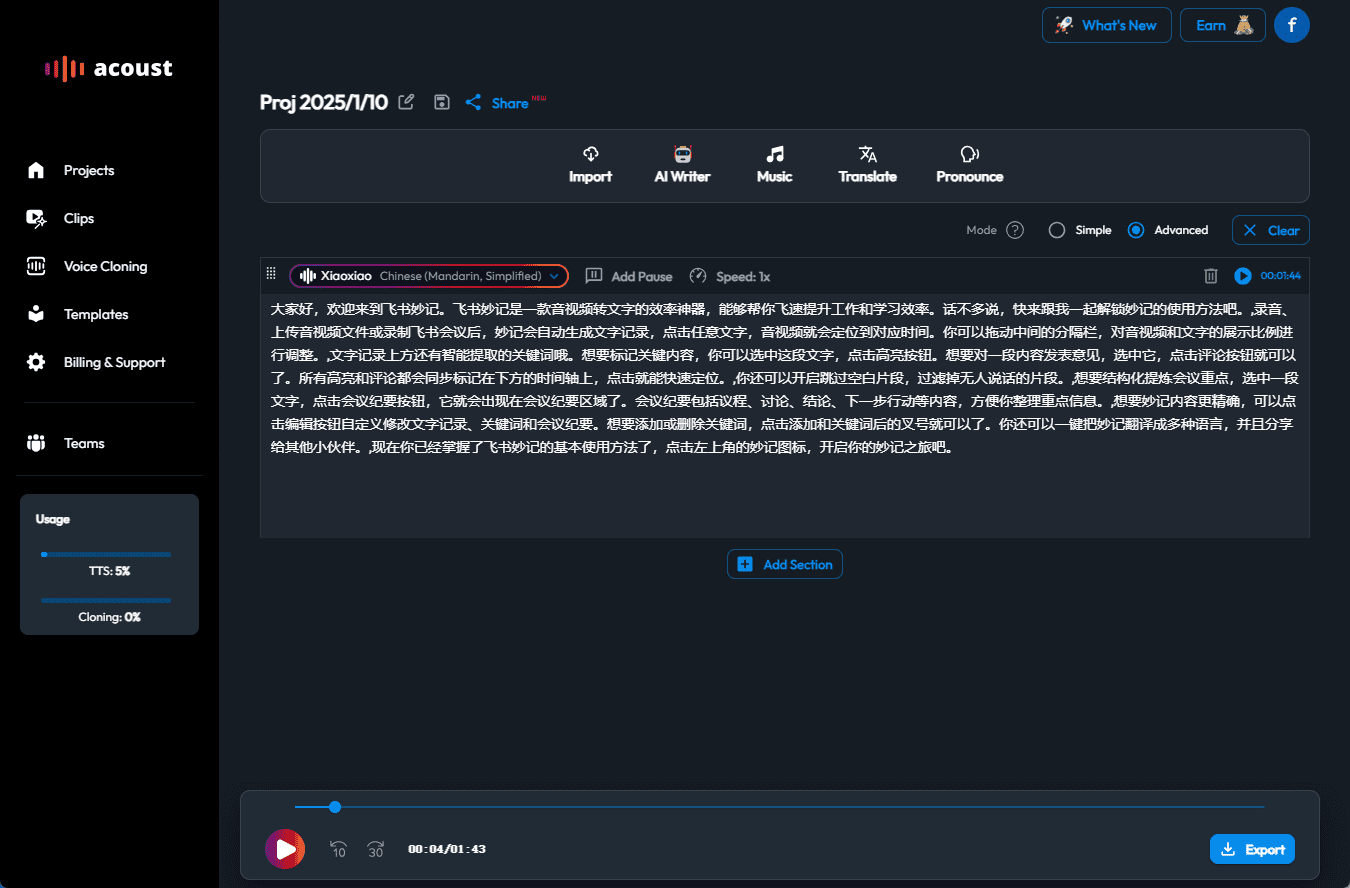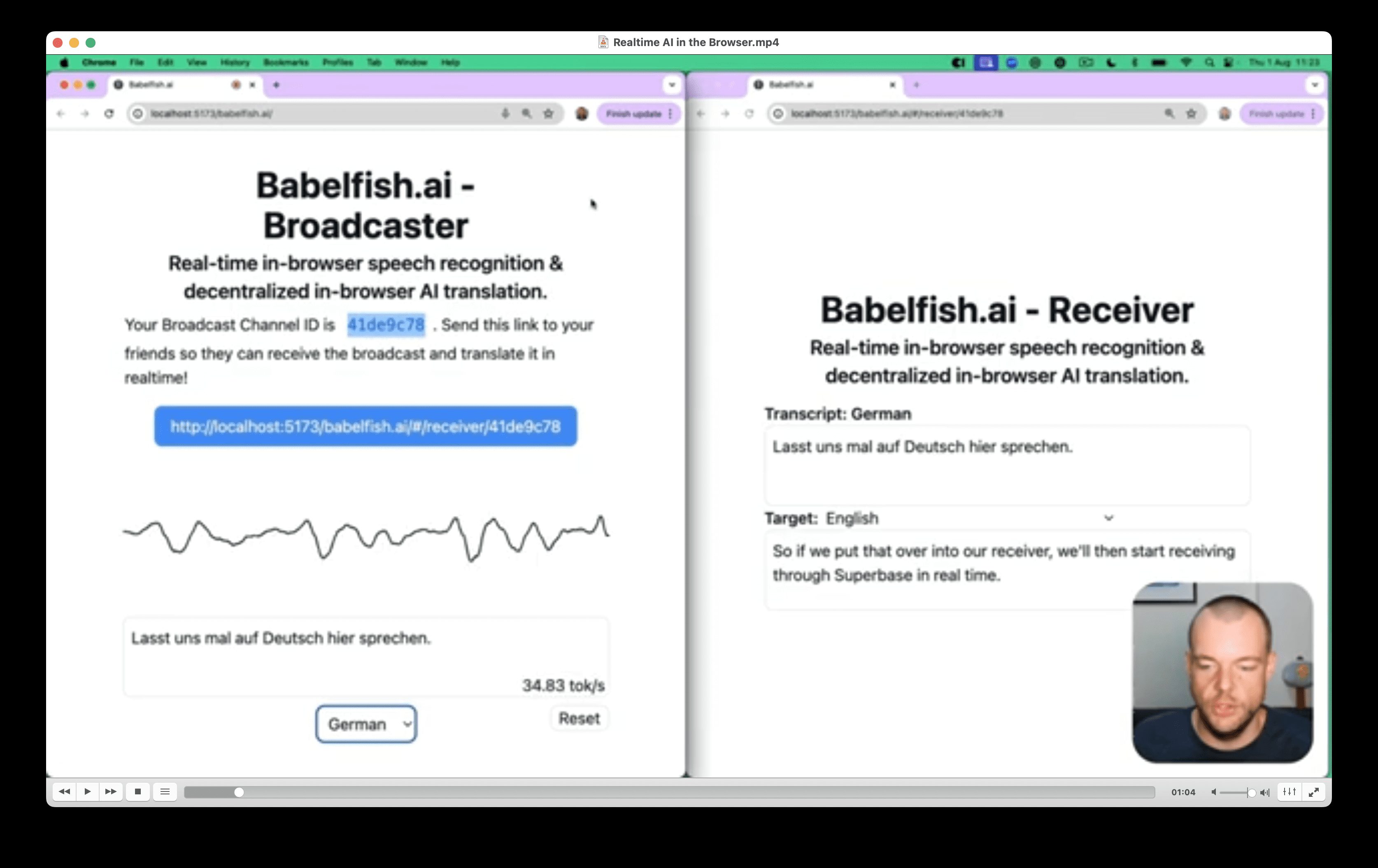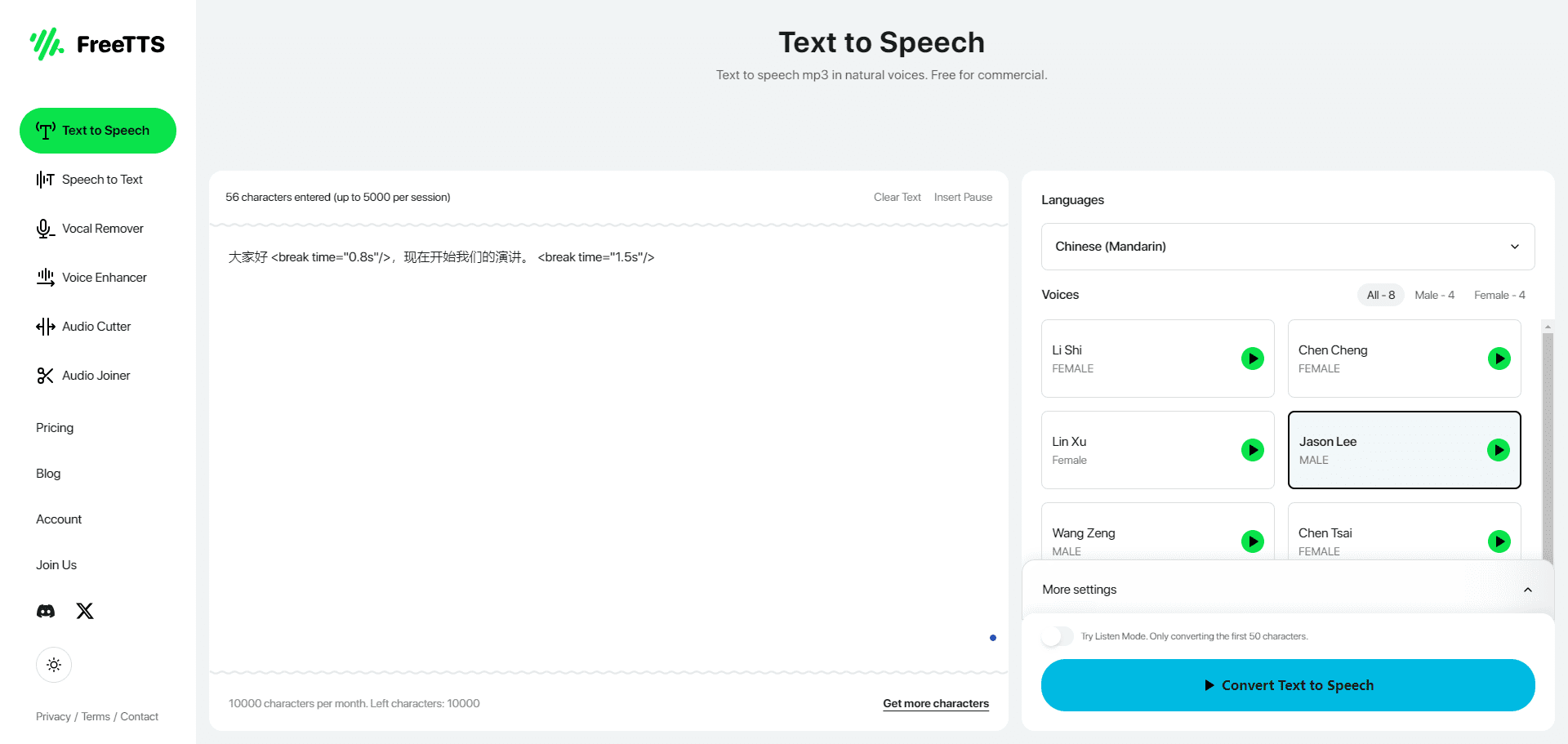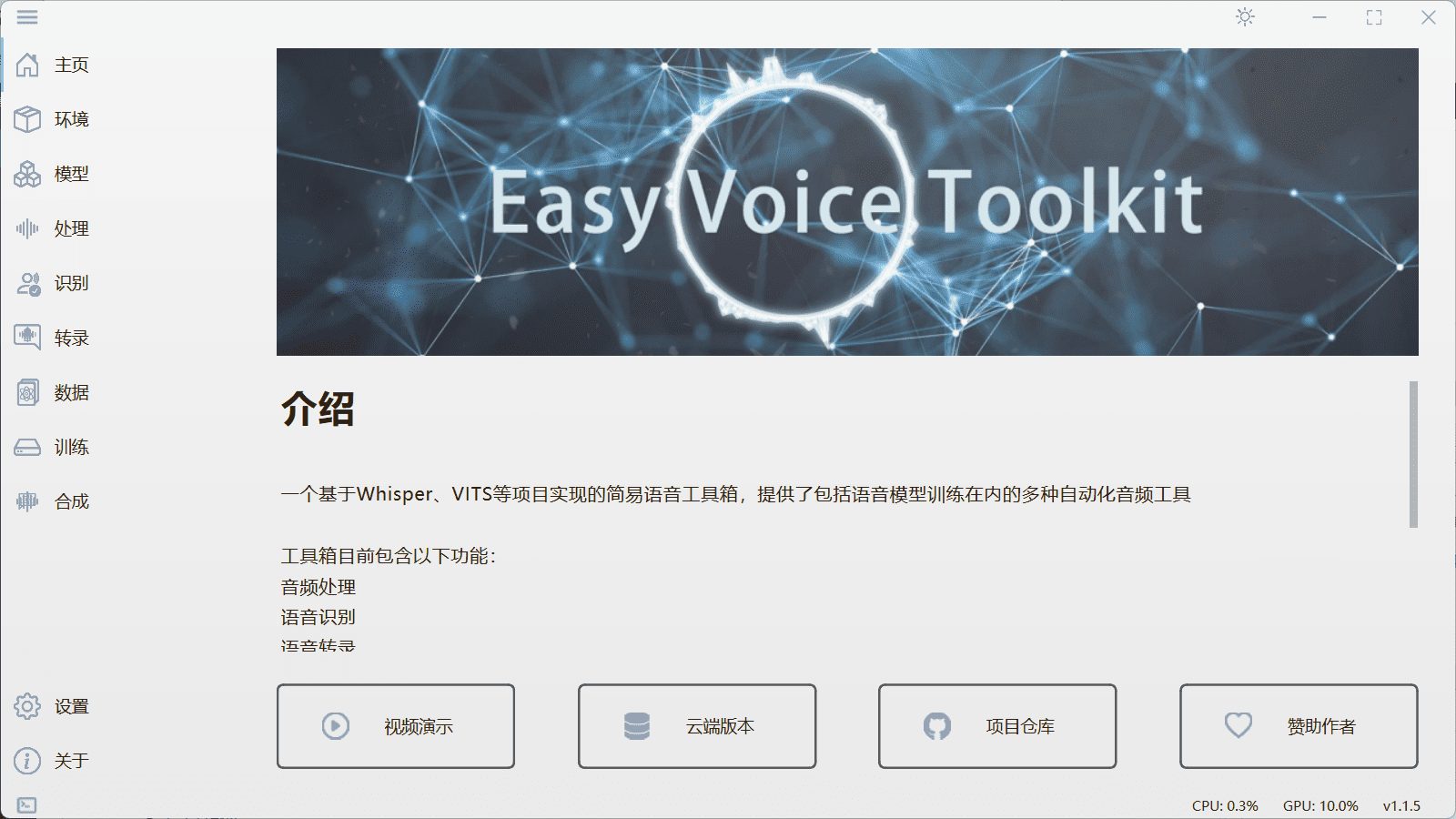
Abogen: a tool for converting multiple text formats to audiobooks
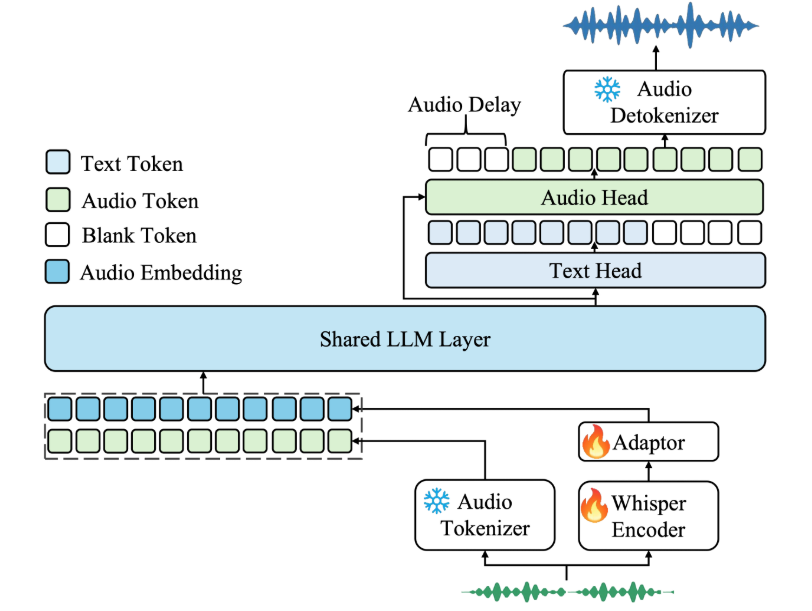
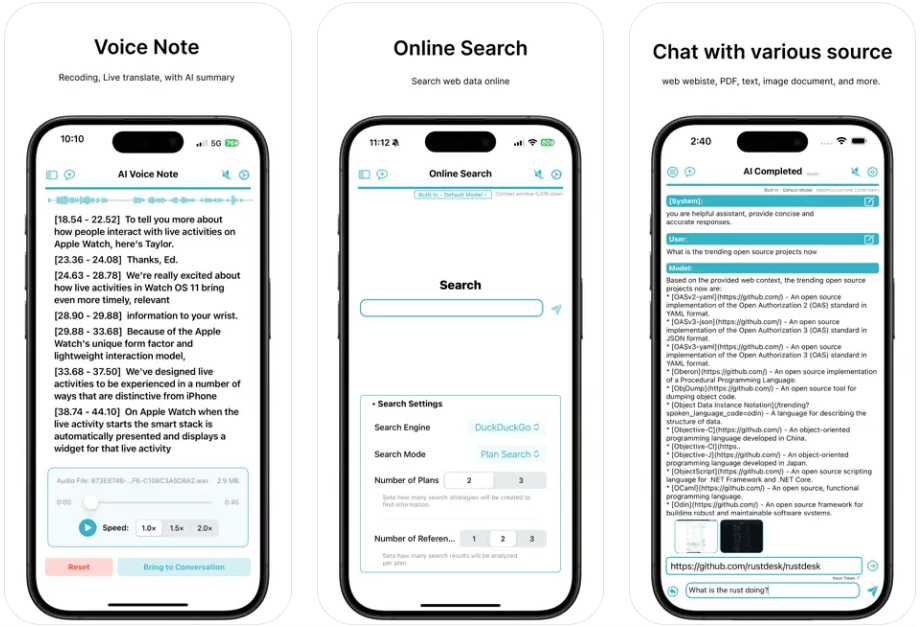
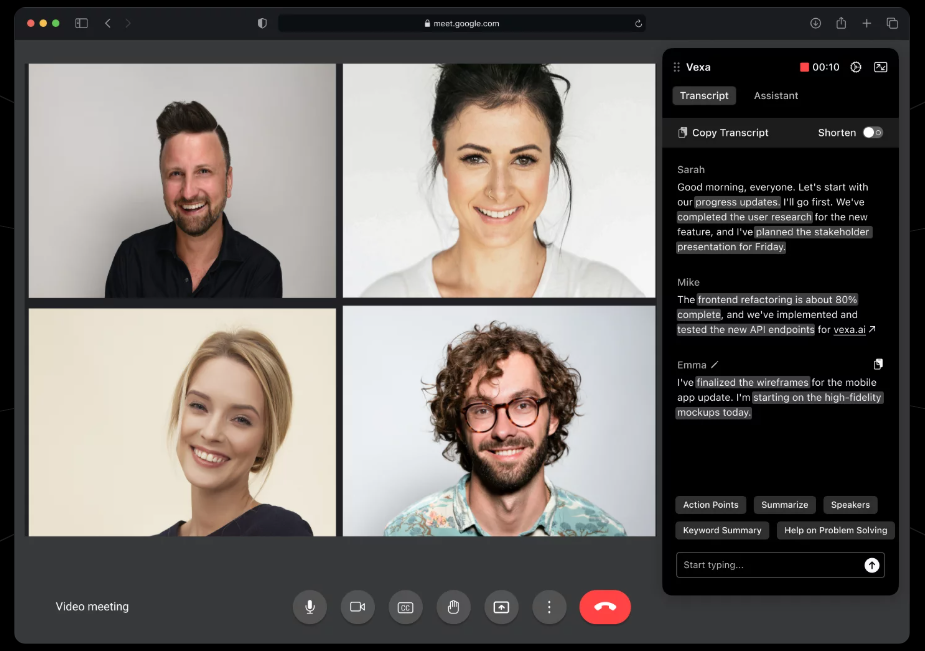
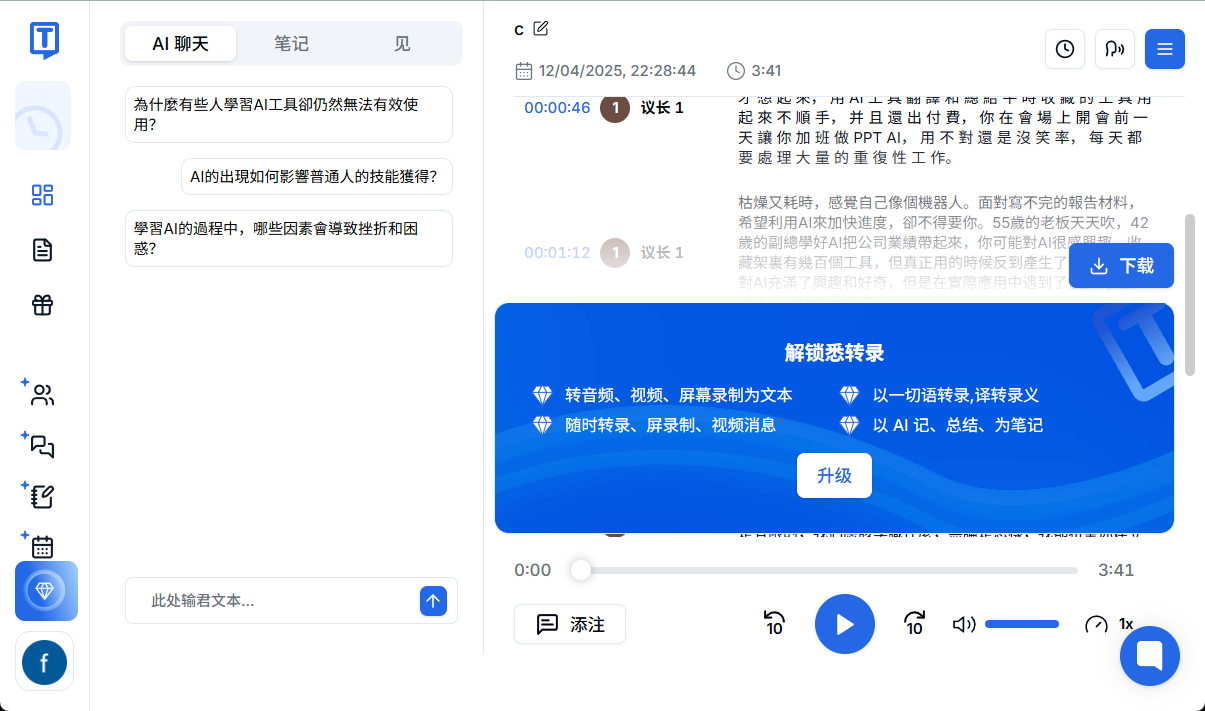
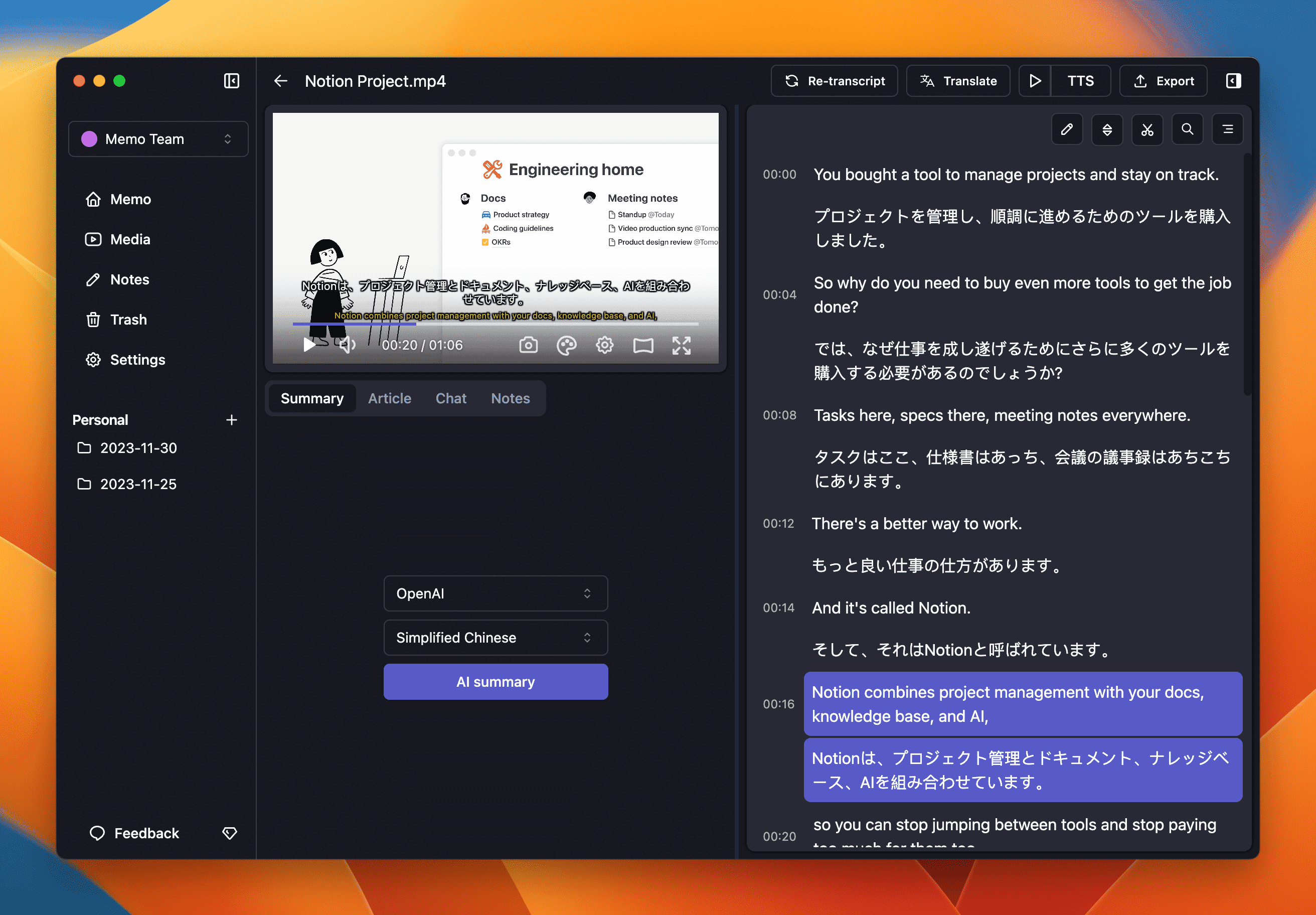
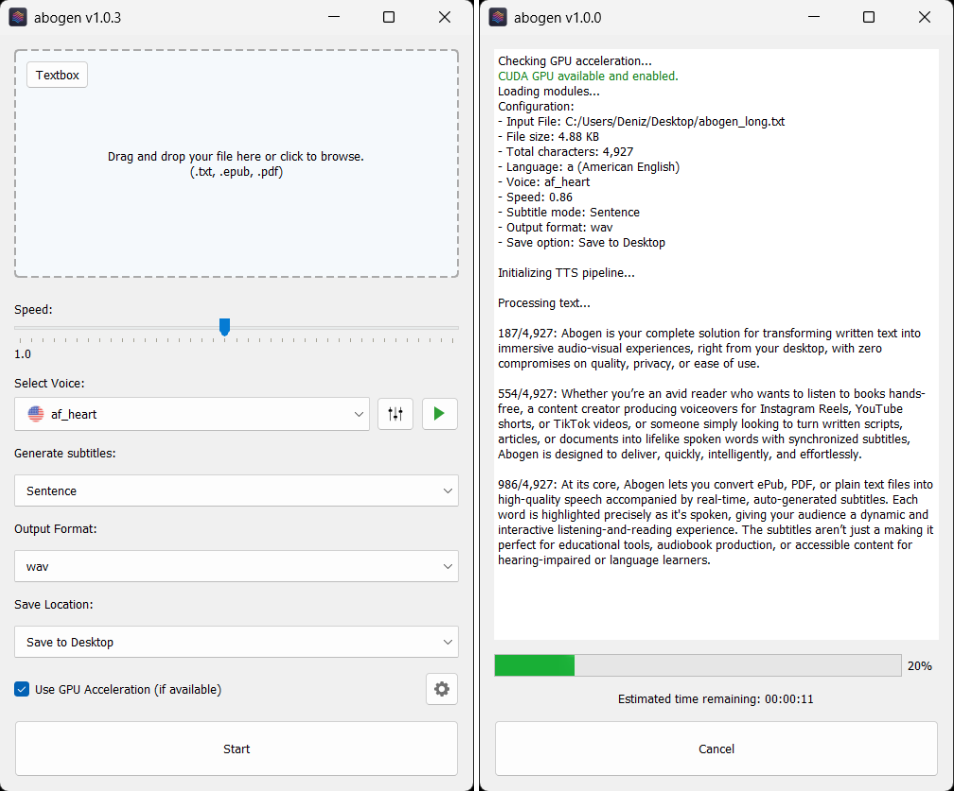
General Introduction Abogen is an open source tool designed to quickly convert ePub, PDF or plain text files to high quality audio. It uses the Kokoro-82M model to generate natural and smooth speech, and supports synchronized subtitle generation, which is suitable for producing audiobooks...