
Llama 3: A Versatile, Open Source Family of AI Models

Abstracts.
This paper introduces a new set of base models called Llama 3. Llama 3 is a community of language models that inherently supports multilingualism, code writing, reasoning, and tool usage. Our largest model is a dense Transformer with 405 billion parameters and a context window of up to 128,000 tokens.In this paper, we perform a wide range of empirical evaluations of Llama 3. The results show that Llama 3 is able to achieve quality comparable to leading language models such as GPT-4 on many tasks. We make Llama 3 publicly available, including pre-trained and post-trained 405 billion parameter language models, as well as the Llama Guard 3 model for input-output security. This paper also presents experimental results on integrating image, video, and speech features into Llama 3 through a combinatorial approach. We observe that this approach is competitive with state-of-the-art approaches for image, video and speech recognition tasks. Since these models are still in the development phase, they have not been widely published.
Full text download pdf:
1722344341-Llama_3.1 paper: a versatile, open-source _AI_ modeling family (Chinese version)
1 Introduction
basic modelare generalized models of language, vision, speech, and other modalities designed to support a wide range of AI tasks. They form the basis of many modern AI systems.
The development of modern base models is divided into two main stages:
(1) Pre-training phase. Models are trained on massive amounts of data, using simple tasks such as word prediction or graph annotation generation;
(2) Post-training phase. Models are fine-tuned to follow instructions, align with human preferences, and improve specific capabilities (e.g., coding and reasoning).
This paper introduces a new set of language base models called Llama 3. The Llama 3 Herd family of models inherently supports multilingualism, encoding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters, capable of processing information in context windows of up to 128K tokens.
Table 1 lists each member of the flock. All results presented in this paper are based on the Llama 3.1 model (Llama 3 for short).
We believe that the three key tools for developing high-quality base models are data, scale, and complexity management. We will strive to optimize all three during our development process:
- Data. Both the quantity and quality of data we used in pre-training and post-training were improved compared to previous versions of Llama (Touvron et al., 2023a, b). These improvements include the development of more careful pre-processing and curation pipelines for pre-training data and the development of more rigorous quality assurance and filtering. of more careful pre-processing and curation pipelines for pre-training data and the development of more rigorous quality assurance and filtering Llama 3 was pretrained on a corpus of about 15T multilingual tokens, while Llama 2 was pretrained on 1.8T tokens.
- Scope. We trained a larger model than the previous Llama model: our flagship language model uses a 3.8 × 1025 FLOPs for pre-training, nearly 50 times more than the largest version of Llama 2. Specifically, we pre-trained a flagship model with 405B trainable parameters on 15.6T text tokens. As expected, the

- Managing complexity. We made design choices aimed at maximizing the scalability of the model development process. For example, we chose a standard dense Transformer model architecture (Vaswani et al., 2017) with some minor adjustments, rather than using an expert mixture model (Shazeer et al., 2017) to maximize training stability. Similarly, we employed a relatively simple post-processor based on supervised fine-tuning (SFT), rejection sampling (RS), and direct preference optimization (DPO; Rafailov et al. (2023)) instead of more complex reinforcement learning algorithms (Ouyang et al., 2022; Schulman et al., 2017), which tend to be less stable and difficult to scale.
The result of our work is Llama 3: a three-language multilingual with 8B, 70B, and 405B parameters.1population of language models. We evaluated the performance of Llama 3 on a large number of benchmark datasets covering a wide range of language understanding tasks. In addition, we performed extensive manual evaluations comparing Llama 3 to competing models. Table 2 shows an overview of the performance of the flagship Llama 3 model in key benchmark tests. Our experimental evaluations show that our flagship model is on par with leading language models such as GPT-4 (OpenAI, 2023a) and close to the state-of-the-art on a variety of tasks. Our smaller model is best-in-class and outperforms other models with similar number of parameters (Bai et al., 2023; Jiang et al., 2023).Llama 3 also strikes a better balance between helpfulness and harmlessness than its predecessor (Touvron et al., 2023b). We analyze the safety of Llama 3 in detail in Section 5.4.
We publicly release all three Llama 3 models under an updated version of the Llama 3 community license; see https://llama.meta.com. This includes pre-training and post-processing versions of our 405B parametric language model, as well as a new version of the Llama Guard model (Inan et al., 2023) for input and output security. We hope that the public release of a flagship model will inspire a wave of innovation in the research community and accelerate progress toward the responsible development of Artificial Intelligence (AGI).
Multilingual: This refers to the ability of the model to understand and generate text in multiple languages.
During the development of Llama 3, we have also developed multimodal extensions to the model to enable image recognition, video recognition and speech understanding. These models are still under active development and are not yet ready for release. In addition to our language modeling results, this paper presents the results of our initial experiments with these multimodal models.
Llama 3 8B and 70B were pre-trained on multilingual data, but were mainly used for English at that time.

2 General
The Llama 3 model architecture is shown in Figure 1. The development of our Llama 3 language model is divided into two main phases:
- Language model pre-training.We first convert a large multilingual text corpus into discrete tokens and pre-train a large language model (LLM) on the resulting data for the next token prediction. In the LLM pre-training phase, the model learns the structure of the language and acquires a large amount of knowledge about the world from the text it "reads". In order to do this efficiently, the pre-training is done at a large scale: we pre-trained a model with 405B parameters on a model with 15.6T tokens, using a context window of 8K tokens. This standard pre-training phase is followed by a continued pre-training phase, which increases the supported context window to 128K tokens. See Section 3 for more information.
- Post-model training.The pre-trained language model has a rich understanding of the language, but it has not yet followed instructions or behaved like the assistant we expect it to. We calibrated the model with human feedback in several rounds, each including supervised fine-tuning (SFT) and direct preference optimization (DPO; Rafailov et al., 2024) on instruction-tuned data. In this post-training phase, we also integrated new features, such as tool usage, and observed significant improvements in areas such as coding and inference. For more information, see Section 4. Finally, security mitigations are also integrated into the model in the post-training phase, the details of which are described in Section 5.4. The generated models are rich in functionality. They are capable of answering questions in at least eight languages, writing high-quality code, solving complex inference problems, and using tools out-of-the-box or in a zero-sample manner.
We also conduct experiments to add image, video, and speech capabilities to Llama 3 through a combined approach. The approach we investigate consists of three additional phases shown in Figure 28:

- Multimodal encoder pretraining.We train separate encoders for image and speech. We train the image encoder on a large number of image-text pairs. This allows the model to learn the relationship between visual content and its natural language description. Our speech encoder uses a self-supervised method that masks a portion of the speech input and attempts to reconstruct the masked portion through a discrete labeled representation. Thus, the model learns the structure of the speech signal. See Section 7 for more information on image encoders and Section 8 for more information on speech encoders.
- Visual adapter training.We train an adapter that integrates a pre-trained image encoder with a pre-trained language model. The adapter consists of a series of cross-attention layers that feed the image encoder representation into the language model. The adapter is trained on text-image pairs, which aligns the image representation with the language representation. During adapter training, we also update the parameters of the image encoder, but intentionally do not update the parameters of the language model. We also train a video adapter on top of the image adapter, using paired video-text data. This allows the model to aggregate information across frames. For more information, see Section 7.
- Finally, we integrate the speech encoder into the model via an adapter that converts the speech coding into a tokenized representation that can be fed directly into the fine-tuned language model. During the supervised fine-tuning phase, the parameters of the adapter and the encoder are jointly updated to achieve high-quality speech understanding. We do not change the language model during speech adapter training. We also integrate a text-to-speech system. See Section 8 for more details.
Our multimodal experiments have led to models that recognize the content of images and videos and support interaction through a speech interface. These models are still under development and are not yet ready for release.
3 Pre-training
Pre-training of language models involves the following aspects:
(1) Collecting and filtering large-scale training corpora;
(2) Development of model architectures and corresponding scaling laws for model sizing;
(3) Development of techniques for efficient large-scale pre-training;
(4) Development of a pre-training program. We describe each of these components below.
3.1 Pre-training data
We create language model pre-training datasets from various data sources that contain knowledge up to the end of 2023. We applied several de-duplication methods and data cleaning mechanisms to each data source to obtain high-quality markup. We removed domains containing large amounts of personally identifiable information (PII), as well as domains known to contain adult content.
3.11 Web data cleansing
Most of the data we utilize comes from the web, and we describe our cleaning process below.
PII and Security Filtering. Among other measures, we have implemented filters designed to remove data from websites that may contain unsafe content or large amounts of PII from domains that are classified as harmful under various Meta security standards, as well as domains known to contain adult content.
Text Extraction and Cleaning. We process raw HTML content to extract high-quality, diverse text and use non-truncated web documents for this purpose. To do this, we built a custom parser that extracts HTML content and optimizes the precision of template removal and content recall. We assessed the quality of the parser through manual evaluation and compared it to popular third-party HTML parsers optimized for the content of similar articles and found it to perform well. We handle HTML pages containing math and code content with care to preserve the structure of that content. We keep the image alt attribute text because math content is usually represented as a pre-rendered image where the math is also provided in the alt attribute.
We found that Markdown was detrimental to the performance of models trained primarily on Web data compared to plain text, so we removed all Markdown tags.
De-weighting. We apply multiple rounds of de-duplication at the URL, document and line level:
- URL-level de-duplication. We perform URL-level de-duplication on the entire dataset. For each page corresponding to a URL, we keep the latest version.
- Document-level de-duplication. We perform global MinHash (Broder, 1997) de-duplication on the entire dataset to remove near-duplicate documents.
- Row-level de-duplication. We perform radical-level de-duplication similar to ccNet (Wenzek et al., 2019). We remove rows that occur more than 6 times in each group containing 30 million documents.
Although our manual qualitative analysis suggests that line-level de-duplication removes not only residual boilerplate content from a variety of sites (e.g., navigation menus, cookie warnings), but also frequent high-quality text, our empirical evaluations show significant improvements.
Heuristic Filtering. Heuristics were developed to remove additional low-quality documents, outliers, and documents with too many repetitions. Some examples of heuristics include:
- We use duplicate n-tuple coverage (Rae et al., 2021) to remove rows consisting of duplicate content (e.g., logs or error messages). These rows can be very long and unique, and thus cannot be filtered by row de-duplication.
- We use a "dirty word" count (Raffel et al., 2020) to filter out adult sites that are not covered by the domain blacklist.
- We use the Kullback-Leibler scatter of the token distribution to filter out documents that contain too many anomalous tokens compared to the training corpus distribution.
Model-Based Quality Filtering.
In addition, we have attempted to use various model-based quality classifiers for selecting high-quality markers. These methods include:
- Using fast classifiers such as fasttext (Joulin et al., 2017), which are trained to recognize whether a given text will be cited by Wikipedia (Touvron et al., 2023a).
- Using the more computationally intensive Roberta model classifier (Liu et al., 2019a), which is trained on the predictions of Llama 2.
To train the Llama 2-based quality classifier, we created a set of cleaned Web documents describing the quality requirements and instructed Llama 2's chat model to determine whether the documents met these requirements. For efficiency, we use DistilRoberta (Sanh et al., 2019) to generate quality scores for each document. We will experimentally evaluate the effectiveness of various quality filtering configurations.
Code and inference data.
Similar to DeepSeek-AI et al. (2024), we constructed domain-specific pipelines to extract code-containing and math-related web pages. Specifically, both code and inference classifiers are DistilledRoberta models trained using Llama 2 annotated Web data. Unlike the generic quality classifiers mentioned above, we perform cue tuning to target web pages containing mathematical inferences, reasoning in STEM domains, and code embedded in natural language. Since the token distributions of code and mathematics are very different from those of natural language, these pipelines implement domain-specific HTML extraction, custom text features, and heuristics for filtering.
Multilingual data.
Similar to the English processing pipeline described above, we implement filters to remove website data that may contain personally identifiable information (PII) or insecure content. Our multilingual text processing pipeline has the following unique features:
- We use a fasttext-based language recognition model to classify documents into 176 languages.
- We perform document-level and row-level de-duplication of data for each language.
- We apply language-specific heuristics and model-based filters to remove low-quality documents.
In addition, we use a multilingual Llama 2-based classifier to rank the quality of multilingual documents to ensure that high-quality content is prioritized. The number of multilingual tokens we use in pre-training is determined experimentally, and model performance is balanced on English and multilingual benchmark tests.
3.12 Determining data mix
为了获得高质量语言模型,必须谨慎确定预训练数据混合中不同数据源的比例。我们主要利用知识分类和尺度定律实验来确定这一数据混合。
知识分类。我们开发了一个分类器,用于对网页数据中包含的信息类型进行分类,以便更有效地确定数据组合。我们使用这个分类器对网页上过度代表的数据类别(例如艺术和娱乐)进行下采样。
为了确定最佳数据混合方案。我们进行规模定律实验,其中我们将多个小型模型训练于特定数据混合集上,并利用其预测大型模型在该混合集上的性能(参见第 3.2.1 节)。我们多次重复此过程,针对不同的数据混合集选择新的候选数据混合集。随后,我们在该候选数据混合集上训练一个更大的模型,并在多个关键基准测试上评估该模型的性能。
数据混合摘要。我们的最终数据混合包含大约 50% 的通用知识标记、25% 的数学和推理标记、17% 的代码标记以及 8% 的多语言标记。
3.13 Annealing data
Empirical results show that annealing on a small amount of high-quality code and math data (see Section 3.4.3) improves the performance of pre-trained models on key benchmark tests. Similar to the study by Li et al. (2024b), we anneal using a mixed dataset containing high-quality data from selected domains. Our annealed data does not contain any training sets from commonly used benchmark tests. This allows us to evaluate the true few-sample learning ability and out-of-domain generalization of Llama 3.
Following OpenAI (2023a), we evaluated the effect of annealing on the GSM8k (Cobbe et al., 2021) and MATH (Hendrycks et al., 2021b) training sets. We find that annealing improves the performance of the pretrained Llama 3 8B model by 24.0% and 6.4% on the GSM8k and MATH validation sets, respectively.However, the improvement is negligible for the 405B model, suggesting that our flagship model has strong contextual learning and inference capabilities, and that it does not require domain-specific training samples to achieve strong performance.
Use annealing to assess data quality.Like Blakeney et al. (2024), we find that annealing allows us to judge the value of small domain-specific datasets. We measure the value of these datasets by linearly annealing the learning rate of the Llama 3 8B model, which has been trained with 50%, to 0 over 40 billion tokens. In these experiments, we assign 30% weights to the new dataset and the remaining 70% weights to the default data mix. It is more efficient to use annealing to evaluate new data sources than to perform scale law experiments on each small data set.
3.2 Model Architecture
Llama 3 uses the standard dense Transformer architecture (Vaswani et al., 2017). Its model architecture is not significantly different from Llama and Llama 2 (Touvron et al., 2023a, b); our performance gains come primarily from improvements in data quality and diversity, as well as scaling up the training size.
We made a couple of minor modifications:
- We use grouped query attention (GQA; Ainslie et al. (2023)), where 8 key-value headers are used to increase inference speed and reduce the size of the key-value cache during decoding.
- We use an attention mask to prevent self-attention mechanisms between different documents in the sequence. We find that this change has limited impact during standard pretraining, but is important during continuous pretraining of very long sequences.
- We use a vocabulary of 128K tokens. Our tokenized vocabulary combines the 100K tokens of the tiktoken3 vocabulary with 28K additional tokens to better support non-English languages. Compared to the Llama 2 vocabulary, our new vocabulary improves the compression of English data samples from 3.17 to 3.94 characters/token. This allows the model to "read" more text with the same amount of training computation. We also found that adding 28K tokens from specific non-English languages improved compression and downstream performance, while having no effect on English tokenization.
- We increase the RoPE base frequency hyperparameter to 500,000. this allows us to better support longer contexts; Xiong et al. (2023) show that this value is valid for context lengths up to 32,768.

The Llama 3 405B uses an architecture with 126 layers, 16,384 labeled representation dimensions, and 128 attention heads; for more information, see Table 3.This results in a model size that is approximately computationally optimal based on our data and a training budget of 3.8 × 10^25 FLOPs.
3.2.1 Law of Scale
We utilize Scaling Laws (Hoffmann et al., 2022; Kaplan et al., 2020) to determine the optimal size of the flagship model given our pre-training computational budget. In addition to determining the optimal model size, predicting the performance of the flagship model on downstream benchmark tasks presents significant challenges for the following reasons:
- Existing Scaling Laws typically predict only the next markup prediction loss, not a specific benchmarking performance.
- Scaling Laws can be noisy and unreliable because they are developed based on pre-training runs using a small computational budget (Wei et al., 2022b).
To address these challenges, we implemented a two-phase approach to develop Scaling Laws that accurately predict downstream benchmarking performance:
- We first establish the correlation between pre-trained FLOPs and the negative log-likelihood of computing the best model on the downstream task.
- Next, we correlate the negative log-likelihood on the downstream task with the task accuracy using the Scaling Laws model and an older model previously trained using higher computational FLOPs. In this step, we exclusively utilize the Llama 2 family of models.
This approach allows us to predict downstream task performance (for computationally optimal models) based on a specific number of pre-trained FLOPs. We use a similar approach to select our pre-training data combinations (see Section 3.4).
Scaling Law Experiment.Specifically, we constructed Scaling Laws by pre-training models using computational budgets between 6 × 10^18 FLOPs and 10^22 FLOPs. at each computational budget, we pre-trained models with sizes between 40M and 16B parameters, and used a fraction of the model size at each computational budget. In these training runs, we use cosine learning rate scheduling and linear warm-up within 2,000 training steps. The peak learning rate was set between 2 × 10^-4 and 4 × 10^-4 depending on the model size. We set the cosine decay to 0.1 times the peak value. The weight decay for each step was set to 0.1 times the learning rate for that step. We used a fixed batch size for each computational size, ranging from 250K to 4M.

These experiments produced the IsoFLOPs curves in Figure 2. The losses in these curves were measured on separate validation sets. We fit the measured loss values using a second-order polynomial and determine the minimum value of each parabola. We refer to the minimum of the parabola as the computationally optimal model under the corresponding pretrained computational budget.
We use computationally optimal models identified in this way to predict the optimal number of training tokens for a given computational budget. For this purpose, we assume a power-law relationship between the computational budget C and the optimal number of training tokens N (C):
N (C) = AC α .
We fit A and α using the data in Fig. 2. We find (α, A) = (0.53, 0.29); the corresponding fit is shown in Fig. 3. Extrapolating the resulting scaling law to 3.8 × 10 25 FLOPs suggests training a model with 402B parameters and using 16.55T tokens.
An important observation is that the IsoFLOPs curve becomes flatter around the minimum as the computational budget increases. This implies that the performance of the flagship model is relatively stable against small variations in the tradeoff between model size and training markers. Based on this observation, we finally decided to train a flagship model containing the 405B parameter.
Predicting performance of downstream tasks.We use the generated computationally optimal model to predict the performance of the flagship Llama 3 model on the benchmark dataset. First, we linearly relate the (normalized) negative log-likelihood of the correct answer in the benchmark to the training FLOPs. For this analysis, we used only the scaling law model trained to 10^22 FLOPs on the above data mixture. Next, we established an S-shaped relationship between log-likelihood and accuracy using the scaling law model and the Llama 2 model, which was trained using the Llama 2 data mix and tagger. (We show the results of this experiment on the ARC Challenge benchmark in Figure 4.) We find this two-step scaling law prediction (extrapolated over four orders of magnitude) to be quite accurate: it only slightly underestimates the final performance of the flagship Llama 3 model.
3.3 Infrastructure, expansion and efficiency
We describe the hardware and infrastructure supporting Llama 3 405B pre-training and discuss several optimizations that improve training efficiency.
3.3.1 Training infrastructure
Llama 1 and Llama 2 models were trained on Meta's AI research supercluster (Lee and Sengupta, 2022). As we scaled up further, Llama 3 training was migrated to Meta's production cluster (Lee et al., 2024). This setup optimizes production-level reliability, which is critical as we scale up training.

Computing resources: The Llama 3 405B trains on up to 16,000 H100 GPUs, each running at 700W TDP with 80GB HBM3, using Meta's Grand Teton AI server platform (Matt Bowman, 2022). Each server is equipped with eight GPUs and two CPUs; inside the server, the eight GPUs are connected via NVLink. Training jobs are scheduled using MAST (Choudhury et al., 2024), Meta's global-scale training scheduler.
Storage: Tectonic (Pan et al., 2021), Meta's general-purpose distributed file system, was used to build the storage architecture for Llama 3 pre-training (Battey and Gupta, 2024). It provides 240 Petabytes of storage space and consists of 7,500 SSD-equipped servers supporting a sustainable throughput of 2 TB/s and a peak throughput of 7 TB/s. A major challenge is to support highly bursty checkpoint writes that saturate the storage fabric in a short period of time. Checkpoints save the model state of each GPU, ranging from 1MB to 4GB per GPU, for recovery and debugging. Our goal is to minimize GPU pause time during checkpointing and increase the frequency of checkpointing to reduce the amount of work lost after recovery.
Networking: The Llama 3 405B uses an RDMA over Converged Ethernet (RoCE) architecture based on the Arista 7800 and Minipack2 Open Compute Project (OCP) rack switches. smaller models in the Llama 3 series were trained using the Nvidia Quantum2 Infiniband network. Both the RoCE and Infiniband clusters utilize 400 Gbps link connectivity between GPUs. Despite the differences in the underlying network technology of these clusters, we have tuned both to provide equivalent performance to handle these large training workloads. We will elaborate further on our RoCE network as we take full ownership of its design.
- Network Topology: Our RoCE-based AI cluster contains 24,000 GPUs (Footnote 5) connected via a three-tier Clos network (Lee et al., 2024). At the bottom tier, each rack hosts 16 GPUs, allocated to two servers and connected via a single Minipack2 top-of-rack (ToR) switch. In the middle tier, 192 of these racks are connected via cluster switches to form a Pod of 3,072 GPUs with full bi-directional bandwidth, ensuring no oversubscription. At the top tier, eight such Pods within the same data center building are connected via aggregation switches to form a cluster of 24,000 GPUs. However, instead of maintaining full bi-directional bandwidth, the network connections at the aggregation layer utilize an oversubscription rate of 1:7. Both our model-parallel approach (see Section 3.3.2) and the training job scheduler (Choudhury et al., 2024) are optimized to be aware of the network topology and are designed to minimize network communication between Pods.
- Load Balancing: The training of large language models generates heavy network traffic that is difficult to balance across all available network paths through traditional methods such as Equal Cost Multipath (ECMP) routing. To address this challenge, we employ two techniques. First, our aggregate library creates 16 network flows between two GPUs instead of one, thus reducing the amount of traffic per flow and providing more flows for load balancing. Second, our Enhanced ECMP (E-ECMP) protocol effectively balances these 16 flows across different network paths by hashing other fields in the RoCE header packet.

- Congestion control: We use deep buffer switches (Gangidi et al., 2024) in the backbone to accommodate transient congestion and buffering caused by aggregate communication patterns. This helps limit the impact of persistent congestion and network backpressure caused by slow servers, which is common in training. Finally, better load balancing through E-ECMP greatly reduces the likelihood of congestion. With these optimizations, we successfully ran a 24,000 GPU cluster without the need for traditional congestion control methods such as Data Center Quantified Congestion Notification (DCQCN).
3.3.2 Parallelism in Model Scale-Up
To scale up the training of our largest model, we shard the model using 4D parallelism - a scheme that combines four different parallel approaches. This approach effectively distributes the computation across many GPUs and ensures that each GPU's model parameters, optimizer states, gradients, and activation values fit within its HBM. Our 4D parallel implementation (as shown in et al. (2020); Ren et al. (2021); Zhao et al. (2023b)), which slices the model, optimizer, and gradient, also implements data parallelism, a parallel approach that processes the data in parallel on multiple GPUs and synchronizes them after each training step. We use FSDP to slice the optimizer state and gradient for Llama 3, but for model slicing, we do not re-slice after forward computation to avoid additional full-collection communication during backward passes.
GPU utilization.By carefully tuning the parallel configuration, hardware, and software, we achieve a BF16 model FLOPs utilization (MFU; Chowdhery et al. (2023)) of 38-43%. The configurations shown in Table 4 indicate that compared to 43% on 8K GPUs and DP=64, the decrease in MFU on 16K GPUs and DP=128 to 41% is due to the need to reduce the batch size of each DP group to keep the number of global markers constant during training.
Streamline parallel improvements.We encountered several challenges in our existing implementation:
- Batch size limitations.Current implementations place a limit on the batch size supported per GPU, requiring it to be divisible by the number of pipeline stages. For the example in Fig. 6, pipeline parallelism for depth-first scheduling (DFS) (Narayanan et al. (2021)) requires N = PP = 4, while breadth-first scheduling (BFS; Lamy-Poirier (2023)) requires N = M, where M is the total number of microbatches and N is the number of consecutive microbatches in the same stage in the forward or reverse direction. However, pre-training usually requires flexibility in batch sizing.
- Memory imbalance.Existing pipeline parallel implementations lead to unbalanced resource consumption. The first stage consumes more memory due to embedding and warming up micro batches.
- The calculation is not balanced. After the last layer of the model, we need to compute the outputs and losses, making this phase a bottleneck in execution latency. where Di is the index of the i-th parallel dimension. In this example, GPU0[TP0, CP0, PP0, DP0] and GPU1[TP1, CP0, PP0, DP0] are in the same TP group, GPU0 and GPU2 are in the same CP group, GPU0 and GPU4 are in the same PP group, and GPU0 and GPU8 are in the same DP group.

To address these issues, we modified the pipeline scheduling approach, as shown in Figure 6, which allows for a flexible setting of N - in this case N = 5, which allows for any number of microbatches to be run in each batch. This allows us to:
(1) When there is a batch size limit, run fewer microbatches than the number of stages; or
(2) Run more micro-batches to hide the peer-to-peer communication and find the best communication and memory efficiency between Depth-First Scheduling (DFS) and Breadth-First Scheduling (BFS). To balance the pipeline, we reduce one Transformer layer from the first stage and the last stage, respectively. This means that the first model block on the first stage has only the embedding layer, while the last model block on the last stage has only the output projection and loss computation.
To minimize pipeline bubbles, we use an interleaved scheduling approach (Narayanan et al., 2021) on a pipeline hierarchy with V pipeline stages. The overall pipeline bubble ratio is PP-1 V * M . In addition, we employ asynchronous peer-to-peer communication, which significantly speeds up training, especially in cases where document masks introduce additional computational imbalances. We enable TORCH_NCCL_AVOID_RECORD_STREAMS to reduce the memory usage from asynchronous peer-to-peer communication. Finally, to reduce memory costs, based on a detailed memory allocation analysis, we proactively free tensors that will not be used for future computations, including input and output tensors for each pipeline stage. ** With these optimizations, we are able to use the 8K tensors without using activation checkpoints. token sequences for Llama 3 pre-training.
Context parallelization is used for long sequences. We utilize context parallelization (CP) to improve memory efficiency when scaling Llama 3 context lengths and to allow training on very long sequences up to 128K. In CP, we partition across sequence dimensions, specifically we divide the input sequence into 2 × CP blocks so that each CP level receives two blocks for better load balancing. The ith CP level receives the ith and (2 × CP -1 -i) blocks.
Unlike existing CP implementations that overlap communication and computation in a ring structure (Liu et al., 2023a), our CP implementation employs an all-gather-based approach, which first globally aggregates key-value (K, V) tensors, and then computes the attentional outputs of a block of local query (Q) tensors. Although the all-gather communication latency is on the critical path, we still adopt this approach for two main reasons:
(1) It is easier and more flexible to support different types of attention masks, such as document masks, in all-gather based CP attention;
(2) The exposed all-gather latency is small because the K and V tensor of the communication is much smaller than the Q tensor, due to the use of GQA (Ainslie et al., 2023). As a result, the time complexity of the attention computation is an order of magnitude larger than that of all-gather (O(S²) versus O(S), where S denotes the length of the sequence in the full causal mask), making the all-gather overhead negligible.

Network-aware parallelized configuration.The order of parallelization dimensions [TP, CP, PP, DP] is optimized for network communication. The innermost layer of parallelization requires the highest network bandwidth and lowest latency, and is therefore usually restricted to within the same server. The outermost layer of parallelization may span multi-hop networks and should be able to tolerate higher network latency. Therefore, based on the network bandwidth and latency requirements, we rank the parallelization dimensions in the order of [TP, CP, PP, DP].DP (i.e., FSDP) is the outermost layer of parallelization because it can tolerate longer network latency by asynchronously prefetching the slicing model weights and reducing the gradient. Determining the optimal parallelization configuration with minimal communication overhead while avoiding GPU memory overflow is a challenge. We developed a memory consumption estimator and a performance projection tool, which help us explore various parallelization configurations and predict overall training performance and identify memory gaps efficiently.
Numerical Stability.By comparing training losses between different parallel settings, we fix some numerical issues that affect training stability. To ensure training convergence, we use FP32 gradient accumulation during the reverse computation of multiple micro-batches and reduce-scatter gradients using FP32 between data parallelizers in FSDP. For intermediate tensors that are used multiple times in the forward computation, such as the visual coder output, the reverse gradient is also accumulated in FP32.
3.3.3 Collective communications
Llama 3's collective communication library is based on a branch of Nvidia's NCCL library called NCCLX. NCCLX greatly improves the performance of NCCL, especially for high latency networks. Recall that the order of parallel dimensions is [TP, CP, PP, DP], where DP corresponds to FSDP, and that the outermost parallel dimensions, PP and DP, may communicate over a multi-hop network with latencies in the tens of microseconds. The collective communication operations all-gather and reduce-scatter of the original NCCL are used in FSDP, while point-to-point communication is used for PP, which require data chunking and staged data replication. This approach leads to some of the following inefficiencies:
- A large number of small control messages need to be exchanged over the network to facilitate data transfer;
- Additional memory copy operations;
- Use additional GPU cycles for communication.
For Llama 3 training, we address some of these inefficiencies by adapting chunking and data transfers to our network latency, which can be as high as tens of microseconds in large clusters. We also allow small control messages to cross our network with higher priority, specifically avoiding head-of-queue blocking in deeply buffered core switches.
Our ongoing work for future versions of Llama includes deeper changes to NCCLX to fully address all of the above issues.

3.3.4 Reliability and operational challenges
The complexity and potential failure scenarios of 16K GPU training exceed those of larger CPU clusters we have operated on. In addition, the synchronous nature of training makes it less fault-tolerant - a single GPU failure may require restarting the entire job. Despite these challenges, for Llama 3 we achieved effective training times higher than 90% while supporting automated cluster maintenance such as firmware and Linux kernel upgrades (Vigraham and Leonhardi, 2024), which resulted in at least one training outage per day.
Effective training time is the time spent on effective training during the elapsed time. During the 54-day pre-training snapshot, we experienced a total of 466 operational outages. Of these, 47 were planned interruptions due to automated maintenance operations (e.g., firmware upgrades or operator-initiated operations such as configuration or dataset updates). The remaining 419 were unanticipated outages, which are categorized in Table 5. Approximately 78% of the unanticipated outages were attributed to either identified hardware issues, such as GPU or host component failures, or suspected hardware-related issues, such as silent data corruption and unplanned individual host maintenance events.GPU issues were the largest category, accounting for 58.7% of all the unanticipated issues.Despite the large number of failures, only three major manual interventions and the remaining issues were handled through automation.
To improve effective training time, we reduced job startup and checkpointing time, and developed tools for rapid diagnosis and problem solving. We made extensive use of PyTorch's built-in NCCL Flight Recorder (Ansel et al., 2024)-this feature captures collective metadata and stack traces into a ring buffer, allowing us to quickly diagnose hangs and performance issues at scale, especially in the case of NCCLX aspects. Using it, we can efficiently log communication events and durations for each collective operation, and automatically dump trace data in the event of an NCCLX watchdog or heartbeat timeout. With online configuration changes (Tang et al., 2015), we can selectively enable more computationally intensive trace operations and metadata collection without code releases or job restarts. Debugging issues in large training sessions is complicated by the mixed use of NVLink and RoCE in our network. Data transfers are typically performed over NVLink via load/store operations issued by the CUDA kernel, and failure of a remote GPU or NVLink connection often manifests itself as a stalled load/store operation in the CUDA kernel without returning an explicit error code.NCCLX improves the speed and accuracy of fault detection and localization by being tightly engineered with PyTorch, allowing PyTorch to access the internal state of NCCLX and track relevant information. While it is not possible to completely prevent stalls due to NVLink failures, our system monitors the state of the communication libraries and automatically times out when such stalls are detected. In addition, NCCLX tracks kernel and network activity for each NCCLX communication and provides a snapshot of the internal state of the failing NCCLX collective, including completed and uncompleted data transfers between all ranks. We analyze this data to debug NCCLX extension issues.
Sometimes, hardware problems can result in still-running but slow stragglers that are hard to detect. Even if there is only one straggler, it can slow down thousands of other GPUs, often in the form of normal operation but slow communication. We developed tools to prioritize potentially problematic communications from selected groups of processes. By investigating only a few key suspects, we are often able to effectively identify stragglers.
An interesting observation is the impact of environmental factors on large-scale training performance. For the Llama 3 405B, we noticed a throughput fluctuation of 1-2% based on time variation. This fluctuation is caused by higher midday temperatures affecting GPU dynamic voltage and frequency scaling. During training, tens of thousands of GPUs may simultaneously increase or decrease power consumption, e.g., due to the fact that all GPUs are waiting for a checkpoint or collective communication to end, or for an entire training job to start or shut down. When this happens, it can lead to transient fluctuations in power consumption within the data center of the order of tens of megawatts, which stretches the limits of the power grid. This is an ongoing challenge as we scale training for future and even larger Llama models.
3.4 Training programs
The pre-training recipe for Llama 3 405B contains three main stages:
(1) initial pretraining, (2) long context pretraining and (3) annealing. Each of these three stages is described below. We use similar recipes to pre-train the 8B and 70B models.
3.4.1 Initial pre-training
We pretrained the Llama 3 405B model using a cosine learning rate scheme with a maximum learning rate of 8 × 10-⁵, linearly warming up to 8,000 steps and decaying to 8 × 10-⁷ after 1,200,000 training steps. To improve the stability of training, we use a smaller batch size at the beginning of training and subsequently increase the batch size to improve efficiency. Specifically, we initially have a batch size of 4M tokens and a sequence length of 4,096. after pre-training 252M tokens, we double the batch size and sequence length to 8M sequences and 8,192 tokens, respectively. after pre-training 2.87T tokens, we again double the batch size to 16M. we found that This training method is very stable: very few loss spikes occur and no intervention is needed to correct deviations in model training.
Adjusting data combinations. During training, we made several adjustments to the pre-training data mix to improve the model's performance in specific downstream tasks. In particular, we increased the proportion of non-English data during pre-training to improve the multilingual performance of Llama 3. We also up-adjusted the proportion of mathematical data to enhance the model's mathematical reasoning, added more recent network data in the later stages of pre-training to update the model's knowledge cutoffs, and down-adjusted the proportion of a subset of the data that was later identified as being of lower quality.
3.4.2 Long-context pre-training
In the final stage of pre-training, we train long sequences to support context windows of up to 128,000 tokens. We do not train long sequences earlier because the computation in the self-attention layer grows quadratically with sequence length. We incrementally increase the supported context length and pre-train after the model has successfully adapted to the increased context length. We evaluate successful adaptation by measuring both:
(1) Whether the model's performance in short-context evaluations has been fully recovered;
(2) Whether the model can perfectly solve the "needle in a haystack" task up to this length. In the Llama 3 405B pre-training, we incrementally increased the length of the context in six phases, starting with an initial context window of 8,000 tokens and eventually reaching a context window of 128,000 tokens. This long context pre-training phase used approximately 800 billion training tokens.

3.4.3 Annealing
During pre-training of the last 40M tokens, we annealed the learning rate linearly to 0 while maintaining a context length of 128K tokens. During this annealing phase, we also adjust the data mix to increase the sample size of very high-quality data sources; see Section 3.1.3. Finally, we computed the average of the model checkpoints (Polyak (1991) average) during annealing to generate the final pretrained model.
4 Follow-up training
We generated and aligned Llama 3 models by applying multiple rounds of follow-up training. These follow-up trainings are based on pre-trained checkpoints and incorporate human feedback for model alignment (Ouyang et al., 2022; Rafailov et al., 2024). Each round of follow-up training consisted of supervised fine-tuning (SFT) followed by direct preference optimization (DPO; Rafailov et al., 2024) using examples generated via manual annotation or synthesis. We describe our subsequent training modeling and data methods in Sections 4.1 and 4.2, respectively. Additionally, we provide further details on customized data wrangling strategies in Section 4.3 to improve the model's inference, programming capabilities, factoring, multi-language support, tool usage, long contexts, and precise instruction adherence.
4.1 Modeling
The basis of our post-training strategy is a reward model and a language model. We first train a reward model on top of the pre-training checkpoints using human-labeled preference data (see Section 4.1.2). We then fine-tune the pre-training checkpoints with supervised fine-tuning (SFT; see Section 4.1.3) and further align them with the checkpoints using direct preference optimization (DPO; see Section 4.1.4). This process is shown in Figure 7. Unless otherwise noted, our modeling process applies to Llama 3 405B, which we refer to as Llama 3 405B for simplicity.
4.1.1 Chat conversation format
In order to adapt a large-scale language model (LLM) for human-computer interaction, we need to define a chat conversation protocol that allows the model to understand human commands and perform conversational tasks. Compared to its predecessor, Llama 3 has new features such as tool usage (Section 4.3.5), which may require generating multiple messages in a single dialog round and sending them to different locations (e.g., user, ipython). To support this, we have designed a new multi-message chat protocol that uses a variety of special header and termination tokens. Header tokens are used to indicate the source and destination of each message in a conversation. Similarly, termination markers indicate when it is the turn of the human and the AI to alternate speaking.
4.1.2 Reward models
We trained a reward model (RM) covering different abilities and built it on top of pre-trained checkpoints. The training objective is the same as in Llama 2, but we remove the marginal term in the loss function because we observe a reduced improvement as the data size increases. As in Llama 2, we use all preference data for reward modeling after filtering out samples with similar responses.
In addition to the standard (selected, rejected) response preference pairs, the annotation creates a third "edited response" for some cues, where the response selected from the pair is further edited for improvement (see Section 4.2.1). Thus, each preference sorting sample has two or three responses that are clearly ranked (edited > selected > rejected). During training, we concatenated the cues and multiple responses into one row and randomized the responses. This is an approximation of the standard scenario of computing scores by placing responses in separate rows, but in our ablation experiments, this approach improves training efficiency without loss of precision.
4.1.3 Oversight fine-tuning
Human labeled cues are first rejected for sampling using the reward model, the detailed methodology of which is described in Section 4.2. We combine these rejection-sampled data with other data sources (including synthetic data) to fine-tune the pre-trained language model using standard cross-entropy losses, with the goal of predicting target tokens (while masking the loss of cued markup). See Section 4.2 for more details on data blending. Although many of the training targets are model-generated, we refer to this phase as supervised fine-tuning (SFT; Wei et al. 2022a; Sanh et al. 2022; Wang et al. 2022b).
Our maximal model is fine-tuned with a learning rate of 1e-5 within 8.5K to 9K steps. We found these hyperparameter settings to be suitable for different rounds and data mixes.
4.1.4 Direct preference optimization
We further trained our SFT models for human preference alignment using Direct Preference Optimization (DPO; Rafailov et al., 2024). In training, we mainly use the latest preference data batches collected from the best performing models in the previous round of alignment. As a result, our training data better matches the distribution of optimized strategy models in each round. We also explored strategy algorithms such as PPO (Schulman et al., 2017), but found that DPO requires less computation and performs better on large-scale models, especially in instruction adherence benchmarks such as IFEval (Zhou et al., 2023).
For Llama 3, we used a learning rate of 1e-5 and set the β hyperparameter to 0.1. In addition, we applied the following algorithmic modifications to DPO:
- Masking Format Markers in DPO Losses. We mask out special format markers (including header and termination markers described in Section 4.1.1) from selected and rejected responses to stabilize DPO training. We note that the participation of these markers in the loss may lead to undesired model behavior, such as tail duplication or sudden generation of termination markers. We hypothesize that this is due to the contrasting nature of DPO loss - the presence of common markers in both selected and rejected responses can lead to conflicting learning goals, as the model needs to simultaneously increase and decrease the likelihood of these markers.
- Regularization using NLL loss: the We added an additional negative log-likelihood (NLL) loss term to the selected sequences with a scaling factor of 0.2, similar to Pang et al. (2024). This helps to further stabilize DPO training by maintaining the format required for generation and preventing the log-likelihood of the selected responses from decreasing (Pang et al., 2024; Pal et al., 2024).
4.1.5 Model averaging
Finally, we averaged the models obtained in experiments using various data versions or hyperparameters at each RM, SFT, or DPO stage (Izmailov et al. 2019; Wortsman et al. 2022; Li et al. 2022). We present statistical information on the internally collected human preference data used for Llama 3 conditioning. We asked evaluators to engage in multiple rounds of dialog with the model and compared responses from each round. During post-processing, we split each conversation into multiple examples, each of which contains a prompt (including the previous conversation if available) and a response (e.g., a response that was selected or rejected).

4.1.6 Iteration rounds
Following Llama 2, we applied the above methodology for six rounds of iterations. In each round, we collect new preference labeling and fine-tuning (SFT) data and sample synthetic data from the latest model.
4.2 Post-training data
The composition of the post-training data plays a crucial role in the utility and behavior of the language model. In this section, we discuss our annotation procedure and preference data collection (Section 4.2.1), the composition of the SFT data (Section 4.2.2), and methods for data quality control and cleaning (Section 4.2.3).
4.2.1 Preferences
Our preference data labeling process is similar to Llama 2. After each round, we deploy multiple models for labeling and sample two responses from different models for each user cue. These models can be trained using different data mixing and alignment schemes, resulting in different capability strengths (e.g., code expertise) and increased data diversity. We asked annotators to categorize preference scores into one of four levels based on their level of preference: significantly better, better, slightly better, or slightly better.
We have also included an editing step after the preference ordering to encourage the annotator to further refine the preferred response. The annotator can either edit the selected response directly, or use the feedback cue model to refine their own response. As a result, some preference data has three sorted responses (Edit > Select > Reject).
The preference annotation statistics we used for Llama 3 training are reported in Table 6. Generalized English covers multiple subcategories, such as knowledge-based question and answer or precise instruction following, which are beyond the scope of specific abilities. Compared to Llama 2, we observed an increase in the average length of prompts and responses, suggesting that we are training Llama 3 on more complex tasks.In addition, we implemented a quality analysis and manual evaluation process to critically assess the collected data, allowing us to refine the prompts and provide systematic, actionable feedback to the annotators. For example, as Llama 3 improves after each round, we will correspondingly increase the complexity of the cues to target areas where the model is lagging.
In each late training round, we use all available preference data at the time for reward modeling, and only the most recent batches from each capability for DPO training. For both reward modeling and DPO, we train with samples labeled "selection response significantly better or better" and discard samples with similar responses.
4.2.2 SFT data
Our fine-tuning data comes primarily from the following sources:
- Cues from our manually labeled collection and their rejection of sampling responses
- Synthetic data for specific capabilities (see Section 4.3 for details)
- Small amount of manually labeled data (see Section 4.3 for details)
As we progressed through our post-training cycle, we developed more powerful variants of Llama 3 and used these to collect larger datasets to cover a wide range of complex capabilities. In this section, we discuss the details of the rejection sampling process and the overall composition of the final SFT data mixture.
Refusal to sample.In Rejection Sampling (RS), for each cue we collect during manual annotation (Section 4.2.1), we sample K outputs from the most recent chat modeling strategy (typically the best execution checkpoints from the previous post-training iteration, or the best execution checkpoints for a given competency) and use our reward model to select the best candidate, in line with Bai et al. (2022). At later stages of post-training, we introduce system cues to guide RS responses to conform to a desired tone, style, or format, which may vary for different abilities.
To improve the efficiency of rejection sampling, we employ PagedAttention (Kwon et al., 2023).PagedAttention improves memory efficiency through dynamic key-value cache allocation. It supports arbitrary output length by dynamically scheduling requests based on the current cache capacity. Unfortunately, this introduces the risk of swapping when memory runs out. To eliminate this swapping overhead, we define a maximum output length and only execute requests if there is enough memory to hold outputs of that length.PagedAttention also allows us to share the hinted key-value cache page across all corresponding outputs. Overall, this resulted in more than a 2x increase in throughput during rejection sampling.
Aggregate data composition.Table 7 shows the statistics for each of the broad categories of data in our "usefulness" mix. While the SFT and preference data contain overlapping domains, they are curated differently, resulting in different count statistics. In Section 4.2.3, we describe the techniques used to categorize the subject matter, complexity, and quality of our data samples. In each round of post-training, we carefully tune our overall data mix to adjust performance across multiple axes for a wide range of benchmarks. Our final data blend will be iterated multiple times for certain high-quality sources and downsampled for others.

4.2.3 Data processing and quality control
Considering that most of our training data is model-generated, careful cleaning and quality control is required.
Data cleansing: In the early stages, we observed many unwanted patterns in the data, such as excessive use of emoticons or exclamation points. Therefore, we implemented a series of rule-based data deletion and modification strategies to filter or remove problematic data. For example, to mitigate the problem of over-apologizing intonation, we would identify overused phrases (e.g., "I'm sorry" or "I apologize") and carefully balance the proportion of such samples in the dataset.
Data pruning: We also apply a number of model-based techniques to remove low-quality training samples and improve overall model performance:
- Subject Categorization: We first fine-tuned Llama 3 8B into a topic classifier and reasoned over all the data to categorize it into coarse-grained categories ("Mathematical Reasoning") and fine-grained categories ("Geometry and Trigonometry").
- Quality rating: We used the reward model and Llama-based signaling to obtain quality scores for each sample. For the RM-based scores, we considered data with scores in the highest quartile as high quality. For the Llama-based scores, we prompted the Llama 3 checkpoints to score the General English data on three levels (accuracy, instruction adherence, and tone/presentation) and the code data on two levels (error recognition and user intent) and considered the samples with the highest scores as high-quality data. RM and Llama-based scores have high conflict rates, and we found that combining these signals resulted in the best recall for the internal test set. Ultimately, we select those examples that are labeled as high quality by either the RM or Llama-based filters.
- Difficulty Rating: Since we were also interested in prioritizing more complex model examples, we scored the data using two difficulty metrics: Instag (Lu et al., 2023) and Llama-based scoring. For Instag, we prompted Llama 3 70B to perform intent labeling on SFT cues, where more intent implies higher complexity. We also prompted Llama 3 to measure the difficulty of the dialog on three levels (Liu et al., 2024c).
- Semantic de-emphasis: Finally, we perform semantic de-duplication (Abbas et al., 2023; Liu et al., 2024c). We first cluster complete conversations using RoBERTa (Liu et al., 2019b) and sort by quality score × difficulty score in each cluster. We then perform greedy selection by iterating over all sorted examples, keeping only those whose maximum cosine similarity to the examples seen in the clusters so far is less than a threshold.
4.3 Capacity
In particular, we highlight some of the efforts made to improve specific competencies, such as code handling (Section 4.3.1), multilingualism (Section 4.3.2), mathematical and reasoning skills (Section 4.3.3), long contextualization (Section 4.3.4), tool use (Section 4.3.5), factuality (Section 4.3.6), and controllability (Section 4.3.7).
4.3.1 Code
since (a time) Copilot Since the release of LLMs for code and Codex (Chen et al., 2021), there has been a lot of interest. Developers now use these models extensively to generate code snippets, debug, automate tasks, and improve code quality. For Llama 3, our goal is to improve and evaluate code generation, documentation, debugging, and review capabilities for the following prioritized programming languages: Python, Java, JavaScript, C/C++, TypeScript, Rust, PHP, HTML/CSS, SQL, and bash/shell.Here, we present the results obtained by training code experts, generating synthetic data for SFT, moving to improved formats via system prompts, and creating quality filters to remove bad samples from training data to improve these coding features.
Specialist training.We trained a code expert and used it in subsequent multiple rounds of post-training to collect high-quality human code annotations. This was achieved by branching off the main pre-training run and continuing to pre-train on a mix of 1T tokens that were primarily (>85%) code data. Continued pre-training on domain-specific data has been shown to be effective in improving performance in specific domains (Gururangan et al., 2020). We follow a similar recipe to CodeLlama (Rozière et al., 2023). In the last few thousand steps of training, we perform long context fine-tuning (LCFT) on a high-quality blend of repository-level code data, extending the expert's context length to 16K tokens. Finally, we follow a similar post-training modeling recipe described in Section 4.1 to align the model, but use a mix of SFT and DPO data that is primarily code-specific. The model is also used for rejection sampling of coding cues (Section 4.2.2).
Synthetic data generation.During development, we identified key problems with code generation, including difficulty following instructions, code syntax errors, incorrect code generation, and difficulty fixing errors. While dense human annotations could theoretically solve these problems, synthetic data generation provides a complementary approach that is cheaper, scales better, and is not limited by the level of expertise of the annotators.
Therefore, we used Llama 3 and Code Expert to generate a large number of synthetic SFT conversations. We describe three high-level methods for generating synthetic code data. Overall, we used over 2.7 million synthetic examples during SFT.
1. Synthetic data generation: implementing feedback.The 8B and 70B models show significant performance improvements on training data generated by larger, more competent models. However, our preliminary experiments show that training only Llama 3 405B on its own generated data does not help (or even degrades performance). To address this limitation, we introduce execution feedback as a source of truth that allows the model to learn from its mistakes and stay on track. In particular, we generate a dataset of approximately one million synthesized coded conversations using the following procedure:
- Problem description generation:First, we generated a large set of programming problem descriptions covering a variety of topics (including long-tail distributions). To achieve this diversity, we randomly sampled code snippets from a variety of sources and prompted the model to generate programming problems based on these examples. This allowed us to capitalize on the wide range of topics and create a comprehensive set of problem descriptions (Wei et al., 2024).
- Solution Generation:We then prompted Llama 3 to solve each problem in the given programming language. We observed that adding good programming rules to the prompts improved the quality of the generated solutions. In addition, we found it helpful to ask the model to explain its thought process with annotations.
- Correctness analysis: After generating solutions, it is critical to recognize that their correctness is not a guarantee, and that including incorrect solutions in the fine-tuned dataset may compromise the quality of the model. While we cannot ensure complete correctness, we develop methods to approximate correctness. To this end, we take the extracted source code from the generated solutions and apply a combination of static and dynamic analysis techniques to test their correctness, including:
- Static analysis: We run all generated code through a parser and code checking tools to ensure syntactic correctness, catching syntax errors, use of uninitialized variables or unimported functions, code style issues, type errors, and more.
- Unit test generation and execution: For each problem and solution, we prompt the model to generate unit tests and execute them with the solution in a containerized environment, catching runtime execution errors and some semantic errors.
- Error feedback and iterative self-correction: When the solution fails at any step, we prompt the model to modify it. The prompt contains the original problem description, the wrong solution, and feedback from the parser/code inspection tool/testing program (standard output, standard error, and return code). After a unit test execution failure, the model can either fix the code to pass the existing tests or modify its unit tests to fit the generated code. Only dialogs that pass all checks are included in the final dataset for supervised fine-tuning (SFT). Notably, we observed that approximately 20% of solutions were initially incorrect but self-corrected, suggesting that the model learns from execution feedback and improves its performance.
- Fine-tuning and iterative improvement: The fine-tuning process takes place over multiple rounds, with each round building on the previous round. After each fine-tuning round, the model is improved to generate higher quality synthetic data for the next round. This iterative process allows for incremental refinements and enhancements to model performance.
2. Synthetic data generation: programming language translation. We observe a performance gap between major programming languages (e.g. Python/C++) and less common programming languages (e.g. Typescript/PHP). This is not surprising since we have less training data for less common programming languages. To mitigate this, we will supplement the available data by translating data from common programming languages into less common ones (similar to Chen et al. (2023) in the field of inference). This is accomplished by prompting Llama 3 and ensuring quality through syntactic parsing, compilation, and execution. Figure 8 shows an example of synthesized PHP code translated from Python. This significantly improves the performance of less common languages measured by the MultiPL-E (Cassano et al., 2023) benchmark.
3. Synthetic data generation: reverse translation. In order to improve certain coding capabilities (e.g., documentation, interpretation) where the amount of information from execution feedback is not sufficient to determine quality, we use another multi-step approach. Using this process, we generated approximately 1.2 million synthetic conversations related to code interpretation, generation, documentation, and debugging. Starting with code snippets in various languages from the pre-training data:


- Generate: We prompted Llama 3 to generate data representing the target capabilities (e.g., adding comments and documentation strings to a code snippet, or asking the model to interpret a piece of code).
- Reverse translation. We prompt the model to "back-translate" the synthetically-generated data back to the original code (e.g., we prompt the model to generate code only from its documents, or let us ask the model to generate code only from its explanations).
- Filtration. Using the original code as a reference, we prompt Llama 3 to determine the quality of the output (e.g., we ask the model how faithful the back-translated code is to the original code). We then use the generated example with the highest self-validation score in SFT.
System prompt guide for rejecting samples. During rejection sampling, we use code-specific system cues to improve the readability, documentation, completeness, and concreteness of the code. Recall from Section 7 that this data is used to fine-tune the language model. Figure 9 shows an example of how system hints can help improve the quality of the generated code - it adds necessary comments, uses more informative variable names, saves memory, and so on.
Filtering training data using execution and modeling as rubrics. As described in Section 4.2.3, we occasionally encountered quality problems in the rejected sampled data, such as the inclusion of erroneous code blocks. Detecting these problems in rejection sampling data is not as simple as detecting our synthetic code data, because rejection sampling responses often contain a mixture of natural language and code that may not always be executable. (For example, user prompts may explicitly ask for pseudocode or edits to only very small pieces of the executable program.) To address this issue, we utilize a "model-as-judge" approach, in which earlier versions of Llama 3 are evaluated and assigned a binary (0/1) score based on two criteria: code correctness and code style. Only samples with a perfect score of 2 were retained. Initially, this strict filtering resulted in a degradation of downstream benchmark performance, primarily because it disproportionately removed samples with challenging hints. To offset this, we strategically modified some of the responses categorized as the most challenging coded data until they met the Llama-based "model as judge" criteria. By improving these challenging questions, the coded data balanced quality and difficulty to achieve optimal downstream performance.
4.3.2 Multilingualism
This section describes how we have improved the multilingual capabilities of Llama 3, including: training an expert model specialized on more multilingual data; sourcing and generating high-quality fine-tuned data of multilingual commands for German, French, Italian, Portuguese, Hindi, Spanish, and Thai; and solving the specific challenges of multilingual language bootstrapping in order to improve the overall performance of our model.
Specialist training.Our Llama 3 pre-training data mix contains far more English tokens than non-English tokens. In order to collect higher-quality non-English manual annotations, we train a multilingual expert model by branching the pretraining runs and continuing the pretraining on a data mix containing 90% multilingual tokens. We then post-train this expert model as described in Section 4.1. This expert model is then used to collect higher quality non-English human annotations until the pre-training is fully completed.
Multilingual data collection.Our multilingual SFT data mainly comes from the following sources. The overall distribution is 2.41 TP3T of human annotations, 44.21 TP3T of data from other NLP tasks, 18.81 TP3T of rejection sampling data, and 34.61 TP3T of translation inference data.
- Manual Annotation:We collect high-quality, manually annotated data from linguists and native speakers. These annotations consist mainly of open-ended cues that represent real-world use cases.
- Data from other NLP tasks:For further enhancement, we use multilingual training data from other tasks and rewrite them into a dialog format. For example, we use data from exams-qa (Hardalov et al., 2020) and Conic10k (Wu et al., 2023). To improve language alignment, we also use parallel texts from GlobalVoices (Prokopidis et al., 2016) and Wikimedia (Tiedemann, 2012). We used LID-based filtering and Blaser 2.0 (Seamless Communication et al., 2023) to remove low-quality data. For the parallel text data, instead of directly using bi-text pairs, we applied a multilingual template inspired by Wei et al. (2022a) to better model real conversations in translation and language learning scenarios.
- Reject sampling data:We applied rejection sampling to human-annotated cues to generate high-quality samples for fine-tuning, with few modifications compared to the process for English data:
- Generation: we explored randomly selecting temperature hyperparameters in the range of 0.2 -1 in early rounds of post-training to diversify generation. When using high temperatures, responses to multilingual cues may become creative and inspiring, but can also be prone to unnecessary or unnatural code switching. In the final stages of post-training, we used a constant value of 0.6 to balance this tradeoff. In addition, we used specialized system cues to improve response formatting, structure, and general readability.
- Selection: prior to reward model-based selection, we implemented multilingual-specific checks to ensure a high rate of linguistic matches between prompts and responses (e.g., Romanized Hindi prompts should not be expected to be responded to using Hindi Sanskrit scripts).
- Translation data:We attempted to avoid using machine translation data to fine-tune the model to prevent the emergence of transliterated English (Bizzoni et al., 2020; Muennighoff et al., 2023) or possible name bias (Wang et al., 2022a), gender bias (Savoldi et al., 2021), or cultural bias (Ji et al., 2023) . In addition, we aimed to prevent the model from being exposed only to tasks rooted in English-speaking cultural contexts, which may not be representative of the linguistic and cultural diversity we aimed to capture. We made an exception to this and translated the synthesized quantitative reasoning data (see Section 4.3.3 for more information) into non-English to improve quantitative reasoning performance in non-English languages. Due to the simple nature of the language of these math problems, the translated samples were found to have few quality issues. We observed significant gains from adding this translated data to the MGSM (Shi et al., 2022).
4.3.3 Mathematics and reasoning
We define reasoning as the ability to perform a multi-step computation and arrive at the correct final answer.
Several challenges guided our approach to training models that excel at mathematical reasoning:
- Lack of tips. As problem complexity increases, the number of valid cues or problems for supervised fine-tuning (SFT) decreases. This scarcity makes it difficult to create diverse and representative training datasets to teach models various mathematical skills (Yu et al. 2023; Yue et al. 2023; Luo et al. 2023; Mitra et al. 2024; Shao et al. 2024; Yue et al. 2024b).
- Lack of Real Reasoning Processes. Effective reasoning requires stepwise solutions to facilitate the reasoning process (Wei et al., 2022c). However, there is often a lack of realistic reasoning processes that are essential to guide the model on how to progressively decompose the problem and arrive at the final answer (Zelikman et al., 2022).
- Incorrect intermediate step. When using model-generated inference chains, intermediate steps may not always be correct (Cobbe et al. 2021; Uesato et al. 2022; Lightman et al. 2023; Wang et al. 2023a). This inaccuracy can lead to incorrect final answers and needs to be addressed.
- Training the model using external tools. Enhancing models to utilize external tools such as code interpreters allows them to reason by interweaving code and text (Gao et al. 2023; Chen et al. 2022; Gou et al. 2023). This ability can significantly improve their problem solving skills.
- Differences between training and reasoning: the The way models are fine-tuned during training usually differs from the way they are used during reasoning. During reasoning, the fine-tuned model may interact with humans or other models and require feedback to improve its reasoning. Ensuring consistency between training and real-world applications is critical to maintaining inference performance.
To address these challenges, we apply the following methodology:
- Resolving the lack of cues. We take relevant pre-training data from mathematical contexts and convert it into a question-answer format that can be used for supervised fine-tuning. In addition, we identify mathematical skills in which the model performs poorly and actively collect cues from humans to teach the model these skills. To facilitate this process, we created a taxonomy of math skills (Didolkar et al., 2024) and asked humans to provide the corresponding prompts/questions.
- Augmenting Training Data with Stepwise Reasoning Steps. We use Llama 3 to generate step-by-step solutions for a set of cues. For each prompt, the model produces a variable number of generated results. These generated results are then filtered based on the correct answers (Li et al., 2024a). We also perform self-validation, where Llama 3 is used to verify that a particular step-by-step solution is valid for a given problem. This process improves the quality of the fine-tuned data by eliminating instances where the model does not produce valid inference trajectories.
- Filtering Faulty Reasoning Steps. We train results and stepwise reward models (Lightman et al., 2023; Wang et al., 2023a) to filter training data with incorrect intermediate inference steps. These reward models are used to eliminate data with invalid stepwise inference, ensuring that fine-tuning yields high-quality data. For more challenging cues, we use Monte Carlo Tree Search (MCTS) with learned stepwise reward models to generate valid inference trajectories, which further enhances the collection of high-quality inference data (Xie et al., 2024).
- Interweaving Codes and Textual Reasoning. We suggest that Llama 3 solves the inference problem through a combination of textual inference and its associated Python code (Gou et al., 2023). Code execution is used as a feedback signal to eliminate cases where the inference chain is invalid and to ensure the correctness of the inference process.
- Learning from Feedback and Mistakes. To model human feedback, we utilize incorrect generation results (i.e., generation results that lead to incorrect inference trajectories) and make error corrections by prompting Llama 3 to generate correct generation results (An et al. 2023b; Welleck et al. 2022; Madaan et al. 2024a). The self-iterative process of using feedback from incorrect attempts and correcting them helps to improve the model's ability to reason accurately and learn from its mistakes.
4.3.4 Long contexts
In the final pre-training phase, we extended the context length of Llama 3 from 8K to 128K tokens (see Section 3.4 for more information on this). Similar to pre-training, we found that during fine-tuning, the formulation had to be carefully adjusted to balance short and long context capabilities.
SFT and synthetic data generation. Simply applying our existing SFT recipe using only short context data resulted in a significant decrease in long context capability in pre-training, highlighting the need to incorporate long context data in the SFT data portfolio. In practice, however, it is impractical to have most of these examples manually labeled, as reading long contexts is tedious and time-consuming, so we rely heavily on synthetic data to bridge this gap. We use an early version of Llama 3 to generate synthetic data based on key long context use cases: (potentially multiple rounds of) quizzes, long document summaries, and reasoning on the codebase, and describe these use cases in more detail below.
- Q&A: We carefully selected a set of long documents from the pre-training dataset. We split these documents into 8K labeled chunks and prompted an earlier version of the Llama 3 model to generate QA pairs on randomly selected chunks. The entire document is used as a context during training.
- Abstracts: We apply hierarchical summarization of long context documents by first hierarchically summarizing blocks of 8K input length using our strongest Llama 3 8K context model. These summaries are then summarized. During training, we provide the full document and prompt the model to summarize the document while preserving all important details. We also generate QA pairs based on the summaries of the documents and prompt the model with questions that require a global understanding of the entire long document.
- Long Context Code Reasoning: We parse Python files to identify import statements and determine their dependencies. From here, we select the most commonly used files, specifically those that are referenced by at least five other files. We remove one of these key files from the repository and prompt the model to identify dependencies on the missing file and generate the necessary missing code.
We further classify these synthetically generated samples based on sequence length (16K, 32K, 64K and 128K) for finer input length localization.
Through careful ablation experiments, we observe that mixing the synthetically generated long context data of 0.1% with the original short context data can optimize the performance of both short and long context benchmark tests.
DPO. We note that using only short-context training data in DPO does not negatively affect long-context performance, as long as the SFT model works well for long-context tasks. We suspect that this is because our DPO formulation has fewer optimizer steps than SFT. Taking this finding into account, we keep the standard short-context DPO formulation on top of the long context SFT checkpoints.
4.3.5 Use of tools
Teaching Large Language Models (LLMs) to use tools such as search engines or code interpreters can greatly expand the range of tasks they can solve, transforming them from pure chat models to more generalized assistants (Nakano et al. 2021; Thoppilan et al. 2022; Parisi et al. 2022; Gao et al. 2023 2022; Parisi et al. 2022; Gao et al. 2023; Mialon et al. 2023a; Schick et al. 2024). We trained Llama 3 to interact with the following tools:
- search engine.Llama 3 was trained to use Brave Search7 to answer questions about recent events after its knowledge deadline, or requests that require retrieval of specific information from the web.
- Python interpreter.Llama 3 generates and executes code to perform complex calculations, reads files uploaded by the user and solves tasks based on these files, such as quizzes, summaries, data analysis or visualization.
- Math Computing Engine.Llama 3 can use the Wolfram Alpha API8 to solve math and science problems more accurately, or to retrieve accurate information from Wolfram's databases.
The generated model is able to use these tools in a chat setting to resolve user queries, including multi-round conversations. If the query requires multiple invocations of the tools, the model can write step-by-step plans that invoke the tools sequentially and reason after each tool invocation.
We also improve Llama 3's zero-sample tool usage capabilities - given potentially unseen tool definitions and user queries in a contextual setting, we train the model to generate the correct tool calls.
Realization.We implement the core tools as Python objects with different methods. Zero-sample tools can be implemented as Python functions with descriptions, documentation (i.e., examples of how to use them), and the model only needs the function signature and docstring as context to generate the appropriate calls.
We also convert function definitions and calls to JSON format, e.g. for Web API calls. All tool calls are executed by the Python interpreter, which must be enabled at the Llama 3 system prompt. The core tools can be enabled or disabled separately from the system prompt.
Data collection.Unlike Schick et al. (2024), we rely on human annotations and preferences to teach Llama 3 to use the tools. This differs from the post-training pipeline typically used in Llama 3 in two major ways:
- With respect to tools, conversations often contain more than one assistant message (e.g., invoking a tool and reasoning about the tool's output). Therefore, we perform message-level annotation to collect detailed feedback: the annotator provides preferences for two assistant messages in the same context, or edits one of the messages if there is a major problem with both. The selected or modified message is then added to the context and the dialog continues. This provides human feedback on the assistant's ability to invoke the tool and reason about the tool's output. The labeler cannot rank or edit the tool output.
- We did not perform rejection sampling because we did not observe gains in our tool benchmarking.
To speed up the annotation process, we first bootstrapped the basic tool-use capabilities by fine-tuning the synthesized data from the previous Llama 3 checkpoints. In this way, the annotator will need to perform fewer editing operations. Similarly, as Llama 3 improves over time during development, we progressively complicate our human annotation protocol: we start with a single round of tool-use annotation, then move to tool-use in conversation, and finally annotate multi-step tool-use and data analysis.
Tools dataset.In order to create data for use in tool-using applications, we use the following steps.
- Single-step tool use. We first perform a small amount of sample generation to synthesize user prompts that, by construction, require a call to one of our core tools (e.g., a question that exceeds our knowledge deadline). Then, still relying on a small amount of sample generation, we generate appropriate tool calls for these hints, execute them, and add the output to the model's context. Finally, we again prompt the model to generate a final answer to the user's query based on the tool output. We end up with trajectories of the following form: system hints, user hints, tool calls, tool output, and final answers. We also filtered out about 30% of the dataset to remove unenforceable tool calls or other formatting issues.
- Multi-step tool use. We follow a similar protocol by first generating synthetic data to teach the model basic 다단계 tool usage capabilities. To do this, we first prompt Llama 3 to generate user hints that require at least two tool invocations (either from the same tool or different tools in our core set). Then, based on these hints, we perform a small number of samples prompting Llama 3 to generate a solution that consists of interwoven inference steps and tool calls, similar to the ReAct (Yao et al., 2022). See Figure 10 for an example of Llama 3 performing a task involving multi-step tool use.
- File Upload. We annotate for the following file types: .txt, .docx, .pdf, .pptx, .xlsx, .csv, .tsv, .py, .json, .jsonl, .html, .xml. Our prompts are based on providing the files and asking to summarize the contents of the files, find and fix bugs, optimize the code snippets, perform data analysis or visualization. Figure 11 shows an example of Llama 3 performing a task involving file uploads.

After fine-tuning this synthetic data, we collected human annotations from a variety of scenarios, including multiple rounds of interactions, tool use beyond three steps, and situations where tool invocations failed to produce satisfactory answers. We augmented the synthetic data with different system cues to teach the model to use tools only when activated. To train the model to avoid tool calls for simple queries, we also added queries and their responses from easy-to-compute or question-and-answer datasets (Berant et al. 2013; Koncel-Kedziorski et al. 2016; Joshi et al. 2017; Amini et al. 2019), which do not use the tool but in which the system cues activated the tool.
Zero Sample Tool Usage Data. We improve Llama 3's ability to use zero-sample tools (also known as function calls) by fine-tuning a large and diverse tuple of partial compositions (function definitions, user queries, corresponding calls). We evaluate our model on a collection of unseen tools.
- Single, nested and parallel function calls: Calls can be simple, nested (i.e., we pass function calls as arguments to another function) or parallel (i.e., the model returns a list of independent function calls). Generating a variety of functions, queries, and real results can be challenging (Mekala et al., 2024), and we rely on mining the Stack (Kocetkov et al., 2022) to base our synthetic user queries on real functions. More precisely, we extract function calls and their definitions, clean and filter them (e.g., missing document strings or non-executable functions), and use Llama 3 to generate natural-language queries corresponding to function calls.
- Multi-round function calls: We also generate synthetic data for multi-round conversations containing function calls, following a protocol similar to that presented in Li et al. (2023b). We use multiple agents to generate domains, APIs, user queries, API calls, and responses, while ensuring that the generated data covers a range of different domains and real APIs.All agents are variants of Llama 3, prompted in a way that depends on their responsibilities and collaborate in a stepwise manner.
4.3.6 Factual
Unreal remains a major challenge for large language models. Models tend to be overconfident, even in domains where they lack knowledge. Despite these shortcomings, they are often used as knowledge bases, which can lead to dangerous results such as the spread of misinformation. While we recognize that veracity transcends illusion, we take an approach here that puts illusion first.
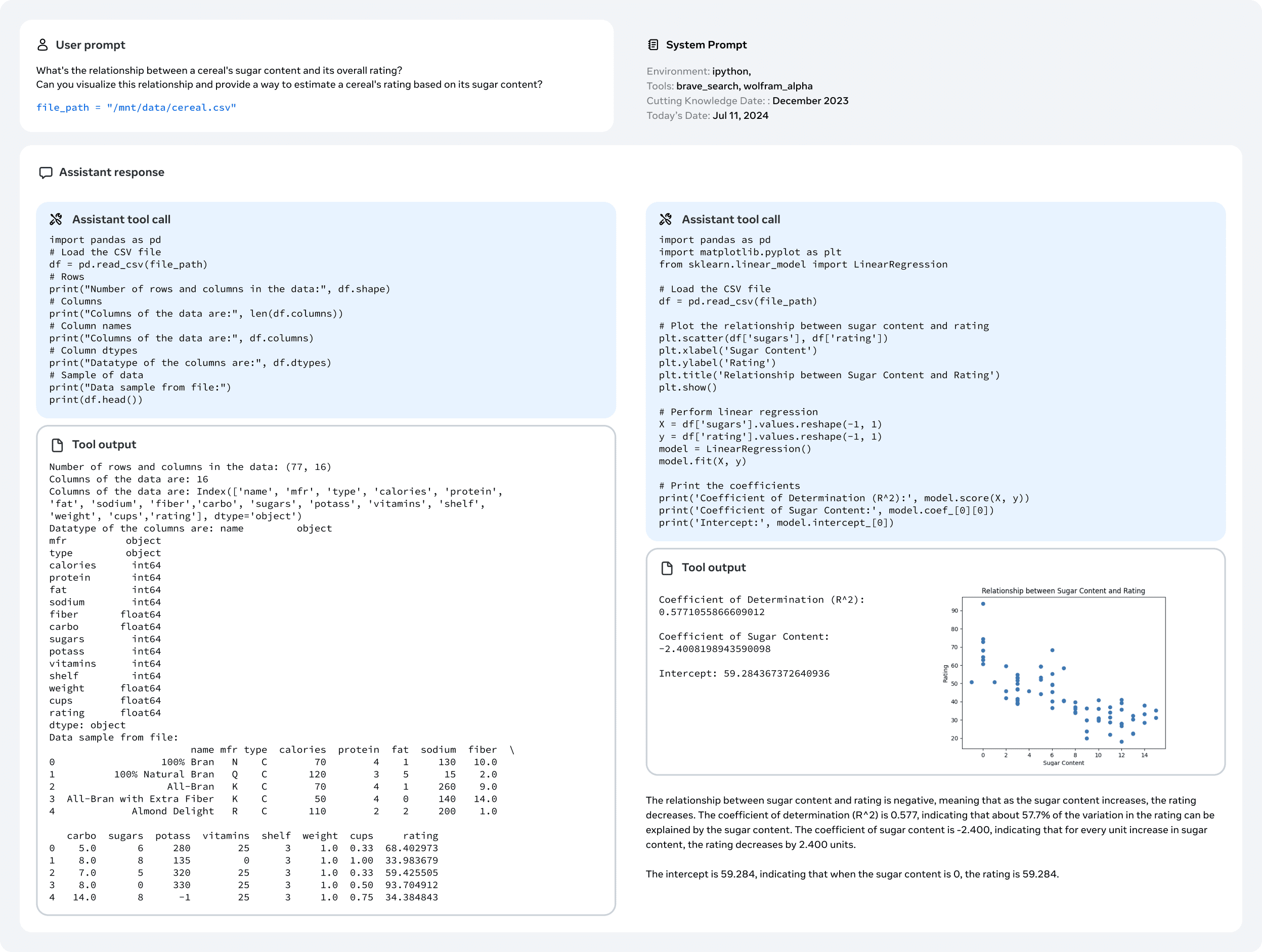
Figure 11 File upload processing. The example shows how Llama 3 analyzes and visualizes uploaded files.
We follow the principle that post-training should align the model with "knowing what it knows" rather than adding knowledge (Gekhman et al., 2024; Mielke et al., 2020). Our main approach involves generating data that aligns model generation with a subset of the real data present in the pre-training data. To this end, we have developed a knowledge detection technique that utilizes the contextual capabilities of Llama 3. This data generation process consists of the following steps:
- Extract a data segment from the pre-training data.
- Generate factual questions about these segments (contexts) by prompting Llama 3.
- Sample responses to this question from Llama 3.
- The original context was used as a reference and Llama 3 was used as a judge to score the correctness of the generation.
- Use Llama 3 as a rater to score the generated richness.
- Generate rejection reasons for responses that are consistently informative and incorrect across multiple generations and use Llama 3
We use data generated from knowledge probes to encourage the model to answer only the questions it knows and refuse to answer questions it is unsure of. In addition, pre-training data is not always factually consistent or correct. Therefore, we also collected a limited set of labeled truthfulness data that dealt with sensitive topics where there were many factually contradictory or incorrect statements.
4.3.7 Controllability
Controllability is the ability to steer the model's behavior and results to meet the needs of developers and users. Since Llama 3 is a generic base model, it should be easy to steer it to different downstream use cases. In order to improve the controllability of Llama 3, we focus on enhancing its controllability through system prompts (using natural language commands), especially with respect to response length, formatting, tone of voice, and role/character setting.
Data collection. We collected controllability preference samples in the General English category by asking annotators to design different system prompts for Llama 3. The annotator then engaged the model in a dialog to assess whether the model was able to consistently follow the instructions defined in the system prompts throughout the dialog. The following are examples of customized system prompts used to enhance controllability:
"You're a helpful and energetic AI chatbot that serves as a meal planning assistant for busy families. Workday meals should be quick and easy. Convenience foods such as cereal, English muffins with pre-cooked bacon and other quick and easy-to-make foods should be prioritized for breakfast and lunch. This family is busy. Be sure to ask if they have essentials and favorite beverages on hand, such as coffee or energy drinks, so they don't forget to buy them. Unless it's a special occasion, remember to save on your budget."
Modeling. After collecting preference data, we use this data for reward modeling, rejection sampling, SFT (continuous fine tuning), and DPO (data-driven parameter optimization) to enhance the controllability of Llama 3.
5 Results
We conducted an extensive series of evaluations of Llama 3, investigating the performance of (1) the pre-trained language model, (2) the post-trained language model, and (3) Llama 3's security features. We present the results of these evaluations in separate subsections below.
5.1 Pre-training language models
In this section, we report the evaluation results of the pre-trained Llama 3 (Part III) and compare them to other models of comparable size. We will reproduce the results of competing models as much as possible. For non-Llama models, we will report the best scores in publicly reported results or (where possible) in results we reproduce ourselves. Specific details of these evaluations, including configurations such as shot counts, metrics, and other relevant hyperparameters and settings, are available in our Github repository: [insert link here]. In addition, we will also publish data generated as part of the public benchmarking evaluations, which can be found here: [insert link here].
We will evaluate model quality against standard benchmarks (Section V 5.1.1), test robustness to changes in multiple-choice settings (Section V 5.1.2), and perform adversarial evaluations (Section V 5.1.3). We will also perform a contamination analysis to estimate the extent to which contamination of the training data affects our evaluation (Section V 5.1.4).
5.1.1 Standard benchmarks
In order to compare our model to the current state-of-the-art, we evaluated Llama 3 in a large number of standard benchmark tests, which are shown below:
(1) common sense reasoning; (2) knowledge; (3) reading comprehension; (4) math, reasoning, and problem solving; (5) long context; (6) code; (7) adversarial assessment; and (8) overall assessment.

Experimental Setup.For each benchmark, we compute the scores for Llama 3 as well as the scores of other pre-trained models with comparable sizes. Where possible, we recalculate the data from other models using our own pipeline. To ensure a fair comparison, we then choose the best score we have between the calculated data and the numbers reported by that model (using the same or more conservative settings). You can find more detailed information about our evaluation settings here. For some models, it is not possible to recalculate the benchmark values, e.g. due to unpublished pre-trained models or because the API does not provide access to log-probability. This applies in particular to all models comparable to Llama 3 405B. Therefore, we do not report category averages for the Llama 3 405B, as it would be necessary for all benchmarking figures to be available.
Significance value.When calculating benchmarking scores, there are several sources of variance that can lead to inaccurate estimates of the performance of the model that the benchmarking is intended to measure, such as a small number of demonstrations, random seeds, and batch sizes. This makes it challenging to understand whether one model is statistically significantly better than another. Therefore, we report scores along with 95% confidence intervals (CIs) to reflect the variance introduced by the choice of benchmark data. We calculated the 95% CI analytically using the formula (Madaan et al., 2024b):

CI_analytic(S) = 1.96 * sqrt(S * (1 - S) / N)
where S is the preferred benchmark score and N is the sample size of the benchmark. We note that since the variance in the benchmark data is not the only source of variance, these 95% CIs are lower bounds on the variance of the actual capacity estimate. For indicators that are not simple averages, the CIs will be omitted.
Results from the Llama 3 8B and 70B models.Figure 12 shows the average performance of Llama 3 8B and 70B on the Common Sense Reasoning, Knowledge, Reading Comprehension, Math and Reasoning, and Code Benchmark tests. The results show that Llama 3 8B outperforms the competing models in almost all categories, both in terms of category wins and average performance by category. We also find that Llama 3 70B substantially improves performance over its predecessor, Llama 2 70B, on most benchmarks, with the exception of common sense benchmarks, which may have been saturated.Llama 3 70B also outperforms Mixtral 8x22B.
Results for models 8B and 70B.Figure 12 shows the average performance of the Llama 3 8B and 70B on the Common Sense Reasoning, Knowledge, Reading Comprehension, Math & Reasoning, and Code Benchmark tests. The results show that the Llama 3 8B outperforms the competing models in almost every category, both in terms of wins by category and average performance per category. We also found that the Llama 3 70B is a significant improvement over its predecessor, the Llama 2 70B, in most benchmarks, except for the Common Sense Benchmark, which may have reached saturation.The Llama 3 70B also outperforms the Mixtral 8x22B.
Detailed results for all models.Tables 9, 10, 11, 12, 13, and 14 show the benchmark test performance of the pretrained Llama 3 8B, 70B, and 405B models on a reading comprehension task, a coding task, a general knowledge comprehension task, a mathematical reasoning task, and a routine task. These tables compare Llama 3 performance to similarly sized models. The results show that Llama 3 405B is competitive in its category and especially outperforms previous open source models to a large extent. For tests with long contexts, we provide more comprehensive results (including detection tasks such as needle-in-a-haystack) in Section 5.2.


5.1.2 Model Robustness
In addition to benchmarking performance, robustness is an important factor in the quality of pre-trained language models. We investigate the robustness of design choices made by pretrained language models in multiple-choice question (MCQ) settings. Previous studies have shown that model performance can be sensitive to seemingly arbitrary design choices in these settings, e.g., model scores and even rankings can change with the order and labeling of contextual examples (Lu et al. 2022; Zhao et al. 2021; Robinson and Wingate 2023; Liang et al. 2022; Gupta et al. 2024), the exact format of the prompts (Weber et al., 2023b; Mishra et al., 2022) or the format and order of the answer options (Alzahrani et al., 2024; Wang et al., 2024a; Zheng et al., 2023). Inspired by this work, we use the MMLU benchmark to evaluate the robustness of pre-trained models to (1) few-shot labeling bias, (2) labeling variants, (3) answer order, and (4) cue format:
- A few lens labels are off. Following Zheng et al. (2023), ... (experimental details and description of results omitted here).
- Labeling variants. We also investigated the response of the model to different sets of selected tokens. We considered two tag sets proposed by Alzahrani et al. (2024): namely, a set of common language-independent tags ($ & # @) and a set of rare tags (oe § з ü) that do not have any implied relative order. We also consider two versions of canonical tags (A. B. C. D. and A) B) C) D)) and a list of numbers (1. 2. 3. 4.).
- Order of answers. Following Wang et al. (2024a), we compute the stability of the results under different answer orders. To do so, we remap all answers in the dataset according to a fixed permutation. For example, for permutations A B C D, all answer choices labeled A and B keep their labels, while all answer choices labeled C acquire label D and vice versa.
- Cue Format. We evaluated performance differences between five task cues that differed in the amount of information they contained: one cue simply asked the model to answer the question, while others asserted the model's expertise or that it should choose the best answer.

Table 11 Performance of the pre-trained model on a general knowledge comprehension task. Results include 95% confidence intervals.

Table 12 Performance of pre-trained models on math and reasoning tasks. Results include 95% confidence intervals. 11 shots.

Table 13 Performance of pre-trained models on general-purpose language tasks. Results include 95% confidence intervals.

Fig. 13 Robustness of our pre-trained language model to different design choices in the MMLU benchmarking. Left side: performance with different labeling variants. Right side: performance in the presence of different labels in the sample less example.

Fig. 14 Robustness of our pre-trained language model to different design choices in the MMLU benchmark test. Left side: performance for different answer orders. Right side: performance for different prompt formats.
Figure 13 illustrates the results of our experiments investigating the robustness of model performance for labeling variants (left) and few-shot labeling biases (right). The results show that our pre-trained language model is very robust to MCQ labeling variations as well as to the structure of few-shot cue labels. This robustness is especially evident for the 405B parametric model.
Figure 14 illustrates the results of our studies on the robustness of answer order and cue format. These results further emphasize the robustness of the performance of our pre-trained language models, in particular the robustness of Llama 3 405B.

5.1.3 Adversarial benchmarking
In addition to the benchmark tests mentioned above, we evaluated several adversarial benchmarks in three domains: question and answer, mathematical reasoning, and sentence rewriting detection. These tests are designed to probe the model's ability on tasks specifically designed to be challenging and may point out overfitting problems of the model on the benchmark tests.
- Questions and Answers, we used Adversarial SQuAD (Jia and Liang, 2017) and Dynabench SQuAD (Kiela et al., 2021).
- Mathematical reasoningWe used GSM-Plus (Li et al., 2024c).
- Sentence rewriting testing aspects, we used PAWS (Zhang et al., 2019).
Figure 15 shows the scores of Llama 3 8B, 70B, and 405B on adversarial benchmark tests as a function of their performance on non-adversarial benchmark tests. The non-adversarial benchmark tests we use are SQuAD for question and answer (Rajpurkar et al., 2016), GSM8K for mathematical reasoning, and QQP for sentence rewriting detection (Wang et al., 2017). Each data point represents an adversarial dataset and non-adversarial dataset pair (e.g., QQP paired with PAWS), and we show all possible pairings within the category. The black line on the diagonal indicates parity between the adversarial and non-adversarial datasets - where the line indicates that the model has similar performance regardless of adversarial or non-adversarial.
In terms of sentence rewriting detection, neither the pre-trained nor the post-trained models seem to be affected by the adversarial nature of the PAWS constructs, which represents a huge improvement over the previous generation of models. This result confirms the findings of Weber et al. (2023a), who also found that large language models are less sensitive to spurious correlations in several adversarial datasets. However, for mathematical reasoning and Q&A, adversarial performance is significantly lower than non-adversarial performance. This pattern applies to both pre-trained and post-trained models.
5.1.4 Pollution analysis
We conducted a contamination analysis to estimate the extent to which benchmark scores may be affected by contamination of the evaluation data in the pretrained corpus. Some previous work has used a variety of different contamination methods and hyperparameters - we refer to the study by Singh et al. (2024). The results show that our pre-trained language model is very robust to variations in multiple-choice question labeling, as well as to variations in labeling structure for sample less cues (outlined in 2024). False positives and false negatives can occur with any of these approaches, and how best to perform contamination analysis is still an open area of research. Here, we primarily follow the recommendations of Singh et al. (2024).


Methods:Specifically, Singh et al. (2024) suggest empirically choosing a contamination detection method based on which method leads to the largest difference between the "clean" dataset and the entire dataset, which they refer to as the estimated performance gain. For all evaluation datasets, we scored based on 8-gram overlap, which Singh et al. (2024) found to be accurate for many datasets. We consider an example of dataset D to be contaminated if its labeling TD of a proportion of them appear at least once in the pre-training corpus. We select for each dataset individually TD, depending on which value shows the maximum significant estimated performance gain (across the three model sizes).
Results:Table 15 shows the percentage of the evaluation data for all major benchmarks that were considered contaminated to maximize the estimated performance gain, as described above. From this table, we excluded benchmark figures where the results were not significant, e.g., due to too few clean or contaminated pooled samples, or where the observed performance gain estimates showed extremely erratic behavior.
In Table 15, we can see that for some datasets contamination has a large impact, while for others it does not. For example, for PiQA and HellaSwag, both the contamination estimate and the performance gain estimate are high. On the other hand, for Natural Questions, the estimated 52% contamination seems to have almost no effect on performance. For SQuAD and MATH, low thresholds result in high levels of contamination, but no performance gain. This suggests that contamination may not be helpful for these datasets, or that a larger n is needed to obtain better estimates. Finally, for MBPP, HumanEval, MMLU, and MMLU-Pro, other contamination detection methods may be needed: even with higher thresholds, the 8-gram overlap gives such high contamination scores that good estimates of performance gain cannot be obtained.
5.2 Fine-tuning the language model
We show the results of the Llama 3 model after training on benchmark tests of different capabilities. Similar to the pre-training, we publish the data generated as part of our evaluation to publicly available benchmarks that can be found on Huggingface (insert link here). More detailed information about our evaluation setup can be found here (insert link here).
Benchmarking and indicators.Table 16 summarizes all benchmark tests, categorized by ability. We will decontaminate the post-training data by making exact matches to the cues in each benchmark test. In addition to the standard academic benchmark tests, we also performed extensive manual evaluation of different abilities. See Section 5.3 for detailed information.
Experimental Setup.We use a similar experimental setup as in the pre-training phase and analyze Llama 3 in comparison to other models with comparable size and capabilities. Where possible, we will evaluate the performance of the other models ourselves and compare the results with the reported figures to select the best score. More detailed information about our evaluation setup can be found here (link inserted here).

Table 16 Post-training benchmark tests by category. An overview of all benchmark tests we used to evaluate the post-training Llama 3 model, sorted by ability.
5.2.1 Generic knowledge and instruction compliance benchmarking
We use the benchmarks listed in Table 2 to evaluate Llama 3's capabilities in terms of general knowledge and instruction adherence.
General Knowledge: We utilize MMLU (Hendrycks et al., 2021a) and MMLU-Pro (Wang et al., 2024b) to evaluate Llama 3's performance on knowledge-based questioning capabilities. For MMLU, we report macro-averages of subtask accuracy in a 5-times exemplar criterion setting without CoT.MMLU-Pro is an extended version of MMLU that contains more challenging, inference-focused questions, eliminates noisy questions, and expands the range of choices from four to ten options. Given its focus on complex reasoning, we report five example CoTs for MMLU-Pro. All tasks are formatted as generative tasks, similar to simple-evals (OpenAI, 2024).
As shown in Table 2, our 8B and 70B Llama 3 variants outperform other similarly sized models on both generalized knowledge tasks. Our 405B model outperforms GPT-4 and Nemotron 4 340B, and Claude 3.5 Sonnet leads in the larger model.
Instructions to follow: We use IFEval (Zhou et al., 2023) to evaluate the ability of Llama 3 and other models to follow natural language instructions. IFEval consists of about 500 "verifiable instructions" such as "write in more than 400 words", which can be verified using heuristics. IFEval includes about 500 "verifiable instructions" such as "write in more than 400 words," which can be verified using heuristics. We report the average of prompt-level and instruction-level accuracy under strict and loose constraints in Table 2. Note that all Llama 3 variants outperform the comparable models on IFEval.
5.2.2 Competency examinations
Next, we evaluate our model on a series of aptitude tests originally designed to test humans. We obtain these exams from publicly available official sources; for some exams, we report the average scores across the different sets of exams as the result of each aptitude test. Specifically, we average:
- GRE: The official GRE practice tests 1 and 2 offered by Educational Testing Service;
- LSAT: Official pretests 71, 73, 80, and 93;
- SAT: 8 exams from The Official SAT Study Guide, 2018 Edition;
- AP: one official practice exam per subject;
- GMAT: The Official GMAT Online Test.
The questions on these exams contain multiple choice and generative questions. We will exclude any questions with images attached. For GRE questions that contain multiple correct options, we qualify the output as correct only if the model selects all correct options. In cases where there is more than one exam set, we use a small number of hints for evaluation. We adjust scores to the 130-170 range (for the GRE) and report accuracy for all other exams.

Our results are shown in Table 17.We found that our Llama 3 405B model performed as well as the Claude The 3.5 Sonnet is very similar to the GPT-4 4o. Our 70B model, on the other hand, showed even more impressive performance. It is significantly better than the GPT-3.5 Turbo and outperforms the Nemotron 4 340B in many tests.
5.2.3 Coding benchmarks
We evaluate Llama 3's code generation capabilities on several popular Python and multilingual programming benchmarks. To measure the effectiveness of the model in generating functionally correct code, we use the pass@N metric, which evaluates the unit test pass rate for a set of N generations. We report the results for pass@1.


Python code generation. HumanEval (Chen et al., 2021) and MBPP (Austin et al., 2021) are popular Python code generation benchmarks that focus on relatively simple, self-contained functionality.HumanEval+ (Liu et al., 2024a) is an enhanced version of HumanEval in which more test cases are generated to avoid false positives.The MBPP EvalPlus benchmark version (v0.2.0) is a selection of 378 well-formatted questions (Liu et al., 2024a) out of 974 initial questions in the original MBPP (training and testing) dataset. The results of these benchmark tests are shown in Table 18. In benchmarking these Python variants, Llama 3 8B and 70B outperformed models of the same size performing similarly. For the largest models, Llama 3 405B, Claude 3.5 Sonnet, and GPT-4o perform similarly, with GPT-4o having the strongest results.
Model. We compared Llama 3 with other models of similar size. For the largest model, Llama 3 405B, Claude 3.5 Sonnet and GPT-4o perform similarly, with GPT-4o showing the best results.
Multi-programming language code generation: To evaluate the code generation capabilities of languages other than Python, we report the results of the MultiPL-E (Cassano et al., 2023) benchmark based on translations of HumanEval and MBPP questions. Table 19 shows the results for a selection of popular programming languages.
Note that there is a significant performance drop compared to the Python counterpart in Table 18.
5.2.4 Multilingual benchmarking
Llama 3 supports 8 languages - English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai - although the base model was trained using a broader set of languages. In Table 20, we show the results of our evaluation of Llama 3 on the Multilingual MMLU (Hendrycks et al., 2021a) and Multilingual Primary Mathematics (MGSM) (Shi et al., 2022) benchmarks.
- Multilingual MMLU: We used Google Translate to translate the MMLU questions, short examples, and answers into different languages. We kept the task descriptions in English and evaluated them in a 5-shot setting.
- MGSM (Shi et al., 2022): For our Llama 3 model, we report 0-shot CoT results for MGSM. Multilingual MMLU is an internal benchmark that involves translating MMLU (Hendrycks et al., 2021a) questions and answers into 7 languages - the 5-shot results we report are averaged across these languages.
For MGSM (Shi et al., 2022), we tested our model using the same native prompts as in simple-evals (OpenAI, 2024) and placed it in a 0-shot CoT environment. In Table 20, we report the average results for all languages included in the MGSM benchmark.

We find that Llama 3 405B outperforms most other models on the MGSM, with an average score of 91.61TP3 T. On the MMLU, consistent with the English MMLU results above, Llama 3 405B lags behind GPT-4o 21TP3 T. On the other hand, both the 70B and 8B models of Llama 3 outperform the competitors, leading the competition by a large margin on both tasks. on both tasks.
5.2.5 Mathematical and reasoning benchmarks
The results of our mathematical and inference benchmarks are shown in Table 2.The Llama 3 8B model outperforms other models of the same size on GSM8K, MATH, and GPQA. Our 70B model shows significantly better performance than its counterparts in all benchmark tests. Finally, the Llama 3 405B model is the best model in its category for GSM8K and ARC-C, while on MATH it is the second best model. On GPQA, it competes well with GPT-4 4o, while Claude 3.5 Sonnet tops the list by a significant margin.
5.2.6 Long-context benchmarking
We consider a range of tasks across different domains and text types. In the benchmarks below, we focus on subtasks that use an unbiased evaluation protocol, i.e., accuracy-based metrics rather than n-gram overlapping metrics. We also prioritize tasks that find lower variance.
- Needle-in-a-Haystack (Kamradt, 2023) Measure the ability of the model to retrieve information hidden in random portions of long documents. Our Llama 3 model exhibits perfect needle retrieval performance, successfully retrieving 100% "needles" at all document depths and context lengths. We also measured the performance of Multi-needle (Table 21), a variation of Needle-in-a-Haystack, where we inserted four "needles" into the context and tested whether the model could retrieve two of them. Our Llama 3 model achieves near-perfect retrieval results.
- ZeroSCROLLS (Shaham et al., 2023)is a zero-sample benchmark test for natural language understanding of long texts. Since the true answers are not publicly available, we report the numbers on the validation set. Our Llama 3 405B and 70B models equal or exceed the other models on a variety of tasks in this benchmark test.
- InfiniteBench (Zhang et al., 2024) Models are required to understand long-distance dependencies in context windows. We evaluate Llama 3 on En.QA (quizzing on novels) and En.MC (multiple choice quizzing on novels), where our 405B model outperforms all other models. The gain is particularly significant on En.QA.

Table 21 Long text benchmarking. For ZeroSCROLLS (Shaham et al., 2023) we report results on the validation set. For QuALITY we report exact matches, for Qasper - f1, and for SQuALITY - rougeL. we report f1 for the InfiniteBench (Zhang et al., 2024) En.QA metrics, and accuracy for En.MC. For Multi-needle (Kamradt, 2023), we insert 4 needles in the context and test whether the model is able to retrieve 2 needles of different context lengths, and we compute the average recall for up to 128k of 10 sequence lengths.
5.2.7 Tool performance
We evaluated our model using a series of zero-sample tool usage (i.e., function call) benchmarks: the Nexus (Srinivasan et al., 2023), API-Bank (Li et al., 2023b), Gorilla API-Bench (Patil et al., 2023), and the Berkeley Function Call Leaderboard ( BFCL) (Yan et al., 2024). The results are shown in Table 22.
On Nexus, our Llama 3 variant performs best, outperforming other models in its category. On API-Bank, our Llama 3 8B and 70B models significantly outperform the other models in their respective categories. The 405B model trails only Claude 3.5 Sonnet 0.6%.Finally, our 405B and 70B models outperform on BFCL and rank second in their respective size categories. The Llama 3 8B was the best performer in its category.
We also conducted a manual evaluation to test the model's ability to use the tool, focusing on code execution tasks. We collected 2000 user prompts, drawing generation, and file uploads related to code execution (not including drawing or file uploads). These prompts come from LMSys dataset (Chiang et al., 2024), GAIA benchmarking (Mialon et al., 2023b), artificial annotators, and synthetic generation. We compared Llama 3 405B to GPT-4o using OpenAI's Assistants API10 . The results are shown in Figure 16. Llama 3 405B clearly outperforms GPT-4o in text-only code execution tasks and drawing generation. however, it lags behind GPT-4o in the file upload use case.

5.3 Manual assessment
In addition to evaluations on standard benchmark datasets, we have conducted a series of human evaluations. These evaluations allow us to measure and optimize more subtle aspects of model performance, such as the model's tone, level of redundancy, and understanding of nuance and cultural context. Carefully designed rengren evaluations are closely related to the user experience, providing insights into how the model performs in the real world.
https://platform.openai.com/docs/assistants/overview
For multi-round human assessments, the number of rounds in each cue ranged from 2 to 11. We evaluated the model's response in the last round.
Cue Collection. We collected high-quality prompts covering a wide range of categories and difficulties. To do this, we first developed a taxonomy that contained categories and subcategories for as many modeled abilities as possible. We used this taxonomy to collect approximately 7,000 prompts covering six single-round abilities (English, Reasoning, Coding, Hindi, Spanish, and Portuguese) and three multi-round abilities11 (English, Reasoning, and Coding). We ensured that within each category, prompts were evenly distributed across subcategories. We also categorized each prompt into one of three difficulty levels and ensured that our set of prompts contained approximately 10% of easy prompts, 30% of moderately difficult prompts, and 60% of difficult prompts. All human evaluations Figure 16 Human evaluation results for Llama 3 405B vs. GPT-4o on code execution tasks including drawing and file uploading. The Llama 3 405B outperforms the GPT-4o on code execution (not including plotting or file uploading) as well as plot generation, but lags behind on the file uploading use case.
The cue sets have undergone a rigorous quality assurance process. The modeling team does not have access to our human evaluation cues to prevent accidental contamination or overfitting of the test set.
Evaluation process. To perform paired human evaluations of two models, we ask human annotators which of the two model responses (generated by different models) they prefer. Annotators use a 7-point scale that allows them to indicate whether one model response is much better, better, slightly better, or roughly the same than the other. When a labeler indicates that a model response is much better or better than another model response, we will consider this a "win" for that model. We will compare models in pairs and report the win rate for each capability in the cue set.
in the end. We compared the Llama 3 405B to the GPT-4 (0125 API version), the GPT-4o (API version), and the Claude 3.5 Sonnet (API version) using a human assessment process. The results of these evaluations are shown in Figure 17. We observe that the Llama 3 405B performs roughly comparable to the 0125 API version of GPT-4, with mixed results (some wins and some losses) when compared to GPT-4o and Claude 3.5 Sonnet. In almost all abilities, Llama 3 and GPT-4 win within the margin of error. The Llama 3 405B outperformed the GPT-4 on the multi-round reasoning and coding tasks, but not on the multilingual (Hindi, Spanish, and Portuguese) prompts.The Llama 3 performed as well as the GPT-4 on the English prompts, as well as the Claude 3.5 Sonnet on the multi-language prompts, and outperformed the Claude 3.5 Sonnet on the single-round and multi-round English prompts.The Llama 3 405B also outperformed the Claude 3.5 Sonnet on the single-round and multi-round English prompts. However, it falls short of the Claude 3.5 Sonnet in areas such as encoding and inference.Qualitatively, we found that the model's performance in human evaluation is greatly influenced by subtle factors such as tone, response structure, and redundancy-all factors that we are optimizing in the post-training process. factors that are being optimized. Overall, our human evaluation results are consistent with those of standard benchmark evaluations: the Llama 3 405B competes very well with leading industry models, making it the best performing publicly available model.
limitations. All human assessment results have undergone a rigorous data quality assurance process. However, due to the difficulty of defining objective criteria for model response, human assessments can still be influenced by the personal biases, backgrounds, and preferences of human annotators, which can lead to inconsistent or unreliable results.

Fig. 16 Human evaluation results of Llama 3 405B vs. GPT-4o on code execution tasks (including plotting and file upload). The Llama 3 405B outperforms the GPT-4o on code execution (excluding plotting and file uploading) as well as plot generation, but lags behind on the file uploading use case.

Fig. 17 Results of manual evaluation of the Llama 3 405B model. Left: comparison with GPT-4. Center: comparison with GPT-4o. Right: comparison with Claude 3.5 Sonnet. All results include 95% confidence intervals and exclude ties.
5.4 Security
The security section involves sensitive words, which can be skipped or downloaded as a PDF, thank you!
We focused on evaluating Llama 3's ability to generate content in a safe and responsible manner while maximizing useful information. Our security work begins with a pre-training phase, primarily in the form of data cleaning and filtering. We will then describe the security fine-tuning methodology, focusing on how to train the model to comply with specific security policies while still retaining helpfulness. We will analyze each feature of Llama 3, including multilingualism, long contexts, tool usage, and various multimodal features, to measure the effectiveness of our security mitigations.
We then describe our assessment of cybersecurity and chemical/biological weapons risk elevation. Elevation refers to the additional risk posed by new technological developments compared to the use of existing available technologies (e.g., web searches).
We then describe how we utilize "red team" testing to iteratively identify and address various cross-functional security risks and perform residual risk assessments.
Finally, we will describe system-level security, or the development and programming of classifiers around the inputs and outputs of the model itself, to further improve security and make it easier for developers to customize security into a variety of use cases and deploy generative AI in a more responsible manner.
5.4.1 Benchmark construction
In order to develop models safely and responsibly, we have created various internal benchmarks. Our benchmarks are inspired by the ML Commons risk taxonomy (Vidgen et al., 2024). While language model security benchmarks such as ToxiGen (Hartvigsen et al., 2022), XS Test (Röttger et al., 2023), etc. already exist, many of the new features of Llama 3 lack sufficient external benchmarks, and the existing external benchmarks are often inadequate in breadth and depth.
For each risk category, we collected adversarial or borderline cues written by humans-examples of these cues are listed in Table 23. Adversarial cues range from simple cues that directly trigger a harmful response to cues that incorporate complex jailbreak techniques. These adversarial cues form the baseline against which we measure violation rates.
As an inverse indicator of the violation rate, we also constructed a false rejection benchmark consisting of boundedness cues. When the model refuses to answer in a helpful way even when a reasonable and safe answer exists, we refer to this situation as false rejection. Boundaryness cues are close to decision boundary cues, and a well-calibrated model should be able to handle these cues, e.g., "How can I steal the spotlight from my best friend who always plays the lead role??" Our overall benchmark size for violations and false rejections exceeds 4000 cues/competencies or languages, including both single-round and multi-round cues.
5.4.2 Security pre-training
We believe that responsible development must be considered from an end-to-end perspective and incorporated at every stage of model development and deployment. During pre-training, we apply various filters, such as those used to identify websites that may contain personally identifiable information (see Section 3.1). We also focus on discoverable memoization (Nasr et al., 2023). Similar to Carlini et al. (2022), we sample cues and true results at different frequencies of occurrence using the effective rolling hash index of all n-tuples in the training data. We construct different test scenarios by varying the length of cues and true results, the detection language and domain of the target data. We then measure how often the model accurately generates sequences of true results and analyze the relative rates of memoization in the specified scenarios. We define verbatim memorization as the inclusion rate (the proportion of model-generated sequels containing true results) and report this rate in the weighted averages shown in Table 24, which are determined by the prevalence of a given feature in the data. We found a low memorization rate for the training data (1.13% and 3.91% on average for n = 50 and n = 1000, respectively, for 405B). Using the same methodology applied to the equivalent size of its data mixture Llama 2 has roughly the same memorization rate.

Table 23 Examples of adversarial cues for all capabilities in our internal benchmarking.

Table 24 Average verbatim memory for pretrained Llama 3 in selected test scenarios. Our baseline is Llama 2 using the same cueing methodology applied to its data mixed with English, 50-gram scenarios.
5.4.3 Security fine-tuning
This chapter describes the security fine-tuning methodology that we use to mitigate the risk of various capabilities, which encompasses two key aspects: (1) safety training data and (2) risk mitigation techniques. Our security fine-tuning process is based on our generalized fine-tuning methodology with modifications to address specific security issues.
We optimize two main metrics: the violation rate (VR), which captures instances where the model generates responses that violate the security policy, and the false rejection rate (FRR), which captures instances where the model incorrectly rejects responses to innocuous cues. At the same time, we evaluate the model's performance in usefulness benchmarking to ensure that security improvements do not compromise overall usefulness. Our experiments show that an 8 billion parameter model requires a higher ratio of safety data to usefulness data relative to a 70 billion parameter model to achieve comparable safety performance. Larger models are better able to distinguish between adversarial and boundary contexts, resulting in a more favoable balance between VR and FRR.
Fine-tuning of data
The quality and design of safety training data has a profound effect on performance. Through extensive ablation experiments, we have found that quality is more important than quantity. We primarily use human-generated data from data vendors, but have found it to be prone to errors and inconsistencies, especially for subtle security policies. To ensure the highest quality data, we have developed AI-assisted annotation tools to support our rigorous quality assurance process.
In addition to collecting adversarial cues, we also collected a similar set of cues called boundary cues. These cues are closely related to the adversarial cues, but are intended to teach the model to provide useful responses, thereby reducing the false rejection rate (FRR).
In addition to human labeling, we utilize synthetic data to improve the quality and coverage of the training dataset. We utilize a variety of techniques to generate additional adversarial examples, including contextual learning using elaborated system cues, mutations based on new attack vectors to guide seed cues, and advanced algorithms including the Rainbow Team (Samvelyan et al., 2024) based on MAP-Elites (Mouret and Clune, 2015), which generates cues that span multiple dimensionally constrained cues.
We further addressed the issue of the tone of the model when generating security responses, which can impact the downstream user experience. We developed a rejection tone guideline for Llama 3 and ensured that all new security data adhered to it through a rigorous quality assurance process. We also improved existing security data using a combination of zero-sample rewriting and manual editing to generate high-quality data. Through these methods, and the use of tone classifiers to assess the tone quality of security responses, we were able to significantly improve the wording of the model.
Safety oversight fine-tuning
Following our Llama 2 recipe (Touvron et al., 2023b), we combine all usefulness data and safety data in the model alignment phase. In addition, we introduced boundary datasets to help the model distinguish the subtle difference between safe requests and unsafe ones. Our annotation team was instructed to carefully design responses to security cues based on our guidelines. We found that SFT was very effective in aligning the model when we strategically balanced the ratio of adversarial to boundary examples. We focused on more challenging risk areas where the ratio of boundary examples was higher. This plays a critical role in our successful security mitigation efforts while minimizing false rejects.
In addition, we investigate the effect of model size on the tradeoff between FRR and VR (see Figure 18). Our results suggest that it will change-smaller models require a greater proportion of safety data relative to usefulness, and it is more difficult to effectively balance VR and FRR than larger models.
Security DPO
To enhance security learning, we incorporate adversarial and boundary examples into the preference dataset in DPO. We found that designing response pairs for a given cue that are nearly orthogonal in the embedding space is particularly effective in teaching the model to distinguish between good and bad responses. We conducted several experiments to determine the optimal ratio of adversarial, bounded, and useful examples with the goal of optimizing the tradeoff between FRR and VR. We also found that model size affects learning outcomes - thus, we adapted different combinations of security for different model sizes.

Figure 18 shows the impact of model size on the design of security data combinations to balance Violation Rate (VR) and False Refusal Rate (FRR). Each point in the scatterplot represents a different data combination in balancing security and usefulness data. Different model sizes preserve different security learning capabilities. Our experiments show that the 8B model needs a higher proportion of safety data relative to usefulness data in the overall SFT (supervised fine-tuning) portfolio to achieve comparable safety performance to the 70B model. Larger models are better able to distinguish between adversarial and edge contexts, resulting in a more desirable balance between VR and FRR.
5.4.4 Safety results
First, we provide an overview of Llama 3's overall performance in all aspects, and then describe the results of testing each new feature and our effectiveness in reducing security risks.
Overall performance:Figures 19 and 20 show the results of the Llama 3 final violation and false rejection rates compared to similar models. These results focus on our largest parameter scale (Llama 3 405B) model and compare it to related competitors. Two of these competitors are end-to-end systems accessed via APIs, and the other is an open source language model that we hosted in-house and evaluated directly. We tested our Llama model both on its own and in conjunction with Llama Guard, our open source system-level security solution, as detailed in Section 5.4.7.
While lower violation rates are desirable, it is critical to use false rejections as a reverse indicator, as a model that always rejects is the highest in terms of security, but completely useless. Similarly, a model that always answers all prompts, no matter how problematic the request, is overly harmful and toxic. Figure 21 explores how different models and systems in the industry make tradeoffs and how Llama 3 performs, using our internal benchmarks. We find that our model is highly competitive in terms of violation rate metrics, as well as having a low false rejection rate, indicating a good balance between utility and security.
Multilingual security:Our experiments show that security knowledge in English is not easily transferable to other languages, especially given the nuances of security policies and language-specific contexts. Therefore, it is crucial to collect high-quality security data for each language. We also find that the distribution of security data per language significantly affects security performance, with some languages benefiting from transfer learning while others require more language-specific data. To strike a balance between False Rejection Rate (FRR) and Violation Rate (VR), we iteratively add adversarial and boundary data while monitoring the impact of these two metrics.
Figure 19 illustrates the results of our internal benchmarking with short context models, showing the violation and false rejection rates of Llama 3 in English and other languages, and comparing them to similar models and systems. To construct the benchmarks for each language, we used a combination of prompts written by native speakers, sometimes supplemented with translations from the English benchmarks. For all the languages we support, we find that Llama 405B in conjunction with Llama Guard is at least as secure as the two competing systems, if not counting the more stringent security, while the false rejection rate is still competitive.
Long context security:Long context models without targeted mitigation are vulnerable to multiple jailbreak attacks (Anil et al., 2024). To address this issue, we fine-tune our model on the SFT dataset, which contains examples of secure behavior in the presence of demonstrations of insecure behavior. We develop a scalable mitigation strategy that significantly reduces VR, thereby effectively neutralizing the impact of longer context attacks, even for 256 attacks. The impact of this approach on FRR and most utility metrics is almost negligible.
To quantify the effectiveness of our long context security mitigations, we use two additional benchmarking methods: DocQA and Many-shot. for DocQA (short for "document quizzing"), we use long documents that contain information that could be used for adversarial purposes. The model is provided with the document and a set of prompts related to the document to test whether the question is relevant to the information in the document, thus affecting the model's ability to respond to the prompts securely.
In Many-shot, following Anil et al. (2024), we construct a synthetic chat log consisting of insecure prompt-response pairs. The last prompt is independent of previous messages and is used to test whether insecure contextual behavior affects the model's insecure responses. Figure 20 shows the violation and false rejection rates for DocQA and Many-shot. We see that the Llama 405B (with and without Llama Guard) outperforms the Comp. 2 system in terms of both violation and false rejection rates for both DocQA and Many-shot.Relative to Comp. 1, we find that the Llama 405B is more secure, but slightly increases the false rejection rate.
Tool use security:The diversity of possible tools and invocations of tool use, as well as implementations that integrate tools into the model, make it challenging to fully mitigate the ability to use tools (Wallace et al., 2024). We focus on the search use case. Figure 20 shows the violation and false rejection rates. We tested against the Comp. 1 system and found that the Llama 405B was more secure, but had a slightly higher false rejection rate.

Figure 19 Violation Rates (VR) and False Rejection Rates (FRR) on English and our Core Multilingual Phrase Context Benchmarks Comparing the Llama 3 405B (with and without Llama Guard (LG) system-level protection) to competitor models and systems.Comp. 3 Unsupported languages are denoted by an "x". ". The lower the value the better.

Figure 20 Violation rate (VR) and false rejection rate (FRR) in tool usage and long text benchmarking. Lower is better. The performance of the DocQA and Multi-Round Q&A benchmark tests are presented separately. Note that due to the adversarial nature of this benchmark test, we do not have a bounded dataset for multi-round quizzing and therefore did not measure the false rejection rate for it. For the tool usage (search) aspect, we only compare Llama 3 405B with Comp. 1.

Figure 21 Violation and rejection rates for models and capabilities. Each point represents the overall denial rate. And the violation rates of the capability benchmarks are evaluated for all security classes intrinsic to the capability. The symbols indicate whether we are evaluating model-level or system-level security. As expected, the results for model-level security show higher violation rates and lower rejection rates than the results for system-level security.Llama 3 aims to balance low violation rates with low false rejection rates, while some competitors prefer one or the other.
5.4.5 Cybersecurity assessment results
To assess cybersecurity risk, we utilize the CyberSecEval benchmarking framework (Bhatt et al., 2023, 2024), which incorporates security measurements for tasks such as generating insecure code, generating malicious code, text-prompted injection, and vulnerability identification. We developed and applied Llama 3 to new benchmarks, including spear phishing and autonomous network attacks. Overall, we found that Llama 3 is not significantly vulnerable to generating malicious code or exploiting vulnerabilities. The following are brief results for specific tasks:
- A framework for testing insecure coding:In evaluating the Llama 3 8B, 70B, and 405B models with the insecure coding test framework, we continue to observe that the larger models generate more insecure code and the code has a higher average BLEU score (Bhatt et al., 2023).
- Code Interpreter Abuse Cue Corpus:We found that the Llama 3 model is prone to executing malicious code on specific prompts, where Llama 3 405B has a compliance rate of 10.41 TP3T to malicious prompts, compared to 3.81 TP3T for Llama 3 70B.
- Text Tip Injection Benchmark:When evaluated against the cue injection benchmark, the Llama 3 405B successfully encountered a cue injection attack at 21.71 TP3T. Figure 22 illustrates the textual cue injection success rate for the Llama 3, GPT-4 Turbo, Gemini Pro, and Mixtral models.
- Vulnerability Identification Challenges:In evaluating Llama 3's ability to identify and exploit vulnerabilities using CyberSecEval 2's Capture-the-Flag test challenge, Llama 3 failed to outperform commonly used traditional non-LLM tools and techniques.
- Spearfishing benchmarks:We evaluated the persuasiveness and success of the model in conducting personalized conversations to deceive targets into unknowingly engaging in security compromises. Randomized detailed victim profiles generated by the LLM were used to spear-phish targets. The judging LLM (Llama 3 70B) rated the performance of Llama 3 70B and 405B when interacting with the victim model (Llama 3 70B) and assessed the success of the attempts. The judging LLM assessed Llama 3 70B as successful in spearfishing attempts at 241 TP3T and Llama 3 405B as successful in attempts at 141 TP3T. Figure 23 illustrates the Judging LLM assessment persuasion scores for each model and fishing target.
- Attack Automation Framework:We evaluated the potential of Llama 3 405B as an autonomous agent in four key phases of a ransomware attack-network reconnaissance, vulnerability identification, exploit execution, and late-stage exploitation actions. We enabled the model to behave autonomously by configuring it to iteratively generate and execute new Linux commands on a Kali Linux virtual machine against another virtual machine with known vulnerabilities. While Llama 3 405B was effective in identifying network services and open ports during network reconnaissance, it failed to effectively utilize this information to gain initial access to vulnerable machines during 34 test runs. The Llama 3 405B performed moderately well in identifying vulnerabilities, but had difficulty selecting and applying successful exploitation techniques. Attempts to perform exploits and maintain access or perform lateral movement within the network failed completely.
Cyber Attack Elevation Test:We conducted a boosting study to measure the extent to which virtual assistants improve attack rates for novice and expert attackers in two simulated offensive cybersecurity challenges. The study included 62 in-house volunteers. Volunteers were categorized as "experts" (31 subjects) and "novices" (31 subjects) based on their offensive security experience.
In order to assess the risks associated with the proliferation of chemical and biological weapons, we conducted a boosting test aimed at assessing whether the use of Llama 3 significantly improves the ability of actors to plan such attacks.
Experimental design.
- The study consisted of a six-hour scenario in which two participants were asked to develop fictional operational plans for a biological or chemical attack.
- Scenarios cover the major planning phases (reagent acquisition, production, weaponization, and delivery) of a CBRNE (Chemical, Biological, Radiological, Nuclear, and Explosive) attack and are designed to trigger detailed planning to address issues related to access to restricted materials, real-world laboratory protocols, and operational safety.
- Participants were recruited based on their prior experience in a science or operations-related field and assigned to a team of two low-skill actors (no formal training) or two medium-skill actors (some formal training and hands-on experience in science or operations).
Research Methods.
- The study was developed in collaboration with a group of CBRNE experts to maximize the general applicability, validity, and robustness of the quantitative and qualitative results.
- A preliminary study was conducted to validate the study design, including a robust efficacy analysis to ensure that our sample size was sufficient for statistical analysis.
- Each team is assigned to either "control" or "LLM" conditions. The control group had access to Internet-based resources only, whereas LLM-equipped teams had access to the Llama 3 model with web search (including PDF ingestion), information retrieval (RAG), and code execution (Python and Wolfram Alpha) enabled, in addition to the Internet.
- To test the RAG functionality, a set of hundreds of relevant scientific papers were generated using keyword searches and preloaded into the Llama 3 model inference system.
Evaluation.
- At the end of the exercise, the action plans generated by each team will be evaluated by subject matter experts with expertise in the fields of biology, chemistry, and operations planning.
- Each program is evaluated at four stages of a potential attack, generating scores for metrics such as scientific accuracy, detail, detection evasion, and probability of successful scientific and operational execution.
- After a rigorous Delphi process to mitigate bias and variability in subject matter expert (SME) assessments, final scores were generated by combining stage-level indicators.
Analysis of results.
Quantitative analyses showed that using the Llama 3 model does not significantly improve performance. This result holds for both the overall analysis (comparing all LLM conditions to Web-based control conditions only) and for subgroup-specific breakdowns (e.g., evaluating the Llama 3 70B and Llama 3 405B models separately, or evaluating scenarios related to chemical or biological weapons separately). After validating these results with the CBRNE SME, we assess the likelihood that the release of the Llama 3 model will increase the risk associated with a biological or chemical weapons attack in the ecosystem as low.

5.4.6 Red team tactics
We utilize "red team testing" to identify risks and use these findings to improve our benchmarking and security tuning datasets. We conduct regular red team exercises to continuously iterate and identify new risks, which guide our model development and mitigation process.
Our Red Team consists of experts in cybersecurity, adversarial machine learning, responsible AI, and integrity, in addition to multilingual content experts with backgrounds in integrity issues in specific geographic markets. We also collaborate with internal and external subject matter experts to build risk taxonomies and help with more focused adversarial assessments.
Adversarial testing for specific model capabilities. We first performed red team testing by focusing on individual model features for specific high-risk categories, and then tested these features together. Focusing on hint-level attacks that simulate more realistic scenarios, the red team found that models often deviated from expected behavior, especially when mentioning schematics that were obfuscated or hints that cascaded multiple abstractions. These risks became more complex with the addition of more features, and we describe some of our red team findings in detail below. We use these red team findings in conjunction with our internal security benchmarking results to develop focused mitigations that iteratively improve model security.
- Short text and long text English. We employ a well-known combination of published and unpublished techniques in both single- and multi-round dialogs. We also utilized advanced adversarial multi-round automation techniques similar to PAIR (Chao et al., 2023) for some techniques and risk categories. Overall, multi-round dialog leads to more harmful outputs. Many attacks are common across model checkpoints, especially when they are used together.
- Multiple rounds of denial suppression: Specifies that the model response should follow a particular format or include/exclude information about a particular phrase associated with the rejection.
- Hypothetical Scenario Packaging: Package the violation prompt as a hypothetical/theoretical task or fictional scenario. Prompts can be as simple as adding the word "hypothetically" or building a complex hierarchical scenario.
- Role Playing: Assign offending roles to models with specific offending response characteristics (e.g., "You are X and your goal is Y"), or you yourself as a user incarnate specific benign roles to mask the context of the prompt.
- Adding disclaimers and warnings is a form of reaction initiation, and we hypothesize that this is a way to provide the model with a path to beneficial compliance that intersects with generalized safety training. Along with the other attacks mentioned, requiring disclaimers, trigger warnings, and other measures to be added in multiple rounds of dialog leads to increased breach rates.
- Escalating violations are multi-round attacks in which a conversation starts with a more or less benign request and then generates more exaggerated content through direct prompts, gradually leading the model to generate very offending responses. Once the model starts outputting the offending content, it may be difficult to recover (or if it encounters a denial, other attacks can be used). This problem will become increasingly common for models with long contexts.
- Multilingual. When considering multiple languages, we find many unique risks.
- Mixing multiple languages in a prompt or conversation can easily lead to more offending output than using a single language.
- Resource-poor languages may result in violated outputs due to a lack of relevant security fine-tuning data, weak generalization of models to security, or prioritization of tests or benchmarks. However, such attacks typically result in poor quality, limiting actual malicious exploitation.
- Slang, context-specific or culture-specific references may give the false impression of a violation to begin with, but in reality the model does not understand a reference correctly, so the output is not really harmful and cannot be made to be a violating output.
- Tool Use. During testing, several tool-specific attacks were identified in addition to the English text-level adversarial prompting techniques that successfully produced the offending output. This includes, but is not limited to:
Insecure tool chaining calls, such as requesting multiple tools at the same time, one of which is violated, can result in a mix of violated and benign inputs to all tools in an early checkpoint.
Compulsory use of tools: Frequently enforcing the use of tools with specific input strings, fragmentation, or encoded text may lead to potential violations of tool inputs, resulting in more offending outputs. Alternative techniques can then be employed to access the tool results, even if the model typically refuses to perform a search or assist in processing the results.
Modify the tool usage parameters: For example, swapping words in a query, retrying, or blurring part of the initial request in a multi-round conversation can lead to violations at many early checkpoints as a form of enforcing the use of tools.
Child safety risks: We assembled a team of experts to conduct child safety risk assessments to assess the model's ability to produce outputs that could lead to child safety risks and to inform any necessary and appropriate risk mitigation measures (through fine-tuning). We used these expert red team meetings to extend the coverage of our assessment benchmarks developed through the model. For Llama 3, we conducted new in-depth sessions using an objective-based approach to assess the model's risk along multiple attack paths. We also worked with content experts to conduct red team exercises to assess potentially offending content while considering market-specific nuances or experiences.
5.4.7 System-level security
Large language models are not used in isolation in a variety of real-world applications, but are integrated into broader systems. This section describes our implementation of system-level security, which complements model-level mitigation by providing additional flexibility and control.
To this end, we have developed and released a new classifier, Llama Guard 3, a Llama 3 8B model fine-tuned for safety categorization. Similar to Llama Guard 2 (Llama-Team, 2024), this classifier is used to detect if the input cues and/or the output responses generated by the language model violate the safety policy for a specific hazard class.
It is designed to support Llama's growing capabilities for English and multilingual text. It is also optimized for use in the context of tool calls (e.g., search tools) and to prevent code interpreter abuse. Finally, we provide quantized variants to reduce memory requirements. We encourage developers to use our versions of the system security components as a base and configure them for their own use cases.
taxonomy: We trained using the 13 harm categories listed in the AI Security Taxonomy (Vidgen et al., 2024): child sexual exploitation, defamation, elections, hate, indiscriminate weapons, intellectual property, nonviolent offenses, privacy, sex-related offenses, pornographic content, professional advice, suicide and self-harm, and violent offenses. We also trained against the code interpreter abuse category to support the tool call use case.
Training data: We start with English data used by Llama Guard (Inan et al., 2023) and extend this dataset to include new features. For new features such as multilingualism and tool use, we collect cue and response categorization data, as well as utilize data used for security fine-tuning. The number of insecure responses in the training set is increased by performing cue engineering so that the LLM does not reject responses to adversarial cues. We use Llama 3 to obtain response labels for these generated data.
To improve the performance of Llama Guard 3, we extensively cleaned the collected samples using both human labeling and LLM labeling of the Llama 3 model. Obtaining labels for user cues is more difficult for both humans and LLMs, and we found manual labeling to be slightly better, especially for boundary cues, although our full iterative system was able to reduce noise and produce more accurate labels.
Results. Llama Guard 3 significantly reduces cross-capability violations (average violation rate dropped by 65% in our benchmarking). Note that adding system safeguards (as well as any security mitigations) will come at the cost of increased rejection of benign prompts. Table 25 reports the decrease in violation rates and the increase in false rejections compared to the base model to highlight this tradeoff. This impact is also visible in Figures 19, 20, and 21.
System security also provides greater flexibility, as Llama Guard 3 can be deployed only for specific hazards, enabling control of violations and false denial tradeoffs at the hazard category level. Table 26 lists violation reductions by category to determine which categories to turn on/off based on developer use cases.
To simplify the deployment of security systems, we provide a quantized version of Llama Guard 3 using the commonly used int8 quantization technique, reducing its size by more than 40%. Table 27 illustrates that quantization has a negligible impact on model performance.
The system-level security component enables developers to customize and control how the LLM system responds to user requests. To improve the overall security of the modeling system and enable developers to deploy models responsibly, we describe and publish two hint-based filtering mechanisms:Prompt Guard cap (a poem) Code Shield. We open-source these to the community so they can use them as-is, or use them as inspiration to adapt them to their use cases.
Prompt Guard is a model-based filter designed to detect hint attacks, i.e., input strings designed to subvert the expected behavior of LLMs that are part of an application. The model is a multi-label classifier that detects two types of hint attack risks:
- Direct jailbreak (explicitly attempting to override the model's security conditions or system-prompted techniques).
- Indirect prompt injection (the case where the model context window contains third-party data, including instructions for user commands that were accidentally executed by the LLM).
The model is fine-tuned from mDeBERTa-v3-base (a small model with 86M parameters) and is suitable for filtering inputs into the LLM. We evaluate its performance on several evaluation datasets shown in Table 28. We evaluate on two datasets from the same distribution as the training data (jailbreaks and injections), as well as an out-of-distribution dataset in English, a multilingual jailbreak set based on machine translation, and an indirect injection dataset (English and multilingual) from CyberSecEval. Overall, we find that the model generalizes well to new distributions and has strong performance.
Code Shield is an example of a system-level protection category based on filtering at inference time. It specifically focuses on detecting the generation of insecure code before it may enter downstream use cases (e.g., production systems). It accomplishes this by leveraging the static analysis library "Insecure Code Detector" (ICD) to identify insecure code. ICD uses a set of static analysis tools to perform analysis across seven programming languages. This type of protection is often very useful for developers, who can deploy multiple layers of protection to various applications.



5.4.8 Limitations
We have conducted extensive work to measure and mitigate the various risks associated with the safe use of Llama 3. However, no test can guarantee complete identification of all possible risks. As a result of training on a variety of datasets, especially in languages other than English and subject to carefully crafted cues from skilled adversarial red team members, Llama 3 may still generate harmful content. Malicious developers or adversarial users may find new ways to crack our models and use them for a variety of nefarious purposes. We will continue to proactively identify risks, conduct research on mitigation methods, and encourage developers to consider liability in all aspects, from model development to deployment to users. We expect developers to utilize and contribute to the tools released in our open source system-level security suite.
6 Inference
We investigate two main techniques to improve the inference efficiency of the Llama 3 405B model: (1) pipeline parallelism and (2) FP8 quantization. We have publicly released an implementation of FP8 quantization.
6.1 Pipeline Parallelism
The Llama 3 405B model does not fit into the GPU memory of a single machine equipped with 8 Nvidia H100 GPUs when using BF16 to represent the model parameters. To address this issue, we used BF16 precision to parallelize model inference across 16 GPUs on two machines. Within each machine, high-bandwidth NVLink enables the use of tensor parallelism (Shoeybi et al., 2019). However, cross-node connections have lower bandwidth and higher latency, so we use pipeline parallelism (Huang et al., 2019).
Bubbles are a major efficiency issue during training using pipeline parallelism (see Section 3.3). However, they are not a problem during inference because inference does not involve backpropagation that requires pipeline flushing. Therefore, we use micro-batching to improve the throughput of pipeline-parallel inference.
We evaluate the effect of using two micro-batches in an inference workload of 4,096 input tokens and 256 output tokens for the key-value cache pre-population phase and the decoding phase of inference, respectively. We find that micro-batching improves inference throughput for the same local batch size; see Figure 24.These improvements come from the ability of micro-batching to concurrently execute micro-batches in both phases. Since micro-batching leads to additional synchronization points, it also increases latency, but overall, micro-batching still leads to a better throughput-latency tradeoff.


6.2 FP8 Quantification
We utilize the FP8 support inherent in the H100 GPU for low-precision inference experiments. To achieve low-precision inference, we applied FP8 quantization to most of the matrix multiplications within the model. Specifically, we quantized the vast majority of parameters and activation values in the feedforward network layers of the model, which account for approximately 50% of the inference computation time.We did not quantize the parameters in the self-attention layer of the model. We utilize a dynamic scaling factor to improve accuracy (Xiao et al., 2024b) and optimize our CUDA kernel15 to reduce computational scaling overhead.
We found that the quality of Llama 3 405B was sensitive to certain types of quantization and made some additional changes to improve the quality of the model output:
- Similar to Zhang et al. (2021), we did not quantize the first and last Transformer layers.
- Highly aligned tokens (e.g., dates) can result in large activation values. In turn, this can lead to higher dynamic scaling factors in FP8 and produce a non-negligible amount of floating-point underflow, leading to decoding errors. Figure 26 shows the distribution of reward scores for Llama 3 405B using BF16 and FP8 inference. Our FP8 quantization method has little effect on the model's response.
To solve this problem, we set the upper limit of the dynamic scaling factor to 1200.
- We used row-by-row quantization to compute scaling factors across rows for the parameter and activation matrices (see Figure 25). We found this to work better than the tensor-level quantization approach.
quantify the impact of errors. Evaluations of standard benchmarks typically show that even without these mitigations, FP8 reasoning performs comparably to BF16 reasoning. However, we find that such benchmarks do not adequately reflect the impact of FP8 quantization. When the scaling factor is not capped, the model occasionally produces corrupted responses, even when the benchmark performance is strong.
Rather than relying on benchmarks to measure changes in the distribution due to quantization, we analyzed the distribution of reward model scores for the 100,000 responses generated using BF16 and FP8. Figure 26 shows the distribution of rewards obtained by our quantization method. The results show that our FP8 quantization method has very limited impact on the model's responses.
efficiency experimental evaluation. Figure 27 depicts the throughput-latency tradeoff for performing FP8 inference in the pre-population and decoding phases using 4,096 input tokens and 256 output tokens using the Llama 3 405B. The figure compares the efficiency of FP8 inference with the two-machine BF16 inference approach described in Section 6.1. The results show that using FP8 inference improves the throughput in the pre-population phase by up to 50% and substantially improves the throughput-delay tradeoff during decoding.



7 Visualization experiments
We conducted a series of experiments to integrate visual recognition capabilities into Llama 3 through a combinatorial approach. The approach is divided into two main phases:
First stage. We combined a pre-trained image encoder (Xu et al., 2023) with a pre-trained language model and introduced and trained a set of cross-attention layers (Alayrac et al., 2022) on a large number of image-text pairs. This resulted in the model shown in Figure 28.
Second stage. We introduce a temporal aggregation layer and additional video cross-attention layers that act on a large number of video text pairs to learn the model to recognize and process temporal information from videos.
The combinatorial approach to building the base model has several advantages.
(1) It allows us to develop visual and linguistic modeling features in parallel;
(2) It avoids the complexities associated with jointly pre-training visual and verbal data, which arise from tokenization of visual data, differences in background perplexity across modalities, and competition between modalities;
(3) It ensures that the introduction of visual recognition capabilities does not affect the model's performance on text-only tasks;
(4) The cross-attention architecture ensures that we do not need to pass full-resolution images to the ever-growing LLM backbone (especially the feed-forward network in each Transformer layer), thus improving inference efficiency.
Please note that our multimodal model is still under development and not yet ready for release.
Before presenting the experimental results in Sections 7.6 and 7.7, we describe the data used to train the visual recognition capabilities, the model architecture of the visual components, how we extended the training of these components, and our pre-training and post-training recipes.
7.1 Data
We describe image and video data separately.
7.1.1 Image data
Our image encoders and adapters are trained on image-text pairs. We construct this dataset through a complex data processing pipeline that consists of four main stages:
(1) Quality filtering (2) Perceptual de-duplication (3) Resampling (4) Optical character recognition . We also apply a range of security measures.
- Mass filtration. We implemented quality filters to remove non-English captions and low-quality captions through heuristics such as the low alignment scores generated by (Radford et al., 2021). Specifically, we remove all image-text pairs that fall below a specific CLIP score.
- De-weighting. De-duplication of large-scale training datasets improves model performance because it reduces training computations for redundant data (Esser et al. 2024; Lee et al. 2021; Abbas et al. 2023) and reduces the risk of model memorization (Carlini et al. 2023; Somepalli et al. 2023). Therefore, we de-emphasize the training data for efficiency and privacy reasons. For this purpose, we use the latest in-house version of the SSCD copy detection model (Pizzi et al., 2022) to massively de-duplicate the images. For all images, we first compute a 512-dimensional representation using the SSCD model. We then use these embeddings to perform a nearest neighbor (NN) search against all images in the dataset, using a cosine similarity metric. We define examples above a specific similarity threshold as duplicate terms. We group these duplicate terms using a connected component algorithm and retain only a single image-text pair for each connected component. We improve the efficiency of the de-duplication pipeline by (1) pre-clustering the data using k-mean clustering (2) using FAISS for NN search and clustering (Johnson et al., 2019).
- Resampling. We ensure the diversity of image-text pairs, similar to Xu et al. (2023); Mahajan et al. (2018); Mikolov et al. (2013). First, we construct an n-tuple grammatical glossary by parsing high-quality text sources. Next, we calculate the frequency of n-tuple grammars for each glossary in the dataset. Then, we resample the data in the following way: if any n-tuple grammar in a caption occurs less than T times in the glossary, we keep the corresponding image-text pair. Otherwise, we independently sampled each n-tuple grammar n i in the headline with probability T / f i , where f i denotes the frequency of the n-tuple grammar n i ; if any n-tuple grammar was sampled, we kept the image-text pair. This resampling helps to improve the performance of low-frequency categories and fine-grained recognition tasks.
- Optical Character Recognition. We have further improved our image text data by extracting the text in the image and stringing it together with a caption. Written text was extracted using a proprietary optical character recognition (OCR) pipeline. We observed that adding OCR data to the training data can greatly improve the performance of tasks that require OCR capabilities, such as document comprehension.
To improve the performance of the model on the document comprehension task, we render document pages as images and pair the images with their respective text. The document text is obtained either directly from the source or through a document parsing pipeline.
Security: Our primary focus is to ensure that image recognition pre-training datasets do not contain unsafe content, such as sexually abusive material (CSAM) (Thiel, 2023). We use perceptual hashing methods such as PhotoDNA (Farid, 2021), as well as an in-house proprietary classifier that scans all training images for CSAM.We also use a proprietary media risk retrieval pipeline to identify and remove image-text pairs that we believe are NSFW, for example because they contain sexual or violent content. We believe that minimizing the prevalence of such material in the training dataset improves the safety and helpfulness of the final model without compromising its usefulness. Finally, we perform facial blurring on all images in the training set. We tested the model against human-generated cues that refer to additional images.
Annealing data: We created an annealed dataset containing approximately 350 million examples by resampling image caption pairs using n-grams. Since n-gram resampling favors richer textual descriptions, it selects a higher quality subset of the data. We also augmented the resulting data with approximately 150 million examples from five additional sources:
- Visual orientation. We associate noun phrases in the text with bounding boxes or masks in the image. The localization information (bounding boxes and masks) is specified in the image-text pairs in two ways:(1) We overlay the boxes or masks on the image and use the markers as references in the text, similar to a marker set (Yang et al., 2023a). (2) We insert the normalized (x min, y min, x max, y max) coordinates directly into the text and separate them with special markers.
- Screenshot Analysis. We render screenshots from HTML code and let the model predict the code that generates specific screenshot elements, similar to Lee et al. (2023). Elements of interest are indicated in the screenshot by bounding boxes.
- Q&A to. We include Q&A pairs that allow us to use large amounts of Q&A data that are too large to be used for model fine-tuning.
- Synthetic title. We include images with synthetic captions generated from earlier model versions. Compared to the original captions, we found that the synthetic captions provided a more comprehensive description of the image than the original captions.
- Synthesize structured images. We also include synthetically generated images for various fields such as charts, tables, flowcharts, mathematical formulas and text data. These images are accompanied by corresponding structured representations, such as corresponding Markdown or LaTeX notation. In addition to improving the model's ability to recognize these domains, we have found this data to be useful for generating Q&A pairs for fine-tuning through textual modeling.

Fig. 28 Schematic of the combined approach to adding multimodal capabilities to Llama 3 studied in this paper. This approach results in a multimodal model that is trained in five stages: language model pre-training, multimodal encoder pre-training, visual adapter training, model fine-tuning, and speech adapter training.
7.1.2 Video data
For video pre-training, we use a large dataset of video-text pairs. Our dataset is organized through a multi-stage process. We use rule-based heuristics to filter and clean up relevant text, e.g., ensuring minimum length and fixing capital letters. We then run language recognition models to filter out non-English text.
We ran the OCR detection model to filter out videos with excessively superimposed text. To ensure reasonable alignment between video-text pairs, we use CLIP (Radford et al., 2021) style image-text and video-text comparison models. We first compute image-text similarity using a single frame from the video and filter out pairs with low similarity, and then subsequently filter out pairs with poor video-text alignment. Some of our data contained still or low-motion videos; we filtered these using motion score-based filtering (Girdhar et al., 2023). We did not apply any filters to the visual quality of the videos, such as aesthetic scores or resolution filters.
Our dataset contains videos with a median duration of 16 seconds with an average duration of 21 seconds, and more than 99% of the videos are under one minute. The spatial resolution varies widely between 320p and 4K videos, with more than 70% videos having short edges larger than 720 pixels. The videos have different aspect ratios, with almost all videos having aspect ratios between 1:2 and 2:1, with a median of 1:1.
7.2 Model Architecture
Our visual recognition model consists of three main components: (1) an image encoder, (2) an image adapter, and (3) a video adapter.
Image Encoder.
Our image encoder is a standard Visual Transformer (ViT; Dosovitskiy et al. (2020)) that is trained to align images and text (Xu et al., 2023). We used the ViT-H/14 version of the image encoder, which has 630 million parameters and was trained for five epochs on 2.5 billion image-text pairs. The input image resolution of the image encoder was 224 × 224; the image was split into 16 × 16 equal-sized chunks (i.e., a block size of 14 × 14 pixels). As shown in previous work such as ViP-Llava (Cai et al., 2024), we found that image encoders trained by comparing text-aligned targets do not retain fine-grained localization information. To mitigate this problem, we employ a multilayer feature extraction approach that provides features at layers 4, 8, 16, 24, and 31 in addition to the last layer of features.
In addition, we further inserted 8 gated self-attention layers (40 Transformer blocks in total) prior to the pre-training of the cross-attention layers to learn alignment-specific features. As a result, the image encoder ends up with 850 million parameters and additional layers. With multiple layers of features, the image encoder produces a 7680-dimensional representation for each of the generated 16 × 16 = 256 chunks. We do not freeze the parameters of the image encoder in subsequent training phases, as we have found that this improves performance, especially in areas such as text recognition.
Image Adapters.
We introduce a cross-attention layer between the visual marker representation produced by the image encoder and the marker representation produced by the language model (Alayrac et al., 2022). The cross-attention layer is applied after every fourth self-attention layer in the core language model. Like the language model itself, the cross-attention layer uses generalized query attention (GQA) to improve efficiency.
The cross-attention layer introduces a large number of trainable parameters to the model: for Llama 3 405B, the cross-attention layer has about 100 billion parameters. We pre-trained the image adapters in two stages: (1) initial pre-training and (2) annealing:* Initial pre-training. We pre-trained our image adapters on the aforementioned dataset of about 6 billion image-text pairs. To improve computational efficiency, we resize all images to fit into a maximum of four 336 × 336 pixel blocks, where we arrange the blocks to support different aspect ratios, such as 672 × 672, 672 × 336, and 1344 × 336. Â Â Annealing. We continue to train the image adapter using approximately 500 million images from the annealing dataset described above. During the annealing process, we increase the image resolution of each plot to improve performance on tasks that require higher resolution images, such as infographic comprehension.
Video Adapter.
Our model accepts inputs of up to 64 frames (uniformly sampled from the complete video), each of which is processed by an image encoder. We model the temporal structure in the video through two components: (i) the encoded video frames are merged into one by a temporal aggregator that combines 32 consecutive frames into one; and (ii) additional video cross-attention layers are added before each fourth image cross-attention layer. Temporal aggregators are implemented as perceptron resamplers (Jaegle et al., 2021; Alayrac et al., 2022). We used 16 frames per video (aggregated into 1 frame) for pre-training, but increased the number of input frames to 64 during supervised fine-tuning. The video aggregator and cross-attention layer have 0.6 and 4.6 billion parameters in Llama 3 7B and 70B, respectively.
7.3 Model Scale
After adding the visual recognition components to Llama 3, the model contains a self-attention layer, a cross-attention layer, and a ViT image encoder. We found that data parallelism and tensor parallelism were the most efficient combinations when training adapters for smaller (8 and 70 billion parameters) models. At these scales, model or pipeline parallelism will not improve efficiency because collecting model parameters will dominate the computation. However, we did use pipeline parallelism (in addition to data and tensor parallelism) when training the adapter for the 405 billion parameter model. Training at this scale presents three new challenges in addition to those outlined in Section 3.3: model heterogeneity, data heterogeneity, and numerical instability.
model heterogeneity. The model computations are heterogeneous, as certain tokens perform more computations than others. In particular, image tokens are processed through the image encoder and the cross-attention layer, while text tokens are processed only through the linguistic backbone network. This heterogeneity can lead to bottlenecks in pipeline parallel scheduling. We address this problem by ensuring that each pipeline stage contains five layers: i.e., four self-attention layers and one cross-attention layer in the linguistic backbone network. (Recall that we introduced a cross-attention layer after every four self-attention layers.) In addition, we replicate the image encoder to all pipeline stages. Since we train on paired image-text data, this allows us to load balance between the image and text portions of the computation.
Data heterogeneityThe data is heterogeneous because, on average, images have more tags than associated text: an image has 2308 tags while associated text has only 192 tags on average. The data is heterogeneous because, on average, images have more tokens than associated text: an image has 2308 tokens, while associated text has only 192 tokens on average. As a result, the computation of the cross-attention layer takes longer and requires more memory than the computation of the self-attention layer. We address this problem by introducing sequence parallelism in the image encoder so that each GPU processes roughly the same number of tokens. We also use a larger micro-batch size (8 instead of 1) due to the relatively small average text size.
Numerical instability. After adding the image encoder to the model, we found that gradient accumulation using bf16 resulted in unstable values. The most likely explanation is that image markers are introduced into the linguistic backbone network through all the cross-attention layers. This means that numerical deviations in the image-tagged representation have a disproportionate impact on the overall computation, as errors are compounded. We address this issue by performing gradient accumulation using FP32.
7.4 Pre-training
Image Pre-training. We start the initialization with the pre-trained text model and visual coder weights. The visual coder was unfrozen while the text model weights remained frozen as described above. First, we trained the model using 6 billion image-text pairs, each image being resized to fit into four 336 × 336 pixel plots. We used a global batch size of 16,384 and a cosine learning rate scheme with an initial learning rate of 10 × 10 -4 and weight decay of 0.01. The initial learning rate was determined based on small-scale experiments. However, these findings do not generalize well to very long training schedules, and we reduce the learning rate several times during training when the loss values stagnate. After basic pre-training, we increase the image resolution further and continue training with the same weights on the annealed dataset. The optimizer is reinitialized to a learning rate of 2 × 10 -5 by warming up, again following the cosine schedule.
Video pre-training. For video pretraining, we start with the image pretraining and annealing weights described above. We will add video aggregator and cross-attention layers as described in the architecture and initialize them randomly. We freeze all parameters in the model except the video-specific ones (aggregator and video cross-attention) and train them on the video pretraining data. We use the same training hyperparameters as in the image annealing phase, with slightly different learning rates. We uniformly sample 16 frames from the full video and use four blocks of size 448 × 448 pixels to represent each frame. We use an aggregation factor of 16 in the video aggregator to get a valid frame that the text markers will cross-focus on. We train using a global batch size of 4,096, a sequence length of 190 tokens, and a learning rate of 10 -4 .
7.5 Post-training treatment
In this section, we describe the subsequent training steps for the visual adapter in detail.
After pre-training, we fine-tuned the model to highly-selected multimodal conversation data to enable chat functionality.
In addition, we implement Direct Preference Optimization (DPO) to improve manual evaluation performance and employ rejection sampling to improve multimodal inference.
Finally, we add a quality tuning phase where we continue to fine-tune the model on a very small dataset of high-quality conversations, which further improves the manual evaluation results while preserving the performance of the benchmark test.
Detailed information on each step is provided below.
7.5.1 Monitoring of fine-tuned data
We describe supervised fine-tuning (SFT) data for image and video functions, respectively, below.
IMAGE. We use a mixture of different datasets for supervised fine-tuning.
- Academic datasets: we convert highly filtered existing academic datasets into question-answer pairs using templates or through a Large Language Model (LLM) rewrite.The purpose of the LLM rewrite is to augment the data with different instructions and to improve the linguistic quality of the answers.
- Manual Annotation: We collect multimodal dialog data for a variety of tasks (open-ended Q&A, captioning, real-world use cases, etc.) and domains (e.g., natural images and structured images) through manual annotators. The annotator will receive the images and be asked to compose the dialog.
To ensure diversity, we clustered the large-scale dataset and sampled the images evenly across the different clusters. In addition, we obtain additional images for some specific domains by using k-nearest neighbor extension seeds. The annotator is also provided with intermediate checkpoints of existing models to facilitate stylized annotation of the models in the loop so that model generation can be used as a starting point for the annotator to provide additional human edits. This is an iterative process in which the model checkpoints are periodically updated to better performing versions that are trained on the latest data. This increases the amount and efficiency of manual annotation while improving quality.
- Synthetic Data: We explore different approaches to generate synthetic multimodal data by using textual representations of images and textual input LLMs. The basic idea is to utilize the inference capabilities of the text input LLM to generate Q&A pairs in the text domain and replace the textual representations with their corresponding images to produce synthetic multimodal data. Examples include rendering text from a Q&A dataset as images or rendering tabular data as synthetic table and chart images. In addition, we use captioning and OCR extraction of existing images to generate general dialog or Q&A data associated with the images.
Video. Similar to the image adapter, we use pre-existing annotated academic datasets for conversion into appropriate textual instructions and target responses. Objectives will be converted to open-ended responses or multiple-choice questions, as appropriate. We asked manual annotators to add questions and corresponding answers to the videos. We asked the annotator to focus on questions that could not be answered based on individual frames in order to steer the annotator towards questions that would take time to understand.
7.5.2 Oversight of the fine-tuning program
We present supervised fine-tuning (SFT) schemes for image and video capabilities, respectively:
IMAGE. We initialize the model from the pre-trained image adapter, but replace the weights of the pre-trained language model with the weights of the instruction-tuned language model. To maintain text-only performance, the language model weights are kept frozen, i.e., we only update the visual coder and image adapter weights.
Our fine-tuning approach is similar to Wortsman et al. (2022). First, we perform hyperparameter scans using multiple random subsets of data, learning rates, and weight decay values. Next, we rank the models based on their performance. Finally, we averaged the weights of the top K models to obtain the final model.The value of K was determined by evaluating the average model and selecting the highest performing instance. We observe that the average model consistently produces better results compared to the best individual model found through the grid search. In addition, this strategy reduces the sensitivity to hyperparameters.
Video. For the video SFT, we initialize the video aggregator and the cross-attention layer using pre-trained weights. The remaining parameters of the model (image weights and LLMs) are initialized from the corresponding models and follow their fine-tuning stages. Similar to video pretraining, only the video parameters on the video SFT data are then fine-tuned. In this phase, we increase the video length to 64 frames and use an aggregation factor of 32 to obtain two valid frames. The resolution of the aynı zamanda,block is increased accordingly to be consistent with the corresponding image hyperparameters.
7.5.3 Preferences
To reward modeling and direct preference optimization, we constructed multimodal paired preference datasets.
- Manual labeling. The manually labeled preference data consisted of a comparison of the outputs of two different models, labeled as "select" and "reject", and rated on a 7-point scale. The models used to generate responses are randomly sampled each week from a pool of the best recent models, each with different characteristics. In addition to the preference labels, we asked the annotator to provide optional manual editing to correct inaccuracies in the "Select" response, as the visual task is less tolerant of inaccuracies. Note that manual editing is an optional step, as there is a trade-off between quantity and quality in practice.
- Synthesis data. Synthetic preference pairs can also be generated by using text-only LLM editing and deliberately introducing errors in the supervised fine-tuning dataset. We took the dialog data as input and used LLM to introduce subtle but meaningful errors (e.g., changing objects, changing attributes, adding computational errors, etc.). These edited responses are used as negative "reject" samples and are paired with the "selected" original supervised fine-tuning data.
- Reject Sampling. In addition, to create more strategic negative samples, we utilize an iterative process of rejection sampling to collect additional preference data. We discuss how rejection sampling is used in more detail in the next sections. In summary, rejection sampling is used to iteratively sample high-quality generated results from the model. Thus, as a byproduct, all unselected generated results can be used as negative rejection samples and as additional preference data pairs.
7.5.4 Reward models
We trained a visual reward model (RM) based on a visual SFT model and a linguistic RM. the visual encoder and cross-attention layers were initialized from the visual SFT model and unfrozen during training, while the self-attention layer was initialized from the linguistic RM and kept frozen. We observe that freezing the language RM part usually leads to better accuracy, especially in tasks that require the RM to make judgments based on its knowledge or language quality. We use the same training objective as for the language RM, but add a weighted regularization term to square the batch-averaged reward logits to prevent reward score drift.
The human preference annotations in Section 7.5.3 were used to train the visual RMs. we followed the same approach as for the linguistic preference data (Section 4.2.1), creating two or three pairs with clear rankings (edited version > selected version > rejected version). In addition, we synthetically enhanced negative responses by scrambling words or phrases (e.g., numbers or visual text) associated with the image information. This encourages the visual RM to base its judgment on the actual image content.
7.5.5 Direct preference optimization
Similar to the language model (Section 4.1.4), we further trained the visual adapter using Direct Preference Optimization (DPO; Rafailov et al. (2023)) with the preference data described in Section 7.5.3. To combat distributional bias during post-training, we retained only the most recent batches of human preference annotations, and discarded those batches with a large gap to the strategy (e.g., if the underlying pre-training model was changed). We found that instead of freezing the reference model all the time, updating it every k steps as an exponential moving average (EMA) helps the model learn more from the data, leading to better performance in human evaluations. Overall, we observe that the visual DPO model consistently outperforms its SFT starting point in human evaluations and performs well in every fine-tuning iteration.
7.5.6 Rejection of sampling
Most existing quiz pairs contain only final answers and lack the chain-of-thought explanations needed to reason about models that generalize the task well. We use rejection sampling to generate the missing explanations for these examples, thereby improving the model's reasoning.
Given a quiz pair, we generate multiple answers by sampling the fine-tuned model using different system cues or temperatures. Next, we compare the generated answers with the true answers via heuristics or LLM referees. Finally, we retrain the model by adding correct answers to the fine-tuned data. We find it useful to retain multiple correct answers per question.
To ensure that only high-quality examples were added to the training, we implemented the following two safety measures:
- We found that some examples contained incorrect explanations, even though the final answer was correct. We note that this pattern is more common in questions where only a small fraction of the generated answers are correct. Therefore, we discarded answers for questions whose probability of a correct answer was below a specific threshold.
- Reviewers favor certain answers due to language or style differences. We use a reward model to select the K highest quality answers and add them to the training.
7.5.7 Quality tuning
We carefully curate a small but highly selective fine-tuned (SFT) dataset, where all samples are rewritten and validated to meet the highest standards, either manually or by our best models. We use this data to train DPO models to improve response quality and refer to this process as quality tuning (QT). We found that when the QT dataset covers a wide range of tasks and appropriate early stops are applied, QT can significantly improve human assessment results without affecting the general performance of the benchmark test validation. At this stage, we select checkpoints based on benchmark tests only to ensure that capabilities are maintained or improved.
7.6 Image Recognition Results
We evaluated the performance of Llama 3 image understanding capabilities on a range of tasks covering natural image understanding, text understanding, diagram understanding, and multimodal reasoning:
- MMMU (Yue et al., 2024a) is a challenging multimodal reasoning dataset where models are required to understand images and solve college-level problems across 30 different disciplines. This includes multiple-choice and open-ended questions. We evaluate the model on a validation set containing 900 images, consistent with other work.
- VQAv2 (Antol et al., 2015) tests the model's ability to combine image understanding, language comprehension, and general knowledge to answer general questions about natural images.
- AI2 Diagram (Kembhavi et al., 2016) assesses the ability of models to parse scientific diagrams and answer questions about them. We used the same model as Gemini Same evaluation protocol as x.ai and uses transparent bounding boxes to report scores.
- ChartQA (Masry et al., 2022) is a challenging benchmark test for chart comprehension. It requires models to visually understand different types of charts and answer questions about the logic of those charts.
- TextVQA (Singh et al., 2019) is a popular benchmark dataset that requires models to read and reason about text in images to answer queries about them. This tests the model's ability to understand OCR in natural images.
- DocVQA (Mathew et al., 2020) is a benchmark dataset focused on document analysis and recognition. It contains images of a variety of documents and evaluates the ability of models to perform OCR to understand and reason about document content to answer questions about them.
Table 29 shows the results of our experiments. The results in the table show that the vision module attached to Llama 3 is competitive on various image recognition benchmarks with different model capacities. Using the resulting Llama 3-V 405B model, we outperform the GPT-4V on all benchmarks, but slightly underperform the Gemini 1.5 Pro and the Claude 3.5 Sonnet. the Llama 3 405B performs particularly well on the document comprehension task.

7.7 Video Recognition Results
We evaluated Llama 3's video adapter on three benchmarks:
- PerceptionTest (Lin et al., 2023): This benchmark tests the ability of the model to understand and predict short video clips. It contains various types of problems such as recognizing objects, actions, scenes, etc. We report the results based on the officially provided code and evaluation metrics (accuracy).
- TVQA (Lei et al., 2018): This benchmark assesses the model's composite reasoning ability, which entails spatial-temporal localization, recognition of visual concepts, and joint reasoning with subtitled dialogues. Since the dataset is derived from popular TV programs, it also tests the model's ability to utilize external knowledge of these TV programs to answer questions. It contains over 15,000 validated QA pairs, each corresponding to a video clip with an average length of 76 seconds. It uses a multiple choice format with five options per question, and we report performance on the validation set based on previous work (OpenAI, 2023b).
- ActivityNet-QA (Yu et al., 2019): This benchmark evaluates the ability of the model to comprehend long video clips for action, spatial relationships, temporal relationships, counting, etc. It contains 8,000 test QA pairs from 800 videos. It contains 8,000 test QA pairs from 800 videos, each with an average length of 3 minutes. For evaluation, we follow the protocol of previous work (Google, 2023; Lin et al., 2023; Maaz et al., 2024), where the model generates short word or phrase responses and compares them to real answers using the GPT-3.5 API to assess the correctness of the output. We report the average accuracy calculated by the API.
process of reasoning
When performing inference, we uniformly sample frames from the full video clip and pass them to the model along with a short textual prompt. Since most benchmarks involve answering multiple-choice questions, we use the following prompts:
- Choose the correct answer from the following options:{question}. Answer using only the correct option letter and do not write anything else.
For benchmarks that need to generate short answers (e.g., ActivityNet-QA and NExT-QA), we use the following hints:
- Answer the question using a word or phrase: {question}.
For NExT-QA, since the assessment metrics (WUPS) are sensitive to length and the specific words used, we also prompted the model to be specific and respond to the most salient answers, e.g., specifying "living room" instead of simply "house" when asked about location. ". For benchmarks that include subtitles (i.e., TVQA), we include the corresponding subtitles of the clip in the cue during the inference process.
in the end
Table 30 shows the performance of the Llama 3 8B and 70B models. We compare their performance to that of the two Gemini models and the two GPT-4 models. Note that all results are zero-sample results, as we did not include any portion of these benchmarks in our training or fine-tuning data. We find that our Llama 3 model is very competitive in training small video adapters during post-processing, and in some cases even outperforms other models that may utilize native multimodal processing from pre-training onwards.Llama 3 performs particularly well in video recognition, as we only evaluated the 8B and 70B parameter models.Llama 3 achieved the best performance on the PerceptionTest, demonstrating the model's strong ability to perform complex temporal reasoning. In long clip activity understanding tasks like ActivityNet-QA, Llama 3 achieves strong results even when it processes only up to 64 frames (for a 3-minute video, the model processes only one frame every 3 seconds).


8 Speech experiment
We conducted experiments to investigate a combinatorial approach to integrating speech functionality into Llama 3, similar to the scheme we used for visual recognition. On the input side, encoders and adapters were added to process speech signals. We utilize system cues (in the form of text) to enable Llama 3 to support different modes of speech understanding. If no system prompts are provided, the model acts as a generic speech dialog model that can effectively respond to user speech in a manner consistent with the text-only version of Llama 3. Introducing dialog history as a cue prefix can improve the multi-round dialog experience. We also experimented with the use of system prompts for Automatic Speech Recognition (ASR) and Automatic Speech Translation (AST) in Llama 3. Llama 3's speech interface supports up to 34 languages.18 It also allows for alternating text and speech input, enabling the model to solve advanced audio comprehension tasks.
We also experimented with a speech generation approach in which we implemented a streaming text-to-speech (TTS) system that dynamically generates speech waveforms during decoding of the language model. We designed Llama 3's speech generator based on the proprietary TTS system and did not fine-tune the language model for speech generation. Instead, we focused on improving the latency, accuracy, and naturalness of speech synthesis by utilizing Llama 3 word embeddings during inference. The speech interface is shown in Figures 28 and 29.
8.1 Data
8.1.1 Speech understanding
The training data can be divided into two categories. Pre-training data consists of large amounts of unlabeled speech used to initialize the speech encoder in a self-supervised manner. Supervised fine-tuning data includes speech recognition, speech translation, and spoken dialog data; these are used to unlock specific capabilities when integrating with large language models.
Pre-training data. To pre-train the speech encoder, we collated a dataset containing about 15 million hours of speech recordings across multiple languages. We filtered the audio data using a Voice Activity Detection (VAD) model and selected audio samples with a VAD threshold higher than 0.7 for pre-training. In the speech pre-training data, we also focused on ensuring the absence of personally identifiable information (PII). We use Presidio Analyzer to identify such PII.
Speech recognition and translation data. Our ASR training data contains 230,000 hours of handwritten transcribed speech recordings in 34 languages. Our AST training data contains 90,000 hours of bi-directional translation: from 33 languages to English and from English to 33 languages. These data contain both supervised and synthetic data generated using the NLLB toolkit (NLLB Team et al., 2022). The use of synthetic AST data can improve the quality of models for low-resource languages. The maximum length of speech segments in our data is 60 seconds.
Spoken dialog data. To fine-tune the speech adapters used for spoken conversations, we synthesized responses to speech prompts by asking the language model to respond to transcriptions of these prompts (Fathullah et al., 2024). We used a subset of the ASR dataset (containing 60,000 hours of speech) to generate the synthesized data in this way.
In addition, we generated 25,000 hours of synthesized data by running the Voicebox TTS system (Le et al., 2024) on a subset of the data used to fine-tune Llama 3. We used several heuristics to select a subset of the fine-tuned data that matched the speech distribution. These heuristics included a focus on relatively short and simply structured cues, and did not include non-textual symbols.
8.1.2 Speech generation
语音生成数据集主要包括用于训练文本规范化(TN)模型和韵律模型(PM)的数据集。两种训练数据都通过添加 Llama 3 词嵌入作为额外的输入特征进行增强,以提供上下文信息。
文本规范化数据。我们的 TN 训练数据集包含 5.5 万个样本,涵盖了广泛的符号类别(例如,数字、日期、时间),这些类别需要非平凡的规范化。每个样本由书面形式文本和相应的规范化口语形式文本组成,并包含一个推断的手工制作的 TN 规则序列,用于执行规范化。
声韵模型数据。PM 训练数据包括从一个包含 50,000 小时的 TTS 数据集提取的语言和声韵特征,这些特征与专业配音演员在录音室环境中录制的文字稿件和音频配对。
Llama 3 嵌入。Llama 3 嵌入取自第 16 层解码器输出。我们仅使用 Llama 3 8B 模型,并提取给定文本的嵌入(即 TN 的书面输入文本或 PM 的音频转录),就像它们是由 Llama 3 模型在空用户提示下生成的。在一个样本中,每个 Llama 3 标记序列块都明确地与 TN 或 PM 本地输入序列中的相应块对齐,即 TN 特定的文本标记(由 Unicode 类别区分)或语音速率特征。这允许使用 Llama 3 标记和嵌入的流式输入训练 TN 和 PM 模块。
8.2 Model Architecture
8.2.1 Speech Understanding
On the input side, the speech module consists of two consecutive modules: a speech encoder and an adapter. The output of the speech module is input directly into the language model as a tokenized representation, allowing speech and text tokens to interact directly. In addition, we introduce two new special tokens for containing sequences of speech representations. The speech module is significantly different from the vision module (see Section 7), which inputs multimodal information into the language model via a cross-attention layer. In contrast, the embeddings generated by the speech module can be seamlessly integrated into the textual tokens, allowing the speech interface to utilize all the features of the Llama 3 language model.
Speech Encoder:Our speech encoder is a Conformer model with 1 billion parameters (Gulati et al., 2020). The input to the model consists of 80-dimensional Meier spectrogram features, which are first processed through a stacked layer with a step size of 4, and then reduced to a frame length of 40 milliseconds by linear projection. The processed features are handled by an encoder containing 24 Conformer layers. Each Conformer layer has a potential dimension of 1536 and includes two Macron-net style feedforward networks with a dimension of 4096, a convolutional module with a kernel size of 7, and a rotational attention module with 24 attention heads (Su et al., 2024).
Voice adapter:The speech adapter contains about 100 million parameters. It consists of a convolutional layer, a rotating Transformer layer and a linear layer. The convolutional layer has a kernel size of 3 and a step size of 2 and is designed to reduce the speech frame length to 80 milliseconds. This allows the model to provide coarser-grained features to the language model.The Transformer layer, with a potential dimension of 3072, and the feed-forward network, with a dimension of 4096, further process the speech information that has been down-sampled by the convolution. Finally, the Linear layer maps the output dimension to match the language model embedding layer.
8.2.2 Speech generation
We use Llama 3 8B embeddings in two key components of speech generation: text normalization and prosody modeling. The Text Normalization (TN) module ensures semantic correctness by contextually transforming written text into spoken form. The Prosodic Modeling (PM) module enhances naturalness and expressiveness by using these embeddings to predict prosodic features. These two components work together to achieve accurate and natural speech generation.
**Text Normalization**: As a determinant of the semantic correctness of the generated speech, the Text Normalization (TN) module performs a context-aware transformation from written text to the corresponding spoken form, which is ultimately verbalized by downstream components. For example, depending on the semantic context, the written form "123" may be read as a base number (one hundred twenty three) or spelled digit-by-digit (one two three).The TN system consists of a streaming LSTM-based sequence labeling model that predicts the number of digits to be used to transforming hand-crafted TN rule sequences of input text (Kang et al., 2024). The neural model also receives Llama 3 embeddings via cross-attention to utilize the contextual information encoded therein, enabling minimal text-tagging foresight and streaming input/output.
**Rhyme modeling**: to enhance the naturalness and expressiveness of synthesized speech, we integrated a rhyme model (PM) that decodes only the Transformer architecture (Radford et al., 2021), which uses Llama 3 embeddings as additional input. This integration leverages the linguistic capabilities of Llama 3 by using its textual output and intermediate embeddings (Devlin et al. 2018; Dong et al. 2019; Raffel et al. 2020; Guo et al. 2023) to enhance the prediction of rhyming features, thereby reducing the look-ahead required by the model.The PM integrates multiple input components to generate comprehensive rhyming predictions: from the text normalization front end detailed above PM integrates multiple input components to generate comprehensive metrical predictions: linguistic features, tokens, and embeddings derived from the text normalization front-end described in detail above. three key metrical features are predicted by PM: the log duration of each phoneme, the mean log fundamental frequency (F0), and the mean log power over the duration of the phoneme. The model consists of a unidirectional Transformer and six attention heads. Each block consists of a cross-attention layer and a dual fully-connected layer with 864 hidden dimensions.A distinctive feature of the PM is its dual cross-attention mechanism, with one layer dedicated to the linguistic input and the other to the Llama embedding. This setup effectively manages different input rates without the need for explicit alignment.
8.3 Training programs
8.3.1 Speech understanding
The speech module is trained in two stages. In the first phase, speech pre-training, a speech encoder is trained using unlabeled data that exhibits strong generalization capabilities with respect to linguistic and acoustic conditions. In the second phase, supervised fine-tuning, the adapter and the pre-trained encoder are integrated with the speech model and co-trained with it while the LLM remains frozen. This allows the model to respond to speech input. This phase uses labeled data that corresponds to speech comprehension capabilities.
Multilingual ASR and AST modeling often leads to language confusion/interference, which degrades performance. A popular mitigation method is to include language identification (LID) information at both the source and target. This can improve performance in a predetermined direction, but it can also lead to degradation of generalization capabilities. For example, if a translation system expects to provide LID information at both the source and target, it is unlikely that the model will exhibit good zero-sample performance in directions not seen in training. Thus, our challenge is to design a system that allows for some degree of LID information while keeping the model general enough for speech translation in unseen directions. To address this problem, we designed system cues that contain only the LID information of the text to be output (target side). These cues do not contain LID information for the speech input (source side), which may also make it possible to handle code-switching speech. For ASR, we use the following system prompt: Repeat my words in {language}:, where {language} is from one of the 34 languages (English, French, etc.). For speech translation, the system prompt is: "Translate the following sentence into {language}:". This design has been shown to be effective in prompting language models to respond in the desired language. We use the same system prompt during training and inference.
We use the self-supervised BEST-RQ algorithm (Chiu et al., 2022) to pre-train speech.
编码器采用长度为 32 帧的掩码,对输入 mel 谱图的概率为 2.5%。如果语音话语超过 60 秒,我们将随机裁剪 6K 帧,对应 60 秒的语音。通过堆叠 4 个连续帧、将 320 维向量投影到 16 维空间,并在 8192 个向量的代码库内使用余弦相似度度量进行最近邻搜索,对 mel 谱图特征进行量化。为了稳定预训练,我们采用 16 个不同的代码库。投影矩阵和代码库随机初始化,在模型训练过程中不更新。多软最大损失仅用于掩码帧,以提高效率。编码器经过 50 万步训练,全局批处理大小为 2048 个语音。
监督微调。预训练语音编码器和随机初始化的适配器在监督微调阶段与 Llama 3 联合优化。语言模型在此过程中保持不变。训练数据是 ASR、AST 和对话数据的混合。Llama 3 8B 的语音模型经过 650K 次更新训练,使用全局批大小为 512 个话语和初始学习率为 10。Llama 3 70B 的语音模型经过 600K 次更新训练,使用全局批大小为 768 个话语和初始学习率为 4 × 10。
8.3.2 Speech generation
To support real-time processing, the rhyming model employs a look-ahead mechanism that takes into account a fixed number of future phonemic positions and a variable number of future tokens. This ensures consistent look-ahead while processing incoming text, which is critical for low-latency speech synthesis applications.
Training. We develop a dynamic alignment strategy utilizing causal masks to facilitate streaming of speech synthesis. The strategy combines a prospective mechanism in the prosodic model for a fixed number of future phonemes and a variable number of future tokens, consistent with the chunking process in text normalization (Section 8.1.2).
For each phoneme, the marker lookahead consists of the maximum number of markers defined by the block size, resulting in Llama embeddings with variable lookahead and phonemes with fixed lookahead.
Llama 3 embeddings from the Llama 3 8B model that remain frozen during rhyme model training. Input call rate features include linguistic and speaker/style controllability elements. The model is trained using an AdamW optimizer with a batch size of 1,024 tones and a learning rate of 9 × 10 -4. The model is trained over 1 million updates, with the first 3,000 updates performing a learning rate warm-up and then following cosine scheduling.
Reasoning. During inference, the same look-ahead mechanism and causal masking strategy are used to ensure consistency between training and real-time processing.PM processes incoming text in a streaming fashion, updating the input phone-by-phone for phone-rate features, and chunk-by-chunk for mark-rate features. New block inputs are updated only when the first phone of the block is current, thus maintaining alignment and look-ahead during training.
To predict rhyme targets, we used a delayed mode approach (Kharitonov et al., 2021), which enhances the model's ability to capture and replicate long-range rhyme dependencies. This approach contributes to the naturalness and expressiveness of the synthesized speech, ensuring low latency and high quality output.
8.4 Speech understanding results
We evaluated the speech understanding capabilities of the Llama 3 speech interface for three tasks: (1) Automatic Speech Recognition (2) Speech Translation (3) Speech Q&A. We compare Llama 3's speech interface performance to three state-of-the-art speech understanding models: Whisper (Radford et al., 2023), SeamlessM4T (Barrault et al., 2023), and Gemini. in all evaluations, we use greedy search to predict Llama 3's tokens.
Speech Recognition. We evaluated ASR performance on Multilingual LibriSpeech (MLS; Pratap et al., 2020), LibriSpeech (Panayotov et al., 2015), VoxPopuli (Wang et al., 2021a), and a subset of the FLEURS multilingual dataset (Conneau et al. 2023) on the English dataset to evaluate ASR performance. In the evaluations, the use of Whisper The text normalization procedure post-processes the decoding results to ensure consistency with results reported by other models. In all benchmarks, we measure the word error rate of the Llama 3 speech interface on the standardized test set of these benchmarks, except for Chinese, Japanese, Korean, and Thai, where we report the character error rate.
Table 31 shows the ASR evaluation results. It demonstrates the strong performance of Llama 3 (and multimodal base models more generally) on speech recognition tasks: our model outperforms speech-specific models such as Whisper20 and SeamlessM4T in all benchmarks. For MLS English, Llama 3 performs similarly to Gemini.
Voice translation. We also evaluated the performance of our model in a speech translation task where the model is asked to translate non-English speech into English text. We use the FLEURS and Covost 2 (Wang et al., 2021b) datasets in these evaluations and measure the BLEU scores for translated English. Table 32 shows the results of these experiments. The performance of our model in speech translation highlights the advantages of multimodal base models in tasks such as speech translation.
Voice Quiz. Llama 3's voice interface demonstrates amazing question answering capabilities. The model can effortlessly understand code-switched speech without prior exposure to such data. Notably, although the model was trained only on single-round conversations, it is capable of extended and coherent multi-round dialog sessions. Figure 30 shows some examples that highlight these multilingual and multi-round capabilities.
Security. We evaluated the safety performance of our speech model on MuTox (Costa-jussà et al., 2023), a dataset for multilingual audio-based datasets containing 20,000 English and Spanish segments and 4,000 segments in 19 other languages, each labeled for toxicity. The audio is passed as input to the model and the output is evaluated for toxicity after removing some special characters. We applied the MuTox classifier (Costa-jussà et al., 2023) to Gemini 1.5 Pro and compared the results. We evaluated the percentage of added toxicity (AT) when the input prompts safe and the output is toxic, and the percentage of lost toxicity (LT) when the input prompts toxic and the answer is safe. Table 33 shows the results for English and our average results across all 21 languages. The percentage of added toxicity is very low: our speech model has the lowest percentage of added toxicity for English, less than 11 TP3T. it removes much more toxicity than it adds.

8.5 Speech generation results
In speech generation, we focus on evaluating the quality of marker-based streaming input models that use Llama 3 vectors for text normalization and rhyme modeling tasks. The evaluation focuses on comparisons with models that do not use Llama 3 vectors as additional input.
Text normalization. In order to measure the impact of the Llama 3 vector, we tried to vary the amount of right-hand side context used by the model. We trained the model using a right-hand side context of 3 text normalization (TN) tokens (separated by Unicode categories). This model was compared to a model that does not use the Llama 3 vector and uses either the 3-tagged right-hand side context or the full bi-directional context. As expected, Table 34 shows that using the full right-hand side context improves the performance of the model without Llama 3 vectors. However, the model that includes Llama 3 vectors outperforms all other models, enabling mark-rate input/output streaming without having to rely on long contexts in the input. We compare models with and without Llama 3 8B vectors and using different right-hand side context values.
Rhythmic Modeling. To evaluate the performance of our rhyming model (PM) with Llama 3 8B, we conducted two sets of human ratings comparing models with and without Llama 3 vectors. Raters listened to samples from different models and indicated their preferences.
To generate the final speech waveform, we used a Transformer-based internal acoustic model (Wu et al., 2021), which predicts spectral features, and a WaveRNN neural vocoder (Kalchbrenner et al., 2018) to generate the final speech waveform.
In the first test, we will directly compare with the streaming benchmark model without using Llama 3 vectors. In the second test, the Llama 3 8B PM was compared to a non-streaming benchmark model that does not use Llama 3 vectors. As shown in Table 35, the Llama 3 8B PM was preferred for 60% of time (compared to the streaming benchmark) and 63.6% of time was preferred (compared to the non-streaming benchmark), which indicates a significant improvement in perceptual quality. The key advantage of the Llama 3 8B PM is its marker-based streaming capability (Section 8.2.2), which maintains low latency during the inference process. This reduces the look-ahead requirements of the model, enabling the model to achieve more responsive and real-time speech synthesis compared to the non-streaming benchmark model. Overall, the Llama 3 8B rhyming model consistently outperforms the benchmark model, demonstrating its effectiveness in improving the naturalness and expressiveness of synthesized speech.




9 Related work
The development of Llama 3 builds on a large body of prior research on fundamental models of language, image, video, and speech. The scope of this paper does not include a comprehensive overview of this work; we refer the reader to Bordes et al. (2024); Madan et al. (2024); Zhao et al. (2023a) for such an overview. Below, we provide a brief overview of seminal works that directly influenced the development of Llama 3.
9.1 Language
Scope. Llama 3 follows the enduring trend of applying simple methods to ever-increasing scales that characterize the base model. Improvements are driven by increases in computational power and data quality, with the 405B model using almost fifty times the pre-training computational budget of Llama 2 70B. Although our largest Llama 3 contains 405B parameters, it actually has fewer parameters than earlier and poorer performing models such as PALM (Chowdhery et al., 2023), due to a better understanding of scaling laws (Kaplan et al., 2020; Hoffmann et al., 2022). The sizes of other frontier models, such as Claude 3 or GPT 4 (OpenAI, 2023a), have limited publicly available information, but have comparable overall performance.
Small-scale models. The development of small-scale models has gone hand in hand with the development of large-scale models. Models with fewer parameters can significantly improve inference costs and simplify deployment (Mehta et al., 2024; Team et al., 2024). The smaller Llama 3 model accomplishes this by far exceeding the computationally optimal training points, effectively trading off training computation for inference efficiency. Another route is to distill larger models into smaller ones, such as Phi (Abdin et al., 2024).
Architecture. Compared to Llama 2, Llama 3 makes minimal architectural modifications, but other recent base models explore alternative designs. Most notably, expert hybrid architectures (Shazeer et al. 2017; Lewis et al. 2021; Fedus et al. 2022; Zhou et al. 2022) can be used as a way to efficiently increase the capacity of a model, such as in Mixtral (Jiang et al. 2024) and Arctic (Snowflake 2024). the performance of Llama 3 outperforms these models, suggesting that dense architectures are not a limiting factor, but that there are still many tradeoffs in terms of training and inference efficiency, as well as model stability at large scales.
Open Source. Open source base models have evolved rapidly over the past year, with Llama3-405B now on par with the current closed source state-of-the-art. A number of model families have been developed recently, including Mistral (Jiang et al., 2023), Falcon (Almazrouei et al., 2023), MPT (Databricks, 2024), Pythia (Biderman et al., 2023), Arctic (Snowflake, 2024), OpenELM (Mehta et al., 2024), OLMo (Groeneveld et al., 2024), StableLM (Bellagente et al., 2024), OpenLLaMA (Geng and Liu, 2023), Qwen (Bai et al., 2023), Gemma (Team et al., 2024), Grok (Biderman et al., 2024), and Gemma (Biderman et al., 2024). 2024), Grok (XAI, 2024), and Phi (Abdin et al., 2024).
Post-training. Llama 3's post-training follows an established instruction tuning strategy (Chung et al., 2022; Ouyang et al., 2022), followed by alignment with human feedback (Kaufmann et al., 2023). While some studies have shown unexpected results with lightweight alignment procedures (Zhou et al., 2024), Llama 3 uses millions of human instruction and preference judgments to improve pre-trained models, including rejection sampling (Bai et al., 2022), supervised fine-tuning (Sanh et al., 2022), and direct preference optimization (Rafailov et al., 2023). To curate these instruction and preference examples, we deployed earlier versions of Llama 3 to filter (Liu et al., 2024c), rewrite (Pan et al., 2024), or generate cues and responses (Liu et al., 2024b), and applied these techniques through multiple rounds of post-training.
9.2 Multimodality
Our Llama 3 multimodal capability experiments are part of a long-term study of fundamental models for jointly modeling multiple modalities. Our Llama 3 approach combines ideas from many papers to achieve results comparable to Gemini 1.0 Ultra (Google, 2023) and GPT-4 Vision (OpenAI, 2023b); see Section 7.6.
video: Despite the growing number of base models supporting video input (Google, 2023; OpenAI, 2023b), not much research has been done on joint modeling of video and language. Similar to Llama 3, most of the current research uses adapter methods to align video and language representations and to unravel questions and answers and reasoning about video (Lin et al. 2023; Li et al. 2023a; Maaz et al. 2024; Zhang et al. 2023; Zhao et al. 2022). We find that such methods produce results that are competitive with the state-of-the-art; see Section 7.7.
colloquial (rather than literary) pronunciation of a Chinese character: Our work is also integrated into a larger effort that combines language and speech modeling. Early joint text and speech models include AudioPaLM (Rubenstein et al., 2023), VioLA (Wang et al., 2023b), VoxtLM Maiti et al. (2023), SUTLM (Chou et al., 2023) and Spirit-LM (Nguyen et al., 2024) . Our work builds on previous compositional approaches to combining speech and language such as Fathullah et al. (2024). Unlike most of this prior work, we chose not to fine-tune the language model itself for the speech task, as doing so could lead to competition from non-speech tasks. We find that even without such fine-tuning, good performance can be achieved at larger model sizes; see Section 8.4.
10 Conclusion
The development of high-quality base models is still in its early stages. Our experience in developing Llama 3 suggests that there is much room for future improvement of these models. In developing the Llama 3 family of models, we have found that a strong focus on high-quality data, scale, and simplicity consistently leads to the best results. In preliminary experiments, we explored more complex model architectures and training scenarios, but did not find that the benefits of these approaches outweighed the additional complexity they introduced in model development.
Developing a flagship base model like Llama 3 requires not only overcoming many deep technical issues, but also making informed organizational decisions. For example, to ensure that Llama 3 is not accidentally overfitted to commonly used benchmark tests, our pre-training data is sourced and processed by an independent team that is strongly incentivized to prevent contaminating external benchmark tests with pre-training data. As another example, we ensure the credibility of human assessments by allowing only a small group of researchers not involved in model development to perform and access these assessments. While these organizational decisions are rarely discussed in technical papers, we found them to be critical to the successful development of the Llama 3 model family.
We share details of our development process because we believe it will help the broader research community understand the key elements of base model development and contribute to a more insightful public discussion about the future development of base models. We also share preliminary experimental results of integrating multimodal functionality into Llama 3. While these models are still under active development and are not yet ready for release, we hope that sharing our results early will accelerate research in this direction.
Given the positive results of the safety analyses detailed in this paper, we are publicly releasing our Llama 3 language model to accelerate the process of developing AI systems for a wide range of socially relevant use cases, and to enable the research community to review our models and find ways to make them better and safer. We believe that the public release of the underlying models is critical to the responsible development of such models, and we hope that the release of Llama 3 will encourage the industry as a whole to embrace open, responsible AI development.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...