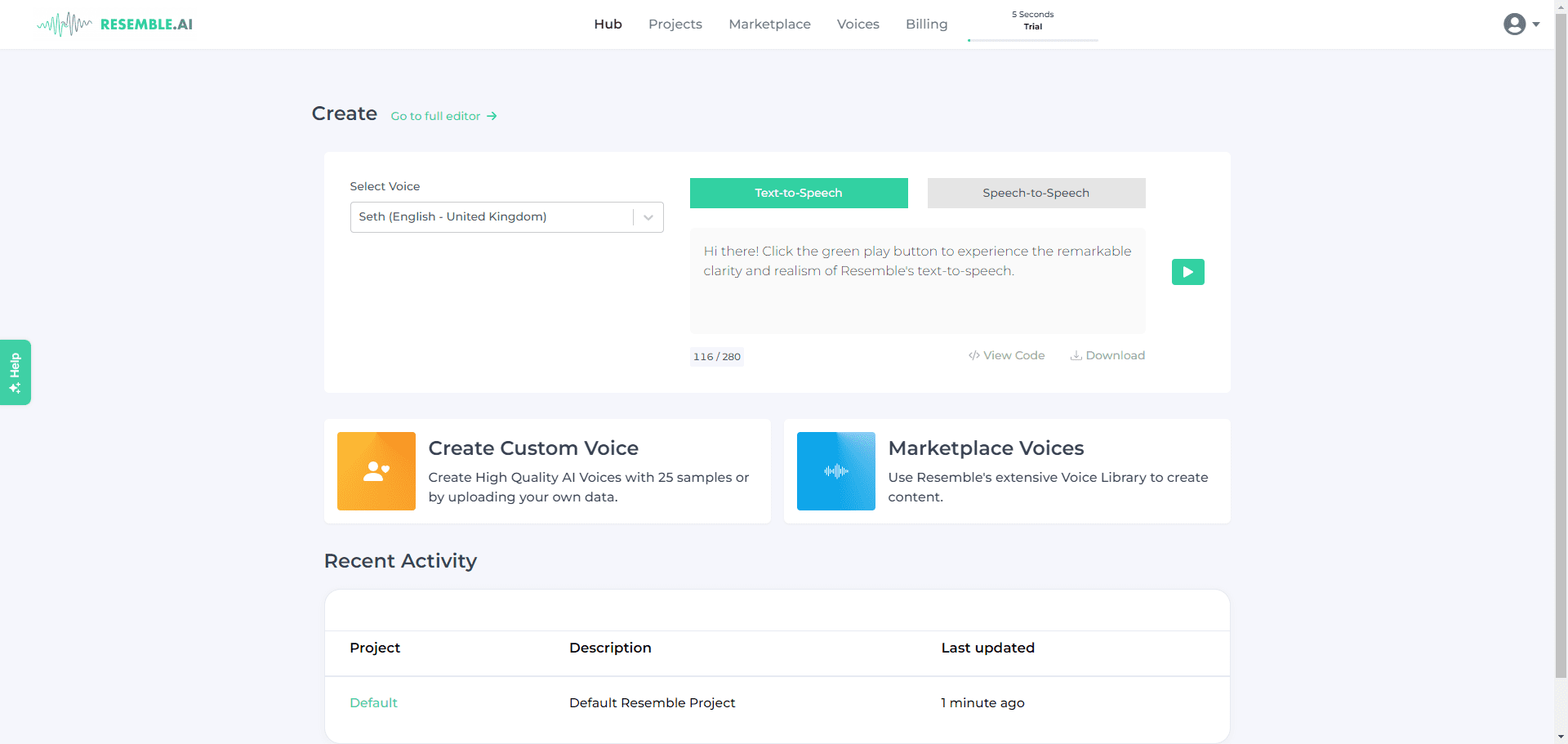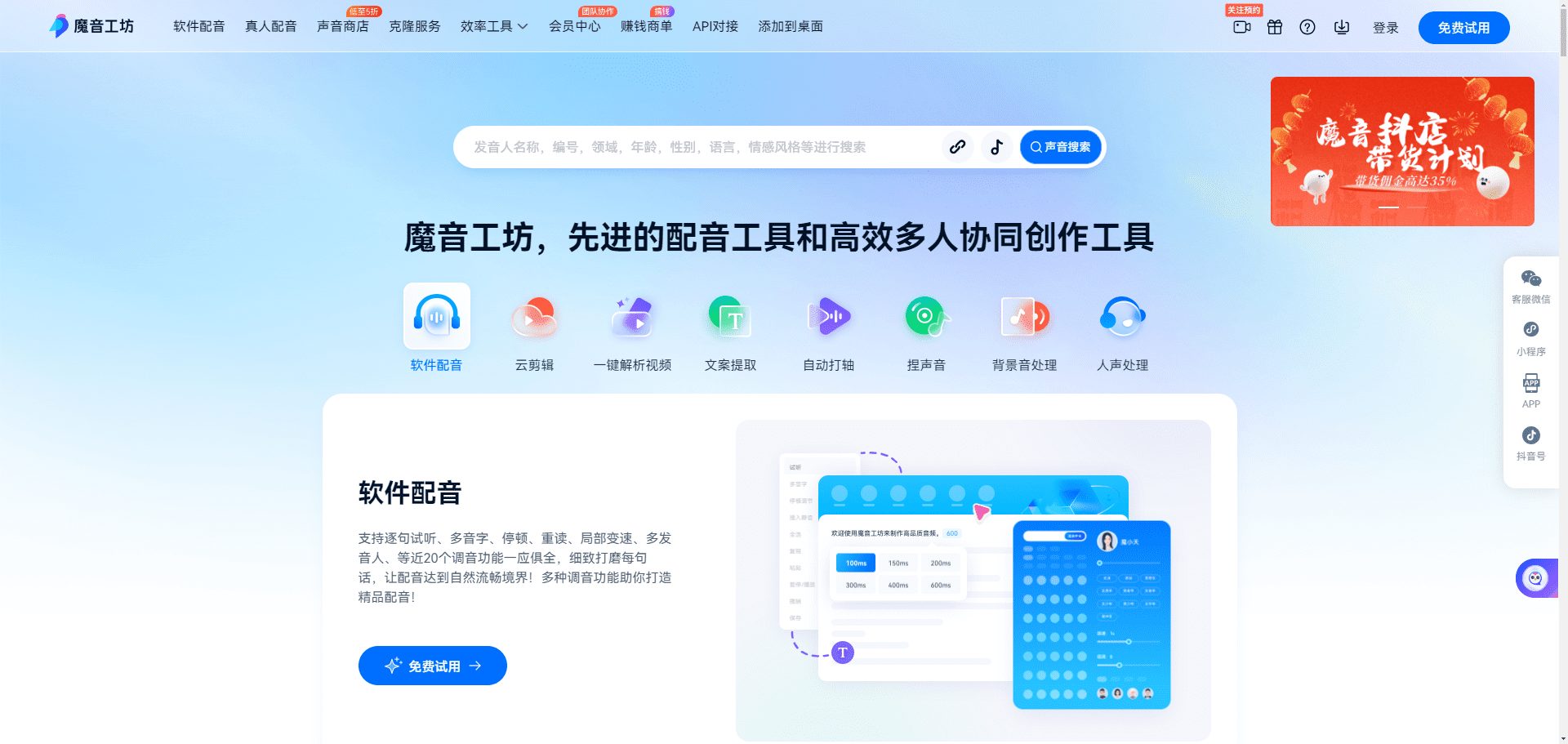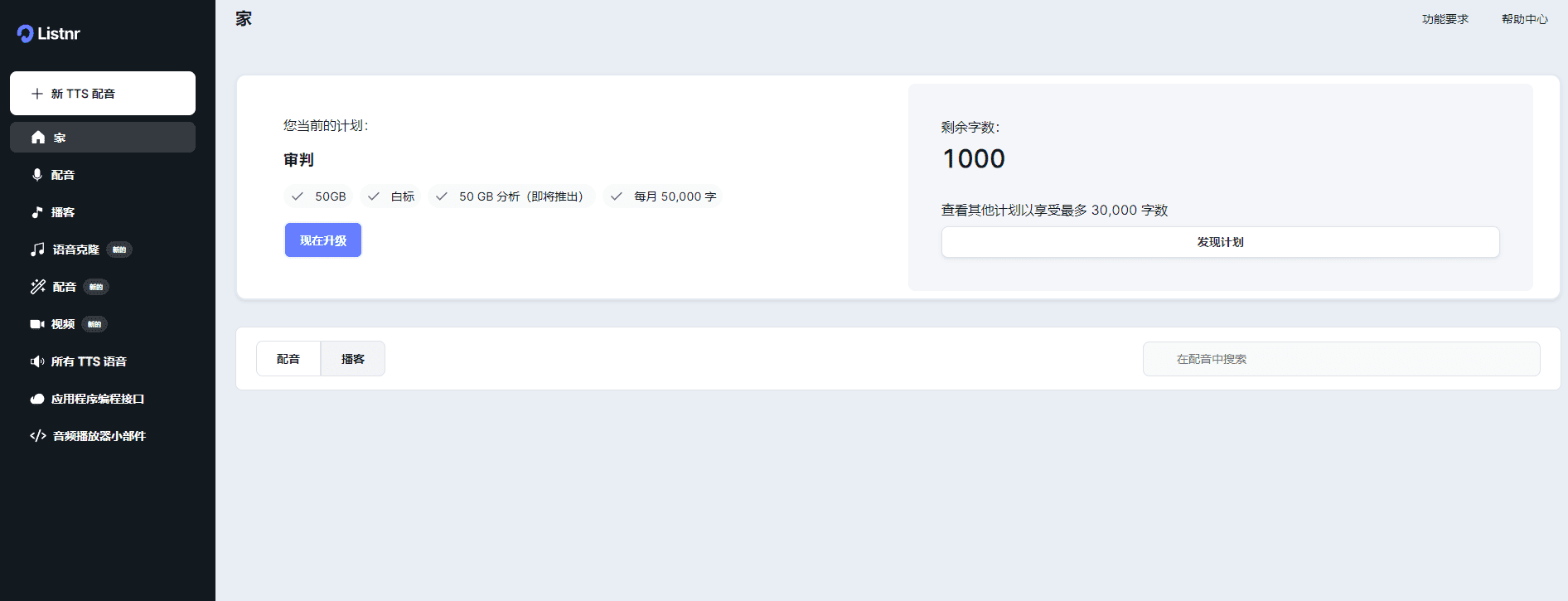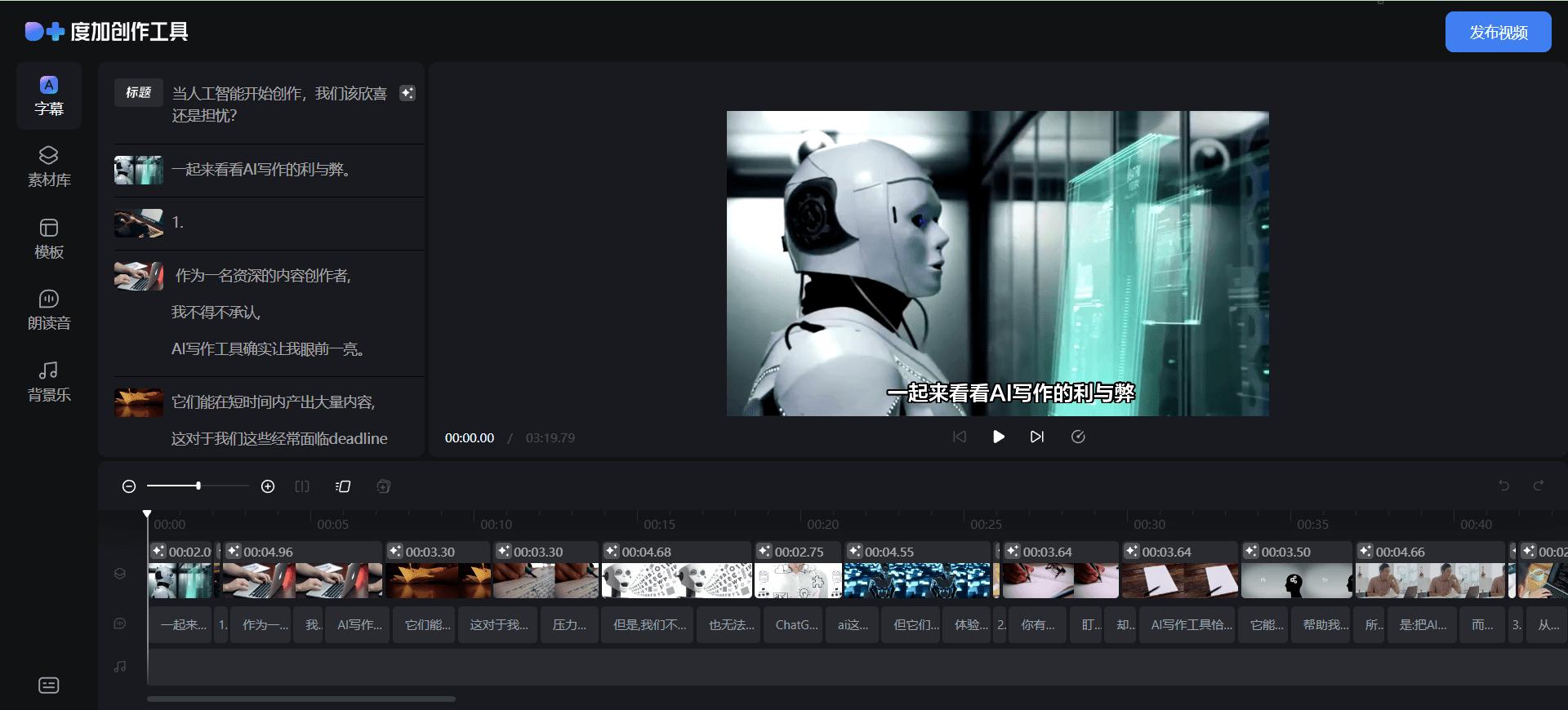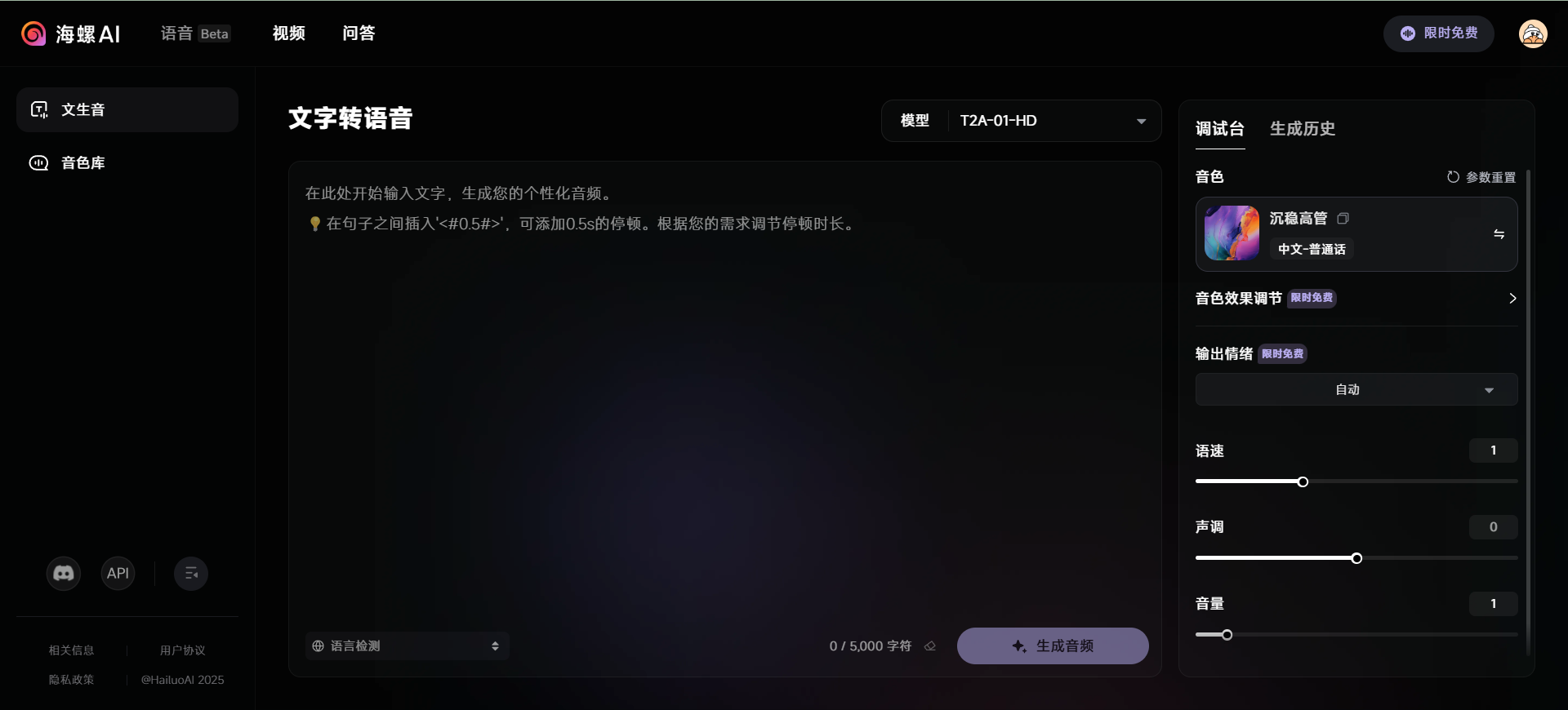
Conch Speech (MiniMax Audio): AI tool for generating natural speech
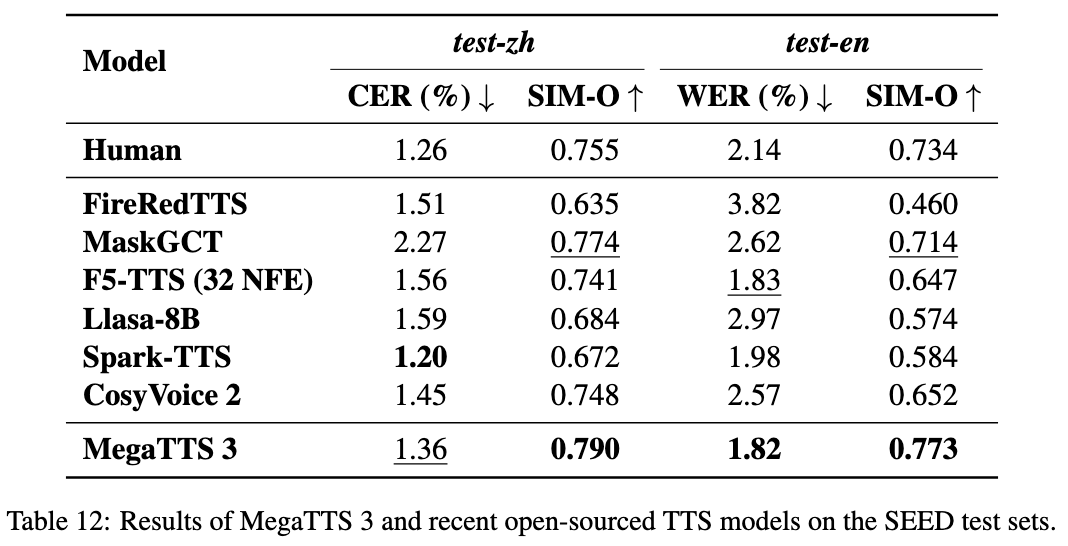
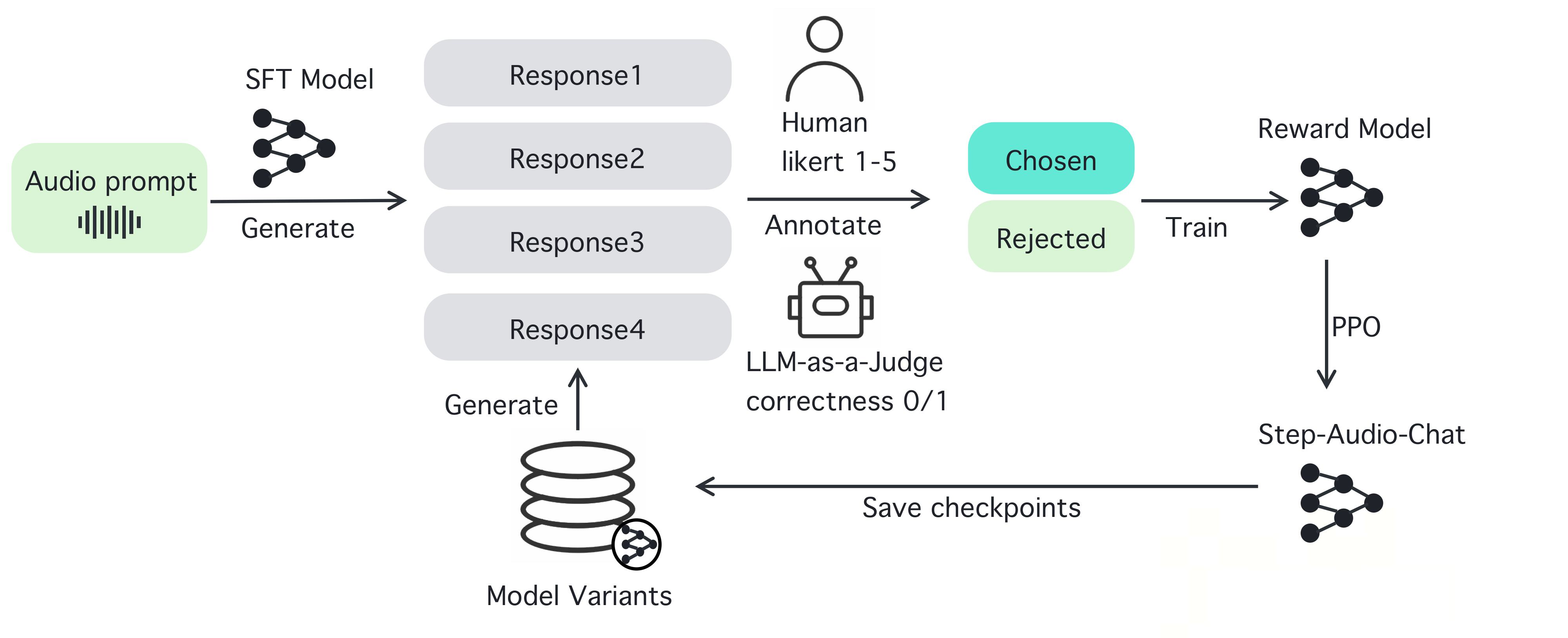
Comprehensive Introduction MiniMax Audio is an AI speech generation tool from MiniMax, the core feature of which is to quickly convert text to natural speech with high similarity. It is based on the Speech-02 model, with a speech synthesis similarity of up to 99...