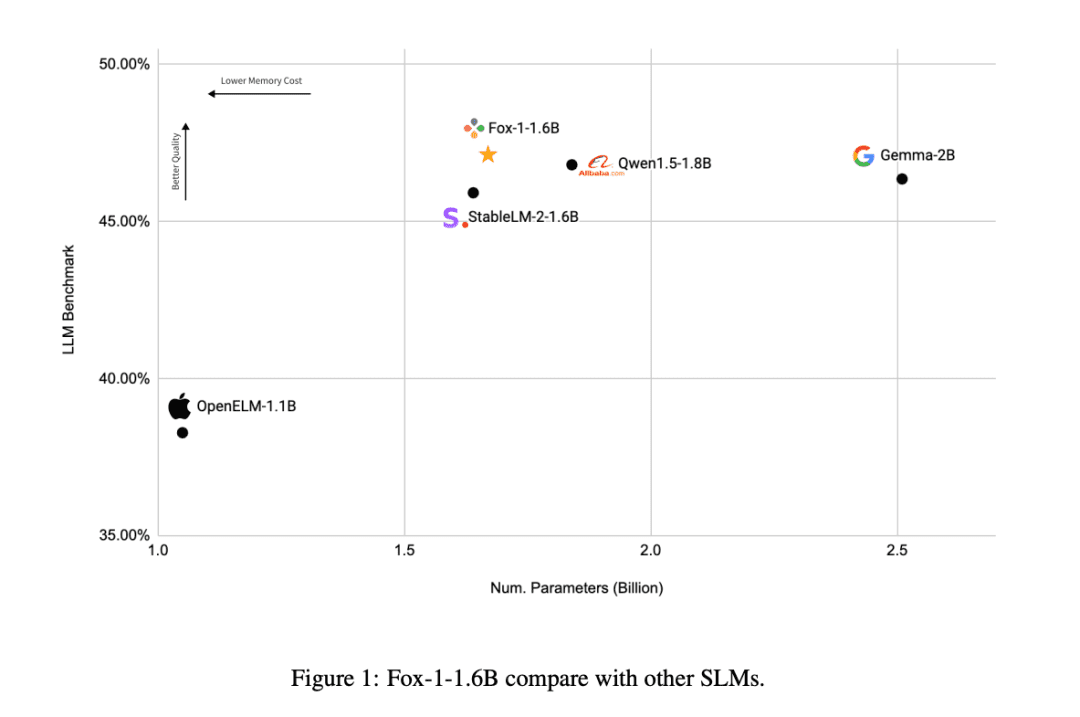
Open source 1.6B miniatures "Little Fox", outperforms similar models Qwen and Gemma


since (a time) Chatgpt Since its inception, the number of LLM (Large Language Model) parameters seems to be a competition metric for each company. the GPT-1 parameter count was 117 million (117M) and its fourth generation, the GPT-4, has refreshed the parameter count to 1.8 trillion (1800B).
Like other LLM models such as Bloom (176 billion, 176B) and Chinchilla (70 billion, 70B) the number of parameters is also soaring. The number of parameters directly affects the performance and capability of the model, with more parameters meaning that the model is able to handle more complex language patterns, understand richer contextual information, and exhibit higher levels of intelligence on a wide range of tasks.
However, these huge number of parameters also directly affect the training cost and development environment of LLM, and limit the exploration of LLM by most common research companies, leading to the fact that big language modeling has gradually become an arms race among big companies.
Recently, emerging AI company TensorOpera released theOpen Source Small Language Model FOX, proving to the industry that Small Language Models (SLMs) can also show enough strength in the field of intelligentsia.

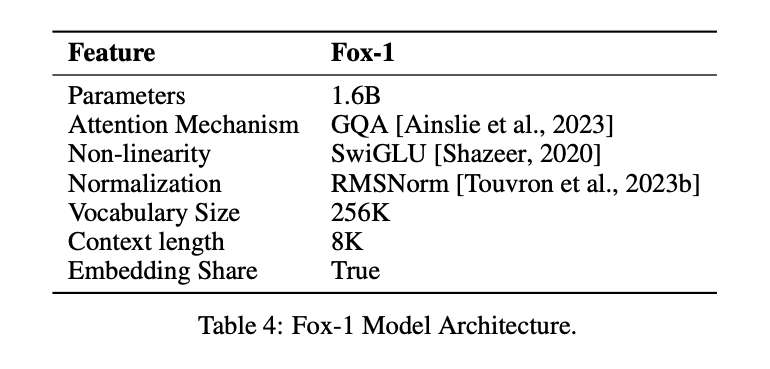
FOX is aSmall Language Models Designed for Cloud and Edge Computing. Unlike large language models with tens of billions of parameters, FOX Only 1.6 billion parametersThe program has been designed to be a very versatile and easy to use, yet it is able to show amazing performance in multiple tasks.
Dissertation Title:
FOX-1 TECHNICAL REPORT
Link to paper:
https://arxiv.org/abs/2411.05281

Who is TensorOpera?
TensorOpera is an innovative artificial intelligence company based in Silicon Valley, California. They previously developed the TensorOpera® AI Platform generative AI ecosystem and the TensorOpera® FedML federal learning and analytics platform. The company's name, TensorOpera, is a combination of technology and art, symbolizing GenAI's eventual development of multimodal and multi-model composite AI systems.

Dr. Jared Kaplan, co-founder and CEO of TensorOpera, said, "The FOX model was originally designed to dramatically reduce compute resource requirements while maintaining high performance. This not only makes AI technology more approachable, but also lowers the barrier to use for organizations."
How does the Fox model work?
In order to achieve the same effect as the LLM with a smaller number of parameters, the Fox-1 modelDecoder onlyarchitecture and introduces various improvements and redesigns for better performance. These include
① network layer: In the design of model architectures, wider and shallower neural networks have better memorization capabilities, while deeper and thinner networks present stronger inference capabilities. Following this principle, Fox-1 uses a deeper architecture than most modern SLMs. Specifically, Fox-1 consists of 32 self-attentive layers, which is 781 TP3T deeper than Gemma-2B (18 layers) and 331 TP3T deeper than StableLM-2-1.6B (24 layers) and Qwen1.5-1.8B (24 layers).
② Shared Embedding: Fox-1 uses 2,048 hidden dimensions to build a total of 256,000 vocabularies with about 500 million parameters. Larger models typically use separate embedding layers for the input layer (glossary to embedded expression) and the output layer (embedded expression to glossary). For Fox-1, the embedding layer alone requires 1 billion parameters. To reduce the total number of parameters, sharing the input and output embedding layers maximizes weight utilization.
(iii) pre-normalization: Fox-1 uses RMSNorm to normalize the inputs of each transformation layer; RMSNorm is the preferred choice for pre-normalization in modern large-scale language models, and it exhibits better efficiency than LayerNorm.
④ Rotary position encoding (RoPE): Fox-1 accepts input tokens up to 8K in length by default. to improve performance with longer context windows, Fox-1 uses rotated positional encoding, where θ is set to 10,000 for encoding token The relative positional dependence between
⑤ Group Query Attention (GQA): Grouped Query Attention divides the query heads of the multi-head attention layer into groups, each sharing the same set of key-value heads.Fox-1 is equipped with 4 key-value heads and 16 attention heads to improve training and inference speeds and reduce memory usage.
In addition to modeling structural improvements.FOX-1 also improves on Tokenization and training.The
the part of speech (in Chinese grammar)Fox-1 uses the SentencePiece-based Gemma classifier, which provides a vocabulary size of 256K. Increasing the vocabulary size has at least two main benefits. First, the length of the hidden information in the context is extended because each token encodes more dense information. For example, a vocabulary size of 26 can encode only one character in [a-z], but a vocabulary size of 262 can encode two letters at the same time, making it possible to represent longer strings in a fixed-length token. Second, a larger vocabulary size reduces the probability of unknown words or phrases, which in practice achieves better performance on downstream tasks.The large vocabulary used by Fox-1 produces fewer tokens for a given text corpus, which yields better inference performance.
Fox-1Pre-training dataSourced from the Redpajama, SlimPajama, Dolma, Pile, and Falcon datasets, totaling 3 trillion pieces of text data. To alleviate the inefficiency of pre-training for long sequences due to its attention mechanism, Fox-1 introduces in the pre-training phase aThree-stage course learning strategyFox-1 is a three-phase training pipeline, in which the chunk length of the training samples is gradually increased from 2K to 8K to ensure long contextual capabilities at a small cost. To align with the three-phase course pre-training pipeline, Fox-1 reorganizes the raw data into three distinct sets, including unsupervised and instruction-tuned datasets, as well as data from different domains such as code, web content, and mathematical and scientific documents.
Fox-1 training can be divided into three phasesThe
- The first phase consists of about 39% total data samples throughout the pre-training process, where the 1.05 trillion token dataset is partitioned into samples of length 2,000, with a batch size of 2 M. A linear warm-up of 2,000epoch is used in this phase.
- The second phase includes about 59% samples with 1.58 trillion tokens and increases the chunk length from 2K to 4K and 8K. the actual chunk length varies with different data sources. Considering that the second phase takes the longest time and involves different sources from different datasets, the batch size is also increased to 4M to improve the training efficiency.
- Finally, in the third phase, the Fox model is trained using 6.2 billion tokens (about 0.02% of the total) of high-quality data to lay the groundwork for different downstream task capabilities such as command following, small talk, domain-specific Q&A, and so on.
How did Fox-1 perform?
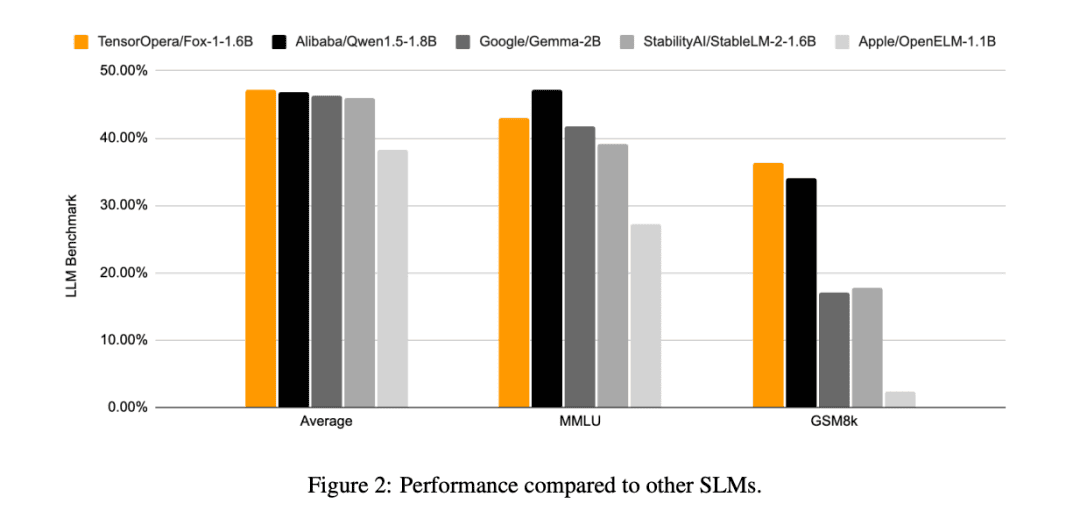
Compared to other SLM models (Gemma-2B, Qwen1.5-1.8B, StableLM-2-1.6B, and OpenELM1.1B), FOX-1 was more successful in the ARC Challenge (25-shot), HellaSwag (10-shot), TruthfulQA (0-shot), the MMLU (5-shot), Winogrande (5-shot), GSM8k (5-shot)The average scores of the benchmark for the six tasks were the highest and were significantly better on the GSM8k.
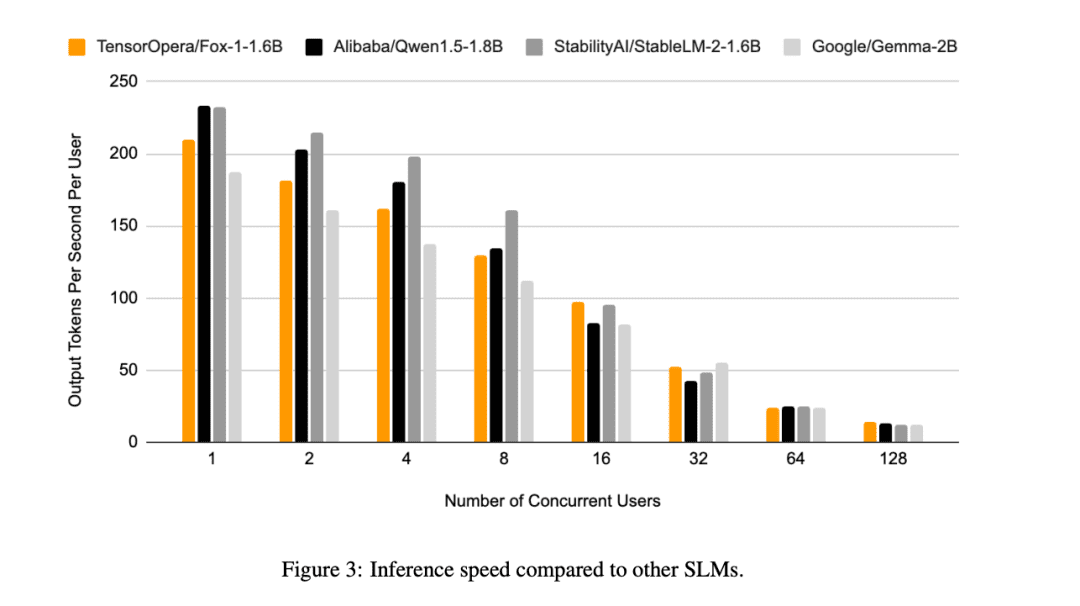
In addition to this, TensorOpera also evaluated Fox-1, Qwen1.5-1.8B and Gemma-2B using the vLLM End-to-end inference efficiency with the TensorOpera Service Platform on a single NVIDIA H100.
Fox-1 achieves a throughput of over 200 tokens per second, outperforming Gemma-2B and matching Qwen1.5-1.8B in the same deployment environment. At BF16 precision, Fox-1 requires only 3703MiB of GPU memory, while Qwen1.5-1.8B, StableLM-2-1.6B, and Gemma-2B require 4739MiB, 3852MiB, and 5379MiB, respectively.
Small parameters, but still competitive
Currently, all AI companies are competing in large language modeling, but TensorOpera has taken a different approach to break through in the SLM field, achieving similar results to LLM with only 1.6B, and performing well in a variety of benchmark tests.
Even with limited data resources, TensorOpera can pre-train language models with competitive performance, providing a new way of thinking for other AI companies to develop.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


![[转]用 2000 美元 EPYC 服务器本地跑起 Deepseek R1 671b 大模型](https://aisharenet.com/wp-content/uploads/2025/02/78984d5c0694467.png)

No comments...