
OmniVinci - NVIDIA's Open Source Omnimodal Large Language Model

What is OmniVinci?
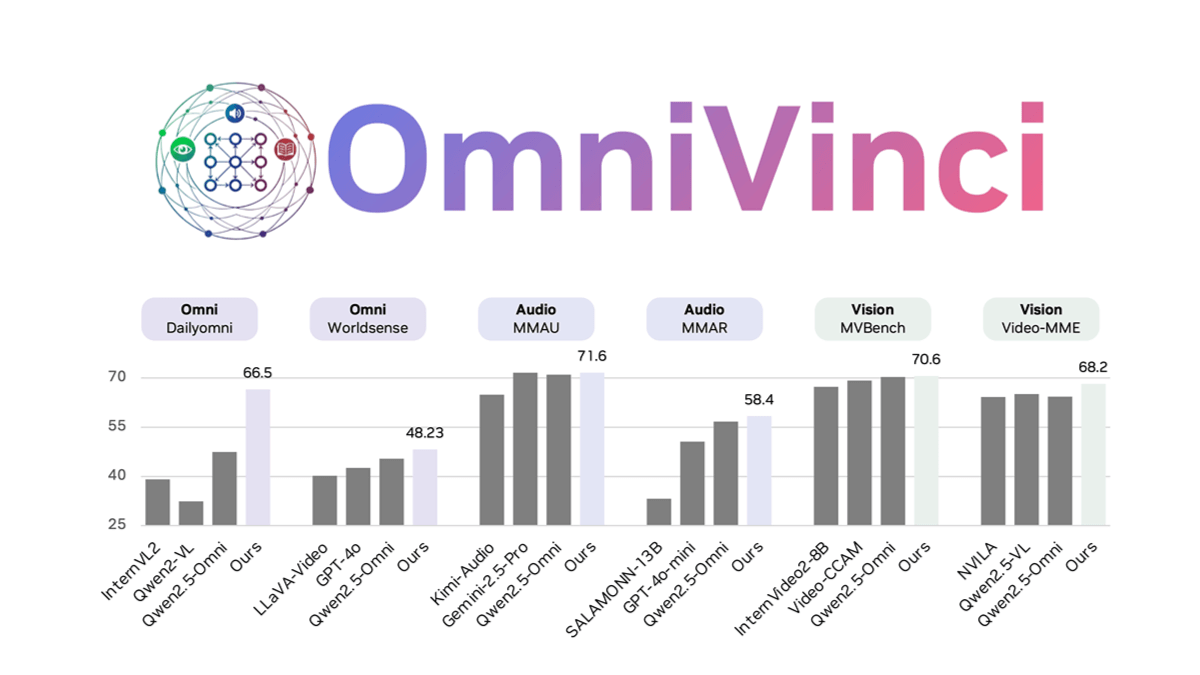
OmniVinci is an open-source, fully-modal, large-scale language model developed by NVIDIA that solves the problem of modal fragmentation in multimodal models through architectural innovation and data optimization. Alignment of visual and audio embeddings is enhanced by OmniAlignNet, which utilizes temporal embedding grouping to capture relative temporal alignment information, and constrained rotational temporal embedding to encode absolute temporal information.OmniVinci generates a large number of unimodal and omnimodal dialog samples for training through data synthesis and a well-designed data distribution strategy. The two-phase training strategy, unimodal training followed by joint omnimodal training, effectively integrates multimodal comprehension.OmniVinci performs well in several benchmarks, e.g., it scores 19.05 points higher than Qwen2.5-Omni on DailyOmni, and the amount of training tokens is reduced dramatically. OmniVinci has been applied to medical CT image interpretation, semiconductor device detection, etc., and has demonstrated strong multimodal understanding capability.
Features of OmniVinci
- multimodal understanding: The ability to process visual, audio, and textual information simultaneously to enable cross-modal understanding and reasoning, e.g., a detailed description can be generated based on video content, including both visual and audio information.
- Model Architecture Innovation: Enhancing the alignment of visual and audio embeddings through OmniAlignNet, using temporal embedding grouping to capture the relative temporal alignment information of visual and audio signals, and encoding absolute temporal information using constrained rotational temporal embeddings to improve the model's understanding of multimodal signals.
- Data Synthesis and Optimization: Generate a large number of unimodal and omnimodal conversation samples through data synthesis and well-designed data distribution strategies to optimize the training data and improve the generalization ability and performance of the model.
- Two-stage training strategy: A two-stage strategy of unimodal training and full-modal joint training is used to develop visual and audio comprehension capabilities separately, and then integrate these capabilities to realize cross-modal comprehension, effectively enhancing the multimodal reasoning ability of the model.
- Efficient training: During training, OmniVinci achieves superior performance using a smaller amount of training tokens (0.2 trillion), dramatically reducing the consumption of training resources compared to other models.
OmniVinci's core strengths
- Powerful multimodal understanding: The ability to simultaneously process information from multiple modalities such as vision, audio and text, enabling cross-modal understanding and reasoning.
- Effective Training Strategies: A two-stage training approach, with unimodal training followed by full-modal joint training, effectively integrates multimodal comprehension while reducing the consumption of training resources.
- Innovative Model Architecture: Enhanced alignment of visual and audio embeddings through OmniAlignNet, temporal embedding grouping, and constrained rotational temporal embedding improves the model's understanding of multimodal signals.
- Optimized data preparation: Generate a large number of high-quality unimodal and omnimodal conversation samples through data synthesis and well-designed data distribution strategies to optimize the training data and improve the generalization ability of the model.
- Excellent performance: Outperforms in several benchmarks, such as significantly outperforming other models on tasks such as DailyOmni, MMAR, and Video-MME, with a significantly reduced amount of training tokens.
What is the official website of OmniVinci
- Project website:: https://nvlabs.github.io/OmniVinci/
- Github repository:: https://github.com/NVlabs/OmniVinci
- HuggingFace Model Library:: https://huggingface.co/nvidia/omnivinci
- arXiv Technical Paper:: https://arxiv.org/pdf/2510.15870
Who is OmniVinci for?
- Artificial intelligence researchers: Scholars with research interests in multimodal learning, large-scale language modeling, and cross-modal understanding can explore new research directions and technological breakthroughs with OmniVinci.
- Machine Learning Engineer: Engineers developing and optimizing multimodal applications can use OmniVinci to enhance model performance for real-world projects.
- Medical Industry PractitionersOmniVinci's multimodal understanding allows radiologists and medical researchers, for example, to more accurately interpret medical images and related data.
- Industrial Automation Specialist: In smart manufacturing, utilize OmniVinci's vision and audio processing capabilities to improve the efficiency of equipment inspection and quality control.
- Robotics Developer: Engineers developing intelligent robotic systems can utilize OmniVinci to enhance a robot's ability to sense and understand its environment.
- data scientist: Data scientists with a need for large-scale data processing and multimodal data analysis can use OmniVinci to improve data processing efficiency and analytical accuracy.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts




No comments...