
Step-Audio-AQAA - End-to-End Big Audio Language Model from StepFun

What is Step-Audio-AQAA?
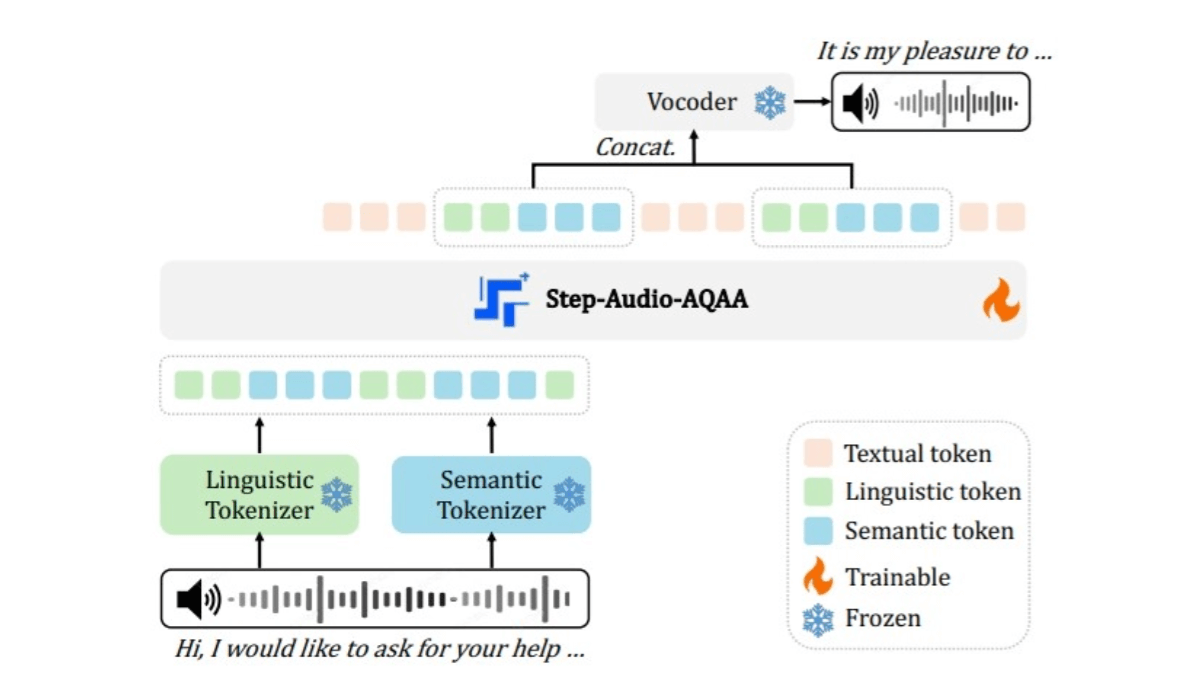
Step-Audio-AQAA is an end-to-end, large-scale audio language model for Audio Query-Audio Answer (AQAA) tasks from the StepFun team. The ability to process audio input directly to generate natural, accurate speech responses without relying on traditional Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) modules simplifies the system architecture and eliminates cascading errors.Step-Audio-AQAA's training process involves multimodal pre-training, Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and model merging. Through these methods, the model excels in complex tasks such as speech emotion control, role-playing, and logical reasoning. In the StepEval-Audio-360 benchmark, Step-Audio-AQAA outperforms existing LALM models on several key dimensions, demonstrating strong potential for end-to-end speech interaction.
Main features of Step-Audio-AQAA
- Direct processing of audio inputs: Generates voice responses directly from raw audio input without relying on traditional automatic speech recognition (ASR) and text-to-speech (TTS) modules.
- Seamless voice interaction: Supporting voice-to-speech interaction, users can ask questions with their voice and the model answers directly with their voice, enhancing the naturalness and smoothness of the interaction.
- Emotional tone adjustment: Support for adjusting the emotional intonation of speech at the sentence level, for example to express emotions such as happiness, sadness or seriousness.
- speech control: The user can adjust the speed of the voice response as needed to make it more responsive to the needs of the scenario.
- Tone and pitch control: It can adjust the tone and pitch of the voice according to user commands, adapting to different roles or scenarios.
- multilingual interaction: Support Chinese, English, Japanese and other languages to meet the language needs of different users.
- Dialect Support: Covering Chinese dialects such as Sichuan and Cantonese to enhance the applicability of the model in specific regions.
- voice-activated emotion control: Can generate voice responses with specific emotions based on context and user commands.
- role-playing (as a game of chess): Supports playing specific roles in a conversation, such as customer service, teacher, friend, etc., and generating voice responses that match the characteristics of the role.
- Logical reasoning and knowledge quizzes: Can handle complex logical reasoning tasks and knowledge quizzes, generating accurate voice responses.
- High quality voice output: Generate high-fidelity, natural and smooth speech waveforms via neural vocoder to enhance user experience.
- phonetic coherence: Maintain coherence and consistency of speech in long sentence or paragraph production, avoiding speech breaks or abrupt changes.
- Interleaved text and speech output: Supports interleaved text and voice output, allowing users to select voice or text responses as needed.
- Multimodal Input Understanding: Can understand mixed inputs containing speech and text, generating appropriate speech responses.
Step-Audio-AQAA's project address
- HuggingFace Model Library:: https://huggingface.co/stepfun-ai/Step-Audio-AQAA
- arXiv Technical Paper:: https://arxiv.org/pdf/2506.08967
Technical Principles of Step-Audio-AQAA
- Dual Codebook Audio Splitter: Converts the input audio signal into a structured sequence of tokens. It contains two lexicons: a linguistic lexicon extracts phonemes and linguistic attributes of speech, sampled at 16.7 Hz with a codebook size of 1024; and a semantic lexicon captures acoustic features of speech, such as emotion and intonation, sampled at 25 Hz with a codebook size of 4096, which is able to better capture the complex information in speech.
- Backbone LLM: Using a pre-trained 130 billion parameter multimodal LLM (Step-Omni), the pre-trained data covers three modalities: text, speech and image. Embedding the bicode text audio tokens into a unified vector space by multiple Transformer blocks for deep semantic understanding and feature extraction.
- neural vocoder: Synthesizes the generated audio tokens into natural, high-quality speech waveforms. The U-Net architecture, combined with the ResNet-1D layer and the Transformer block, efficiently converts discrete audio tokens into continuous speech waveforms.
Step-Audio-AQAA's Core Benefits
- End-to-end audio interaction: Step-Audio-AQAA generates natural and smooth voice responses directly from the raw audio input, eliminating the need to rely on traditional Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) modules. The end-to-end design avoids the distortion of results caused by errors in ASR or TTS in traditional solutions.
- Multi-language support: The model supports multiple languages, including Chinese (including Sichuanese and Cantonese), English, Japanese, etc., which can meet the language needs of different users.
- Fine-grained voice feature control: Step-Audio-AQAA enables fine-grained voice feature control, such as emotional intonation, speech rate, etc., to generate more responsive voice responses. It performs particularly well in voice emotion control.
Who is Step-Audio-AQAA for?
- Intelligent voice assistant users: Users who wish to use voice interaction devices (e.g., smart speakers, smart assistants) for daily operations (e.g., checking information, setting reminders, playing music, etc.).
- gaming enthusiast: Gamers who like to interact with in-game NPCs for a more immersive gaming experience.
- Educational Users: Students and parents, who want to learn through voice interaction (e.g., language learning, knowledge quizzes, etc.).
- Older persons and children: Voice interaction is more convenient and natural for users who are not good at using text input.
- audiobook creator: Creators who need to generate high-quality voice content, such as audiobooks, radio plays, etc.
- video producer: Creators who need voice interaction or voice generation capabilities when producing video content (e.g., short videos, live streams).
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles


No comments...