Cursor Creates and Manages Project Documentation to Improve Development Efficiency
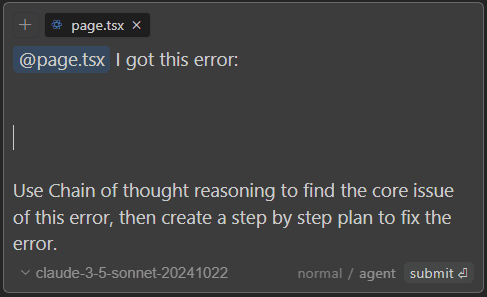
"Fixing Errors" Tip AI models like Sonnet 3.5 can sometimes miss important details, which can trigger a series of error loops. Use the following tips to solve this problem. This will help the AI analyze the root cause of the error and then create a step-by-step plan to fix it...