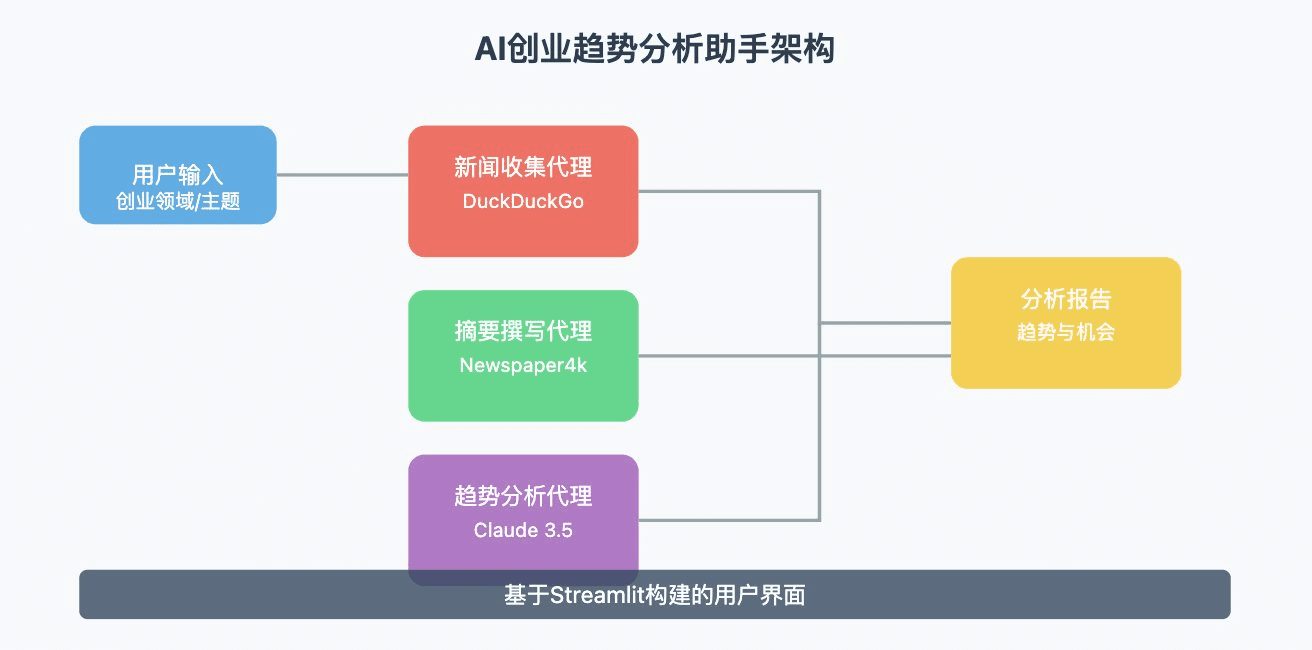
Ollama in LangChain - Python Integration

summary
This document describes how to use the Ollama Integrate with LangChain to create powerful AI applications.Ollama is an open source deployment tool for large language models, while LangChain is a framework for building language model-based applications. By combining the two, we can rapidly deploy and use advanced AI models in a local environment.
Note: This document contains core code snippets and detailed explanations. The full code can be found in theThis Jupyter notebookFound in.
1. Environmental settings
Configuring the Conda Environment
First, we need to use the Conda environment in Jupyter. Execute the following command from the command line:
conda create -n handlm python=3.10 -y
conda activate handlm
pip install jupyter
python -m ipykernel install --user --name=handlm
After execution, restart Jupyter and select the Kernel for that environment as shown:

⚠️ Note
Attention: It is also possible to use the global environment directly without the conda virtual environment.
Installation of dependencies
Before we start, we need to install the following packages:
langchain-ollama: for integrating Ollama models into the LangChain frameworklangchain: LangChain's core library, which provides tools and abstractions for building AI applicationslangchain-community: Includes various integrations and tools contributed by the communityPillow: for image processing, which is used in multimodal tasksfaiss-cpu: for building simple RAG retriever
It can be installed with the following command:
pip install langchain-ollama langchain langchain-community Pillow faiss-cpu
2. Download the required models and initialize OllamaLLM
Download llama3.1 model
- Go to the official website https://ollama.com/download to download and install Ollama on available supported platforms.
- Check out https://ollama.ai/library for all the available models.
- pass (a bill or inspection etc)
ollama pull <name-of-model>command to get the available LLM models (for example:ollama pull llama3.1).
The command line is executed as shown in the figure:

Model storage location:
- Mac.
~/.ollama/models/ - Linux (or WSL).
/usr/share/ollama/.ollama/models - Windows.
C:\Users\Administrator\.ollama\models
3. Examples of basic use
Conducting a conversation with ChatPromptTemplate
ChatPromptTemplate allows us to create a reusable template with one or more parameters. These parameters can be dynamically replaced at runtime to generate different prompts.
template = """
你是一个乐于助人的AI,擅长于解决回答各种问题。
问题:{question}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = prompt | model
chain.invoke({"question": "你比GPT4厉害吗?"})
In the Create Chain section, use the pipe operator |It connects the prompt to the model to form a processing flow. This chaining makes it easy to combine and reuse different components.
invoke method triggers the entire processing chain, passing our question into the template and then sending the formatted prompt to the model for processing.
streaming output
Streaming output is a technique that returns results incrementally as it generates long text. This method has several important advantages:
- Improved user experience: users can see partial results immediately, rather than waiting for the entire response to complete.
- Reduce waiting time: for long answers, users can start reading before the full answer is generated.
- Real-time interaction: allows intervention or termination during the generation process.
In practice, especially in chatbots or real-time dialog systems, streaming output is almost essential.
from langchain_ollama import ChatOllama
model = ChatOllama(model="llama3.1", temperature=0.7)
messages = [
("human", "你好呀"),
]
for chunk in model.stream(messages):
print(chunk.content, end='', flush=True)
model.stream() method is a wrapper around the Ollama API's streaming output interface, which returns a generator object. When calling the model.stream(messages) When you do, the following operations are completed:
- Send a request to the Ollama API to start generating a response.
- The API starts generating text, but instead of waiting until it's all generated, it returns it in small chunks.
- For each small piece of text received, the
stream()method yields the block of text. flush=TrueMake sure that each clip is displayed immediately, rather than waiting for the buffer to fill up.
Tool Call
Tool calls are the ability of an AI model to interact with external functions or APIs. This allows the model to perform complex tasks such as mathematical computations, data queries, or external service calls.
def simple_calculator(operation: str, x: float, y: float) -> float:
'''实际的代码处理逻辑'''
llm = ChatOllama(
model="llama3.1",
temperature=0,
).bind_tools([simple_calculator])
result = llm.invoke("你知道一千万乘二是多少吗?")
bind_tools method allows us to register a custom function into the model. This way, when the model encounters a problem that needs to be computed, it can call this function to get accurate results, rather than relying on its pre-training knowledge.
This capability is useful when building complex AI applications, for example:
- Create chatbots that can access real-time data
- Build intelligent assistants that can perform specific tasks (e.g., booking, querying, etc.)
- Development of AI systems capable of performing precise calculations or complex operations
multimodal model
Ollama supports multimodal models such as bakllava and llava. multimodal models are AI models that are capable of handling multiple types of input (e.g., text, images, audio, etc.). These models excel at understanding and generating cross-modal content, enabling more complex and natural human-computer interactions.
First, the multimodal model needs to be downloaded. Execute it at the command line:
ollama pull llava

We can then use the following code to process the image and text input:
from langchain_ollama import ChatOllama
from langchain_core.messages import HumanMessage
from langchain_core.output_parsers import StrOutputParser
llm = ChatOllama(model="llava", temperature=0)
def prompt_func(data):
'''构造多模态输入'''
chain = prompt_func | llm | StrOutputParser()
query_chain = chain.invoke(
{"text": "这个图片里是什么动物啊?", "image": image_b64}
)
The key point here is:
- Image preprocessing: we need to convert the image to a base64 encoded string.
- Hint function:
prompt_funcA multimodal input containing text and images is created. - Chaining: we use
|operator connects the hint function, the model, and the output parser.
Multimodal models are useful in many scenarios, for example:
- Image description generation
- visual question and answer system
- Image-based content analysis and recommendation
4. Advanced usage
Conversation using ConversationChain
ConversationChain is a powerful tool provided by LangChain for managing multi-round conversations. It combines language models, prompt templates, and in-memory components to make it easy to create context-aware dialog systems.
memory = ConversationBufferMemory()
conversation = ConversationChain(
llm=model,
memory=memory,
verbose=True
)
# 进行对话
response = conversation.predict(input="你好,我想了解一下人工智能。")
print("AI:", response)
response = conversation.predict(input="能给我举个AI在日常生活中的应用例子吗?")
print("AI:", response)
response = conversation.predict(input="这听起来很有趣。AI在医疗领域有什么应用?")
print("AI:", response)
The key component here is:
ConversationBufferMemory: This is a simple in-memory component that stores the history of all previous conversations.ConversationChain: It combines a language model, memory, and a default dialog prompt template.
Maintaining a dialog history is important because it allows for modeling:
- Understanding context and previously mentioned information
- Generate more coherent and relevant responses
- Handling complex multi-round dialog scenarios
In practice, you may need to consider using more advanced memory components, such as the ConversationSummaryMemoryto handle long dialogs and avoid exceeding the model's context length limit.
Customized prompt templates
Well-designed prompt templates are key to creating efficient AI applications. In this example, we created a complex prompt for generating product descriptions:
system_message = SystemMessage(content="""
你是一位经验丰富的电商文案撰写专家。你的任务是根据给定的产品信息创作吸引人的商品描述。
请确保你的描述简洁、有力,并且突出产品的核心优势。
""")
human_message_template = """
请为以下产品创作一段吸引人的商品描述:
产品类型: {product_type}
核心特性: {key_feature}
目标受众: {target_audience}
价格区间: {price_range}
品牌定位: {brand_positioning}
请提供以下三种不同风格的描述,每种大约50字:
1. 理性分析型
2. 情感诉求型
3. 故事化营销型
"""
# 示例使用
product_info = {
"product_type": "智能手表",
"key_feature": "心率监测和睡眠分析",
"target_audience": "注重健康的年轻专业人士",
"price_range": "中高端",
"brand_positioning": "科技与健康的完美结合"
}
There are several important design considerations for this structure:
- system_prompt: defines the roles and overall tasks of the AI, setting the tone of the entire conversation.
- human_message_template: provides the structure of specific instructions and required messages.
- Multi-parameter design: allows flexibility to adapt to different products and needs.
- Diversity Output Requirement: encourages models to demonstrate their diversity by requiring different styles of description.
Consider the following when designing an effective prompt template:
- Clearly define the role and mission of AI
- Provide a clear, structured input format
- Contains specific output requirements and formatting guidance
- Consider how to maximize the model's capabilities and creativity
Building a simple RAG Q&A system
RAG (Retrieval-Augmented Generation) is an AI technique that combines retrieval and generation to augment the answering ability of a language model by retrieving relevant information.The workflow of a RAG system typically includes the following steps:
- Split knowledge base documents into chunks and create vector indexes
- Vectorize the user's problem and retrieve relevant documents in an index
- Provide the retrieved relevant documents to the language model as context along with the original question
- The language model generates responses based on the retrieved information
The advantage of RAG is that it helps language models access up-to-date and specialized information, reduces illusions, and improves the accuracy and relevance of responses.
LangChain provides a variety of components that can be seamlessly integrated with Ollama models. Here we will show how to use the Ollama model in conjunction with a vector store and a retriever to create a simple RAG question and answer system.
First you need to make sure that the embedding model is downloaded, which can be done by executing the following command at the command line:
ollama pull nomic-embed-text
We can then build the RAG system:
# 初始化 Ollama 模型和嵌入
llm = ChatOllama(model="llama3.1")
embeddings = OllamaEmbeddings(model="nomic-embed-text")
# 准备文档
text = """
Datawhale 是一个专注于数据科学与 AI 领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。
Datawhale 以" for the learner,和学习者一起成长"为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。
同时 Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。
如果你想在Datawhale开源社区发起一个开源项目,请详细阅读Datawhale开源项目指南[https://github.com/datawhalechina/DOPMC/blob/main/GUIDE.md]
"""
# 分割文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
chunks = text_splitter.split_text(text)
# 创建向量存储
vectorstore = FAISS.from_texts(chunks, embeddings)
retriever = vectorstore.as_retriever()
# 创建提示模板
template = """只能使用下列内容回答问题:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# 创建检索-问答链
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
)
# 使用链回答问题
question = "我想为datawhale贡献该怎么做?"
response = chain.invoke(question)
This RAG system works as follows:
- Text segmentation: use the
RecursiveCharacterTextSplitterSplit long text into smaller chunks. - Vectorization and indexing: using
OllamaEmbeddingsConverts a block of text to a vector and creates a vector index with FAISS. - Retrieval: When a question is received, the system vectorizes the question and retrieves the most relevant block of text in the FAISS index.
- Generating Answers: the retrieved relevant text chunks are provided to the language model along with the original question to generate the final answer.
The RAG system is very useful in many real-life scenarios, for example:
- Customer service: customer inquiries can be answered quickly based on the company's knowledge base.
- Research Aid: Helps researchers quickly find relevant literature and summarize key information.
- Personal Assistant: Combines personal notes and web information to provide personalized information retrieval and suggestions.
reach a verdict
With these examples, we show how to use Ollama and LangChain to build a variety of AI applications, ranging from simple dialog systems to complex RAG Q&A systems. These tools and techniques provide a solid foundation for developing powerful AI applications.
The combination of Ollama and LangChain provides developers with great flexibility and possibilities. You can choose the right models and components according to your specific needs and build an AI system that suits your application scenario.
As the technology continues to evolve, we expect to see more innovative applications emerge. Hopefully, this guide will help you get started on your AI development journey and inspire your creativity to explore the endless possibilities of AI technology.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...