
Ming-flash-omni-Preview - Ant Group's open source fully modal large models

What is Ming-flash-omni-Preview?
Ming-flash-omni-Preview is an open source full-modal large model released by Ant Group inclusionAI, with a parameter scale of hundreds of billions, based on the sparse MoE architecture of Ling 2.0, with total parameters of 103B and activations of 9B. it excels in full-modal understanding and generation, especially in controlled image generation, streaming video understanding, speech and dialect In particular, it has significant advantages in controlled image generation, streaming video understanding, speech and dialect recognition, and timbre cloning. The first "generative segmentation paradigm" realizes fine-grained spatial semantic control and highly controllable image generation; it can understand streaming video at a fine-grained level and provide explanations in real time; and in the field of speech, it supports context-aware speech comprehension and dialect recognition, and its comprehension ability of 15 Chinese dialects has been greatly improved, and its ability of timbre cloning has been significantly enhanced. The training architecture of the model is efficient, and the training throughput is improved by several optimizations.
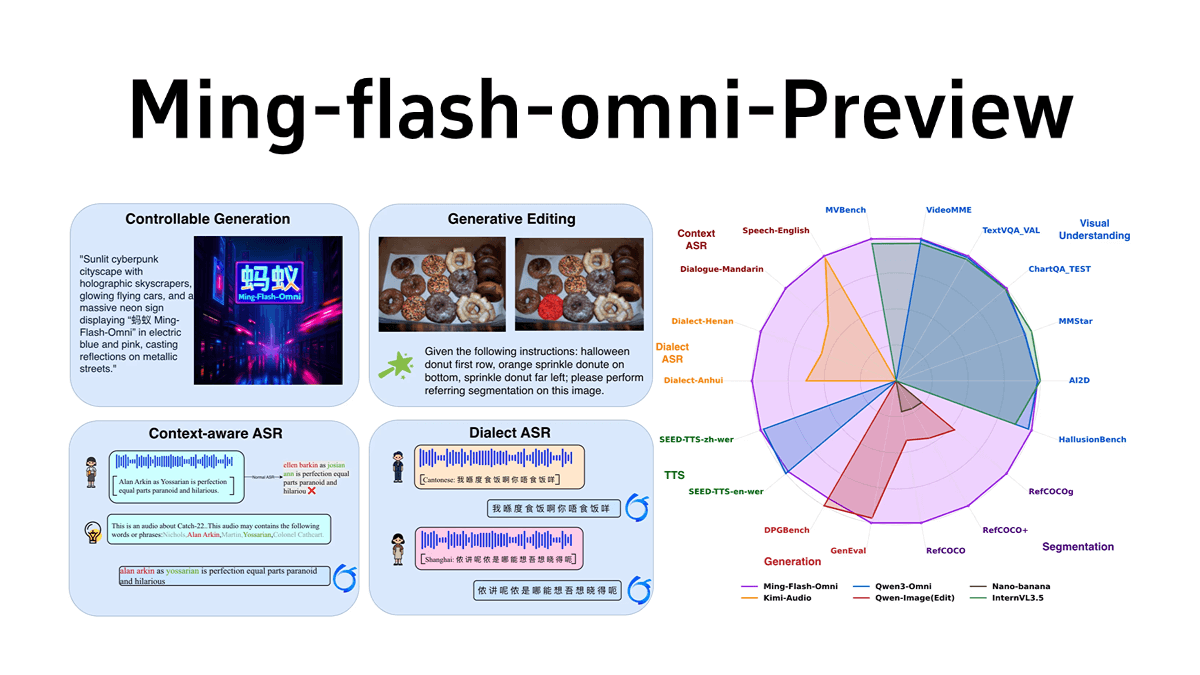
Features of Ming-flash-omni-Preview
- Full modal capability: Supports multiple modal inputs and outputs, including image, text, video and audio, with powerful multimodal comprehension and generation capabilities.
- Controlled image generationThe first "generative segmentation paradigm" realizes fine-grained spatial semantic control and significantly improves the controllability of image generation and editing.
- Streaming Video Understanding: enables fine-grained understanding of streaming video, provides descriptions of relevant objects and interactions in real time, and supports continuous dialog based on realistic scenarios.
- Phonetics and dialect understanding: Supports context-aware speech understanding (ContextASR) and dialect recognition, with greatly enhanced comprehension of 15 Chinese dialects.
- tone cloning: Upgraded speech generation capability, able to effectively clone the timbre of the original dialog into the newly generated dialog, with stable mixed Chinese and English pronunciation.
- Efficient Training FrameworkBased on the sparse MoE architecture, the training throughput is improved through several optimizations to achieve "large capacity and small activation" for each mode.
- Open Source and Community Support: The model and code are open source and resources can be found on GitHub, HuggingFace and ModelScope for developers to try out and give feedback.
Core Benefits of Ming-flash-omni-Preview
- 100 billion parameter size: As the first open-source full-modal large model with a parameter scale of hundreds of billions, it has powerful computational capabilities and rich semantic understanding.
- Sparse MoE ArchitectureThe sparse MoE architecture based on Ling 2.0 realizes "large capacity, small activation", which improves the performance and flexibility of the model while maintaining high computational efficiency.
- Multimodal Leadership Performance: Achieve the leading level of open-source full-modal models in multiple modal tasks such as image generation, video understanding, and speech recognition, and especially excel in controlled image generation and dialect recognition.
- Innovative Generative Segmentation ParadigmA collaborative training paradigm of "generative segmentation-as-editing" is proposed to reconstruct image segmentation as a semantics-preserving editing task, which significantly improves the controllability of image generation and editing quality.
- Efficient training and optimization: The problem of data heterogeneity and model heterogeneity in multimodal training is solved by techniques such as sequence packing and elastic encoder slicing, which dramatically improve the training throughput.
What is Ming-flash-omni-Preview's official website?
- GitHub repository: https://github.com/inclusionAI/Ming
- HuggingFace Model Library: https://huggingface.co/inclusionAI/Ming-flash-omni-Preview
Ming-flash-omni-Preview's Applicable Crowd
- Artificial intelligence researchers: Dedicated to multimodal research, the model can be used to explore new methods and application scenarios for multimodal fusion of image, video, and speech.
- development engineer: Those who wish to integrate multimodal functions in their projects, such as developing applications for intelligent video analysis, voice interaction, image generation, etc., can quickly realize them with its powerful multimodal capabilities.
- data scientist: Required to process and analyze multimodal data, it can be used for data preprocessing, feature extraction, etc., to improve the efficiency and quality of data processing.
- Product Designer: Focusing on user experience and product innovation, it can utilize its multimodal generation capabilities to design more creative and interactive product features.
- educator: It can be applied in the field of education, such as the development of intelligent educational software to enhance teaching effectiveness and interactivity through voice recognition, image generation and other functions.
- content creator: such as video producers, designers, writers, etc., can utilize its generative capabilities to quickly generate creative content and improve creative efficiency.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...