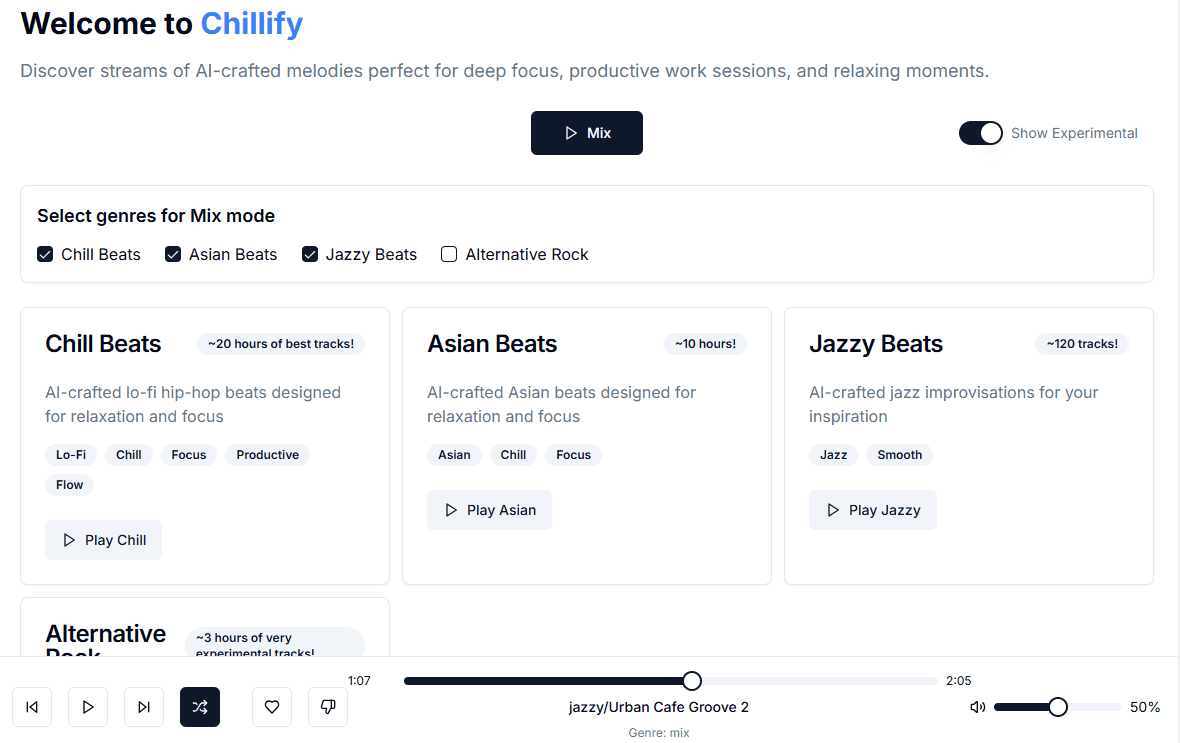
Knowledge Table: an open source tool for efficient extraction and exploration of structured data

General Introduction
Knowledge Table (Knowledge Table) is an open source project designed to simplify the process of extracting and exploring structured data from unstructured documents. Users can create structured knowledge representations such as tables and graphs through a natural language query interface. The tool supports customization of extraction rules and formatting options, and ensures data traceability by displaying data sources through a user interface. Knowledge Sheets provides business users with a familiar spreadsheet interface, while providing developers with a flexible and highly configurable backend for a variety of data processing needs.


Function List
- natural language extraction (NLE): Support for extracting structured data from unstructured documents using natural language queries.
- Customized extraction rules: Users can define extraction rules to ensure data quality.
- format control: The output format of the extracted data can be controlled.
- Document Filtering: Filter documents based on metadata or extracted data.
- CSV or Trigram Export: Supports downloading of extracted data into CSV or Chart Triad format.
- chain extraction: Allow references to previous columns in questions.
Using Help
Installation and operation
- Docker running::
- Ensure that Docker and Docker Compose are installed.
- Using commands
docker-compose up -d --buildLaunch the application. - Access to the front end
http://localhost:3000and back-endhttp://localhost:8000The
- local operation::
- Cloning the code base:
git clone https://github.com/yourusername/knowledge-table.git - Go to the backend directory and create a virtual environment:
cd knowledge-table/backend/ python3 -m venv venv source venv/bin/activate # Windows使用 venv\Scripts\activate pip install -r requirements.txt - Start the back-end service:
cd src/ python -m uvicorn knowledge_table_api.main:app
- Cloning the code base:
- Front-end settings::
- Go to the front-end directory and install the dependencies:
cd ../frontend/ curl https://bun.sh/install | bash # 安装Bun bun install bun start - Front-end services can be found in the
http://localhost:5173Access.
- Go to the front-end directory and install the dependencies:
Usage Process
- Upload a document: Uploading unstructured documents to the knowledge table, the system splits them into chunks and stores them in a vector database.
- Setting questions and rules: Define the type of data to be extracted and the corresponding questions that the system will process based on this information.
- View Results: After completing the data processing, the user can view the structured output and make adjustments as needed.
caveat
- Ensure that relevant laws and regulations are followed to avoid infringing on the rights of others.
- Extracted data is regularly validated to ensure its accuracy and currency.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles


No comments...