MoshiVis: an open source model for real-time speech dialog and image understanding

General Introduction
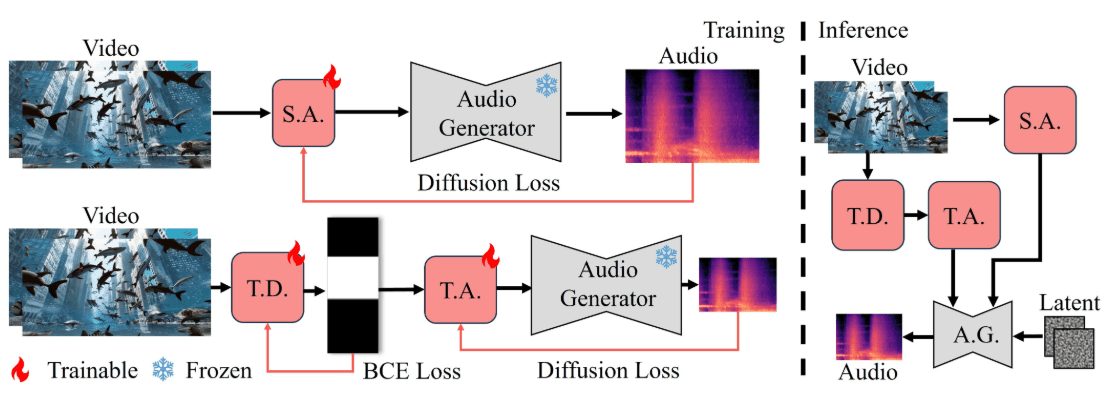
MoshiVis is an open source project developed by Kyutai Labs and hosted on GitHub. It is based on the Moshi speech-to-text model (7B parameters), with about 206 million new adaptation parameters and a frozen PaliGemma2 visual encoder (400M parameters), which allows the model to discuss image content with the user in real-time using speech.The core features of MoshiVis are low-latency, natural dialog, and image comprehension capabilities. It supports PyTorch, Rust and MLX backends, and users can download the code and model weights for free to run on their local devices. The project is aimed at developers and researchers, and is suitable for exploring AI interactions or developing new applications.

Function List
- Support real-time voice input and output, the model responds quickly after the user speaks.
- Ability to analyze the content of an image and describe the details of the image in speech or text.
- PyTorch, Rust, and MLX backends are available for different hardware.
- Open source code and model weights, allowing users to modify them freely.
- Low-latency design for real-time dialog scenarios.
- Supports quantization formats (e.g., 4-bit, 8-bit) to optimize memory and performance.
- Built-in cross-attention mechanism to fuse visual and speech information.
Using Help
MoshiVis requires some technical skills to install and use. Detailed official instructions are provided, and the following is a complete guide to installation and operation.
Installation process
MoshiVis supports three backend runs, allowing users to choose the appropriate version for their device. Minimum requirements include Python 3.10+, and enough RAM (24GB GPU is recommended for the PyTorch version, and the MLX version is suitable for Macs).
PyTorch Backend Installation
- Install the dependencies:
pip install -U moshi
- Download the model weights and start the service:
cd kyuteye_pt
python -m moshi.server --hf-repo kyutai/moshika-vis-pytorch-bf16 --port 8088
- interviews
https://localhost:8088, enter the web interface. - If running remotely, you need to use SSH to forward the port:
ssh -L 8088:localhost:8088 user@remote
Rust Backend Installation
- Install the Rust toolchain (via
rustup(Access). - Configure GPU support (Metal for Mac, CUDA for NVIDIA).
- Run the service:
cd kyuteye_rs
cargo run --features metal --bin moshi-backend -r -- --config configs/config-moshika-vis.json standalone --vis
- Once you see "standalone worker listening", visit the
https://localhost:8088The - Optional quantized version:
cargo run --features metal --bin moshi-backend -r -- --config configs/config-moshika-vis-q8.json standalone --vis
MLX Backend Installation (Mac Recommended)
- Install the MLX dependency:
pip install -U moshi_mlx
- Startup service (supports multiple quantization formats)
cd kyuteye_mlx
python -m moshi_mlx.server # 默认 BF16
python -m moshi_mlx.server -q 4 # 4 位量化
python -m moshi_mlx.server -q 8 # 8 位量化
- interviews
http://localhost:8008Use the web interface.
Front-end Installation
- Download the pre-built client:
pip install fire rich huggingface_hub
python scripts/get_static_client.py
- Generate an SSL certificate (for HTTPS):
openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout key.pem -out cert.pem
- The back-end provides a web interface by default, with no additional operations required.
Main Functions
real time voice dialog
- move: After starting the service, open the web interface (
https://localhost:8088maybehttp://localhost:8008). Click on the microphone icon to start talking. - typical example: Say "Hello" and the model will respond with a female voice (Moshika) "Hello, how can I help you?". .
- particulars: Latency as low as milliseconds to ensure microphone privileges are enabled.
- align: The Rust version supports a command line interface:
cd kyuteye_rs
cargo run --bin moshi-cli -r -- tui --host localhost
graphic understanding
- move: Upload an image in the web interface, or specify a path with a command line:
python -m moshi_mlx.server -q 8 --image path/to/image.jpg
- manipulate: After uploading, say "What is this?" The model will describe it phonetically, e.g. "It's a picture of a blue sky with white clouds".
- distinctiveness: Based on the PaliGemma2 encoder, it recognizes objects, colors and scenes.
Model Customization
- move: Download other weights from Hugging Face (e.g.
kyutai/moshika-vis-mlx-bf16), replace the path in the configuration file. - manipulate: Modification
configs/moshika-vis.yamlmaybeconfig-moshika-vis.json, restart the service. - use: Adjust voice style or optimize performance.
Full Operation Procedure
- Select Backend: Pick PyTorch (GPU), Rust (cross-platform), or MLX (Mac) depending on your device.
- installation environment: Install the dependencies and models as described above.
- Starting services: Run the backend and wait for the service to be ready.
- Connection Interface: Access the specified port with your browser.
- test voice: Say simple sentences and check responses.
- Test Image: Upload pictures and ask questions by voice.
- Optimized settings: Adjust the quantization parameters (
-q 4maybe-q 8) or port number.
caveat
- HTTPS requires an SSL certificate, otherwise browsers may restrict microphone access.
- Quantization is not supported in PyTorch and requires a high-performance GPU.
- The Rust version takes time to compile, so be patient when running it for the first time.
- MLX version tested stable on M3 MacBook Pro, recommended for Mac users.
application scenario
- Educational support
Students upload textbook images, and MoshiVis explains the content using audio, e.g., "This is a diagram of a cell structure, showing the nucleus and mitochondria." - Accessibility assistance
Visually impaired users upload daily photos of their models describing "this is a supermarket shelf full of milk and bread". - development experiment
Developers use it to build voice assistants that are integrated into smart devices for image interaction.
QA
- Does MoshiVis support offline use?
Yes. Once installed, all functions run locally without the need for an internet connection. - Does Voice support multiple languages?
Currently supports mainly English dialog and descriptions, with limited functionality in other languages. - Will a low end computer work?
The MLX version runs on a regular Mac, and the PyTorch version requires 24GB of GPU memory.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...