MiMo-VL - Xiaomi's open source multimodal modeling

What is MiMo-VL
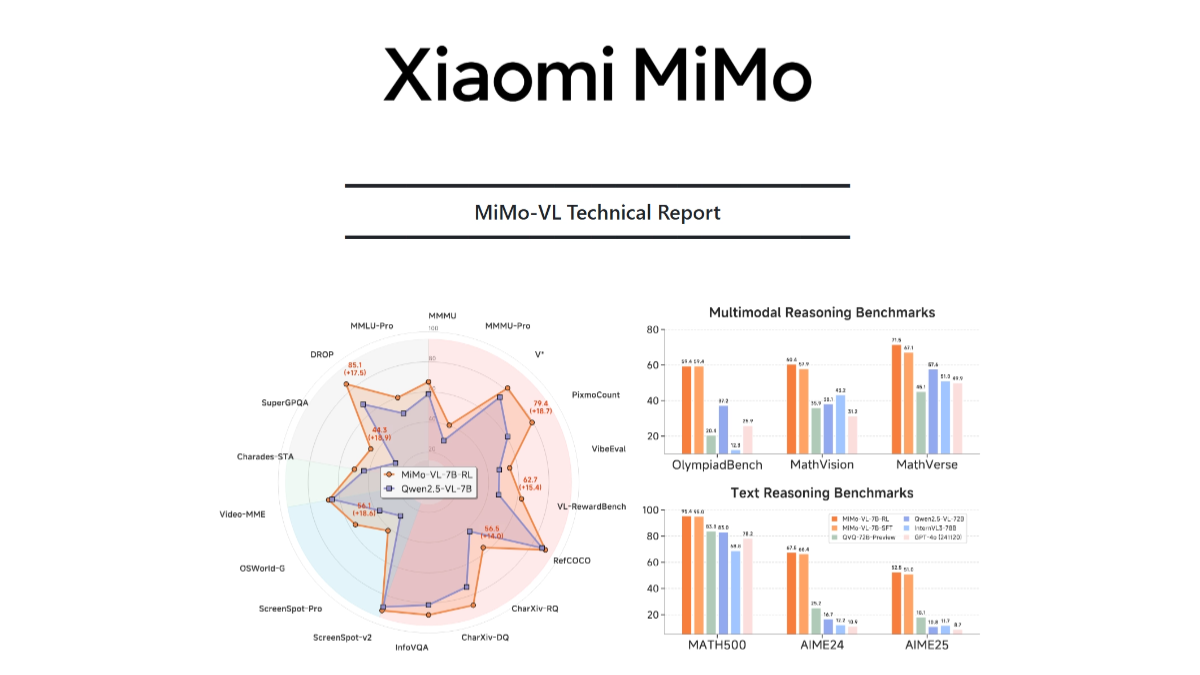
MiMo-VL is Xiaomi's open source multimodal grand model, which consists of a visual coder, a cross-modal projection layer and a language model. The visual coder is based on Qwen2.5-ViT, which supports native resolution input and preserves more details; the language model is Xiaomi's self-developed MiMo-7B, optimized for complex reasoning. The model is based on a multi-stage pre-training strategy, trained with 2.4T tokens of multimodal data, covering data types such as image-text pairs, video-text pairs, and GUI operation sequences. Based on the hybrid online reinforcement learning (MORL) algorithm, the model's inference, perceptual performance and user experience are improved in all aspects.MiMo-VL performs well in complex image inference, GUI interaction, video comprehension, and long document parsing, for example, it reaches 66.7% on MMMU-val, surpassing Gemma 3 27B; 59.4% on OlympiadBench 59.4% on OlympiadBench, surpassing the 72B model.
Key Features of MiMo-VL
- Complex Picture Reasoning and Quiz: Accurately understand the content of complex pictures giving reasonable explanations and answers.
- GUI operation and interaction: Supports up to 10+ steps of GUI operations to understand and execute complex instructions.
- Video and Language Understanding: Comprehend video content, reasoning and quizzing in conjunction with language.
- Long Document Parsing and Reasoning: Processing long documents for complex reasoning and information extraction.
- User Experience Optimization: Improving inference, perceptual performance and user experience based on hybrid online reinforcement learning.
MiMo-VL's official website address
- Github repository::https://github.com/XiaomiMiMo/MiMo-VL
- HuggingFace Model Library::https://huggingface.co/collections/XiaomiMiMo/mimo-vl
- Technical Papers::https://github.com/XiaomiMiMo/MiMo-VL/blob/main/MiMo-VL-Technical-Report
How to use MiMo-VL
- Hugging Face Platform::
- Access to the Hugging Face model library: Access to MiMo-VL'sHugging Face Model LibraryPage.
- Loading Models: Use Hugging Face's Python library to load the MiMo-VL model. Example:
from transformers import AutoModelForVision2Seq, AutoProcessor
model = AutoModelForVision2Seq.from_pretrained("XiaomiMiMo/mimo-vl")
processor = AutoProcessor.from_pretrained("XiaomiMiMo/mimo-vl")- Processing of input data: Input data such as images, videos or text are pre-processed based on the processor.
- Generate Output: Input the processed data into the model and obtain the output of the model.
- GitHub repository::
- Cloning GitHub repositories: AccessGitHub repository, clone the repository locally.
git clone https://github.com/XiaomiMiMo/MiMo-VL.git- Installation of dependencies: Install the required Python dependencies according to the requirements.txt file in the repository.
pip install -r requirements.txt- running code: Follow the instructions in the repository to run sample code or open an application.
MiMo-VL's Core Advantages
- Strong multimodal fusion capability: Processing multimodal data such as images, video and text to understand complex scenes.
- Excellent inference performance: Excellent performance in several benchmarks, such as 66.71 TP3T on MMMU-val and 59.41 TP3T on OlympiadBench.
- User Experience Optimization: Based on Mixed Online Reinforcement Learning (MORL), the model behavior is dynamically adjusted based on user feedback to enhance user experience.
- Wide range of application scenarios: Applicable to many fields such as smart customer service, smart home and research.
- Open Source and Community Support: Open source code and community support are provided to facilitate developer research and development.
Individuals eligible for MiMo-VL
- AI researchers: Focuses on research in the areas of multimodal fusion, complex reasoning, and vision and language understanding.
- Developers and engineers: Developing smart applications such as smart customer service, smart home, smart healthcare, etc. requires the integration of multimodal functionality.
- data scientist: Processing and analyzing multimodal data to improve model performance and data processing efficiency.
- Educators and students: Aids in teaching and learning, such as math problem solving and programming learning.
- Medical professionals: Assisting medical image analysis and text comprehension to improve diagnostic efficiency and accuracy.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts

No comments...