
OCR Prompt for Extracting Image Text Using Visual Models

In the face of complex text structures, or mixed-text content, it is good to utilize the visual model OCR capability to extract the content.
Multimodal macromodels or specialized visual models can understand the content of the image and receive instructions to perform recognition tasks, and we will use this capability to make the output match our requirements.
OCR Prompt is recommended to be tested in the following tool: ChatGPT , Kimi , Qwen2-VL(Currently the most accurate)
Test image:
The complexity of this image is the obscured json part, which is understood differently by different big models
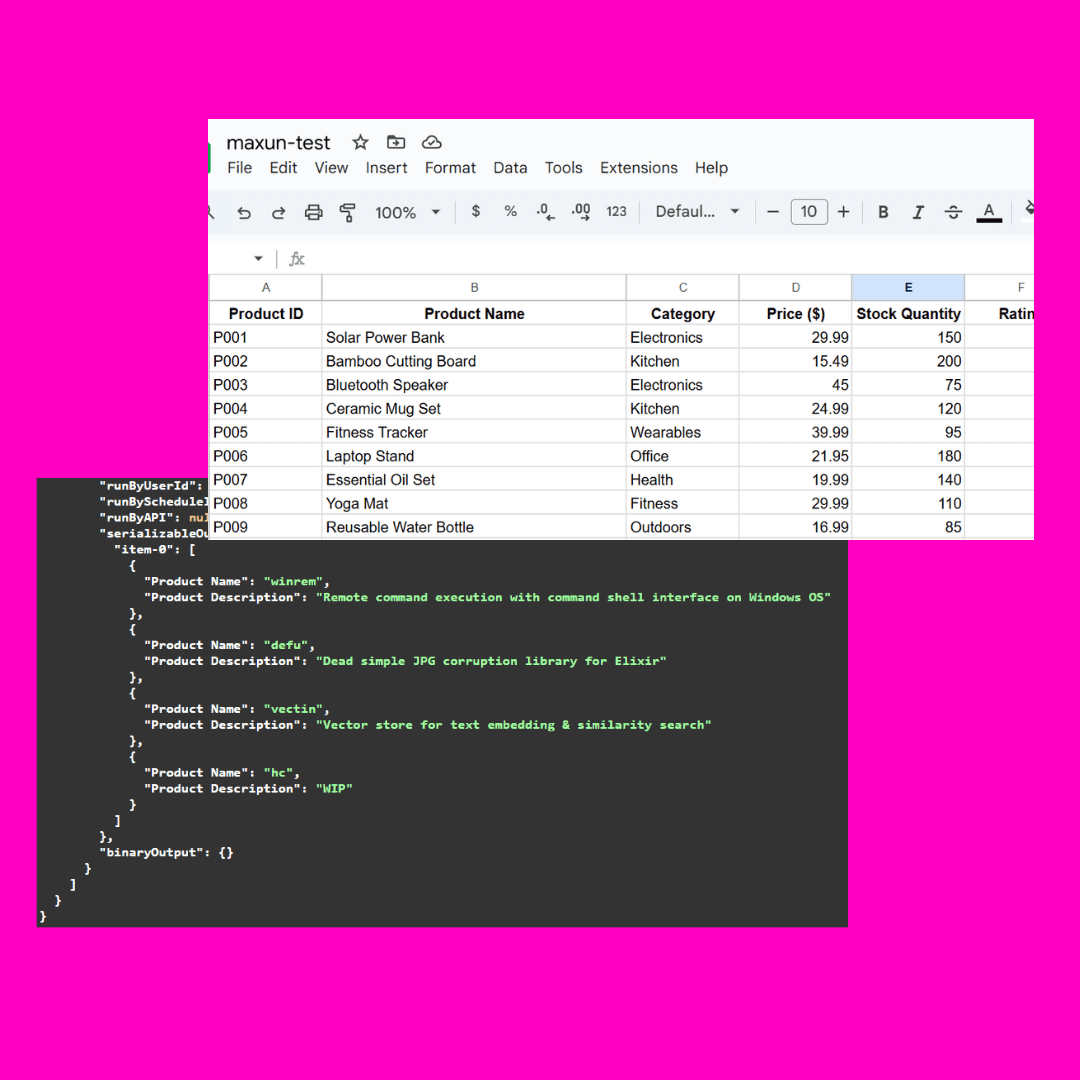
Generally simple commands are fine:
按照原文格式提取
Only part of the content is extracted:
仅提取图片中的表格部分
Extract and transcribe to fixed format text:
识别图片后整理为MARKDOWN格式表格,请保持表格原始顺序、格式和语言
Structured Extraction:
您的任务是将文件内容转录并格式化为 markdown。您的目标是创建一个结构良好、可读性强的 markdown 文档,该文档准确表示原始内容,同时添加适当的格式和标签。 请按照以下说明完成任务: 1. 仔细阅读整个文件内容。 2. 将内容转录为 markdown 格式,密切关注现有的格式和结构。 3. 如果您在原始内容中发现任何不清楚的格式,请自行判断添加适当的 markdown 格式以提高可读性和结构。 4. 对于表格、标题和目录,请添加以下标签: - 表格:将整个表格括在 [TABLE] 和 [/TABLE] 标签中。如果表格内容在下一页继续,请合并表格内容。 - 标题(在每页开头重复的完整字符串):括在 markdown 文件内的 [HEADER] 和 [/HEADER] 标签中。 - 目录:用 [TOC] 和 [/TOC] 标签括起来 5. 转录表格时: - 如果表格跨越多页,请将内容合并为一个连贯的表格。 - 使用适当的 markdown 表格格式,表格结构使用竖线 (|) 和连字符 (-)。 6. 不要在转录中包含分页符。 7. 保持文档的逻辑流程和结构,确保使用 markdown 标题正确格式化章节和小节(# 表示主标题,## 表示副标题等)。 8. 根据需要对其他格式元素(如粗体、斜体、列表和代码块)使用适当的 markdown 语法。 10. 仅返回 markdown 格式的解析内容,包括表格、标题和目录的指定标签。
Extract and translate:
The translation commands I use most often are used here, and they also work wonders for OCR extraction of complex structured text:Translation of the "English instruction template" into "Chinese instructions", retaining the original formatting
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...