MiniRAG: Simplified Retrieval Enhanced Generation Framework, Entity Graph Index Recall Relevant Text Blocks

General Introduction
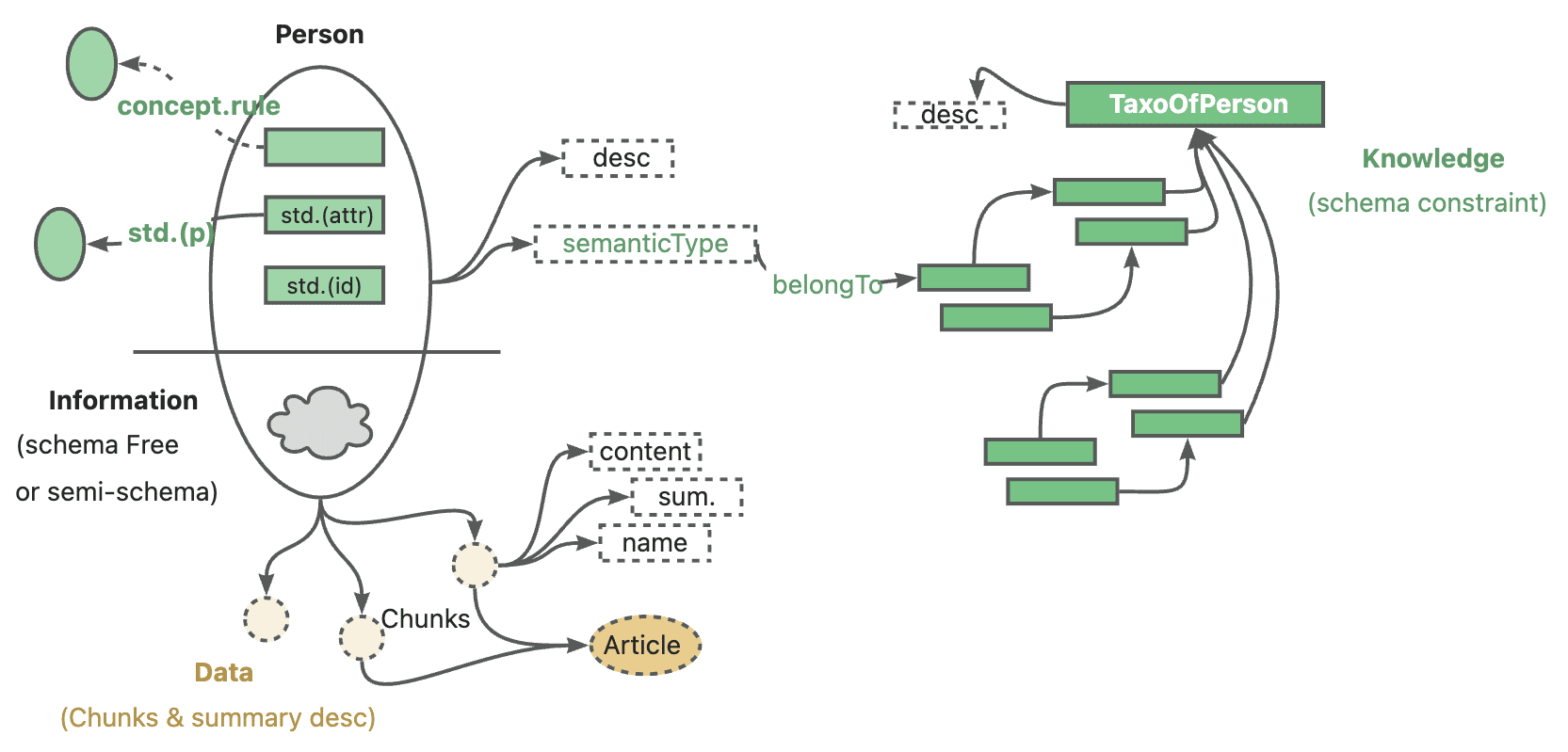
MiniRAG is an extremely simple Retrieval Augmented Generation (RAG) framework that aims to achieve good RAG performance even for small models through heterogeneous graph indexing and lightweight topology-enhanced retrieval. Developed by the Data Science Laboratory of the University of Hong Kong (HKUDS), the project focuses on solving the performance degradation problem faced by Small Language Models (SLMs) in existing RAG frameworks. miniRAG reduces the reliance on complex semantic understanding by combining text blocks and named entities in a unified structure, and utilizes graph structures for efficient knowledge discovery. The framework achieves comparable performance with only 251 TP3T of storage space of the Large Language Model (LLM) approach.

Function List
- Heterogeneous graph indexing mechanism: combining text blocks and named entities to reduce reliance on complex semantic understanding.
- Lightweight topology-enhanced retrieval: efficient knowledge discovery using graph structures.
- Compatible with small language models: provides efficient RAG performance in resource-constrained scenarios.
- Comprehensive benchmark dataset: the LiHua-World dataset is provided to evaluate the performance of lightweight RAG systems under complex queries.
- Easy installation: supports installation from source code and PyPI.
Using Help
Installation process
Installation from source (recommended)
- Cloning the MiniRAG repository:
git clone https://github.com/HKUDS/MiniRAG.git
cd MiniRAG
- Install the dependencies:
pip install -e .
Installation from PyPI
MiniRAG is based on LightRAG and can therefore be installed directly:
pip install lightrag-hku
Quick Start
- Download the desired dataset and place it in the
./datasetcatalog. For example, the LiHua-World dataset has been placed in the./dataset/LiHua-World/data/Catalog. - Use the following command to index the dataset:
python ./reproduce/Step_0_index.py
- Run the Q&A module:
python ./reproduce/Step_1_QA.py
- Alternatively, use the
./main.pyThe code in initializes the MiniRAG.
Main function operation flow
Heterogeneous graph indexing mechanism
MiniRAG creates heterogeneous graph indexes by combining text blocks and named entities in a unified structure. Users can achieve this by following the steps below:
- Prepare the dataset and ensure that the dataset is formatted as required.
- Run the indexing script:
python ./reproduce/Step_0_index.py
- After indexing is complete, the data will be stored in the specified directory for subsequent retrieval.
Lightweight Topology Enhanced Search
MiniRAG utilizes the graph structure for efficient knowledge discovery, and users can retrieve it through the following steps:
- Initialize the MiniRAG:
from minirag import MiniRAG
model = MiniRAG()
- Load the dataset and retrieve it:
results = model.retrieve("你的查询")
- Processes the search results and generates a response:
response = model.generate(results)
With the above steps, users can fully utilize MiniRAG's features for efficient search enhancement generation.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...