
Logics-Parsing - Ali open source document parsing model

What is Logics-Parsing
Logics-Parsing is Ali open source end-to-end document parsing model , based on Qwen2.5-VL-7B. Optimize document layout analysis and reading order inference through reinforcement learning , PDF images can be converted to structured HTML output , support for a variety of content types , including ordinary text , mathematical formulas , tables , chemical formulas and handwritten Chinese characters . The model is trained in two phases: the first phase is supervised fine-tuning to learn to generate structured output; the second phase is layout-centric reinforcement learning to optimize text accuracy, layout positioning and reading order. It performs well in the LogicsParsingBench benchmark, especially outperforming other methods in plain text, chemical structure and handwritten content parsing.
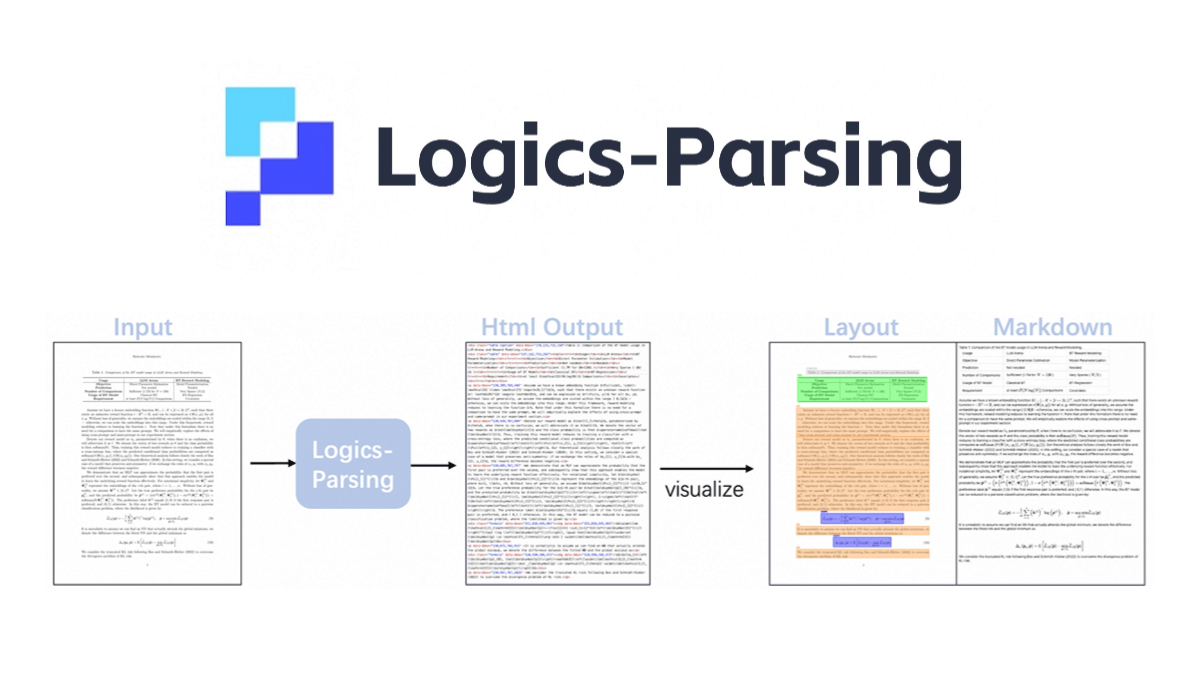
Features of Logics-Parsing
- end-to-end resolution capability: Generate structured HTML output directly from document images without complex multi-stage pipelines.
- Advanced Content Recognition: Accurately recognize complex content such as mathematical formulas, chemical structures and handwritten Chinese characters.
- Structured Output: The generated HTML retains the logical structure of the document, with detailed tags and coordinates for each content block.
- Automatic removal of irrelevant elements: Automatically filter irrelevant elements such as headers and footers to focus on the core content.
- Enhanced Learning Optimization: Optimize layout analysis and reading order to improve parsing accuracy through intensive study.
- High performance: Outperforms other existing methods on a wide range of complex document types.
- Simple deployment and reasoning: The model weights can be quickly downloaded from the command line after installation and inference operations can be performed.
Logics-Parsing's Core Benefits
- high accuracy: Excellent performance and high accuracy on a wide range of document types and complex content.
- end-to-end analysis: Streamline the process by generating structured output directly from document images without the need for a multi-stage pipeline.
- Strong ability to handle complex content: The ability to accurately recognize and parse complex content such as mathematical formulas, chemical structures, and handwritten Chinese.
- Structured Output: The resulting HTML output preserves the logical structure of the document for subsequent processing and application.
- Automatic filtering of irrelevant elements: Automatically recognizes and removes extraneous content such as headers and footers to focus on the core message.
- Enhanced Learning Optimization: Optimize layout analysis and reading order through reinforcement learning to improve overall performance.
What is Logics-Parsing's official website?
- Github repository:: https://github.com/alibaba/Logics-Parsing
- HuggingFace Model Library:: https://huggingface.co/Logics-MLLM/Logics-Parsing
- arXiv Technical Paper:: https://arxiv.org/pdf/2509.19760
Who Logics-Parsing is for?
- (scientific) researcher: Used to parse academic papers and scientific reports to extract key information.
- educator: Handle instructional materials, test papers, handwritten notes, etc., to support teaching and learning.
- Corporate Analyst: Parsing business documents, reports, and extracting data and information.
- data scientist: Handle large amounts of document data for data mining and analysis.
- Document Processing Engineer: Develop a document processing system to enhance automation.
- schoolchildren: Assisted learning, parsing textbooks and notes to improve study efficiency.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles



No comments...