ScrapeGraphAI: A single cue word for web crawling, no need to write rules intelligent web content extraction tools

General Introduction
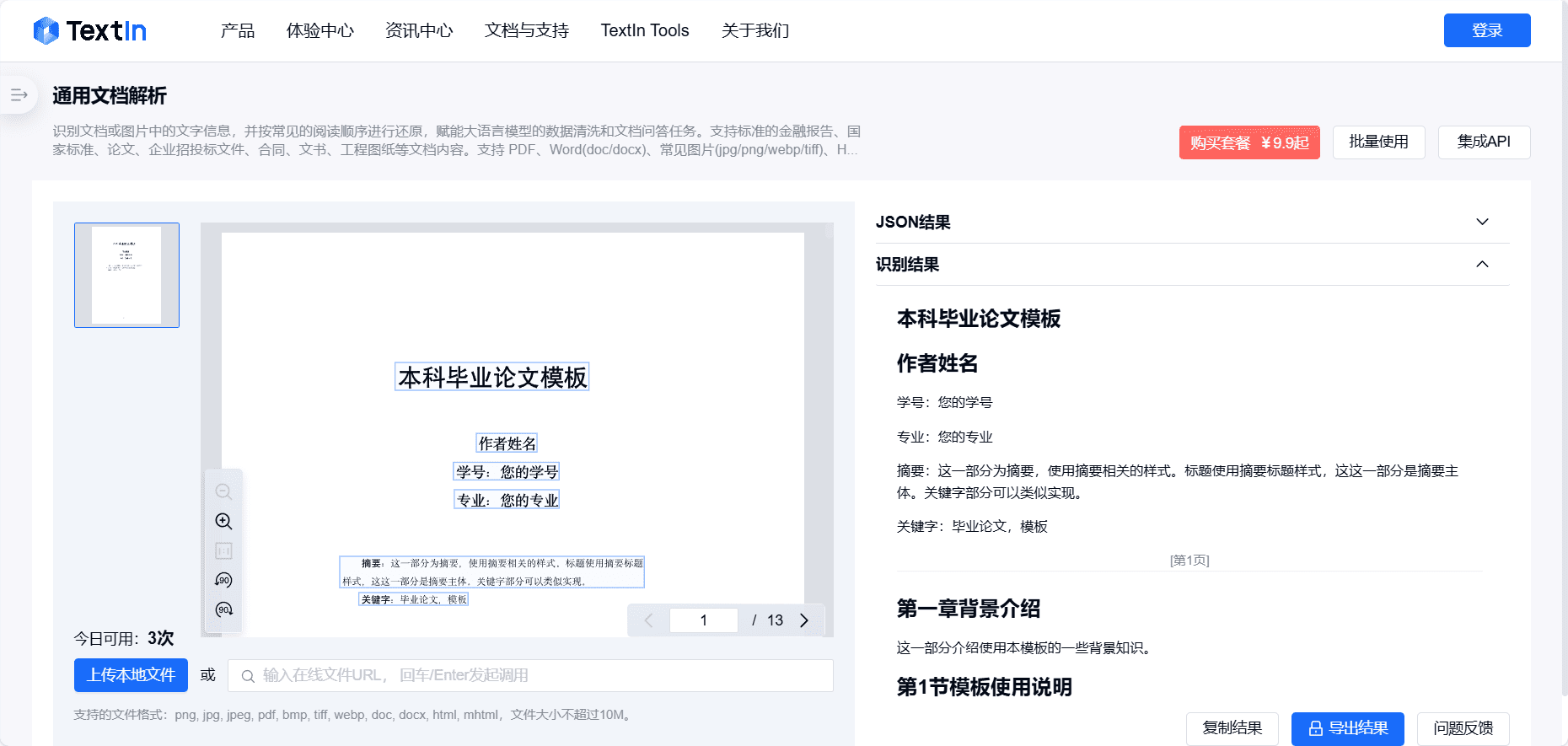
ScrapeGraphAI is an innovative Python web crawling library that cleverly combines Large Language Modeling (LLM) and Direct Graph Logic to create crawling pipelines for websites and local documents. The uniqueness of this tool lies in its perfect balance of simplicity and power: the user simply describes the information he/she wants to extract, and ScrapeGraphAI automates all the complexity of the crawling process. The program supports processing documents in multiple formats, including XML, HTML, JSON and Markdown. By providing SDKs for Python and Node.js, it enables developers to easily integrate web crawling functionality into their projects.ScrapeGraphAI is more than just a simple web crawling tool, it also provides rich functionality such as parallel crawling of multiple pages, speech generation, automatic generation of Python scripts and other advanced features.

Graph logic is a core technical concept in ScrapeGraphAI, which refers to a structured processing method for web data extraction. Specifically:
- Data structure representation:
- Think of web content as a graphical structure
- The HTML document is converted into a collection of nodes and edges.
- Each HTML element is a node, and the relationships between elements are represented by edges
- Processing Flow:
- First build the DOM tree structure of the page
- Analyze the hierarchical and associative relationships between nodes
- Using AI (Big Language Modeling) to Understand User Needs
- Finding the optimal data extraction path based on the graph structure
Function List
- Intelligent single-page crawling: content extraction can be accomplished with just a user prompt and an input source
- Multi-page parallel crawling: support extracting information from multiple web pages at the same time
- Search engine results crawling: can extract information from the first N results of search engines
- Voice conversion function: can convert web content to audio files
- Automatic script generation: Python scripts for content extraction can be generated
- Multiple LLM support: compatible with OpenAI, Groq, Azure, Gemini and other APIs and native Ollama models
- Advanced semantic processing: support for semantic processing tools such as Graphviz
- Browser management: integrated with a variety of browser management tools and services
- API integration support: provide complete API interface and SDK support
Using Help
1. Installation steps
- Foundation Installation
pip install scrapegraphai
playwright install
It is recommended to install in a virtual environment to avoid library conflicts.
- Optional dependency installation
- Install more language model support:
pip install scrapegraphai[other-language-models]
- Installation of semantic processing options:
pip install scrapegraphai[more-semantic-options]
- Install the browser option:
pip install scrapegraphai[more-browser-options]
2. Basic usage
Below is an example of using SmartScraperGraph (the most commonly used scraping pipeline):
import json
from scrapegraphai.graphs import SmartScraperGraph
# 配置抓取管道
graph_config = {
"llm": {
"api_key": "YOUR_OPENAI_APIKEY",
"model": "openai/gpt-4o-mini",
},
"verbose": True,
"headless": False,
}
# 创建SmartScraperGraph实例
smart_scraper_graph = SmartScraperGraph(
prompt="Extract me all the news from the website",
source="https://www.wired.com",
config=graph_config
)
# 运行管道
result = smart_scraper_graph.run()
print(json.dumps(result, indent=4))
3. Description of the use of advanced functions
- multi-page crawling
- Use SmartScraperMultiGraph to extract information from multiple pages at the same time.
- Supports parallel LLM calls to improve processing efficiency
- Search Result Crawl
- Use SearchGraph to extract information directly from search engine results.
- Supports setting the number of extraction results
- phonetic transcription
- Use SpeechGraph to convert web content to audio files.
- Supports multiple speech synthesis options
- Automatic Script Generation
- ScriptCreatorGraph generates Python scripts for content extraction.
- Support for single-page and multi-page script generation
- LLM Integration
- Support for multiple LLM services: OpenAI, Groq, Azure, Gemini
- Support for native Ollama models (you need to install Ollama and download the model first)
4. Cautions
- Ensure that the API key is properly configured before use
- Recommended to run in a virtual environment to avoid dependency conflicts
- When using local models, it is necessary to install and download the corresponding models in advance.
- Comply with the site's terms of use and crawl policy
- Pay attention to control the frequency of crawling to avoid pressure on the target site
5. Troubleshooting
- If you encounter a dependency conflict, it is recommended to recreate the virtual environment
- Checking key configuration when API calls fail
- Checking network connectivity and target site availability when a page crawl fails
6. Access to help
- Official Documentation: https://scrapegraph-ai.readthedocs.io/
- Docusaurus documentation: https://docs-oss.scrapegraphai.com/
- Discord Community Support: https://discord.gg/uJN7TYcpNa
- GitHub Issue Tracker: https://github.com/ScrapeGraphAI/Scrapegraph-ai/issues
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...