Qwen2.5-VL Released: Supports Long Video Understanding, Visual Localization, Structured Output, Open Source Fine-tunable

1.Model Introduction
In the five months since Qwen2-VL was released, numerous developers have built new models on top of the Qwen2-VL visual language model, providing valuable feedback to the Qwen team. During this time, the Qwen team has focused on building more useful visual language models. Today, the Qwen team is pleased to introduce the newest member of the Qwen family: Qwen2.5-VL.
Major enhancements:
- Understanding things visually: Qwen 2.5-VL is not only proficient in recognizing common objects such as flowers, birds, fish and insects, but also in analyzing text, charts, icons, graphs and layouts in images.
- Agenticity: Qwen2.5-VL plays the role of a visual agent directly, with the functionality of a reasoning and dynamic command tool that can be used on computers and cell phones.
- Understand long videos and capture events: Qwen 2.5-VL can understand videos longer than 1 hour, and this time it has the new ability to capture events by pinpointing relevant video clips.
- Capable of visual localization in different formats: Qwen2.5-VL can accurately locate objects in an image by generating bounding boxes or points, and can provide stable JSON output for coordinates and attributes.
- Generate Structured Output: For scanned data such as invoices, forms, tables, etc., Qwen 2.5-VL supports structured output of their contents, which is beneficial for financial and business purposes.
Model Architecture:
- Dynamic resolution and frame rate training for video understanding:
Extending the dynamic resolution to the temporal dimension by employing dynamic FPS sampling allows the model to understand video at various sample rates. Correspondingly, the Qwen team updated mRoPE with ID and absolute time alignment in the temporal dimension, enabling the model to learn temporal order and speed, ultimately gaining the ability to pinpoint specific moments.
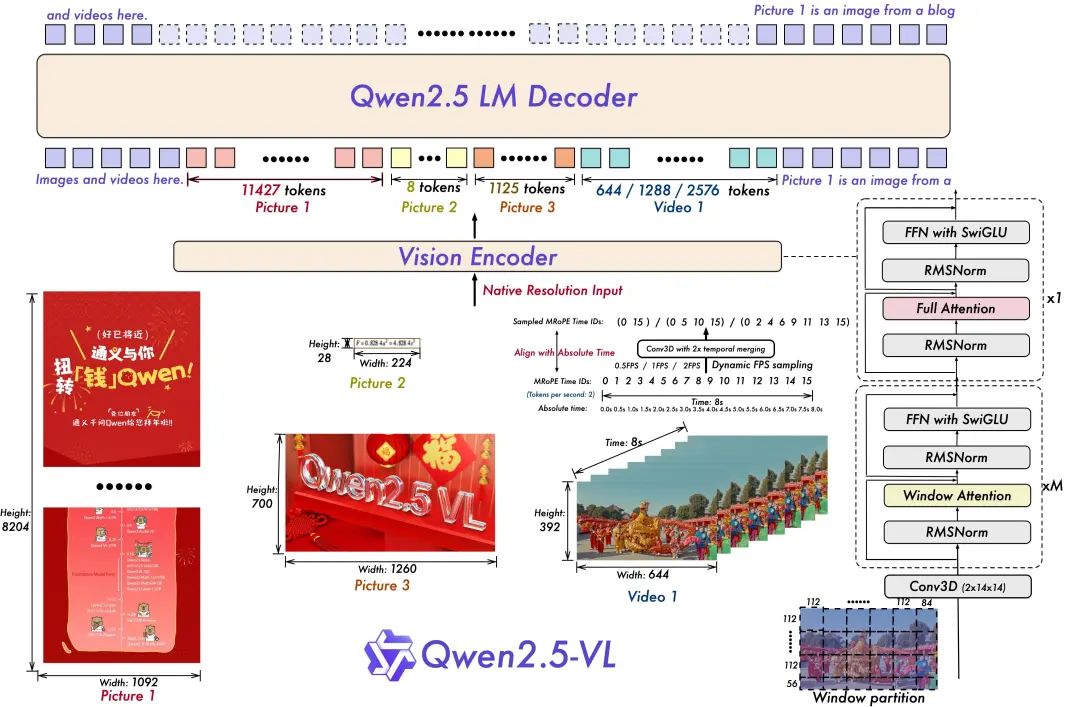
- Streamlined and efficient visual coder
The Qwen team has improved training and inference speed by strategically introducing the windowed attention mechanism into ViT. The ViT architecture has been further optimized with SwiGLU and RMSNorm to align it with the structure of Qwen 2.5 LLM.
This open source has three models with parameters of 3 billion, 7 billion and 72 billion. This repo contains the command-tuned 72B Qwen2.5-VL Model.
Model Ensemble:
https://www.modelscope.cn/collections/Qwen25-VL-58fbb5d31f1d47
Modeling Experience:
https://chat.qwenlm.ai/
Tech Blog:
https://qwenlm.github.io/blog/qwen2.5-vl/
Code Address:
https://github.com/QwenLM/Qwen2.5-VL
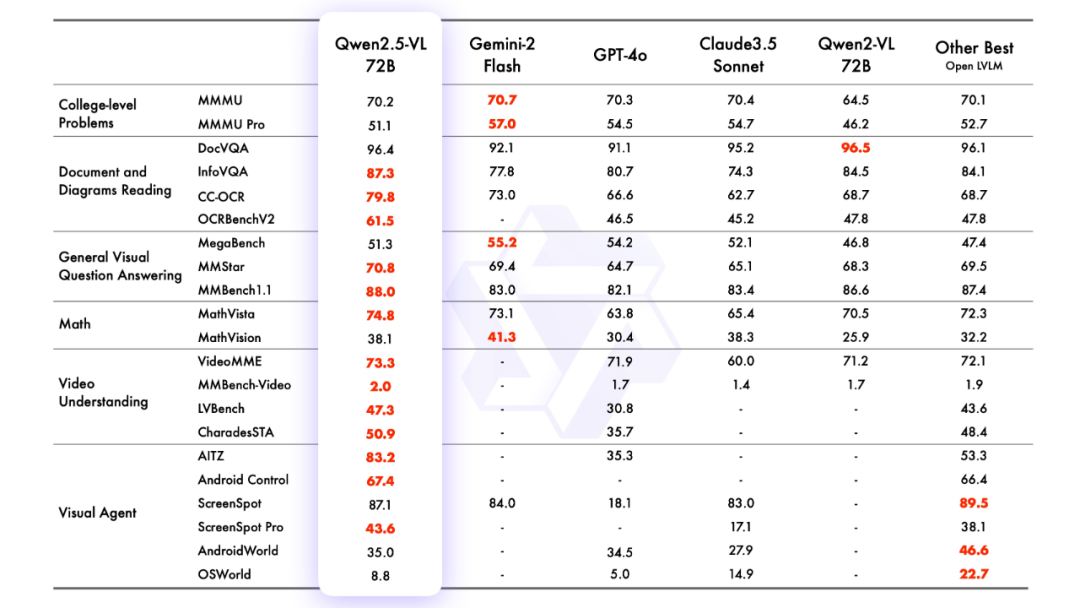
2.model effect
Model Evaluation
Mr. José María González
3.model-based reasoning
Reasoning with transformers
The code for Qwen2.5-VL is in the latest transformers, and it is recommended to build from source using the command:
pip install git+https://github.com/huggingface/transformersA toolkit is provided to help make it easier to work with various types of visual input, just as you would with an API. This includes base64, URLs, and interleaved images and videos. It can be installed using the following command:
pip install qwen-vl-utils[decord]==0.0.8Reasoning about the code:
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
from modelscope import snapshot_download
# Download and load the model
model_dir = snapshot_download("Qwen/Qwen2.5-VL-3B-Instruct")
# Default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_dir, torch_dtype="auto", device_map="auto"
)
# Optional: Enable flash_attention_2 for better acceleration and memory saving
# model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-VL-3B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# Load the default processor
processor = AutoProcessor.from_pretrained(model_dir)
# Optional: Set custom min and max pixels for visual token range
# min_pixels = 256 * 28 * 28
# max_pixels = 1280 * 28 * 28
# processor = AutoProcessor.from_pretrained(
# "Qwen/Qwen2.5-VL-3B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels
# )
# Define input messages
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Prepare inputs for inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generate output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
# Print the generated output
print(output_text)
Called directly using the Magic Hitch API-Inference
The API-Inference of the Magic Match platform is also the first to provide support for the Qwen2.5-VL series of models. Users of Magic Match can use it directly through the API call. The specific way of using API-Inference can be found on the model page (e.g. https://www.modelscope.cn/models/Qwen/Qwen2.5-VL-72B-Instruct):

Or see the API-Inference documentation:
https://www.modelscope.cn/docs/model-service/API-Inference/intro
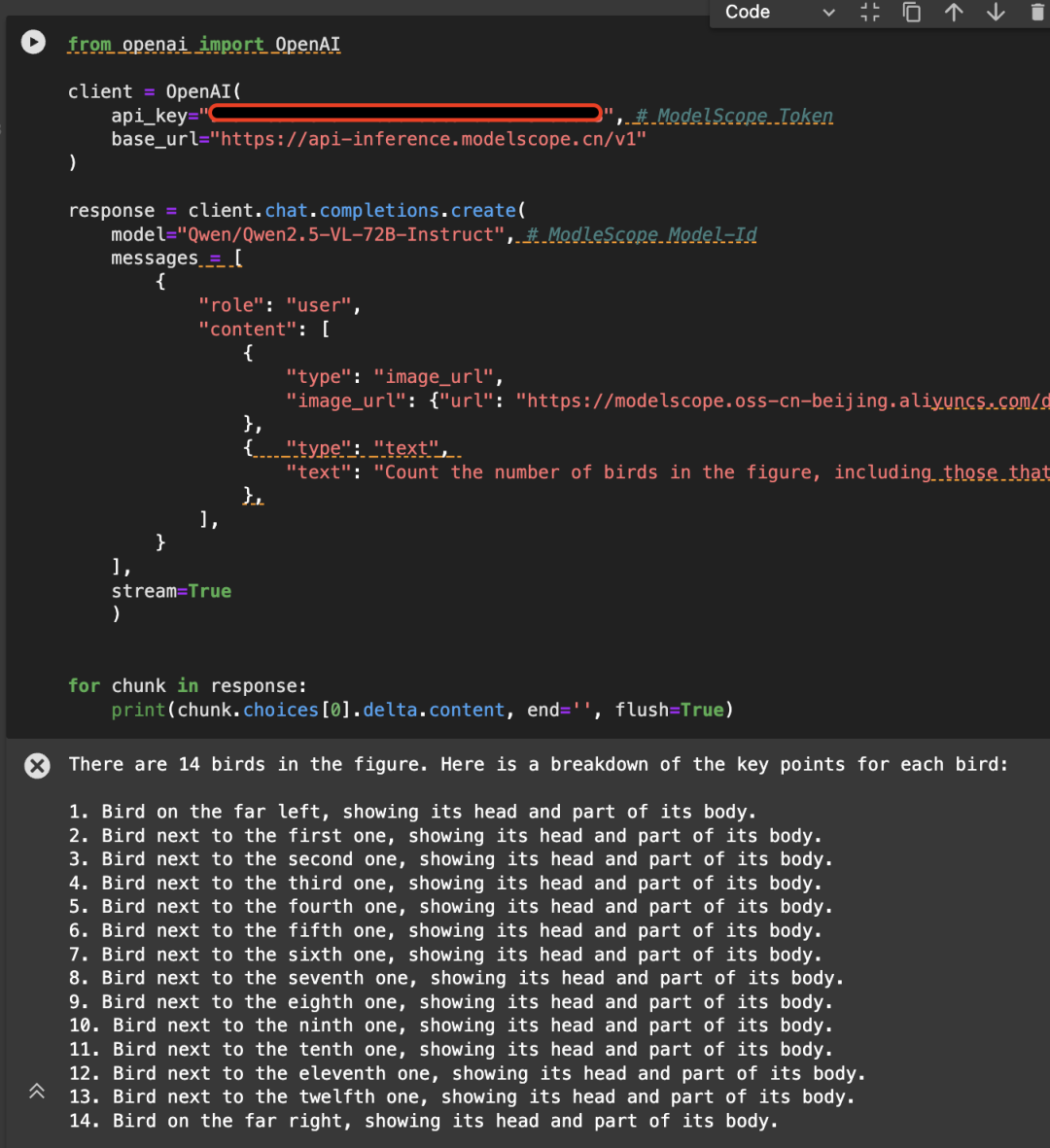
Here is an example of the following image, calling the API using the Qwen/Qwen2.5-VL-72B-Instruct model:

from openai import OpenAI
# Initialize the OpenAI client
client = OpenAI(
api_key="<MODELSCOPE_SDK_TOKEN>", # ModelScope Token
base_url="https://api-inference.modelscope.cn/v1"
)
# Create a chat completion request
response = client.chat.completions.create(
model="Qwen/Qwen2.5-VL-72B-Instruct", # ModelScope Model-Id
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://modelscope.oss-cn-beijing.aliyuncs.com/demo/images/bird-vl.jpg"
}
},
{
"type": "text",
"text": (
"Count the number of birds in the figure, including those that "
"are only showing their heads. To ensure accuracy, first detect "
"their key points, then give the total number."
)
},
],
}
],
stream=True
)
# Stream the response
for chunk in response:
print(chunk.choices[0].delta.content, end='', flush=True)
4. Model fine-tuning
We introduce the use of ms-swift on Qwen/Qwen2.5-VL-7B-Instruct fine-tuning. ms-swift is the magic ride community officially provided by the large model and multimodal large model fine-tuning deployment framework. ms-swift open source address:
https://github.com/modelscope/ms-swift
Here, we'll show runnable fine-tuning demos and give the format of the self-defined dataset.
Before you start fine-tuning, make sure your environment is ready.
git clone https://github.com/modelscope/ms-swift.git cd ms-swift pip install -e .
The image OCR fine-tuning script is as follows:
MAX_PIXELS=1003520 \
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset AI-ModelScope/LaTeX_OCR:human_handwrite#20000 \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4
Training video memory resources:

The video fine-tuning script is below:
# VIDEO_MAX_PIXELS等参数含义可以查看:
# https://swift.readthedocs.io/zh-cn/latest/Instruction/%E5%91%BD%E4%BB%A4%E8%A1%8C%E5%8F%82%E6%95%B0.html#id18
nproc_per_node=2
CUDA_VISIBLE_DEVICES=0,1 \
NPROC_PER_NODE=$nproc_per_node \
VIDEO_MAX_PIXELS=100352 \
FPS_MAX_FRAMES=24 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset swift/VideoChatGPT:all \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--deepspeed zero2
Training video memory resources:

The custom dataset format is as follows (the system field is optional), just specify `--dataset `:
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}
{"messages": [{"role": "user", "content": "<image><image>两张图片有什么区别"}, {"role": "assistant", "content": "前一张是小猫,后一张是小狗"}], "images": ["/xxx/x.jpg", "xxx/x.png"]}
{"messages": [{"role": "system", "content": "你是个有用无害的助手"}, {"role": "user", "content": "<video>视频中是什么"}, {"role": "assistant", "content": "视频中是一只小狗在草地上奔跑"}], "videos": ["/xxx/x.mp4"]}
The grounding task fine-tuning script is as follows:
CUDA_VISIBLE_DEVICES=0 \
MAX_PIXELS=1003520 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset 'AI-ModelScope/coco#20000' \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--dataset_num_proc 4
Training video memory resources:

The grounding task customizes the data set format as follows:
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "<image>描述图像"}, {"role": "assistant", "content": "<ref-object><bbox>和<ref-object><bbox>正在沙滩上玩耍"}], "images": ["/xxx/x.jpg"], "objects": {"ref": ["一只狗", "一个女人"], "bbox": [[331.5, 761.4, 853.5, 1594.8], [676.5, 685.8, 1099.5, 1427.4]]}}
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "<image>找到图像中的<ref-object>"}, {"role": "assistant", "content": "<bbox><bbox>"}], "images": ["/xxx/x.jpg"], "objects": {"ref": ["羊"], "bbox": [[90.9, 160.8, 135, 212.8], [360.9, 480.8, 495, 532.8]]}}
After training is complete, inference is performed on the validation set from training using the following command.
Here `--adapters` needs to be replaced with the last checkpoint folder generated by the training. Since the adapters folder contains the parameter files for the training, there is no need to specify `--model` additionally:
CUDA_VISIBLE_DEVICES=0swift infer--adapters output/vx-xxx/checkpoint-xxx--stream false--max_batch_size 1--load_data_args true--max_new_tokens 2048
Push the model to ModelScope:
CUDA_VISIBLE_DEVICES=0swift export--adapters output/vx-xxx/checkpoint-xxx--push_to_hub true--hub_model_id '<your-model-id>'--hub_token '<your-sdk-token>'
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts




No comments...