Ming-UniAudio - Ant open source unified audio multimodal generation model

What is Ming-UniAudio?
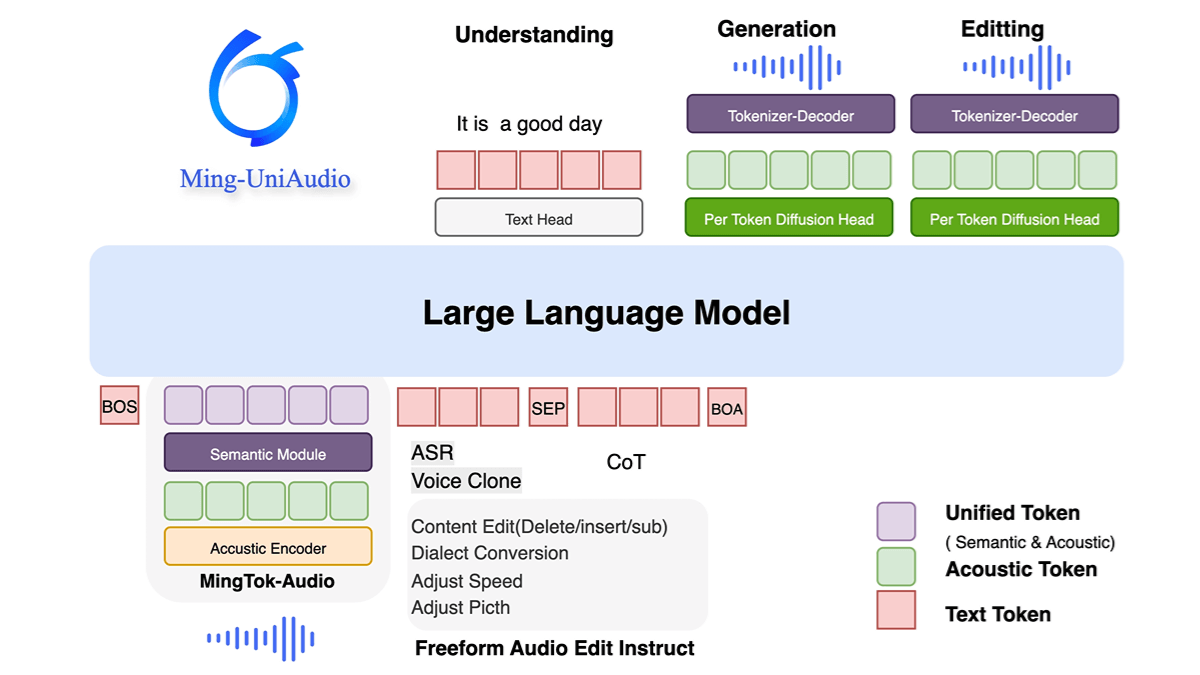
Ming-UniAudio is Ant Group's open source unified audio multimodal generation model that supports mixed input and output of text, audio, image and video. Adopting Multi-scale Transformer and Mixed Expert (MoE) architecture, it efficiently handles cross-modal information through modality-aware routing mechanism and significantly improves computational efficiency. The model performs well in speech synthesis, voiceprint cloning, multi-dialect generation, and audio-text cross-modal tasks, and is capable of high-quality real-time generation. The open-source nature of the model provides the research community with a scalable solution to promote the development of multimodal technology and practical application innovation.
Features of Ming-UniAudio
- Unified multimodal processing: Supports mixed input and generation of audio, text, images and video for unified cross-modal modeling and interaction.
- End-to-end speech synthesis and cloning: High-quality speech generation capability, supporting multi-dialect cloning and personalized voiceprint customization.
- Multi-mission joint training: Processing multiple audio types through discrete sequence tokenization, combined with LLM for joint training and fine-tuning, adapted to unseen tasks.
- Efficient Computing Architecture: Adopting multi-scale Transformer structure to optimize codec design and enhance generation efficiency and quality.
Core Advantages of Ming-UniAudio
- Unified multimodal processing capability: Supports mixed input and generation of audio, text, images, and video, enabling unified cross-modal modeling and interaction through a single model without the need to rely on multiple independent models.
- Efficient Computing ArchitectureThe multi-scale Transformer and MoE (Mixed Expert) design, combined with a modal-specific routing mechanism, significantly improves computational efficiency and resource utilization.
- High quality speech synthesis and cloning: Integrated advanced audio decoder supports multi-dialect speech generation, personalized voiceprint customization and real-time response, and excels in speech naturalness and adaptability.
- Multi-task co-optimization: Synchronized optimization of perceptual and generative tasks through discrete sequence tokenization and phased training strategies, reaching the leading level in benchmark tests such as audio comprehension and text generation.
- Open Source and Scalability: Fully open code and model weights to support further research and development in the community, and to promote the popularization of multimodal technology and application innovation.
What is Ming-UniAudio's official website?
- Project website:: https://xqacmer.github.io/Ming-Unitok-Audio.github.io/
- Github repository:: https://github.com/inclusionAI/Ming-UniAudio
- HuggingFace Model Library:: https://huggingface.co/inclusionAI/Ming-UniAudio-16B-A3B
People for whom Ming-UniAudio is suitable
- AI Research and Developers: A unified multimodal model is needed for audio, text, image and video hybrid processing and generation tasks.
- Speech technology applicators: Specializing in speech synthesis, voice cloning and multi-dialect generation, e.g., intelligent assistants, audio content creators.
- Multimodal Product Team: Seek efficient computational architectures and open source solutions to integrate perceptual and generative capabilities into real-world applications.
- Computing Resource Optimization Demanders: Focus on model efficiency, need to utilize MoE with modal routing mechanism to improve resource utilization.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...