LLaSO - The Industry's First Fully Open Source Speech Model from Logic Intelligence

What is LLaSO?
LLaSO is an open source speech model launched by Beijing Depth Logic Intelligent Technology Co., Ltd. which solves the problems of data dispersion and insufficient task coverage in the field of large-scale speech language models by integrating speech and text data and providing alignment datasets, command fine-tuning datasets and evaluation benchmarks.LLaSO supports a variety of interaction modes, including the combination of text commands and audio inputs, and audio commands and text inputs, etc. It can be widely used in intelligent speech assistants, education and learning, medical and health care, etc. etc. It can be widely used in intelligent voice assistants, voice content creation, education and learning, medical and health care, etc. It promotes the transformation of speech technology from fragmentation to collaborative innovation, and provides strong support for speech language model research and application.
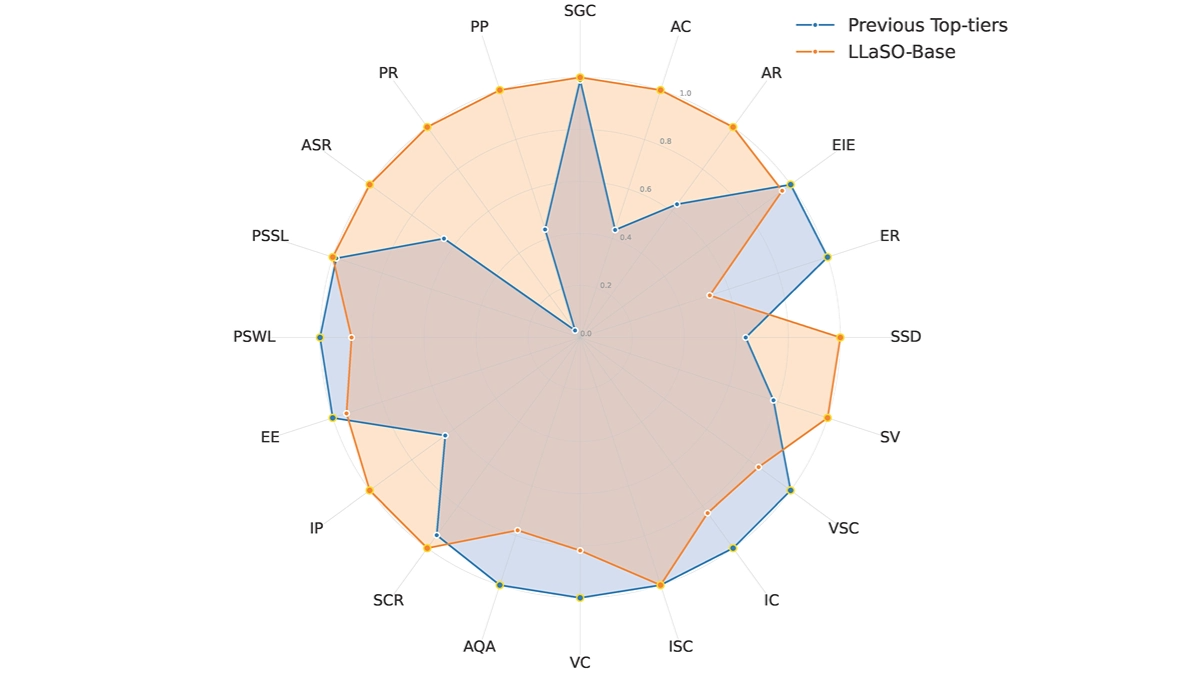
Features of LLaSO
- The data set provides: LLaSO provides large-scale speech-text alignment datasets, which provide rich data resources for model training and help the model better learn the correspondence between speech and text.
- Multitasking command fine-tuning: Fine-tuning the model with multi-task data, covering linguistic, semantic and paralinguistic tasks, improves the model's comprehensive understanding and generation capabilities so that it can better handle complex linguistic tasks.
- Standardized assessment benchmarks: LLaSO provides standardized evaluation benchmarks to ensure fairness and reproducibility of model evaluations, facilitating researchers to compare and validate the performance of different models.
- multimodal supportLLaSO supports a variety of modal interactions, including "text command + audio input", "audio command + text input" and audio-only interactions, expanding the model's application scenarios and making it adaptable to more practical application needs.
LLaSO's core strengths
- open source: As the world's first fully open-source speech model, the open-source feature enables researchers and developers to freely access, use and improve the model, greatly facilitating technology sharing and innovation.
- Unified infrastructure: By providing a unified dataset, model training, and evaluation benchmarks, LLaSO addresses the long-standing problems of architectural fragmentation and data privatization in the field of large-scale speech-language modeling, and provides researchers with a standardized development environment.
- Multimodal interaction capabilities: The model supports multi-modal interactions, which can be better adapted to different application scenarios and user needs, e.g., in the fields of intelligent voice assistants, education and healthcare, multi-modal interactions can provide a more natural and efficient user experience.
- Balancing Performance and Efficiency: While maintaining high performance, LLaSO focuses on the efficiency and scalability of the model, which can run efficiently on different hardware platforms, reducing deployment costs and improving the practicality of the model.
- Promoting collaborative innovation in the industry: The launch of the model helps to promote collaborative innovation in the entire speech-language modeling field, and accelerates the development of the technology and the landing of the application by providing an open platform and encouraging more researchers and developers to participate in the improvement of the model and the development of the application.
What is the official website of LLaSO
- GitHub repository:: https://github.com/EIT-NLP/LLaSO
- HuggingFace Model Library:: https://huggingface.co/papers/2508.15418
- arXiv Technical Paper:: https://arxiv.org/pdf/2508.15418v1
Who LLaSO is for
- Artificial intelligence researchers: Provide rich open source datasets and standardized evaluation benchmarks for speech and natural language processing research, fueling academic research and technological innovation.
- developers: Provides developers with powerful tools to build smart voice applications and accelerate product development and optimization.
- Businesses and Entrepreneurs: Helping companies to quickly develop speech-related products and entrepreneurs to validate and land speech projects at low cost.
- Educators and students: Provide rich voice interaction tools for the education sector to help educators develop personalized teaching applications where students can learn languages and practice pronunciation.
- healthcare practitioner: Provides healthcare practitioners with efficient tools to improve medical efficiency and patient recovery.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...