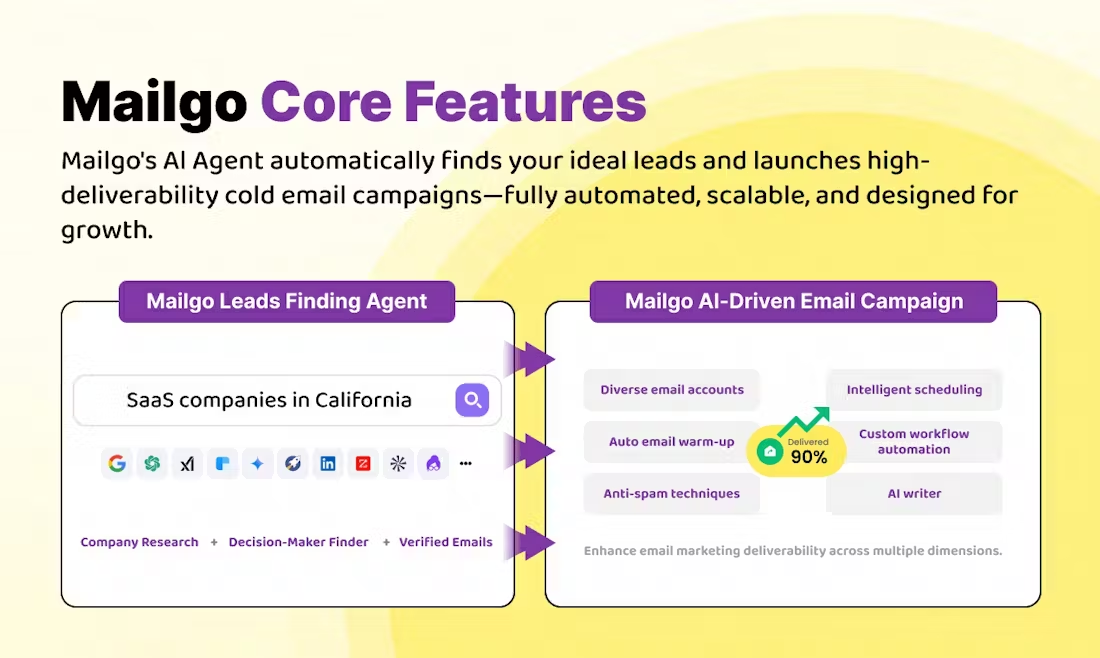
LHM: Generating action-enabled 3D human models from a single image

General Introduction
LHM (Large Animatable Human Reconstruction Model) is an open source project, which is developed by aigc3d team, and can quickly generate action-supporting 3D human models from a single image. The core feature is the use of AI technology to turn a 2D image into a 3D model in seconds, with support for real-time preview and pose adjustment.LHM uses 3D Gaussian Splatting technology to represent the human body, combined with a multimodal transformer architecture that preserves clothing texture and geometric details. The project, first released on March 13, 2025, provides pre-trained models and code suitable for research or development of 3D digital human-related applications.

Function List
- Generate a 3D mannequin from a single image in seconds.
- Real-time rendering is supported and the generated model can be viewed directly.
- Provide action function to adjust human body posture to generate dynamic video.
- Output 3D mesh files (e.g. OBJ format) for subsequent editing.
- Pre-trained models (e.g. LHM-0.5B and LHM-1B) are included and do not need to be trained themselves.
- Integrated Gradio interface with local visualization support.
- Provides a video processing pipeline that can extract actions from video to apply to models.
Using Help
The use of LHM is divided into two parts: installation and operation. Below are detailed steps to help you get started quickly.
Installation process
- Preparing the environment
System requires Python 3.10 and CUDA (version 11.8 or 12.1 supported). An NVIDIA graphics card, such as an A100 or 4090, with at least 16GB of video memory is recommended.- Check the Python version:
python --version - Check the CUDA version:
nvcc --version
- Check the Python version:
- clone warehouse
Enter the following command in the terminal to download the LHM code:git clone https://github.com/aigc3d/LHM.git cd LHM
- Installation of dependencies
Run the corresponding script according to your CUDA version:- CUDA 11.8:
sh ./install_cu118.sh - CUDA 12.1:
sh ./install_cu121.sh
If the script fails, install the dependencies manually:
pip install -r requirements.txt - CUDA 11.8:
- Download model
The model will be downloaded automatically. If you want to download it manually, use the following command:- LHM-0.5B model:
wget https://virutalbuy-public.oss-cn-hangzhou.aliyuncs.com/share/aigc3d/data/for_lingteng/LHM/LHM-0.5B.tar tar -xvf LHM-0.5B.tar - LHM-1B model:
wget https://virutalbuy-public.oss-cn-hangzhou.aliyuncs.com/share/aigc3d/data/for_lingteng/LHM/LHM-1B.tar tar -xvf LHM-1B.tar
Download it and extract it to the project root directory.
- LHM-0.5B model:
- Verify Installation
Run the test commands to ensure that the environment is OK:python app.pyIf successful, the Gradio interface will be launched.
workflow
Generate 3D models
- Prepare the picture
Prepare a clear image containing the whole body of the human body and save it locally, for example<path_to_image>/person.jpgThe - Running inference scripts
Enter it in the terminal:bash ./inference.sh ./configs/inference/human-lrm-1B.yaml LHM-1B <path_to_image>/ ./output/<path_to_image>is the path to your image../output/is the output folder where the generated results are saved.
- View Results
After generating the<output>The folder will have the 3D model file and the rendered video. You can open the mesh files with 3D software (e.g. Blender) or play the videos directly.
Add Action
- Preparatory Movement Sequence
The project provides sample action files, located in the<LHM根目录>/train_data/motion_video/mimo1/smplx_params. You can also use your own SMPL-X parameter file. - Running Action Scripts
Enter the following command:bash ./inference.sh ./configs/inference/human-lrm-1B.yaml LHM-1B <path_to_image>/ <path_to_motion>/smplx_params<path_to_motion>is the action file path.
- Preview Action Video
The output folder generates an action video, which can be played directly.
Using the Gradio Interface
- Launch Interface
Runs in the terminal:python app.pyThe browser will open
http://0.0.0.0:7860The - Upload a picture
Upload a body image in the interface and click "Submit". - Getting results
After a few seconds, the interface will display the rendered image and action video, which can be downloaded and viewed.
Exporting 3D meshes
- Run the export script
Input:bash ./inference_mesh.sh ./configs/inference/human-lrm-1B.yaml LHM-1B - Find the file.
The output folder will have mesh files in OBJ format, which can be edited with 3D software.
caveat
- Pictures need to be clear and simple backgrounds work better.
- The action effect depends on the quality of the input action.
- If there is not enough video memory, try the LHM-0.5B model.
application scenario
- game development
Developers can use LHM to quickly generate 3D character models from photos, adjust poses and import them into the game engine, saving modeling time. - film and television production
Film and TV teams can use LHM to create digital stand-ins, generate action videos for special effects scenes, and reduce labor modeling costs. - virtual anchor (TV)
Hosts can upload their photos to generate a 3D image and then add actions to create a personalized virtual image. - Educational research
Researchers were able to test 3D reconstruction algorithms with LHM or demonstrate the conversion process from pictures to models in the classroom.
QA
- What image formats does LHM support?
Support common formats such as JPG, PNG, JPG is recommended, file size not more than 10MB. - How long does it take to generate a model?
About 0.2 seconds on A100 cards, 1-2 seconds on 4090 cards, varies slightly depending on hardware. - Can I train the model myself?
It is possible, but no training scripts are officially provided. Requires preparation of dataset and tuning of code, suitable for experienced users. - Can the output 3D model be edited?
Can. After exporting the OBJ file, edit the geometry and textures with Blender or Maya.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...