QwenLong-L1.5 - Ali Tongyi Labs open source long text inference model

What is QwenLong-L1.5?
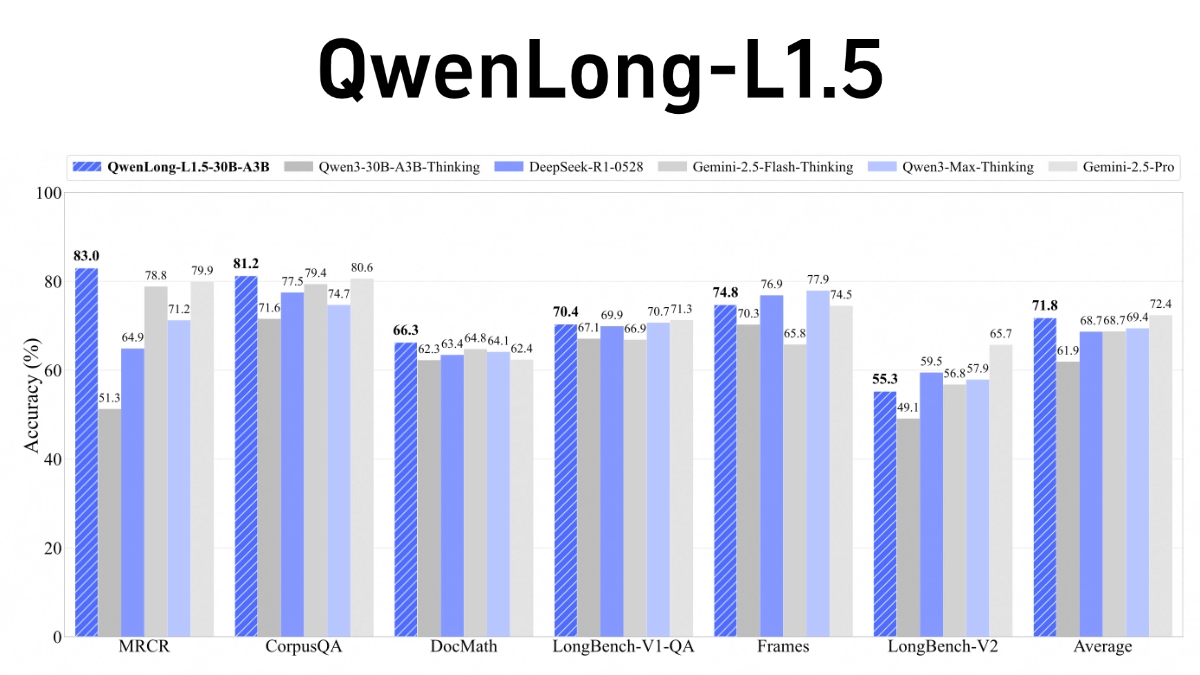
QwenLong-L1.5 is an open source long text inference model from Alibaba Tongyi Lab, focusing on solving complex inference problems with ultra-long contexts (e.g., 1M-4M tokens). The core breakthrough lies in three major innovations in the post-training phase: generating high-quality multi-hop inference data through knowledge graph, SQL parsing, and multi-intelligence body framework; proposing the adaptive entropy control strategy AEPo to dynamically balance the training stability; and designing the memory agent architecture to process ultra-long text in chunks and update the memory summary in real time. The model outperforms GPT-5 and Gemini-2.5-Pro in LongBench-V2 and other lists, especially in the ultra-long text task, and also improves the general-purpose capabilities such as mathematical reasoning.
Features of QwenLong-L1.5
- Significant improvement in long context reasoning: With a systematic post-training scheme, QwenLong-L1.5 excels in long context inference and can handle tasks beyond its physical context window (256K).
- Innovative Data Synthesis and Reinforcement Learning Strategies: Developed a new data synthesis process focused on creating challenging tasks requiring multi-hop traceability and globally distributed evidential reasoning, introducing reinforcement learning strategies such as task-balanced sampling and adaptive entropy control policy optimization to stabilize long context training.
- Powerful Memory Management Framework: Using multi-stage fusion reinforcement learning, combined with a memory update mechanism, enables the model to handle longer tasks outside the 256K context window for a single inference.
- excellent performance: In long context benchmarks, QwenLong-L1.5 outperforms its baseline model Qwen3-30B-A3B-Thinking by an average of 9.9 points, with a performance comparable to top models such as GPT-5 and Gemini-2.5-Pro. Its memory-smartbody framework achieves a performance gain of 9.48 points over the smartbody baseline on ultra-long tasks (1 million to 4 million tokens).
- expand one's financial resources: The model has been open-sourced for easy use by researchers and developers.
Core Advantages of QwenLong-L1.5
- Super long text processing capability: Can handle tasks that exceed its physical context window (256K), and is suitable for processing very long textual reasoning and analysis, such as long documents, complex datasets, and so on.
- Innovative training strategies: Combining reinforcement learning methods such as task-balanced sampling and adaptive entropy-controlled policy optimization (AEPO) to effectively improve the stability and performance of the model in long context tasks.
- Efficient Memory Management: Through the memory updating mechanism and multi-stage fusion reinforcement learning, the model can effectively manage the information in long texts and realize efficient processing of ultra-long tasks (1 million to 4 million tokens).
- Excellent performance: In long context benchmarks, QwenLong-L1.5 significantly outperforms its baseline model and even rivals top models such as GPT-5 and Gemini-2.5-Pro.
What is QwenLong-L1.5's official website?
- GitHub repository:: https://github.com/Tongyi-Zhiwen/Qwen-Doc
- HuggingFace Model Library:: https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1.5-30B-A3B
- arXiv Technical Paper:: https://arxiv.org/pdf/2512.12967
Applicable people of QwenLong-L1.5
- natural language processing (NLP) researcher: QwenLong-L1.5's long context processing capabilities and innovative training strategies provide researchers with new tools to study cutting-edge issues such as long text reasoning and memory management, and help to advance research progress in the field of natural language processing.
- Artificial Intelligence Developers: The open source nature makes it ideal for developers to build long text processing applications, such as intelligent customer service, document analysis, content creation, etc., which can help developers quickly develop high-performance long text processing functions.
- data scientist: When dealing with large-scale text datasets, QwenLong-L1.5 can effectively perform long text analysis and inference, providing data scientists with powerful support to aid in data analysis and machine learning tasks.
- Corporate Technical Team: For enterprises that need to deal with long text business, such as financial, legal, medical and other industries, QwenLong-L1.5 can help the team to deal with long text data such as contracts, reports, medical records and other long text data more efficiently, and improve the efficiency of the business.
- Academic researchers: In academic research, especially in fields involving long text analysis, such as literary research, historical document analysis, etc., QwenLong-L1.5 can be used as a research tool to help researchers dig out the deep information in the text.
- educator: In the field of education, QwenLong-L1.5 can be used to assist teaching, such as automatically correcting long essays, analyzing academic papers, etc., providing educators with more efficient teaching support tools.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...