MediaCrawler: Multi-social media platform content, video comment crawler tool

General Introduction
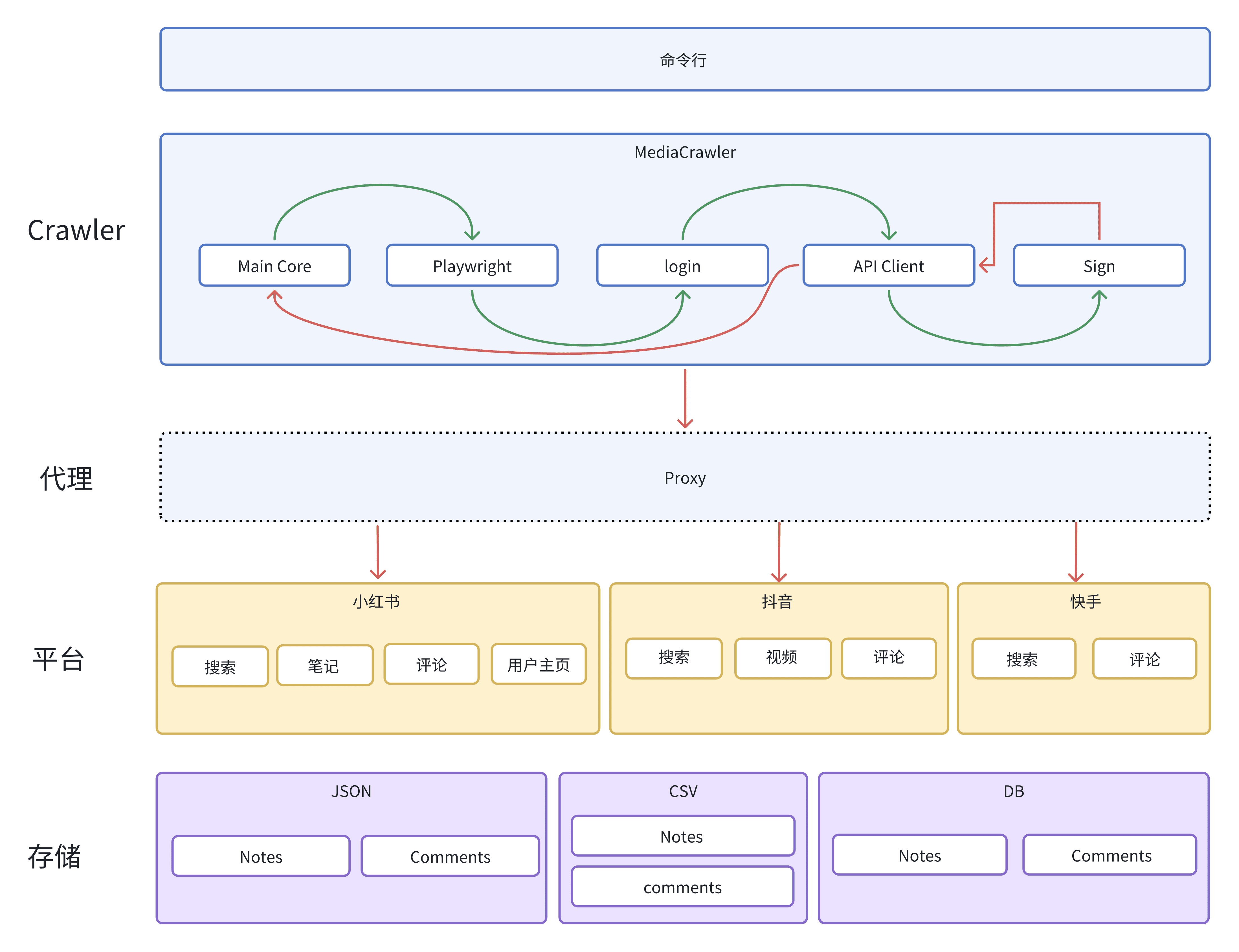
MediaCrawler is a social media content crawler tool designed for developers. By providing a powerful crawler function, it can quickly grab videos, images, comments, likes, retweets and other data from social platforms such as Xiaohongshu, Jieyin, Shutterbugs, B-station, Weibo and so on. This tool uses Playwright as a bridge, preserving the browser environment after login, and obtaining encrypted parameters by executing JS expressions, thus simplifying the difficulty of complex reverse engineering.
For professional use only, please note that data collection needs to be done within the scope of authorization.
Function List
Support platforms such as Xiaohongshu, Jieyin, Shutterbug, B Station, Weibo, etc.
Provide cookie login, QR code login, cell phone number login and other methods
Support keyword search and specified video/post ID crawling function
Login state caching and IP proxy pool support
Provide slider CAPTCHA solutions (some platforms)
| flat-roofed building | Keyword Search | Specify post ID to crawl | Secondary comments | Designated Creator Home Page | Login State Cache | IP proxy pool | Generate comment word clouds |
|---|---|---|---|---|---|---|---|
| Little Red Book (social networking website) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| jitterbug | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| violin | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Station B | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| microblog | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| electronic message board | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Using Help
Create and activate a Python virtual environment
Install the dependencies: Use the `pip install -r requirements.txt` command.
To install the Playwright browser driver: Use the `playwright install` command.
To run the crawler: use a command line argument such as `python main.py --platform xhs --lt qrcode --type search`.
Use `python main.py --help` to see examples of crawlers for other platforms.
Check out the project code structure and answer more questions on the GitHub repository.
Learning Materials
https://relakkes.feishu.cn/wiki/JUgBwdhIeiSbAwkFCLkciHdAnhh
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...