Qwen2.5-Omni: an end-measurement model for multimodal input and real-time speech interaction

General Introduction
Qwen2.5-Omni is an open source multimodal AI model developed by Alibaba Cloud Qwen team. It can process multiple inputs such as text, images, audio and video and generate text or natural speech responses in real-time. The model was released on March 26, 2025, and the code and model files are hosted on GitHub and free for all to download and use. It uses the Thinker-Talker architecture and TMRoPE technology to ensure efficient processing of multimodal data.Qwen2.5-Omni performs well in tasks such as speech recognition, image understanding, and video analytics, and is suitable for scenarios such as intelligent assistants and multimedia processing.

Function List
- Supports multimodal inputs: can process text, images, audio and video simultaneously.
- Real-time streaming response: text or voice feedback is generated immediately after input.
- Natural Speech Synthesis: Generate clear and natural speech, support multiple tones.
- Image and video understanding: recognize image content or analyze video clips.
- End-to-end command following: complete tasks directly based on voice or text commands.
- Open Source Free: Provides complete code and models to support user customization.
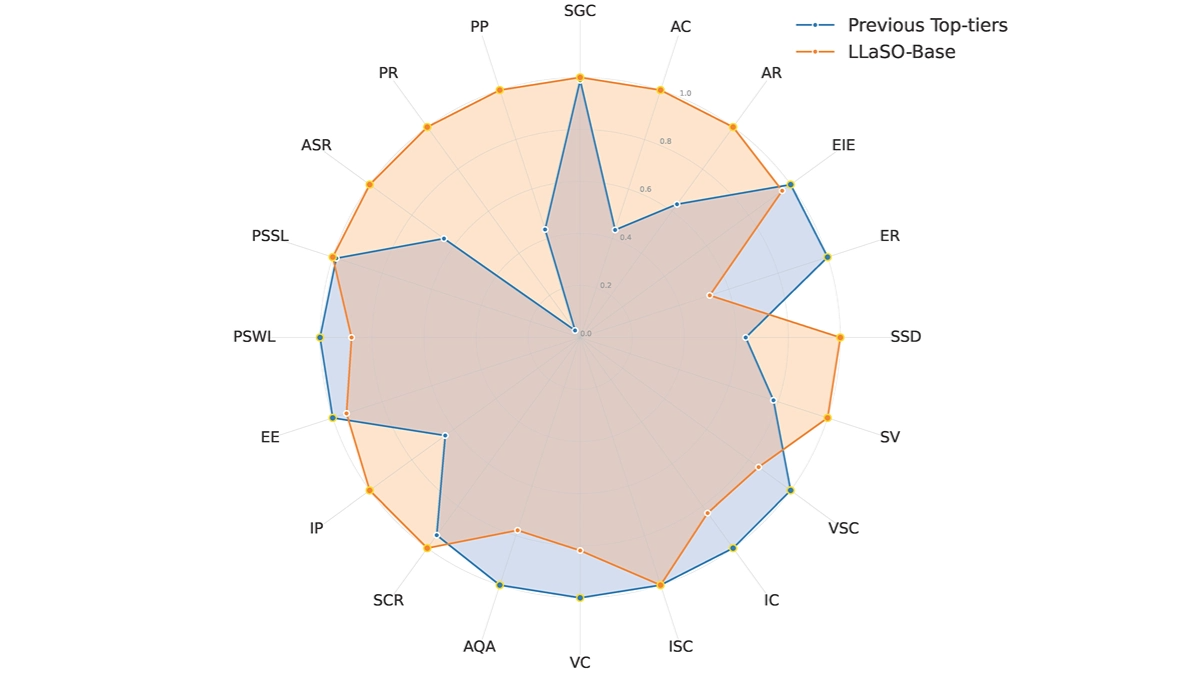
We performed a comprehensive evaluation of Qwen2.5-Omni. The results show that it performs strongly on all modalities, giving it an advantage over equally sized single-modality models as well as closed-source models such as Qwen2.5-VL-7B, Qwen2-Audio, and Gemini-1.5-Pro. In tasks that require the integration of multiple modalities, such as OmniBench, Qwen2.5-Omni achieves state-of-the-art performance. Furthermore, in single-modal tasks, it excels in the areas of speech recognition (Common Voice), translation (CoVoST2), audio understanding (MMAU), image reasoning (MMMU, MMStar), video understanding (MVBench), and speech generation (Seed-tts-eval and Subjective Naturalness).

Using Help
The use of Qwen 2.5-Omni requires a certain level of technical knowledge. Below is a detailed installation and operation guide to help users get started quickly.
Installation process
- Preparing the environment
- Make sure Python 3.10 or later is installed.
- Git is required to download the code.
- Recommended for Linux systems, non-Linux systems may require additional configuration.
- Download Code
- Clone your GitHub repository by entering the command in the terminal:
git clone https://github.com/QwenLM/Qwen2.5-Omni.git - Go to the project catalog:
cd Qwen2.5-Omni
- Clone your GitHub repository by entering the command in the terminal:
- Installation of dependencies
- Because the code has not been fully merged into the Hugging Face master branch, a specific version of Transformers needs to be installed:
pip uninstall transformers pip install git+https://github.com/huggingface/transformers@3a1ead0aabed473eafe527915eea8c197d424356 pip install accelerate - Install the multimodal processing tool:
pip install qwen-omni-utils[decord]- Note: Pre-installation is required
ffmpegLinux users can runsudo apt install ffmpegThe - Non-Linux users who are unable to install
decord, could read:pip install qwen-omni-utils
- Note: Pre-installation is required
- Because the code has not been fully merged into the Hugging Face master branch, a specific version of Transformers needs to be installed:
- Download model
- Download the Qwen2.5-Omni-7B model from Hugging Face (https://huggingface.co/Qwen/Qwen2.5-Omni-7B), save it locally.
- Verify Installation
- Run the following command to check the environment:
python -c "from transformers import Qwen2_5OmniModel; print('安装成功')"
- Run the following command to check the environment:
Functional operation flow
1. Processing of text inputs
- procedure::
- Load models and processors:
from transformers import Qwen2_5OmniModel, Qwen2_5OmniProcessor model = Qwen2_5OmniModel.from_pretrained("Qwen/Qwen2.5-Omni-7B", device_map="auto") processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B") - Enter text and generate a response:
text = "今天天气怎么样?" inputs = processor(text=text, return_tensors="pt") outputs = model.generate(**inputs) print(processor.batch_decode(outputs, skip_special_tokens=True))
- Load models and processors:
- in the end: Return text responses such as "It was a sunny day and the temperature was perfect."
2. Processing of image inputs
- procedure::
- Prepare the image file (e.g.
image.jpg). - Modify the script to include images:
images = ["image.jpg"] text = "图片里有什么?" inputs = processor(text=text, images=images, return_tensors="pt") outputs = model.generate(**inputs) print(processor.batch_decode(outputs, skip_special_tokens=True))
- Prepare the image file (e.g.
- in the end: Describe the content of the picture, e.g., "The picture shows a dog running in the grass."
3. Processing of audio inputs
- procedure::
- Prepare the audio file (e.g.
audio.wav). - Modify the script to include audio:
audios = ["audio.wav"] text = "音频里说了什么?" inputs = processor(text=text, audios=audios, return_tensors="pt") outputs = model.generate(**inputs) print(processor.batch_decode(outputs, skip_special_tokens=True))
- Prepare the audio file (e.g.
- in the end: Transcribe the audio content, e.g., "The audio says, 'It's going to rain tomorrow.'"
4. Processing of video inputs
- procedure::
- Prepare the video file (e.g.
video.mp4). - Modify the script to include a video:
videos = ["video.mp4"] text = "视频里发生了什么?" inputs = processor(text=text, videos=videos, return_tensors="pt") outputs = model.generate(**inputs) print(processor.batch_decode(outputs, skip_special_tokens=True))
- Prepare the video file (e.g.
- in the end: Describe the content of the video, e.g., "Someone in the video is drawing."
5. Generating speech output
- procedure::
- Set up system prompts and enable voice:
conversation = [ {"role": "system", "content": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}, {"role": "user", "content": "请用语音回答:今天天气如何?"} ] text = processor.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True) inputs = processor(text=text, return_tensors="pt") text_ids, audio = model.generate(**inputs, use_audio_in_video=True) import soundfile as sf sf.write("output.wav", audio.reshape(-1).detach().cpu().numpy(), samplerate=24000)
- Set up system prompts and enable voice:
- in the end: Generate
output.wavfile with the content of the voice response.
6. Adjustment of voice tones
- procedure::
- Specify the tone (e.g. Chelsie or Ethan) at generation time:
text_ids, audio = model.generate(**inputs, spk="Ethan") sf.write("output.wav", audio.reshape(-1).detach().cpu().numpy(), samplerate=24000)
- Specify the tone (e.g. Chelsie or Ethan) at generation time:
- in the end: Generates a voice file with the specified timbre.
7. Acceleration with FlashAttention-2
- procedure::
- Install FlashAttention-2:
pip install -U flash-attn --no-build-isolation - Enabled when loading a model:
model = Qwen2_5OmniModel.from_pretrained("Qwen/Qwen2.5-Omni-7B", device_map="auto", attn_implementation="flash_attention_2")
- Install FlashAttention-2:
- in the end: Faster generation and lower video memory usage.
caveat
- hardware requirement: GPUs are recommended, with at least 16GB of video memory.
- network requirement: The network needs to be stabilized when downloading models and dependencies.
- Debugging Support: See GitHub for more information on this.
README.mdor community discussion.
application scenario
- Real-time voice assistant
Users ask questions by voice and the model generates voice answers in real time, suitable for customer service or personal assistants. - Video Content Analysis
Input the video and the model extracts key information to help users organize the footage or generate reports. - Educational support
Students upload course audio or video, and models answer questions or extract key points to enhance learning.
QA
- What languages are supported?
It mainly supports Chinese and English, and provides Chelsie, Ethan and other tones for speech synthesis. - How much storage space is required?
The Qwen2.5-Omni-7B model is approximately 14GB and it is recommended to reserve more than 20GB. - Is it commercially available?
Yes, based on the Apache 2.0 license, free for commercial use subject to terms.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles


No comments...