Qwen3-ASR-Flash - A series of speech recognition models launched by Ali Tongyi Qianqian

What is Qwen3-ASR-Flash?
Qwen3-ASR-Flash is the latest high-precision speech recognition model from Alibaba, based on the Qwen3 Base model, trained by massive multimodal data. It supports 11 languages and multiple accents, including dialects such as Mandarin, Sichuan, Minnan, Wu, Cantonese, as well as British and American English. Core features include leading recognition accuracy, stunning song recognition capability (error rate below 8%), customized recognition (users can provide background text to get customized results), language recognition with non-vocal rejection, and high robustness in complex acoustic environments. Users can experience the model for free via ModelScope, Hugging Face, and the AliCloud Hundred Refinements API.
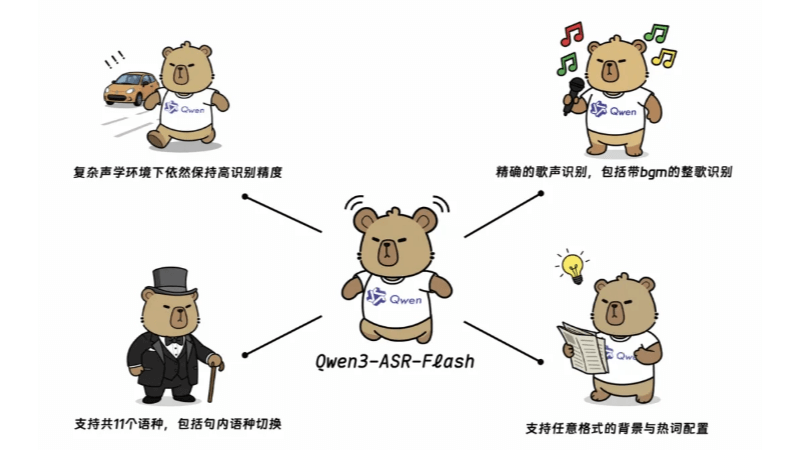
Qwen3-ASR-Flash Functional Features
- High-precision recognition: Best performance in multiple English, Chinese and multilingual benchmark tests, recognizing multiple languages and dialects.
- song recognitionThe program supports clean singing and whole song recognition with background music, and the measured error rate is lower than 8%.
- Customized identification: The user can provide background text in any format, and the model can adjust the recognition results accordingly, without pre-processing.
- Language Recognition and Non-Vocal Rejection: Accurately distinguishes speech languages and automatically filters out non-speech segments such as silence and background noise.
- high robustness: Maintains high accuracy in complex acoustic environments and when confronted with difficult text patterns such as long and difficult sentences and mid-sentence language switching.
Core Benefits of Qwen3-ASR-Flash
- High-precision recognition: Excellent performance in recognition tests for multiple languages and dialects, with lower error rates than comparable competitors.
- Multi-language support: The single model supports 11 languages and multiple dialects, covering Mandarin, English, French, German, and more.
- Customized identification: Users can provide background text in any format, and the model can intelligently use the contextual information to output customized recognition results.
- song recognitionThe system supports clean singing and whole song recognition with background music, and the measured error rate is lower than 8%, which is an excellent performance in the field of song recognition.
- Language Recognition and Non-Vocal Rejection: The ability to accurately distinguish speech languages and automatically filter non-speech segments, such as silence and background noise, improves recognition efficiency.
- high robustness: Maintains high accuracy in complex acoustic environments and when confronted with difficult text patterns such as long and difficult sentences and mid-sentence language switching.
What is the official website for Qwen3-ASR-Flash?
- Project website: https://bailian.console.aliyun.com/?spm=5176.29597918.J_tAwMEW-mKC1CPxlfy227s.1.4f007b08aWhTjW&tab=model#/model-market/detail /group-qwen3-asr-flash?modelGroup=group-qwen3-asr-flash
- Online Experience Demo:: https://huggingface.co/spaces/Qwen/Qwen3-ASR-Demo
People for whom Qwen3-ASR-Flash is intended
- Users who need high-precision voice transcription: e.g. journalists, conference recorders, researchers, etc., can quickly and accurately convert voice content to text.
- polyglot: e.g. foreign language learners, employees of multinational corporations, participants in international conferences, etc., can help to cross the language barrier.
- content creator: such as video bloggers, podcast hosts, etc., can efficiently generate subtitles and transcripts.
- Professionals in the fieldFor example, practitioners in the medical, financial, and legal industries can customize the recognition function to accurately identify professional terms.
- People with special speech recognition needs: such as the hearing impaired, who can better understand speech information with the help of the model; and users who need speech recognition in noisy environments, such as customer service personnel and on-site journalists.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts




No comments...