
LLaVA-OneVision-1.5 - Free and open source multimodal modeling, high performance multimodal understanding

What is LLaVA-OneVision-1.5?
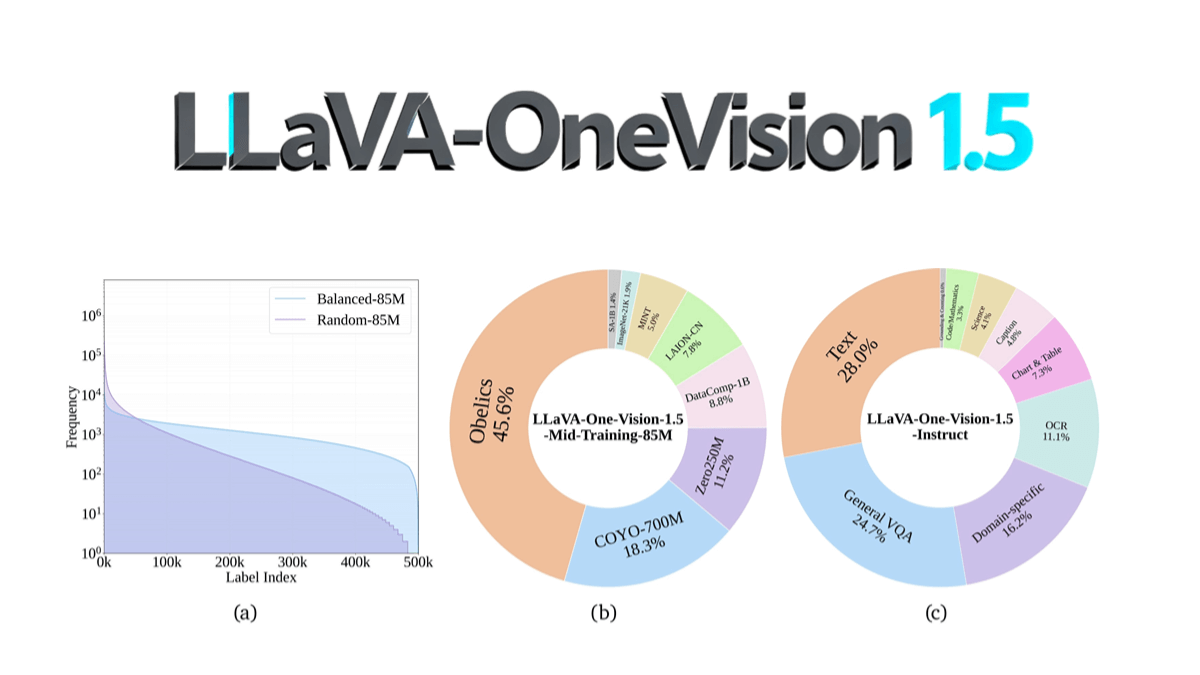
LLaVA-OneVision-1.5 is an open-source multimodal model from the EvolvingLMMS-Lab team that was pre-trained in 4 days on 128 A800 GPUs at a total cost of ~$16K through a compact 3-phase training process (language-image alignment, conceptual equalization and knowledge injection, and instruction fine-tuning) using a parameter scale of 8B. Core innovations include the RICE-ViT visual encoder's support for native resolution and region-level fine-grained semantic modeling, as well as optimized data utilization through a "concept equalization" strategy. It outperforms Qwen2.5-VL in OCR, document understanding, and other tasks, and for the first time realizes full open source (including data, training toolchain, and evaluation scripts), significantly lowering the threshold of multimodal model reproduction. The model code has been published in GitHub, supporting low-cost reproduction and secondary development by the community.
Features of LLaVA-OneVision-1.5
- High-performance multimodal understanding: Efficiently processes and understands image and text information to generate accurate descriptions and answers for a wide range of complex scenarios.
- Efficient Training and Low Cost: Using optimized training strategies and data packing techniques to significantly reduce training costs while maintaining high performance.
- Strong command compliance: It can accurately understand and execute user commands, has good task generalization ability, and can be applied to a variety of multimodal tasks.
- High-quality data-driven: Ensure that the model learns rich knowledge and semantic information through carefully constructed pre-training and instruction fine-tuning datasets.
- Flexible input resolution support: The visual encoder supports variable input resolution, eliminating the need for resolution-specific fine-tuning and adapting to different image size requirements.
- Regional perceptual attention mechanisms: Enhancing semantic understanding of localized regions in an image through a region-aware attention mechanism to improve the model's ability to capture details.
- Multi-language supportSupport multi-language input and output, with cross-language comprehension and generation capabilities, to adapt to the needs of internationalized applications.
- Transparent and open framework: Provide complete code, data, and modeling resources to ensure low-cost reproduction and verifiable extensions for the community, facilitating academic and industrial applications.
- ability to recognize the long tail: Categories or concepts that occur less frequently in the data can also be effectively identified and understood, improving the generalization ability of the model.
- Cross-modal search function: Support text-based query image or image-based query text to realize efficient cross-modal information retrieval.
Core Benefits of LLaVA-OneVision-1.5
- high performance: Performs well in multimodal tasks, efficiently processing image and text information to produce high-quality output.
- inexpensive: Significantly reduces training costs and improves cost-effectiveness through optimized training strategies and data packing techniques.
- highly reproducible: Providing complete code, data, and training scripts ensures that the community can cost-effectively reproduce and validate model performance.
- Efficient training: Offline parallel data packing and hybrid parallel techniques are used to improve the training efficiency and reduce the waste of computational resources.
- High-quality data: A large-scale and high-quality pre-training and instruction fine-tuning dataset was constructed to ensure that the model learns rich semantic information.
- Flexible input support: The visual encoder supports variable input resolution, eliminating the need for resolution-specific fine-tuning and adapting to different image size requirements.
- Area-awareness capability: Enhanced semantic understanding of localized regions in images and improved detail capture through region-aware attention mechanism.
What is the official website for LLaVA-OneVision-1.5?
- Github Address:: https://github.com/EvolvingLMMs-Lab/LLaVA-OneVision-1.5
- HuggingFace Model Library:: https://huggingface.co/collections/lmms-lab/llava-onevision-15-68d385fe73b50bd22de23713
- arXiv Technical Paper:: https://arxiv.org/pdf/2509.23661
- Online Experience Demo:: https://huggingface.co/spaces/lmms-lab/LLaVA-OneVision-1.5
People for LLaVA-OneVision-1.5
- research worker: Scholars working on multimodal learning, computer vision, and natural language processing can use the model for cutting-edge research and algorithm development.
- developers: Software engineers and application developers can integrate LLaVA-OneVision-1.5 in a variety of applications to develop intelligent customer service, content recommendation, and other features.
- educator: Teachers and educational technologists who can use it in education to assist teaching and learning, such as image interpretation and multimedia content creation.
- Medical professionals: Doctors and medical researchers, can be used for medical image analysis and assisted diagnosis to improve medical efficiency and accuracy.
- content creator: Writers, designers, and media producers use the model to generate creative content, copy, and graphic descriptions to improve creative efficiency.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...