R1-Onevision: an open source visual language model supporting multimodal reasoning

General Introduction
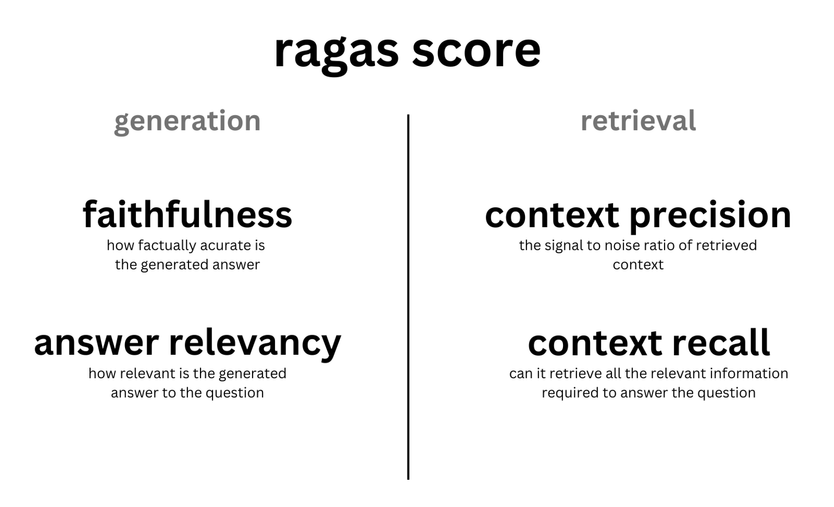
R1-Onevision is an open source multimodal large language model developed by Fancy-MLLM team, focusing on the deep combination of vision and language, capable of processing multimodal inputs such as images and text, and excelling in the fields of visual reasoning, image understanding, and mathematical problem solving. Based on Qwen2.5-VL model optimization, R1-Onevision outperforms comparable models such as Qwen2.5-VL-7B in several benchmarks and even challenges the capabilities of GPT-4V. The project is hosted on GitHub, providing model weights, datasets, and code suitable for developers, researchers for academic exploration or practical applications.Since its release on February 24, 2025, it has received widespread attention, and has especially performed well in visual reasoning tasks.

Function List
- multimodal inference: Supports complex reasoning tasks that combine images and text, such as math problem solving and scientific problem analysis.
- graphic understanding: The ability to analyze image content and generate detailed descriptions or answer related questions.
- Dataset Support: Provides R1-Onevision datasets containing multi-domain data such as natural scenes, OCR, charts, etc.
- model training: Supports full-model supervised fine-tuning (SFT) using the open-source LLama-Factory framework.
- High Performance Evaluation: Demonstrate superior reasoning skills to your peers on tests such as Mathvision, Mathverse, and others.
- open source resource: Provide model weights and code to facilitate secondary development or research.
Using Help
Installation process
R1-Onevision is a GitHub-based open source project that requires a certain programming foundation and environment configuration to run. The following is a detailed installation and usage guide:
1. Environmental preparation
- operating system: Linux (e.g. Ubuntu) or Windows (with WSL) is recommended.
- hardware requirement: An NVIDIA GPU (at least 16GB of video memory, such as the A100 or RTX 3090) is recommended to support model inference and training.
- software-dependent::
- Python 3.8 or later.
- PyTorch (we recommend installing the GPU version, see the PyTorch website).
- Git (for cloning code repositories).
2. Cloning of warehouses
Open a terminal and run the following command to get the R1-Onevision project code:
git clone https://github.com/Fancy-MLLM/R1-Onevision.git
cd R1-Onevision
3. Installation of dependencies
The project relies on several Python libraries, which can be installed with the following commands:
pip install -r requirements.txt
If you need to speed up reasoning, we recommend installing Flash Attention:
pip install flash-attn --no-build-isolation
4. Download model weights
R1-Onevision provides pre-trained models that can be downloaded from Hugging Face:
- Visit the Hugging Face model page.
- Download the model file (e.g.
R1-Onevision-7B) and extract it to the project directory under themodelsfolder (needs to be created manually).
5. Configuration environment
Ensure that CUDA is properly installed and compatible with PyTorch, which can be verified by running the following code:
import torch
print(torch.cuda.is_available()) # 输出 True 表示 GPU 可用
Usage
Basic Reasoning: Image and Text Analysis
R1-Onevision supports running inference tasks via Python scripts. Below is an example of loading a model and processing images and text:
- Writing reasoning scripts::
Create a file in the project root directory (e.g.infer.py), enter the following code:
from transformers import AutoProcessor, Qwen2_5_VLForConditionalGeneration
import torch
from qwen_vl_utils import process_vision_info
# 加载模型和处理器
MODEL_ID = "models/R1-Onevision-7B" # 替换为模型实际路径
processor = AutoProcessor.from_pretrained(MODEL_ID, trust_remote_code=True)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
MODEL_ID, trust_remote_code=True, torch_dtype=torch.bfloat16
).to("cuda").eval()
# 输入图像和文本
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "path/to/your/image.jpg"}, # 替换为本地图像路径
{"type": "text", "text": "请描述这张图片的内容并回答:图中有几个人?"}
]
}
]
# 处理输入
inputs = processor(messages, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=512)
response = processor.decode(outputs[0], skip_special_tokens=True)
print(response)
- Running Scripts::
python infer.py
The script will output an image description and a response. For example, if there are two people in the image, the model might return, "The image shows a park scene with two people sitting on a bench."
Feature: Math Reasoning
R1-Onevision excels in math visual reasoning. Assuming a picture containing a math problem (e.g., "2x + 3 = 7, find x"), the following steps can be followed:
- modifications
messagesThe text in reads, "Please answer the math problem in this picture and give the calculations." - Run the script and the model will return results similar to the following:
图片中的题目是:2x + 3 = 7
解题过程:
1. 两边同时减去 3:2x + 3 - 3 = 7 - 3
2. 简化得:2x = 4
3. 两边同时除以 2:2x / 2 = 4 / 2
4. 得出:x = 2
最终答案:x = 2
Data set use
R1-Onevision provides specialized datasets that can be used for model fine-tuning or testing:
- Download the dataset: Hugging Face dataset page.
- The data contains image and text pairs that can be used directly for training or validation after unzipping.
Model fine-tuning
If a custom model is required, supervised fine-tuning can be performed using the LLama-Factory:
- Install LLama-Factory:
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -r requirements.txt
- Configure the training parameters (refer to the project documentation) and run:
python train.py --model_name models/R1-Onevision-7B --dataset path/to/dataset
Summary of the operation process
- image analysis: Prepare the image path, write the script and run it to get the result.
- mathematical reasoning: Upload a picture of the topic, enter a question, and view the detailed answer.
- Custom Development: Download the dataset and model and adjust the parameters for training.
Be mindful of GPU memory usage, at least 16GB of video memory is recommended to ensure smooth operation.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...