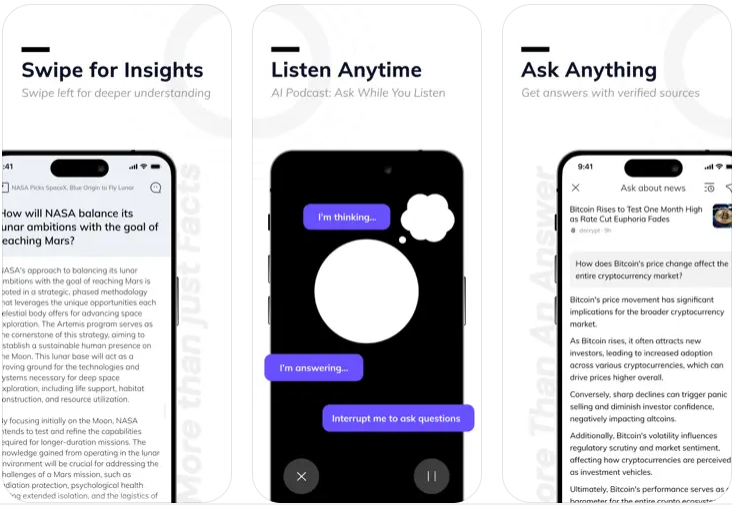
PaddleOCR-VL - Baidu open source ultra-lightweight visual-linguistic models

What is PaddleOCR-VL?
PaddleOCR-VL is Baidu's open source ultra-lightweight visual-language model, optimized for document parsing scenarios. The model contains only 0.9B parameters, by fusing a dynamic high-resolution visual coder with a lightweight ERNIE language model, it significantly reduces computational overhead while maintaining high accuracy. Supporting 109 languages, it can accurately recognize complex elements such as text, tables, formulas, charts, etc., and restore the layout structure in line with human reading habits. In the authoritative benchmark OmniDocBench v1.5, the model won the world's first place in comprehensive performance with 92.6 points, reaching the SOTA level in core indexes such as text editing distance (0.035), formula recognition (CDM 91.43), and formulas processing (TEDS 93.52), and outperforming the mainstream multimodal models such as GPT-4o.

Features of PaddleOCR-VL
- Extreme lightweight and high performance: only 0.9B parameters, runs on regular CPUs, supports browser plugin-level deployment, and significantly faster inference than similar models (14.21 TP3T faster than MinerU2.5, 253.011 TP3T faster than dots.ocr).
- Multi-element precision analysisIt supports fine-grained recognition of text, tables, formulas, charts and other complex elements, with a text editing distance of only 0.035, a formula recognition CDM of 91.43, and a table TEDS of 93.52 in authoritative evaluations, all reaching the industry's optimal level.
- Multi-language and Complex Scenario Adaptation: Covering 109 languages (including Russian, Arabic and other special writing systems), it is good at handling handwriting, historical documents and vertically-typed text (e.g., vertical Chinese), adapting to the needs of globalized document processing.
- Intelligent Layout Analysis and Reading Order Restoration: Automatic prediction of reading logic through a two-stage architecture (PP-DocLayoutV2 layout detection + PaddleOCR-VL-0.9B recognition), with a reading order error of only 0.043, accurately restoring human reading habits.
- Open Source and Practical Advantages: Fully open source and provide Demo, excellent performance in invoice recognition, academic paper parsing and other scenarios, can be combined with RAG system to become AI knowledge processing infrastructure.
Core Benefits of PaddleOCR-VL
- Extreme Lightweight & Efficient Reasoning: The core model is only 0.9B ParametersMinerU2.5 can run on regular CPUs, supports browser plug-in level deployment, and has a very low memory footprint. Improved inference speed over MinerU2.5 on a single A100 GPU. 14.2%, upgraded from dots.ocr 253.01%, which significantly reduces computational overhead.
- Accurate recognition of multilingual and complex elements: Support 109 languagesIt covers special writing systems such as Chinese, English, Arabic, Russian, etc., and can accurately handle complex elements such as text, tables, formulas, charts, handwriting and historical documents.
- Two-stage architecture is stable and reliable: Adoption PP-DocLayoutV2 Layout Inspection + PaddleOCR-VL-0.9B Content Recognition The synergistic framework effectively avoids the common phantom and misalignment problems of end-to-end models, and performs more stably in complex layouts.
- Deep Multimodal Fusion and Realistic Understanding: By NaViT Dynamic Resolution Visual Encoder together with ERNIE-4.5-0.3B Language models Combined, it realizes a comprehensive breakthrough from character recognition to semantic understanding, and intelligently handles special elements such as multi-column typography, mathematical formulas, and QR codes.
- Leading performance in authoritative reviewsThe comprehensive performance is ranked No. 1 in the world in OmniDocBench V1.5 and other authoritative lists, surpassing giant multimodal models such as Gemini-2.5 Pro and GPT-4o, as well as vertical domain models such as dots.ocr and MinerU.
What is PaddleOCR-VL's official website?
- Project website:: https://ernie.baidu.com/blog/zh/posts/paddleocr-vl/
- HuggingFace Model Library:: https://huggingface.co/PaddlePaddle/PaddleOCR-VL
- arXiv Technical Paper:: https://arxiv.org/pdf/2510.14528
- Online Experience Demo:: https://huggingface.co/spaces/PaddlePaddle/PaddleOCR-VL_Online_Demo
- Official Experience Address:: https://aistudio.baidu.com/application/detail/98365
Who is PaddleOCR-VL for?
- Developers & Engineers: Software developers who need to integrate OCR capabilities, especially suitable for resource-constrained scenarios (e.g., browser plug-ins, mobile applications) and open source community collaboration.
- Enterprise IT & Digital Team: Businesses in finance, retail, manufacturing, and other industries that deal with large volumes of documents for building automated processes (e.g., contract review, inventory management).
- Researchers and educators: Academic institutions, libraries, and practitioners in the education industry for digitizing literature, transcribing manuscripts, or parsing instructional materials.
- Government and Public Utilities: Government archives departments, public service organizations, and other organizations that need to handle sensitive documents in a compliant and efficient manner.
- SMEs and startups with limited budgets: Project teams that need high-performance OCR capabilities but can't afford the cost of large model calculations.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles


No comments...